- 首发公号:Rand_cs
Hypervisor 需要对每个虚机的虚拟中断进行管理,这其中涉及的一系列数据结构和操作就是虚拟中断子系统
VIRQ
虚拟中断描述符
struct vcpu {
uint32_t vcpu_id;
...........
/*
* member to record the irq list which the
* vcpu is handling now
*/
struct virq_struct *virq_struct;
...........
} __cache_line_align;
minos 对于每个物理 CPU 定义了 struct pcpu 来管理其相关状态,同样的,minos 对于每个 vm 的 vcpu,也定义了一个结构体来管理 struct vcpu。每个 vcpu 里面又有一个 virq_struct 字段来管理该 vcpu 关于中断的一些信息,具体来看:
struct virq_struct {
int nr_lrs; // LR 寄存器个数
int last_fail_virq; // 上一个因分配 LR 失败的 virq
atomic_t pending_virq; // 有多少个 virq 处于 pending 状态
uint32_t active_virq; // 有多少个 virq 处于 active 状态
struct virq_desc local_desc[VM_LOCAL_VIRQ_NR]; // virq 描述符(PPI+SGI)
unsigned long *pending_bitmap; // virq pending 位图(PPI+SGI+SPI)
unsigned long *active_bitmap; // virq active 位图
unsigned long lrs_bitmap[BITS_TO_LONGS(VGIC_MAX_LRS)]; // LR 位图
};
//..........................
#define VM_SGI_VIRQ_NR (CONFIG_NR_SGI_IRQS) //16
#define VM_PPI_VIRQ_NR (CONFIG_NR_PPI_IRQS) //16
#define VM_LOCAL_VIRQ_NR (VM_SGI_VIRQ_NR + VM_PPI_VIRQ_NR)
在 minos 中,每个物理中断都有一个 irq_desc 来描述,同样的每个虚拟中断都有一个 virq_desc 描述符,定义如下:
struct virq_desc {
int32_t flags;
uint16_t vno; // virq number
uint16_t hno; // 如果该 virq 关联了一个 hwirq,记录该 hwirq number
uint8_t id; // LR 寄存器编号
uint8_t state; // 状态
uint8_t pr; // 优先级
uint8_t src; // SGI 中断下,记录源 vcpu id
uint8_t type; // edge or level
uint8_t vcpu_id; // vcpu id
uint8_t vmid; // vm id
uint8_t padding;
} __packed;
SGI 和 PPI 可以看作是 percpu 中断,所以这里将这两种虚拟中断描述符定义在了 vcpu->virq_struct 结构体中,那 SPI 类型的中断呢,SPI 类型的中断时所有 CPU 共享的,在虚拟化的情况下就是所有 VCPU 共享,它定义在 struct vm 中:
struct vm {
int vmid;
..................
uint32_t vspi_nr; // 当前 vm spi 中断个数
struct virq_desc *vspi_desc; // spi 类型中断描述符数组
unsigned long *vspi_map; // 分配 virq_desc 时使用的位图
struct virq_chip *virq_chip; // vgic 指针
..................
} __align(sizeof(unsigned long));
初始化操作
上述涉及了很多的结构体及其字段信息,这里来看一下它们的初始化流程
// 初始化 vm 的 virq 信息
static int virq_create_vm(void *item, void *args)
{
uint32_t size, vdesc_size, vdesc_bitmap_size, status_bitmap_size;
struct vm *vm = (struct vm *)item;
struct virq_struct *vs;
void *base;
int i;
/*
* Total size:
* 1 - sizeof(struct virq_desc) * vspi_nr
* 3 - vitmap_size(spi_nr)
* 2 - vcpu_nr * bitmap_size * (SGI + PPI + SPI) * 2
*/
// 获取最大的 vspi 数量
vm->vspi_nr = vm_max_virq_line(vm);
// 计算需要的 virq_desc 大小
vdesc_size = sizeof(struct virq_desc) * vm->vspi_nr;
// 对齐
vdesc_size = BALIGN(vdesc_size, sizeof(unsigned long));
// 根据数量 vspi_nr 计算位图大小
vdesc_bitmap_size = BITMAP_SIZE(vm->vspi_nr);
// 计算一个位图大小
// 包括所有类型的中断:PPI+SGI+SPI
status_bitmap_size = BITMAP_SIZE(vm->vspi_nr + VM_LOCAL_VIRQ_NR);
// 需要分配的总大小 = virq_descs + spi_bitmap + pending_bitmap + active_bitmap
size = vdesc_size + vdesc_bitmap_size +
(status_bitmap_size * vm->vcpu_nr * 2);
size = PAGE_BALIGN(size);
pr_notice("allocate 0x%x bytes for virq struct\n", size);
// 根据大小分配内存
base = get_free_pages(PAGE_NR(size));
if (!base) {
pr_err("no more page for virq struct\n");
return -ENOMEM;
}
// 相关地址信息记录到 vm 对应字段
memset(base, 0, size);
vm->vspi_desc = (struct virq_desc *)base;
vm->vspi_map = (unsigned long *)(base + vdesc_size);
// 初始化 vcpu 的 pending 和 active 位图
base = base + vdesc_size + vdesc_bitmap_size;
for (i = 0; i < vm->vcpu_nr; i++) {
vs = vm->vcpus[i]->virq_struct;
ASSERT(vs != NULL);
vs->pending_bitmap = base;
base += status_bitmap_size;
vs->active_bitmap = base;
base += status_bitmap_size;
}
return 0;
}
在创建 vm 的时候会调用 virq_create_vm 来初始化 virq 的基本信息,就是上述所提到的一些值
// virq_struct 初始化
void vcpu_virq_struct_init(struct vcpu *vcpu)
{
struct virq_struct *virq_struct = vcpu->virq_struct;
struct virq_desc *desc;
int i;
virq_struct->active_virq = 0;
atomic_set(0, &virq_struct->pending_virq);
// 所有 desc 重置清零,设置为 0
memset(&virq_struct->local_desc, 0,
sizeof(struct virq_desc) * VM_LOCAL_VIRQ_NR);
// 初始化每个 desc,所欲字段设置为默认值
for (i = 0; i < VM_LOCAL_VIRQ_NR; i++) {
desc = &virq_struct->local_desc[i];
virq_clear_hw(desc);
virq_set_enable(desc);
/* this is just for ppi or sgi */
desc->vcpu_id = VIRQ_AFFINITY_VCPU_ANY;
desc->vmid = VIRQ_AFFINITY_VM_ANY;
desc->vno = i;
desc->hno = 0;
desc->id = VIRQ_INVALID_ID;
desc->state = VIRQ_STATE_INACTIVE;
}
}
// 重置 vm 中所有 virq_desc
void vm_virq_reset(struct vm *vm)
{
struct virq_desc *desc;
int i;
/* reset the all the spi virq for the vm */
for ( i = 0; i < vm->vspi_nr; i++) {
desc = &vm->vspi_desc[i];
virq_clear_enable(desc); //屏蔽该 virq
desc->pr = 0xa0; //优先级
desc->type = 0x0;
desc->id = VIRQ_INVALID_ID;
desc->state = VIRQ_STATE_INACTIVE;
if (virq_is_hw(desc)) //如果是 hw interrupt
irq_mask(desc->hno); //芯片级屏蔽
}
}
还有一些如上所示的一些重置函数,比较简单了,这里不再详述,大家可以自行阅读相关代码
注册虚拟中断
// 注册普通的 virq
int request_virq(struct vm *vm, uint32_t virq, unsigned long flags)
{
// hwirq 设置为 0,该 virq 没有与物理物理中断关联
return request_hw_virq(vm, virq, 0, flags);
}
// 注册中断衍生函数
int request_hw_virq(struct vm *vm, uint32_t virq, uint32_t hwirq,
unsigned long flags)
{
if (virq >= vm_max_virq_line(vm)) {
pr_err("invaild virq-%d for vm-%d\n", virq, vm->vmid);
return -EINVAL;
} else {
// 默认将所有的中断都发送给 vcpu0
return request_virq_affinity(vm, virq, hwirq, 0, flags);
}
}
// 注册中断的一个衍生函数
int request_virq_affinity(struct vm *vm, uint32_t virq, uint32_t hwirq,
int affinity, unsigned long flags)
{
struct vcpu *vcpu;
struct virq_desc *desc;
// 获取 vcpu0,这里的 affinity 其实就是一个 vcpu_id
vcpu = get_vcpu_in_vm(vm, affinity);
if (!vcpu) {
pr_err("request virq fail no vcpu-%d in vm-%d\n",
affinity, vm->vmid);
return -EINVAL;
}
// 获取对应的 desc
desc = get_virq_desc(vcpu, virq);
if (!desc) {
pr_err("virq-%d not exist vm-%d", virq, vm->vmid);
return -ENOENT;
}
// 注册中断
return __request_virq(vcpu, desc, virq, hwirq, flags);
}
上述是注册虚拟中断的一系列衍生函数,有一个注意点:request_hw_virq 调用 request_virq_affinity 时,affinity 参数默认是 0,也就是说后续默认将 virq 发送到 vcpu0。以前看过 KVM 的代码,KVM 也是这么处理的,默认将 SPI 中断发送到 virq0,对于 MAC ARM 使用的 HVF,虽然闭源,但是从结果上来看也是这样处理的,这是为了方便处理?存疑
// 根据 virq 获取对应的 virq_desc 结构体
// local virq(sgi ppi) 为每个 cpu 拥有的,所以将 local_desc 定义于 vcpu 中
// spi 为所有该 vm 中的 vcpu 中共享,所以将 vspi_desc 定义与 vm 中
struct virq_desc *get_virq_desc(struct vcpu *vcpu, uint32_t virq)
{
struct vm *vm = vcpu->vm;
// if virq < 32
if (virq < VM_LOCAL_VIRQ_NR)
// 直接返回对应的 virq_desc
return &vcpu->virq_struct->local_desc[virq];
// 如果 virq 大于了最大号数
if (virq >= VM_VIRQ_NR(vm->vspi_nr))
return NULL;
// virq-32 即为对应的下标值
return &vm->vspi_desc[VIRQ_SPI_OFFSET(virq)];
}
get_virq_desc 根据 virq 虚拟中断号获取对应的 virq_desc 虚拟中断描述符,如果是 percpu 中断,从 vcpu->virq_struct 获取,如果是 SPI 类型中断,从 vm->vspi_desc 中获取
// 注册 virq
static int __request_virq(struct vcpu *vcpu, struct virq_desc *desc,
uint32_t virq, uint32_t hwirq, unsigned long flags)
{
if (test_and_set_bit(VIRQS_REQUESTED_BIT,
(unsigned long *)&desc->flags)) {
pr_warn("virq-%d may has been requested\n", virq);
return -EBUSY;
}
// 设置 desc 字段值
desc->vno = virq; // virq
desc->hno = hwirq; // hwirq
desc->vcpu_id = get_vcpu_id(vcpu); // vcpu_id
desc->pr = 0xa0; // 优先级
desc->vmid = get_vmid(vcpu); // vmid
desc->id = VIRQ_INVALID_ID; // LR 编号,send_virq 的时候分配
desc->state = VIRQ_STATE_INACTIVE; //刚注册,inactive
/* mask the bits in spi_irq_bitmap, if it is a SPI */
// 如果大于 VM_LOCAL_VIRQ_NR,则为 SPI 类型的中断
if (virq >= VM_LOCAL_VIRQ_NR)
set_bit(VIRQ_SPI_OFFSET(virq), vcpu->vm->vspi_map);
/* if the virq affinity to a hwirq need to request
* the hw irq */
// 如果有对应的 hwirq
if (hwirq) {
// 设置芯片级别的 cpu 亲和性
irq_set_affinity(hwirq, vcpu_affinity(vcpu));
// 设置 VIRQS_HW 标志
virq_set_hw(desc);
// 在 hyp 下注册 hwirq 中断
request_irq(hwirq, guest_irq_handler, IRQ_FLAGS_VCPU,
vcpu->task->name, (void *)desc);
irq_mask(desc->hno);
// 否则清除 desc 的 VIRQS_HW 标志
} else {
virq_clear_hw(desc);
}
// 更新 virq 的 一些标志信息
update_virq_cap(desc, flags);
return 0;
}
想想之前注册物理中断所做的事情,主要就是设置物理中断号 irq 对应的物理中断描述符 irq_desc,其重点设置了该中断对应的 handler。注册虚拟中断类似,但有一点不同,虚拟中断在 host 侧是没有 handler 的,所以上述只是在 virq_desc 中设置了该中断的中断号、状态、各个 id 等等信息,就是没有 handler。因为 host 只是负责向虚机注入虚拟中断,处理是虚机做的事情。
另外如果一个虚拟中断关联了一个物理中断,那么需要在 host 注册该物理中断,其 handler 为 guest_irq_handler:
// hw 类型的 virq 将会注册到 hyp,注册时的 handler 便为此 guest_irq_handler,它会将中断路由到某具体的 vcpu
static int guest_irq_handler(uint32_t irq, void *data)
{
struct vcpu *vcpu;
struct virq_desc *desc = (struct virq_desc *)data;
if ((!desc) || (!virq_is_hw(desc))) {
pr_notice("virq %d is not a hw irq\n", desc->vno);
return -EINVAL;
}
/* send the virq to the guest */
// 如果 vmid 和 vcpu_id 都没有指定,很随便的话,那么就选择当前的 vcpu
if ((desc->vmid == VIRQ_AFFINITY_VM_ANY) &&
(desc->vcpu_id == VIRQ_AFFINITY_VCPU_ANY))
vcpu = get_current_vcpu();
else
// 获取 desc 指定的 vcpu
vcpu = get_vcpu_by_id(desc->vmid, desc->vcpu_id);
// send virq 给某 vcpu
return send_virq(vcpu, desc);
}
该函数主要做的事情就是调用 send_virq 来向目标 vcpu 发送虚拟中断。
中断注入
// 发送 virq 给某个 vcpu
static int send_virq(struct vcpu *vcpu, struct virq_desc *desc)
{
.......
ret = __send_virq(vcpu, desc);
.......
return 0;
}
// send virq,主要就是设置 vcpu 中对应的 virq_struct pending 位图
static int inline __send_virq(struct vcpu *vcpu, struct virq_desc *desc)
{
struct virq_struct *virq_struct = vcpu->virq_struct;
/*
* if the virq is already at the pending state, do
* nothing, other case need to send it to the vcpu
* if the virq is in offline state, send it to vcpu
* directly.
*
* SGI need set the irq source.
*/
//将 virq 设置到 pending_bitmap
if (test_and_set_bit(desc->vno, virq_struct->pending_bitmap))
return 0;
// pending_virq ++
atomic_inc(&virq_struct->pending_virq);
// 如果是 sgi 类型的 virq,设置来源 cpu 为当前 cpu
if (desc->vno < VM_SGI_VIRQ_NR)
desc->src = get_vcpu_id(get_current_vcpu());
return 0;
}
先暂时略去 send_virq 中一些复杂逻辑,中断注入的主要流程如上所示,会发现就是简单的设置 pending 位图操作。这样就完了吗,当然不是,前文 minos 4.5 中断虚拟化——vGIC 我们提到过,在 host 侧发送虚拟中断的操作实际上是获取并写一个 LR 寄存器,所以实际的中断注入操作如下:
// 进入 guest
int vgic_irq_enter_to_guest(struct vcpu *vcpu, void *data)
{
struct virq_struct *vs = vcpu->virq_struct;
struct vm *vm = vcpu->vm;
struct virq_desc *virq;
int id = 0, bit, flags = 0, size, old;
bit = vs->last_fail_virq;
size = vm_irq_count(vm) - bit;
old = vs->last_fail_virq;
vs->last_fail_virq = 0;
repeat:
// 遍历该 vcpu 的 pending_map
for_each_set_bit_from(bit, vs->pending_bitmap, size) {
// 获取该 virq 对应的 virq_desc
virq = get_virq_desc(vcpu, bit);
if (virq == NULL) {
pr_err("bad virq %d for vm %s\n", bit, vm->name);
clear_bit(bit, vs->pending_bitmap);
continue;
}
/*
* do not send this virq if there is same virq in
* active state, need wait the previous virq done.
*/
// 如果它也存在于 active_map,continue
// 说明这里处理 pending_and_active 中断的方式是不重复 trigger
if (test_bit(bit, vs->active_bitmap))
continue;
/* allocate a id for the virq */
// 分配一个 LR 寄存器
id = find_first_zero_bit(vs->lrs_bitmap, vs->nr_lrs);
// 分配失败
if (id >= vs->nr_lrs) {
pr_err("VM%d no space to send new irq %d\n",
vm->vmid, virq->vno);
// 记录分配 LR 失败的 virq
vs->last_fail_virq = bit;
break;
}
/*
* indicate that FIQ has been inject.
*/
// 如果存在标志就说明该 FIQ 已经被注入了????????
if (virq->flags & VIRQS_FIQ)
flags |= FIQ_HAS_INJECT;
flags++;
virq->id = id; // 设置刚分配的 lr_id
set_bit(id, vs->lrs_bitmap);
// 芯片级别 send_virq,核心是写 gich_lr 寄存器
virqchip_send_virq(vcpu, virq);
// 状态转移
virq->state = VIRQ_STATE_PENDING;
/*
* mark this virq as pending state and add it
* to the active bitmap.
*/
// 设置为 active
set_bit(bit, vs->active_bitmap);
vs->active_virq++;
/*
* remove this virq from pending bitmap.
*/
// pending_nr --
atomic_dec(&vs->pending_virq);
// 清除在 pending map 中的比特位
clear_bit(bit, vs->pending_bitmap);
}
// old != 0 表示上次想要 send virq 时,但是没有空闲的 lr 寄存器了,且发送失败的 virq 号记录到了 bit
// vs->last_fail_virq == 0 表示这次很可能有空闲的 lr 寄存器
// 所以调整 size 为上次失败的 virq 号,让上面的循环能够触及该失败的 virq 号,且为其分配 lr 寄存器
if ((old != 0) && (vs->last_fail_virq == 0)) {
bit = 0;
size = old;
old = 0;
goto repeat;
}
return flags;
}
该函数有点长,但同样的略去一些“无关紧要”的代码,主要逻辑就是遍历 pending 位图,为每一个 pending 状态的 virq 分配一个 LR 寄存器,然后将该 virq 的信息记录到 LR 寄存器,该 virq 的状态从 pending 变为 active。在分配 LR 寄存器的时候可能因为没有空闲的 LR 导致分配失败,处理方式是记录下来下次 enter guest 的时候处理。
// 退出 guest
int vgic_irq_exit_from_guest(struct vcpu *vcpu, void *data)
{
struct virq_struct *vs = vcpu->virq_struct;
struct virq_desc *virq;
int bit;
// 遍历该 vcpu 所有的 active_bitmap,这也就是说,可能出现多个 active interrupt
for_each_set_bit(bit, vs->active_bitmap, vm_irq_count(vcpu->vm)) {
// 获取对应的 virq_desc
virq = get_virq_desc(vcpu, bit);
if (virq == NULL) {
pr_err("bad active virq %d\n", virq);
clear_bit(bit, vs->active_bitmap);
continue;
}
/*
* the virq has been handled by the VCPU, if
* the virq is not pending again, delete it
* otherwise add the virq to the pending list
* again
*/
// 获取状态
virq->state = virqchip_get_virq_state(vcpu, virq);
// 如果该 virq 已经是 inactive,说明已处理完成
// 重置 virq 对应的 LR 为空闲状态
if (virq->state == VIRQ_STATE_INACTIVE) {
virqchip_update_virq(vcpu, virq, VIRQ_ACTION_CLEAR);
clear_bit(virq->id, vs->lrs_bitmap);
virq->id = VIRQ_INVALID_ID;
vs->active_virq--;
clear_bit(bit, vs->active_bitmap);
}
}
return 0;
}
对应的,当虚机退出 guest 会执行上述函数检查中断处理的情况,具体的会遍历 active 位图,对每一个 active virq,获取其对应的 LR.state,查看其状态,如果是 inactive,表明该 virq 已经处理完成,那么重置 LR 为空闲状态
总结xxxxxxxxxxxxxxxxxxx
Exception
前面讲述了虚拟中断,这里讲述虚机异常,也就是在 EL0、EL1 状态下发生的异常处理流程。Exception 的处理流程前文 minos 4.2 中断虚拟化——异常处理流程 讲述过,流程没有变,只是对于虚拟化多了几种异常,定义如下:
/* type defination is at armv8-spec 1906 */
DEFINE_SYNC_DESC(guest_ESR_ELx_EC_WFx, EC_TYPE_BOTH, wfi_wfe_handler, 1, 4);
DEFINE_SYNC_DESC(guest_ESR_ELx_EC_UNKNOWN, EC_TYPE_BOTH, unknown_handler, 1, 4);
DEFINE_SYNC_DESC(guest_ESR_ELx_EC_CP15_32, EC_TYPE_BOTH, mcr_mrc_cp15_handler, 1, 4);
DEFINE_SYNC_DESC(guest_ESR_ELx_EC_CP15_64, EC_TYPE_AARCH32, mcrr_mrrc_cp15_handler, 1, 4);
DEFINE_SYNC_DESC(guest_ESR_ELx_EC_CP14_MR, EC_TYPE_AARCH32, mcr_mrc_cp14_handler, 1, 4);
DEFINE_SYNC_DESC(guest_ESR_ELx_EC_CP14_LS, EC_TYPE_AARCH32, ldc_stc_cp14_handler, 1, 4);
DEFINE_SYNC_DESC(guest_ESR_ELx_EC_FP_ASIMD, EC_TYPE_BOTH, access_simd_reg_handler, 1, 4);
DEFINE_SYNC_DESC(guest_ESR_ELx_EC_CP10_ID, EC_TYPE_AARCH32, mcr_mrc_cp10_handler, 1, 4);
DEFINE_SYNC_DESC(guest_ESR_ELx_EC_CP14_64, EC_TYPE_AARCH32, mrrc_cp14_handler, 1, 4);
DEFINE_SYNC_DESC(guest_ESR_ELx_EC_ILL, EC_TYPE_BOTH, illegal_exe_state_handler, 1, 4);
DEFINE_SYNC_DESC(guest_ESR_ELx_EC_SYS64, EC_TYPE_AARCH64, access_system_reg_handler, 1, 4);
DEFINE_SYNC_DESC(guest_ESR_ELx_EC_IABT_LOW, EC_TYPE_BOTH, insabort_tfl_handler, 1, 4);
DEFINE_SYNC_DESC(guest_ESR_ELx_EC_PC_ALIGN, EC_TYPE_BOTH, misaligned_pc_handler, 1, 4);
DEFINE_SYNC_DESC(guest_ESR_ELx_EC_DABT_LOW, EC_TYPE_BOTH, dataabort_tfl_handler, 1, 4);
DEFINE_SYNC_DESC(guest_ESR_ELx_EC_SP_ALIGN, EC_TYPE_BOTH, stack_misalign_handler, 1, 4);
DEFINE_SYNC_DESC(guest_ESR_ELx_EC_FP_EXC32, EC_TYPE_AARCH32, floating_aarch32_handler, 1, 4);
DEFINE_SYNC_DESC(guest_ESR_ELx_EC_FP_EXC64, EC_TYPE_AARCH64, floating_aarch64_handler, 1, 4);
DEFINE_SYNC_DESC(guest_ESR_ELx_EC_SERROR, EC_TYPE_BOTH, serror_handler, 1, 4);
DEFINE_SYNC_DESC(guest_ESR_ELx_EC_HVC32, EC_TYPE_AARCH32, aarch64_hypercall_handler, 1, 0);
DEFINE_SYNC_DESC(guest_ESR_ELx_EC_HVC64, EC_TYPE_AARCH64, aarch64_hypercall_handler, 1, 0);
DEFINE_SYNC_DESC(guest_ESR_ELx_EC_SMC32, EC_TYPE_AARCH32, aarch64_smccall_handler, 1, 4);
DEFINE_SYNC_DESC(guest_ESR_ELx_EC_SMC64, EC_TYPE_AARCH64, aarch64_smccall_handler, 1, 4);
static struct sync_desc *guest_sync_descs[] = {
[0 ... ESR_ELx_EC_MAX] = &sync_desc_guest_ESR_ELx_EC_UNKNOWN,
[ESR_ELx_EC_WFx] = &sync_desc_guest_ESR_ELx_EC_WFx,
[ESR_ELx_EC_CP15_32] = &sync_desc_guest_ESR_ELx_EC_CP15_32,
[ESR_ELx_EC_CP15_64] = &sync_desc_guest_ESR_ELx_EC_CP15_64,
[ESR_ELx_EC_CP14_MR] = &sync_desc_guest_ESR_ELx_EC_CP14_MR,
[ESR_ELx_EC_CP14_LS] = &sync_desc_guest_ESR_ELx_EC_CP14_LS,
[ESR_ELx_EC_FP_ASIMD] = &sync_desc_guest_ESR_ELx_EC_FP_ASIMD,
[ESR_ELx_EC_CP10_ID] = &sync_desc_guest_ESR_ELx_EC_CP10_ID,
[ESR_ELx_EC_CP14_64] = &sync_desc_guest_ESR_ELx_EC_CP14_64,
[ESR_ELx_EC_ILL] = &sync_desc_guest_ESR_ELx_EC_ILL,
[ESR_ELx_EC_SYS64] = &sync_desc_guest_ESR_ELx_EC_SYS64,
[ESR_ELx_EC_IABT_LOW] = &sync_desc_guest_ESR_ELx_EC_IABT_LOW,
[ESR_ELx_EC_PC_ALIGN] = &sync_desc_guest_ESR_ELx_EC_PC_ALIGN,
[ESR_ELx_EC_DABT_LOW] = &sync_desc_guest_ESR_ELx_EC_DABT_LOW,
[ESR_ELx_EC_SP_ALIGN] = &sync_desc_guest_ESR_ELx_EC_SP_ALIGN,
[ESR_ELx_EC_FP_EXC32] = &sync_desc_guest_ESR_ELx_EC_FP_EXC32,
[ESR_ELx_EC_FP_EXC64] = &sync_desc_guest_ESR_ELx_EC_FP_EXC64,
[ESR_ELx_EC_SERROR] = &sync_desc_guest_ESR_ELx_EC_SERROR,
[ESR_ELx_EC_HVC32] = &sync_desc_guest_ESR_ELx_EC_HVC32,
[ESR_ELx_EC_HVC64] = &sync_desc_guest_ESR_ELx_EC_HVC64,
[ESR_ELx_EC_SMC32] = &sync_desc_guest_ESR_ELx_EC_SMC32,
[ESR_ELx_EC_SMC64] = &sync_desc_guest_ESR_ELx_EC_SMC64,
};
这个就不一一解释了,主要来看几个比较重要的异常,看看它们是如何处理的,最后结合前面讲述的串一下总体流程
系统调用
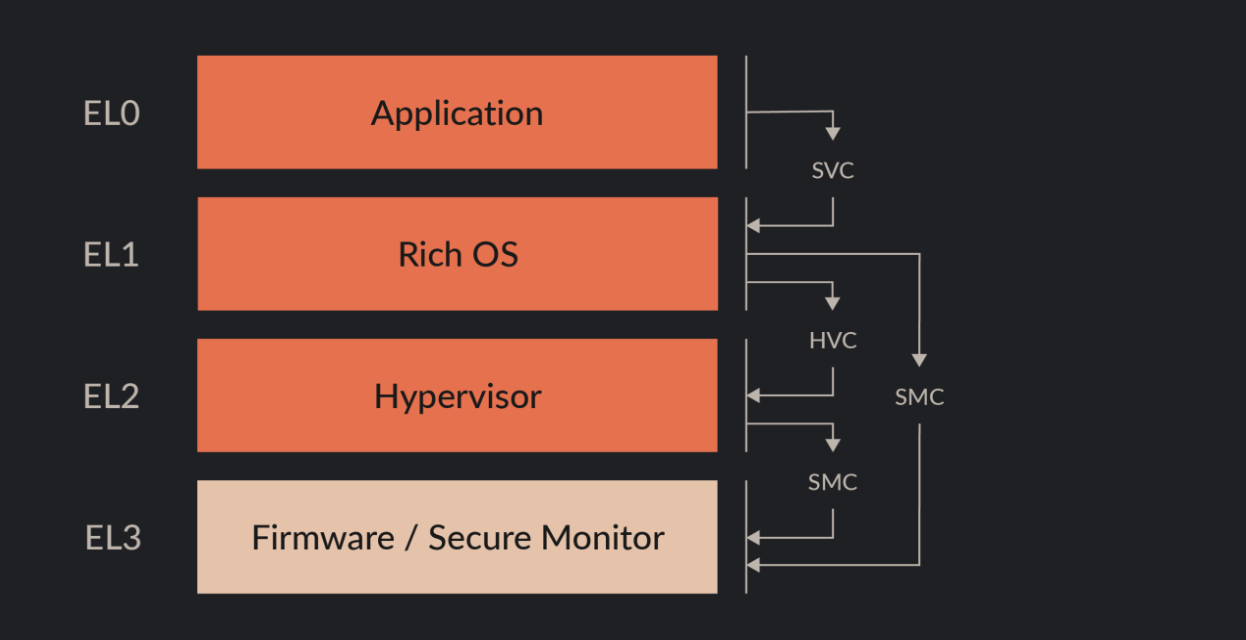
为什么分特权等级,很重要的一个原因就是为了安全,底层总是对上层保持不信任的态度。底层的一些核心功能不能直接交由上层来执行。上层只能发出请求,然后底层调用相关 handler 来帮忙处理,将结果返回给上层。
ARM 有 4 种特权等级,因此有了 3 种系统调用:SVC(Supervisor Call)、HVC(Hypervisor Call) 、SMC(Secure Monitor Call) 。通过上图,以及从名字上来看,SVC 就是请求 EL1 的服务,只能 EL0 调用;HVC 请求 EL2,之恶能 EL1 调用;SMC 请求 EL3,只能 EL1 和 EL2 调用。一般情况下是这样,但 ARM 比较灵活,EL2 也可以使用 SVC 指令,但是并不是请求 EL1 的服务,而是请求 EL2 它自己的服务
struct svc_desc {
char *name; // 服务名字
uint16_t type_start; // 服务号
uint16_t type_end; // 同服务号,目前 start、end 都只是表示服务号
svc_handler_t handler;
};
// 通过该宏定义一个 hvc 调用
#define DEFINE_HVC_HANDLER(n, start, end, h) \
static struct svc_desc __hvc_##h __used \
__section(".__hvc_handler") = { \
.name = n, \
.type_start = start, \
.type_end = end, \
.handler = h, \
}
// 两个例子
DEFINE_HVC_HANDLER("vm_hvc_handler", HVC_TYPE_VM0,
HVC_TYPE_VM0, vm_hvc_handler);
DEFINE_HVC_HANDLER("misc_hvc_handler", HVC_TYPE_MISC,
HVC_TYPE_MISC, misc_hvc_handler);
每个系统调用都有一个 svc_desc 描述符,记录了服务名字、服务号、handler。DEFINE_HVC_HANDLER 该宏定义一个静态全局的 svc_desc,并将它放在 __hvc_handler节里面。
在 boot 阶段解析 __hvc_handler 节来动态的加载服务例程:
// minos.ld.S
__hvc_handler_start = .;
.__hvc_handler : {
*(.__hvc_handler)
}
__hvc_handler_end = .;
. = ALIGN(8);
//.............................................
// svc_service.c
// 定义一系列的 svc_desc 指针,boot 阶段初始化
static struct svc_desc *smc_descs[SVC_STYPE_MAX];
static struct svc_desc *hvc_descs[SVC_STYPE_MAX];
static int __init_text svc_service_init(void)
{
pr_notice("parsing SMC/HVC handler\n");
parse_svc_desc((unsigned long)&__hvc_handler_start,
(unsigned long)&__hvc_handler_end, hvc_descs);
parse_svc_desc((unsigned long)&__smc_handler_start,
(unsigned long)&__smc_handler_end, smc_descs);
return 0;
}
// 解析 __hvc_handler/__smc_handler 节,注册服务例程到对应的 table
static void parse_svc_desc(unsigned long start, unsigned long end,
struct svc_desc **table)
{
struct svc_desc *desc;
int32_t j;
// 从 start 开始遍历每一个 svc_desc 描述符
section_for_each_item_addr(start, end, desc) {
BUG_ON((desc->type_start > desc->type_end) ||
(desc->type_end >= SVC_STYPE_MAX));
// 注册该 svc_desc 到 hvc_descs/smc_descs table
for (j = desc->type_start; j <= desc->type_end; j++) {
if (table[j])
pr_warn("overwrite SVC_DESC:%d %s\n", j,
desc->name);
table[j] = desc;
}
}
}
上述流程简述:
- 首先定义了一系列的 svc_desc 描述符,编译期间将它们存放在 __hvc_handler 节里面
- boot 阶段,解析 __hvc_handler 节,遍历每一个 svc_desc,将它们的信息记录到 hvc_descs table 里面
这样做的好处我能想到的就是动态加载,如果不需要某个服务例程,可以直接在编译期间就剔除,不将它们编译到镜像,但其实像 sync_descn 这种定义感觉也行呢。
__smc_handler 和 smc_descs 类似,它们的定义和初始化流程不再赘述。但有朋友可能疑惑,smc,secure monitor call,其服务例程应该定义在 EL3,minos 不是运行在 EL2 的 hypervisor 吗,为什么 EL2 也有 smc handler?这是因为 EL2 有能力 trap smc 指令,当 HCR_EL2.TSC = 1 时,smc 指令并不会 trap 到 EL3,而是 trap 到 EL2,由 EL2 处理。
了解了 svc_desc 定义之后,我们来看其处理流程:
// __sync_exception_from_lower_el -> sync_exception_from_lower_el
void sync_exception_from_lower_el(gp_regs *regs)
{
#ifdef CONFIG_VIRT
extern void handle_vcpu_sync_exception(gp_regs *regs);
/*
* check whether this task is a vcpu task or a normal
* userspace task.
* 1 - TGE bit means a normal task
* 2 - current->flags
*/
// HCR_EL2.TGE = 1 表示所有 trap 到 EL1 的异常都会 trap 到 EL2 处理
if ((current->flags & TASK_FLAGS_VCPU) && !(read_hcr_el2() & HCR_EL2_TGE))
handle_vcpu_sync_exception(regs);
else
#endif
handle_sync_exception(regs);
}
首先从 vector.S 中的 __sync_exception_from_lower_el 开始,表示从低特权等级来的一个异常。只有当前 cpu 上运行的是 vcpu 线程,cpu 上运行的是 guest os,一个异常才有可能来自低特权等级。HCR_EL2.TGE = 1 表示所有 trap 到 EL1 的异常都会 trap 到 EL2 处理,比如说用户态(EL0) 执行 svc 请求内核 (EL1) 的服务也会被 trap 到 EL2 处理,我们不应该是这种情况,trap 到 EL1 就直接让 EL1 自己处理,所以应该设置 HCR_EL2.TGE = 0
void handle_vcpu_sync_exception(gp_regs *regs)
{
int cpuid = smp_processor_id();
uint32_t esr_value;
int ec_type;
struct sync_desc *ec;
struct vcpu *vcpu = get_current_vcpu();
if ((!vcpu) || (vcpu->task->affinity != cpuid))
panic("this vcpu is not belong to the pcpu");
// 读取 ESR.ec 值,可以当作 exception number
esr_value = read_esr_el2();
ec_type = (esr_value & ESR_ELx_EC_MASK) >> ESR_ELx_EC_SHIFT;
if (ec_type >= ESR_ELx_EC_MAX) {
pr_err("unknown sync exception type from guest %d\n", ec_type);
goto out;
}
pr_debug("sync from lower EL, handle 0x%x\n", ec_type);
// 获取该 exception 对应的描述符
ec = guest_sync_descs[ec_type];
if (ec->irq_safe)
local_irq_enable();
// 返回地址修正
regs->pc += ec->ret_addr_adjust;
// 处理该异常
ec->handler(regs, ec_type, esr_value);
out:
local_irq_disable();
}
该函数从 ESR.ec 里面取出异常号,然后执行相应的 handler,对于 hvc handler 为 aarch64_hypercall_handler
int aarch64_hypercall_handler(gp_regs *reg, int ec, uint32_t esr_value)
{
struct vcpu *vcpu = get_current_vcpu();
struct arm_virt_data *arm_data = vcpu->vm->arch_data;
if (arm_data->hvc_handler)
return arm_data->hvc_handler(vcpu, reg, read_esr_el2());
else
return __arm_svc_handler(reg, 0);
}
static int __arm_svc_handler(gp_regs *reg, int smc)
{
uint32_t id;
unsigned long args[6];
// 第一个参数是服务号
id = reg->x0;
args[0] = reg->x1;
args[1] = reg->x2;
args[2] = reg->x3;
args[3] = reg->x4;
args[4] = reg->x5;
args[5] = reg->x6;
if (!(id & SVC_CTYPE_MASK))
local_irq_enable();
// 执行服务号对应的 handler
return do_svc_handler(reg, id, args, smc);
}
// 系统调用 handler
int do_svc_handler(gp_regs *regs, uint32_t svc_id, uint64_t *args, int smc)
{
uint16_t type;
struct svc_desc **table;
struct svc_desc *desc;
// 如果是 smc 调用,调用 smc handler,反之调用 hvc handler
if (smc)
table = smc_descs;
else
table = hvc_descs;
// 获取服务号
// bit[29:24] : service call ranges SVC_STYPE_XX
type = (svc_id & SVC_STYPE_MASK) >> 24;
if (unlikely(type > SVC_STYPE_MAX)) {
pr_err("Unsupported SVC type %d\n", type);
goto invalid;
}
// 获取该服务号对应的 svc_desc
desc = table[type];
if (unlikely(!desc))
goto invalid;
pr_debug("doing SVC Call %s:0x%x\n", desc->name, svc_id);
// 执行 handler
return desc->handler(regs, svc_id, args);
invalid:
SVC_RET1(regs, -EINVAL);
}
流程很简单,看注释应该能明白,这里不赘述,最后我们以 guest OS 调用 hvc 为例梳理一下系统调用的流程
hvc #xx
__sync_exception_from_lower_el
sync_exception_from_lower_el
handle_vcpu_sync_exception
esr_value = read_esr_el2(); //异常原因
ec_type = (esr_value & ESR_ELx_EC_MASK) >> ESR_ELx_EC_SHIFT; //异常号
ec = guest_sync_descs[ec_type]; //异常描述符
regs->pc += ec->ret_addr_adjust; //返回地址修正
ec->handler(regs, ec_type, esr_value); //异常处理
__arm_svc_handler
id = reg->x0; //服务号
do_svc_handler
type = (svc_id & SVC_STYPE_MASK) >> 24; //具体的服务号
desc = table[type]; //服务描述符
desc->handler(regs, svc_id, args); //执行该服务例程
minos 中还有一个特殊的系统调用,在调度 sys_sched() 中,底层实际上就是一个 svc #0 系统调用,这就是前面所说的例外,并不是说只有 EL0 才能使用 svc 来请求 EL1 的服务。EL2 也能使用 svc 指令,来调用 EL2 自己的一个服务例程。有了异常、系统调用的了解,我们再来回顾一下之前提到的调度:
svc #0 // EL2 下使用 svc 指令
__sync_exception_from_current_el // 来自当前特权级的异常
mrs x1, ESR_EL2 // 获取异常原因
ubfx x2, x1, #ESR_ELx_EC_SHIFT, #ESR_ELx_EC_WIDTH
cmp x2, #ESR_ELx_EC_SVC64 // 如果 x2 == ESR_ELx_EC_SVC64 表示一个 svc 指令
b.eq __sync_current_out // 跳去 __sync_current_out
exception_return
exception_return_handler
__exception_return_handler
pick_next_task // 调度策略挑选下一个 task
switch_to_task // 切换 task
因为 minos 目前在 EL2 中使用 svc 只有这么一种情况,所以直接在 vector.S 里面做了判断,并没有为其定义 svc_desc 描述符等,直接判断如果是 svc 指令那么就异常返回,在异常返回中执行调度操作。
- 首发公号:Rand_cs