# We are More than Our Joints: Predicting how 3D Bodies Move #paper
1. paper-info
1.1 Metadata
- Author:: [[Yan Zhang]], [[Michael J. Black]], [[Siyu Tang]]
- 作者机构::
- Keywords:: #HMP
- Journal:: #CVPR
- Date:: [[2021-04-02]]
- 状态:: #Done
1.2. Abstract
A key step towards understanding human behavior is the prediction of 3D human motion. Successful solutions have many applications in human tracking, HCI, and graphics. Most previous work focuses on predicting a time series of future 3D joint locations given a sequence 3D joints from the past. This Euclidean formulation generally works better than predicting pose in terms of joint rotations. Body joint locations, however, do not fully constrain 3D human pose, leaving degrees of freedom undefined, making it hard to animate a realistic human from only the joints. Note that the 3D joints can be viewed as a sparse point cloud. Thus the problem of human motion prediction can be seen as point cloud prediction. With this observation, we instead predict a sparse set of locations on the body surface that correspond to motion capture markers. Given such markers, we fit a parametric body model to recover the 3D shape and pose of the person. These sparse surface markers also carry detailed information about human movement that is not present in the joints, increasing the naturalness of the predicted motions. Using the AMASS dataset, we train MOJO, which is a novel variational autoencoder that generates motions from latent frequencies. MOJO preserves the full temporal resolution of the input motion, and sampling from the latent frequencies explicitly introduces high-frequency components into the generated motion. We note that motion prediction methods accumulate errors over time, resulting in joints or markers that diverge from true human bodies. To address this, we fit SMPL-X to the predictions at each time step, projecting the solution back onto the space of valid bodies. These valid markers are then propagated in time. Experiments show that our method produces state-of-the-art results and realistic 3D body animations. The code for research purposes is at https://yz-cnsdqz.github.io/MOJO/MOJO.html
2. Introduction
- 领域:
human motion prediction - 问题:
- 之前的方法大多数都不能生成真实的人体3D动作序列
- 之前的方法:
- 之前的方法大多数使用人体骨架(利用人体关节点)去预测。
- 通过关节位置的稀疏集去预测未来的动作序列忽略了人体的其他自由度。
- 通过关节点预测出来的人体骨架往往对应不可用的人体结构。
- 骨架不能够表示人体动作的细节。
- 作者的方法:
MOJO(More than Our Joints)- We propose a marker-based representation for bodies in motion, which provides more constraints than the body skeleton and hence benefits 3D body recovery.
- We design a new CVAE with a latent DCT space to improve motion modelling.
- We propose a recursive projection scheme to preserve valid bodies at test time.
3. Method
3.1 Preliminaries
SMPL-X body mesh model
可以将人体参数集转换成真实的人体结构。
body parameter set :\(\Theta\)
在\(\Theta\)中包括
global translation\(t \in \mathbb{R} ^3\)global orientation\(R \in \mathbb{R}^6\)body shape\(\beta \in \mathbb{R}^{10}\)body pose\(\theta \in \mathbb{R}^{32}\)in the VPoser latent spacehand pose\(\theta^h \in \mathbb{R}^{24}\)in the MANO PCA space
Diversifying latent flows(DLow)
3.2 Human Motion Representation
input sequence:\(X := \{x_t\}_{t=0}^M; x \in \mathbb{R}^V\)
prediction sequence:\(Y:=\{y_t\}_{t=0}^N; y_{0} = x_{M+1}\)
3.3. Motion Generator with Latent Frequencies
Architeectures

Figure 1. 网络结构
Source: http://arxiv.org/abs/2012.00619
Training with robust Kullback-leibler divergence
\[\begin{aligned} \mathcal{L} &=\mathbb{E}_{\boldsymbol{Y}}\left[\left|\boldsymbol{Y}-\boldsymbol{Y}^{r e c}\right|\right]+\alpha \mathbb{E}_{\boldsymbol{Y}}\left[\left|\Delta \boldsymbol{Y}-\Delta \boldsymbol{Y}^{r e c}\right|\right] \\ &+\Psi(K L D(q(\boldsymbol{Z} \mid \boldsymbol{X}, \boldsymbol{Y}) \| \mathcal{N}(0, \boldsymbol{I})))) \end{aligned} \]损失函数由三部分构成:
- 重构误差
- 速度重构误差
latent distribution regularization
Sampling from the latent DCT space
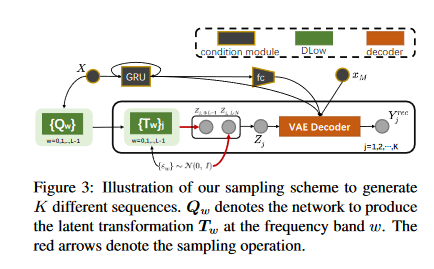
Figure 2. 采样过程
Source: http://arxiv.org/abs/2012.00619
3.4. Recursive Projection to the Valid Body Space
由于RNN的误差累计,导致预测的人体表面标记偏离有效的3D body,作者利用了有效物体位于欧几里得标记空间中的低维流形上的事实。每当 RNN 执行预测步骤时,解决方案往往会离开这个流形。因此,在每个预测步骤中,我们通过将 SMPL-X 身体网格拟合到预测标记,将预测标记投影回该流形。由于标记提供了丰富的身体约束,并且我们开始接近解决方案,因此拟合过程是有效的。
Instead, we exploit the fact that valid bodies lie on a lowdimensional manifold in the Euclidean space of markers. Whenever the RNN performs a prediction step, the solution tends to leave this manifold. Therefore, at each prediction step, we project the predicted markers back to that manifold, by fitting a SMPL-X body mesh to the predicted markers. Since markers provide rich body constraints, and we start close to the solution, the fitting process is efficiently.
该过程只在推理阶段使用。
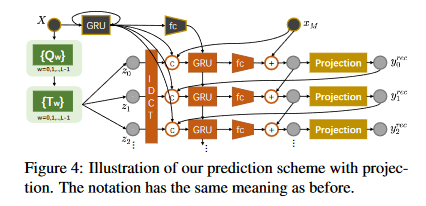
Figure 3. prediction scheme with projection
Source: http://arxiv.org/abs/2012.00619
总结
该方法利用人体表面的标记点来学习,预测未来动作序列,能够更好的与真实人体结构相匹配。利用CVAE+DCT的模型来提高模型的泛化能力。并且能够将学习到的人体表面标记转化成真实的3D人体结构。
里面有很多知识点不理解,需要查看的论文还有很多。
标签:02,body,Move,04,boldsymbol,prediction,motion,human,3D From: https://www.cnblogs.com/guixu/p/16802355.html