论文提出CeiT混合网络,结合了CNN在提取低维特征方面的局部性优势以及Transformer在建立长距离依赖关系方面的优势。CeiT在ImageNet和各种下游任务中达到了SOTA,收敛速度更快,而且不需要大量的预训练数据和额外的CNN蒸馏监督,值得借鉴
来源:晓飞的算法工程笔记 公众号
论文: Incorporating Convolution Designs into Visual Transformers

Introduction
在视觉领域中,纯Transformer架构往往需要大量的训练数据或额外的监督来达到与CNN相当的性能。为了克服这些限制,论文对直接使用Transformer架构的潜在缺点进行了分析,发现Transformer主要缺乏了CNN的平移不变性以及局部性。于是,论文将CNN在提取低维特征方面的局部性优势以及Transformer在建立长距离依赖关系方面的优势进行结合,提出了Convolution-enhanced image Transformer(CeiT)混合网络。
论文对原生Transformer做了三处修改:
- 设计了Image-to-Tokens(I2T)模块,从生成的低维特征中提取token序列,而不是将原始输入图像直接分割成token序列。
- 提出Locally-enchanced Feed-Forward(LeFF)层替换每个encoder中的feed-forward层,LeFF能够促进相邻token之间的相关性。
- 在Transformer的顶部附加Layer-wise Class token Attention(LCA),能够综合多层特征作为最终输出。
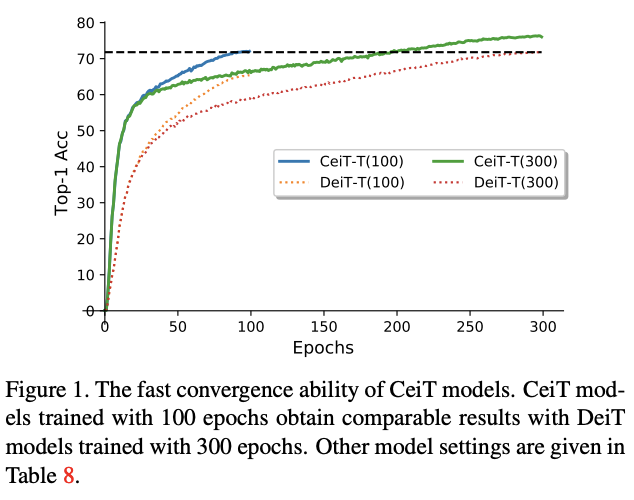
在ImageNet和七个下游任务的实验结果表明,CeiT的性能和泛化能力比之前的Transformer和CNN更优,而且不需要大量的训练数据和额外的CNN蒸馏。此外,CeiT模型的收敛性更好,训练迭代次数减少了3倍,极大地降低了训练成本。
Methodology
Image-to-Tokens with Low-level Features
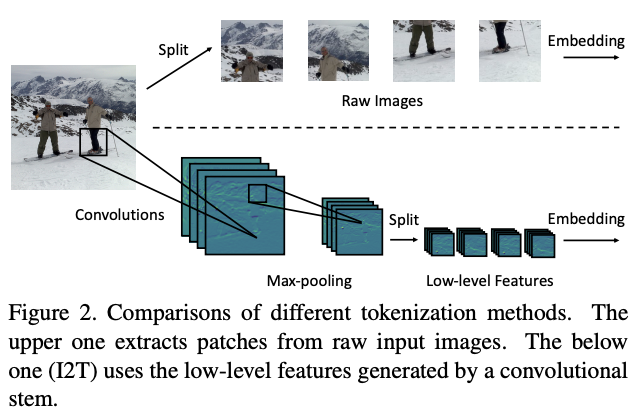
为了优化初始token序列的生成,论文提出了简单而有效的Imageto-Tokens(I2T)模块,从生成的低维特征中提取token序列,而不是将原始输入图像直接分割。如图2所示,I2T模块是由卷积层和最大池化层组成的轻量级stem结构,卷积层后面会进行BN操作。整个模块可表示为:
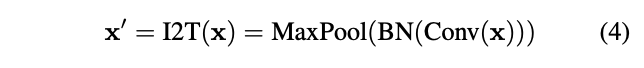
其中\(x^{'}\in \mathbb{R}^{\frac{H}{S}\times \frac{W}{S}\times D}\),\(S\)为卷积的stride参数,\(D\)为卷积输出的通道数。
在得到输出特征图后,根据空间维度从中切割图像块序列。为了保持生成的标记数量与ViT一致,论文将图像块的分辨率缩减为\((\frac{P}{S} ,\frac{P}{S})\),在实践中设定\(S = 4\)。最后,通过embedding操作将图像块序列转换为token序列。
I2T模块能够充分发挥CNN在提取低层次特征方面的优势,并且能够通过缩小图像块的大小来降低embedding的训练难度。与用ResNet-50来提取后两个阶段的高层特征的混合类型Transformer对比,I2T模块要轻量得多。
Locally-Enhanced Feed-Forward Network
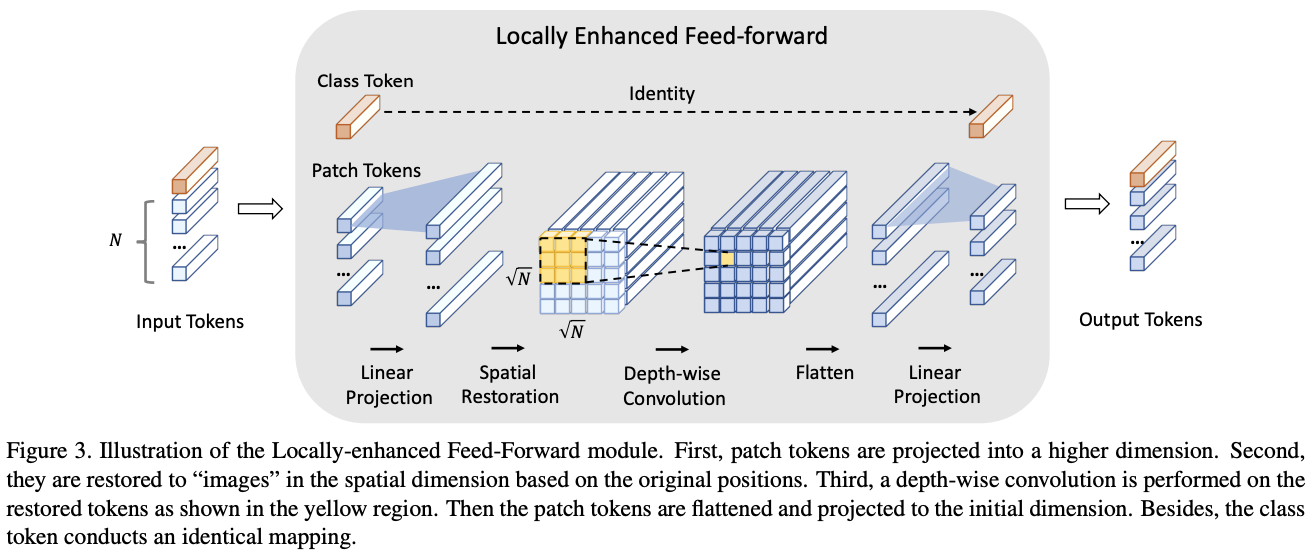
为了将CNN提取局部信息的优势与Transformer建立长距离依赖关系的能力相结合,论文提出了Locally-enhanced FeedForward Network(LeFF)层。在每个encoder模块中,保持MHSA模块不变来保留捕捉token间全局相似性的能力,将原来的前馈网络层用LeFF取代,LeFF的结构如图3。

LeFF模块的执行如公式5-11所示,每条公式对应以下一条处理:
- 定义MSA模块生成的输出为\(x^h_t \in\mathbb{R}^{(N+1)\times C}\),将其区分为图像token序列\(x^h_p\in \mathbb{R}^{N\times C}\)和一个class token \(x^h_c\in \mathbb{R}^C\)。
- 对图像token序列进行线性投影,扩展到更高维度的\(x^{l1}_p\in \mathbb{R}^{N\times (e×C)}\),其中\(e\)是扩展率。
- 根据相对于原始图像的位置,将图像token序列进行空间维度的还原,得到还原特征图\(x^s_p\in \mathbb{R}^{\sqrt{N}\times \sqrt{N}\times(e\times C)}\)。
- 对还原的特征图进行内核大小为\(k\)的深度卷积处理,增强每个token与相邻的\(k^2 - 1\)个token的特征相关性,得到增强特征图\(x^d_p\in \mathbb{R}^{\sqrt{N}\times \sqrt{N}\times(e\times C)}\)。
- 将还原特征图中拉平为\(x^f_p\in \mathbb{R}^{N\times (e\times C)}\)的序列。
- 将序列中的token映射回初始维度,得到最终的token序列\(x^{l2}_p\in \mathbb{R}^{N\times C}\),
- 将最终的token序列与class tken连接,得到最终输出\(x^{h+1}_t\in \mathbb{R}^{(N+1)\times C}\)。
需要注意,在每次线性投影和深度卷积之后,都会增加进行BatchNorm和GELU处理。
Layer-wise Class-Token Attention
在CNN中,特征图的感受域随着网络的加深而增加。在ViT中也有类似的现象,自注意计算范围随深度增加而增加。因此,特征的表达在不同层会有所不同。为了整合不同层的信息,论文设计了Layer-wise Class-token Attention(LCA)模块。标准的ViT只使用第\(L\)层(最后)的class token \(x^{(L)}_c\)作为最终特征,而LCA则综合不同层的class token作为最终特征。
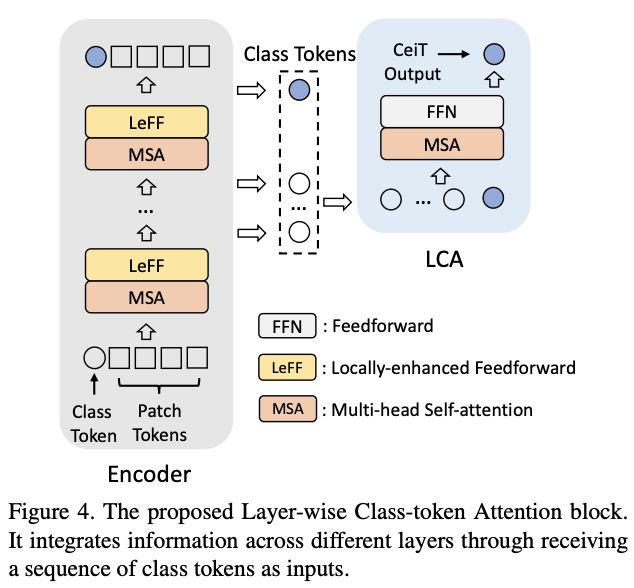
如图4所示,LCA将一串class token \(X_c = [x^{(1)}_c,\cdots,x^{(l)}_c,\cdots,x^{(L)}_c]\)作为输入,其中\(l\)表示层深度。LCA遵循Transformer block的标准实现,包含一个MSA和一个FFN层。LCA的MSA层只计算第\(L\)个class token \(x^{(L)}_c\)和其他class token之间的单向相似性,这样可以将计算复杂度从\(O(n^2)\)降低到\(O(n)\)。聚合后的\(x^{(L)}_c\)的对应值被送入FFN层,从而得到最终特征\(x^{(L)^{'}}_c\)。
Computational Complexity Analysis

论文设计了不同大小的CeiT模型,并对修改所带来的额外计算复杂性(以FLOPs为单位)进行了分析。一般来说,在计算成本略有增加的情况下,CeiT可以有效地结合CNN和Transformer的优势获得更高的性能和更好的收敛性,具体的计算复杂度分析可以看看原文。
Experiment

训练配置。
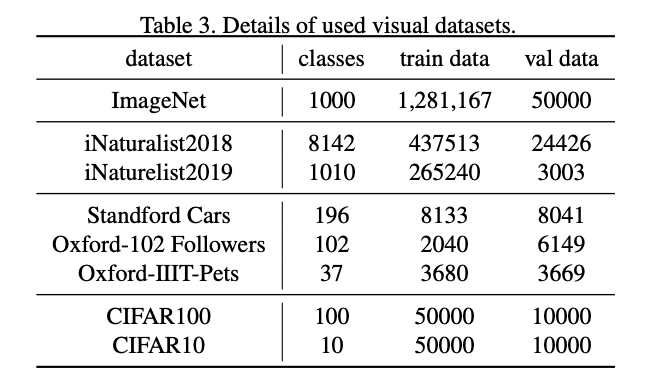
使用的数据集。

ImageNet结果。
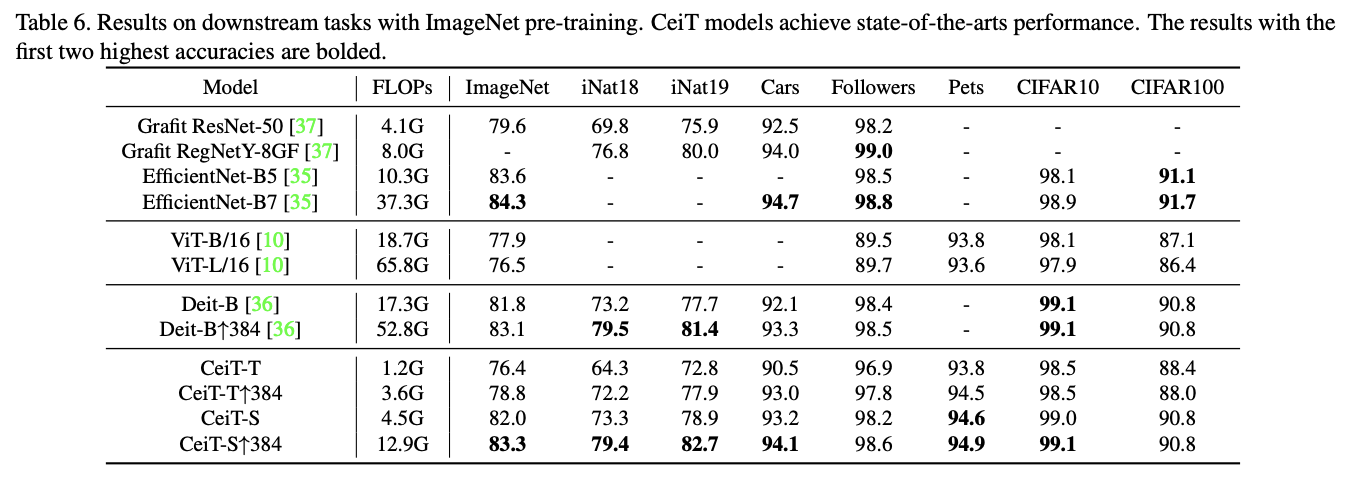
ImageNet预训练迁移结果。
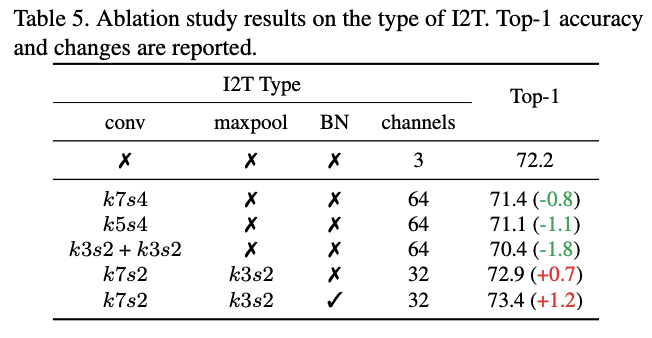
I2T模块参数的对比实验。
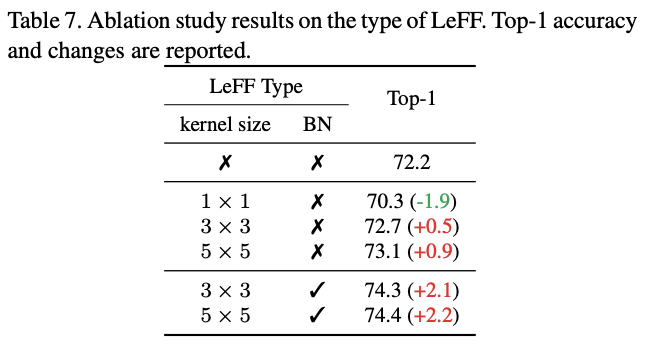
LeFF模块参数的对比实验。
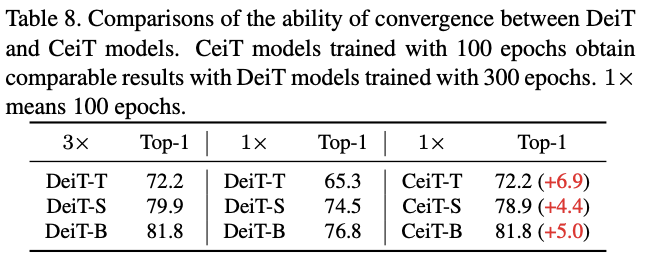
不同模型大小在不同周期下的收敛效果对比。
Conclusion
论文提出CeiT混合网络,结合了CNN在提取低维特征方面的局部性优势以及Transformer在建立长距离依赖关系方面的优势。CeiT在ImageNet和各种下游任务中达到了SOTA,收敛速度更快,而且不需要大量的预训练数据和额外的CNN蒸馏监督,值得借鉴。
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】
