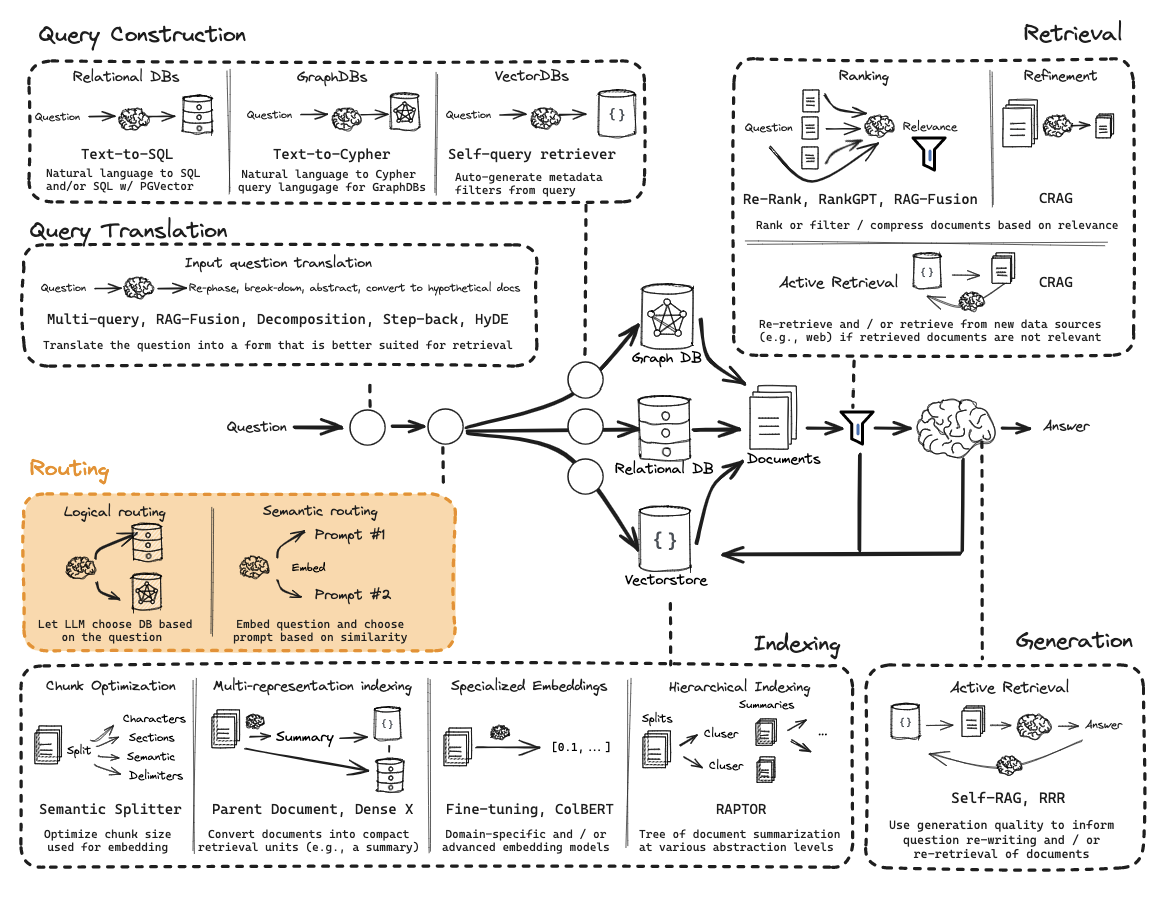
路由Routing
完成第一步Query Translation之后就要进入第二步Routing,Routing的意义在于根据不同的问题类型走不同的策略,比如关系型数据库走nl2sql查询,向量查询走索引向量数据库查询。
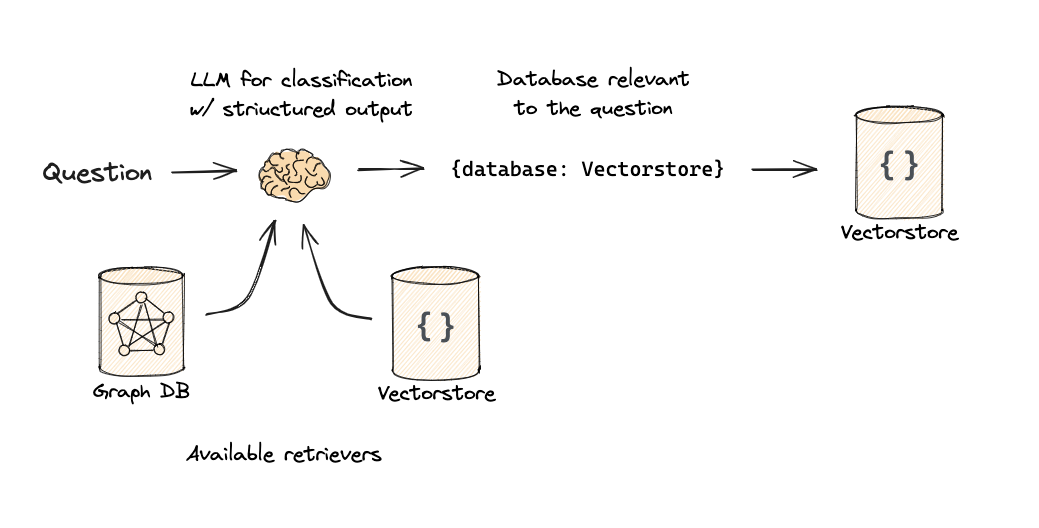
逻辑和语义路由 Logical and Semantic routing
使用函数调用进行分类
参考资料:
https://python.langchain.com/docs/expression_language/how_to/routing
https://smith.langchain.com/public/c2ca61b4-3810-45d0-a156-3d6a73e9ee2a/r
1from typing import Literal 2 3from langchain_core.prompts import ChatPromptTemplate 4from langchain_core.pydantic_v1 import BaseModel, Field 5from langchain_openai import ChatOpenAI 6 7# Data model 8class RouteQuery(BaseModel): 9 """Route a user query to the most relevant datasource.""" 10 11 datasource: Literal["python_docs", "js_docs", "golang_docs"] = Field( 12 ..., 13 description="Given a user question choose which datasource would be most relevant for answering their question", 14 ) 15 16# LLM with function call 17llm = ChatOpenAI(model="gpt-3.5-turbo-0125", temperature=0) 18structured_llm = llm.with_structured_output(RouteQuery) 19 20# Prompt 21system = """You are an expert at routing a user question to the appropriate data source. 22 23Based on the programming language the question is referring to, route it to the relevant data source.""" 24 25prompt = ChatPromptTemplate.from_messages( 26 [ 27 ("system", system), 28 ("human", "{question}"), 29 ] 30) 31 32# Define router 33router = prompt | structured_llm
注意:我们使用函数调用来产生结构化输出。

1question = """Why doesn't the following code work: 2 3from langchain_core.prompts import ChatPromptTemplate 4 5prompt = ChatPromptTemplate.from_messages(["human", "speak in {language}"]) 6prompt.invoke("french") 7""" 8 9result = router.invoke({"question": question}) 10#result.datasource -> 'python_docs' 11def choose_route(result): 12 if "python_docs" in result.datasource.lower(): 13 ### Logic here 14 return "chain for python_docs" 15 elif "js_docs" in result.datasource.lower(): 16 ### Logic here 17 return "chain for js_docs" 18 else: 19 ### Logic here 20 return "golang_docs" 21 22from langchain_core.runnables import RunnableLambda 23 24full_chain = router | RunnableLambda(choose_route) 25full_chain.invoke({"question": question}) 26# 'chain for python_docs' 27
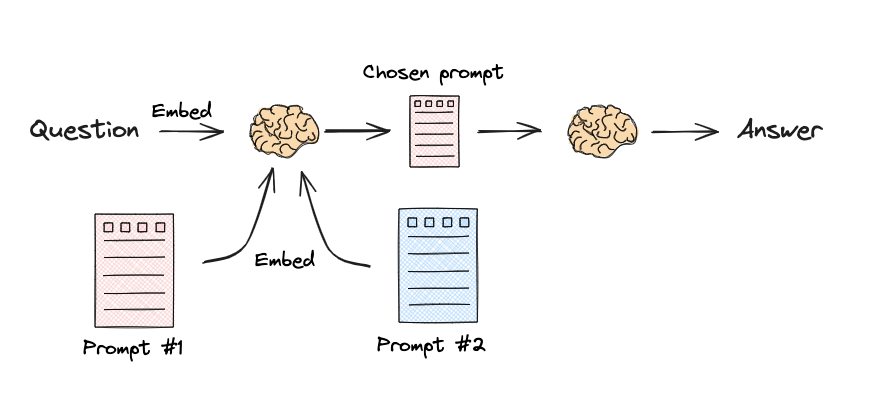
语义路由 Semantic routing
参考资料:
https://python.langchain.com/docs/expression_language/cookbook/embedding_router
https://smith.langchain.com/public/98c25405-2631-4de8-b12a-1891aded3359/r
1from langchain.utils.math import cosine_similarity 2from langchain_core.output_parsers import StrOutputParser 3from langchain_core.prompts import PromptTemplate 4from langchain_core.runnables import RunnableLambda, RunnablePassthrough 5from langchain_openai import ChatOpenAI, OpenAIEmbeddings 6 7# Two prompts 8physics_template = """You are a very smart physics professor. \ 9You are great at answering questions about physics in a concise and easy to understand manner. \ 10When you don't know the answer to a question you admit that you don't know. 11 12Here is a question: 13{query}""" 14 15math_template = """You are a very good mathematician. You are great at answering math questions. \ 16You are so good because you are able to break down hard problems into their component parts, \ 17answer the component parts, and then put them together to answer the broader question. 18 19Here is a question: 20{query}""" 21 22# Embed prompts 23embeddings = OpenAIEmbeddings() 24prompt_templates = [physics_template, math_template] 25prompt_embeddings = embeddings.embed_documents(prompt_templates) 26 27# Route question to prompt 28def prompt_router(input): 29 # Embed question 30 query_embedding = embeddings.embed_query(input["query"]) 31 # Compute similarity 32 similarity = cosine_similarity([query_embedding], prompt_embeddings)[0] 33 most_similar = prompt_templates[similarity.argmax()] 34 # Chosen prompt 35 print("Using MATH" if most_similar == math_template else "Using PHYSICS") 36 return PromptTemplate.from_template(most_similar) 37 38 39chain = ( 40 {"query": RunnablePassthrough()} 41 | RunnableLambda(prompt_router) 42 | ChatOpenAI() 43 | StrOutputParser() 44) 45 46print(chain.invoke("What's a black hole"))
输出:
1Using PHYSICS 2A black hole is a region in space where the gravitational pull is so strong that nothing, not even light, can escape from it. It is formed when a massive star collapses in on itself. The boundary surrounding a black hole is called the event horizon. Beyond the event horizon, the gravitational pull is so intense that even time and space are distorted. Black holes are some of the most mysterious and fascinating objects in the universe.
结构化查询 Query Construction
参考资料
元数据过滤器的查询结构 Query structuring for metadata filters
许多矢量存储包含元数据字段。这使得可以根据元数据过滤特定块成为可能。
参考资料:https://python.langchain.com/docs/use_cases/query_analysis/techniques/structuring

1from langchain_community.document_loaders import YoutubeLoader 2 3docs = YoutubeLoader.from_youtube_url( 4 "https://www.youtube.com/watch?v=pbAd8O1Lvm4", add_video_info=True 5).load() 6 7docs[0].metadata
输出
1{'source': 'pbAd8O1Lvm4', 2 'title': 'Self-reflective RAG with LangGraph: Self-RAG and CRAG', 3 'description': 'Unknown', 4 'view_count': 11922, 5 'thumbnail_url': 'https://i.ytimg.com/vi/pbAd8O1Lvm4/hq720.jpg', 6 'publish_date': '2024-02-07 00:00:00', 7 'length': 1058, 8 'author': 'LangChain'}
假设我们已经建立了一个索引:
允许我们对每个文档的内容和标题进行非结构化搜索 并对查看次数、发布日期和长度使用范围过滤。
我们希望将自然语言转换为结构化搜索查询。我们可以为结构化搜索查询定义一个架构。
1import datetime 2from typing import Literal, Optional, Tuple 3from langchain_core.pydantic_v1 import BaseModel, Field 4 5class TutorialSearch(BaseModel): 6 """Search over a database of tutorial videos about a software library.""" 7 8 content_search: str = Field( 9 ..., 10 description="Similarity search query applied to video transcripts.", 11 ) 12 title_search: str = Field( 13 ..., 14 description=( 15 "Alternate version of the content search query to apply to video titles. " 16 "Should be succinct and only include key words that could be in a video " 17 "title." 18 ), 19 ) 20 min_view_count: Optional[int] = Field( 21 None, 22 description="Minimum view count filter, inclusive. Only use if explicitly specified.", 23 ) 24 max_view_count: Optional[int] = Field( 25 None, 26 description="Maximum view count filter, exclusive. Only use if explicitly specified.", 27 ) 28 earliest_publish_date: Optional[datetime.date] = Field( 29 None, 30 description="Earliest publish date filter, inclusive. Only use if explicitly specified.", 31 ) 32 latest_publish_date: Optional[datetime.date] = Field( 33 None, 34 description="Latest publish date filter, exclusive. Only use if explicitly specified.", 35 ) 36 min_length_sec: Optional[int] = Field( 37 None, 38 description="Minimum video length in seconds, inclusive. Only use if explicitly specified.", 39 ) 40 max_length_sec: Optional[int] = Field( 41 None, 42 description="Maximum video length in seconds, exclusive. Only use if explicitly specified.", 43 ) 44 45 def pretty_print(self) -> None: 46 for field in self.__fields__: 47 if getattr(self, field) is not None and getattr(self, field) != getattr( 48 self.__fields__[field], "default", None 49 ): 50 print(f"{field}: {getattr(self, field)}") 51 52from langchain_core.prompts import ChatPromptTemplate 53from langchain_openai import ChatOpenAI 54 55system = """You are an expert at converting user questions into database queries. \ 56You have access to a database of tutorial videos about a software library for building LLM-powered applications. \ 57Given a question, return a database query optimized to retrieve the most relevant results. 58 59If there are acronyms or words you are not familiar with, do not try to rephrase them.""" 60prompt = ChatPromptTemplate.from_messages( 61 [ 62 ("system", system), 63 ("human", "{question}"), 64 ] 65) 66llm = ChatOpenAI(model="gpt-3.5-turbo-0125", temperature=0) 67structured_llm = llm.with_structured_output(TutorialSearch) 68query_analyzer = prompt | structured_llm 69query_analyzer.invoke({"question": "rag from scratch"}).pretty_print()
输出:
1content_search: rag from scratch 2title_search: rag from scratch
1query_analyzer.invoke( 2 {"question": "videos on chat langchain published in 2023"} 3).pretty_print()
输出:
1content_search: chat langchain 2title_search: 2023 3earliest_publish_date: 2023-01-01 4latest_publish_date: 2024-01-01
1query_analyzer.invoke( 2 {"question": "videos that are focused on the topic of chat langchain that are published before 2024"} 3).pretty_print()
输出:
1content_search: chat langchain 2title_search: chat langchain 3earliest_publish_date: 2024-01-01
1query_analyzer.invoke( 2 { 3 "question": "how to use multi-modal models in an agent, only videos under 5 minutes" 4 } 5).pretty_print()
输出:
1content_search: multi-modal models agent 2title_search: multi-modal models agent 3max_length_sec: 300
索引Indexing
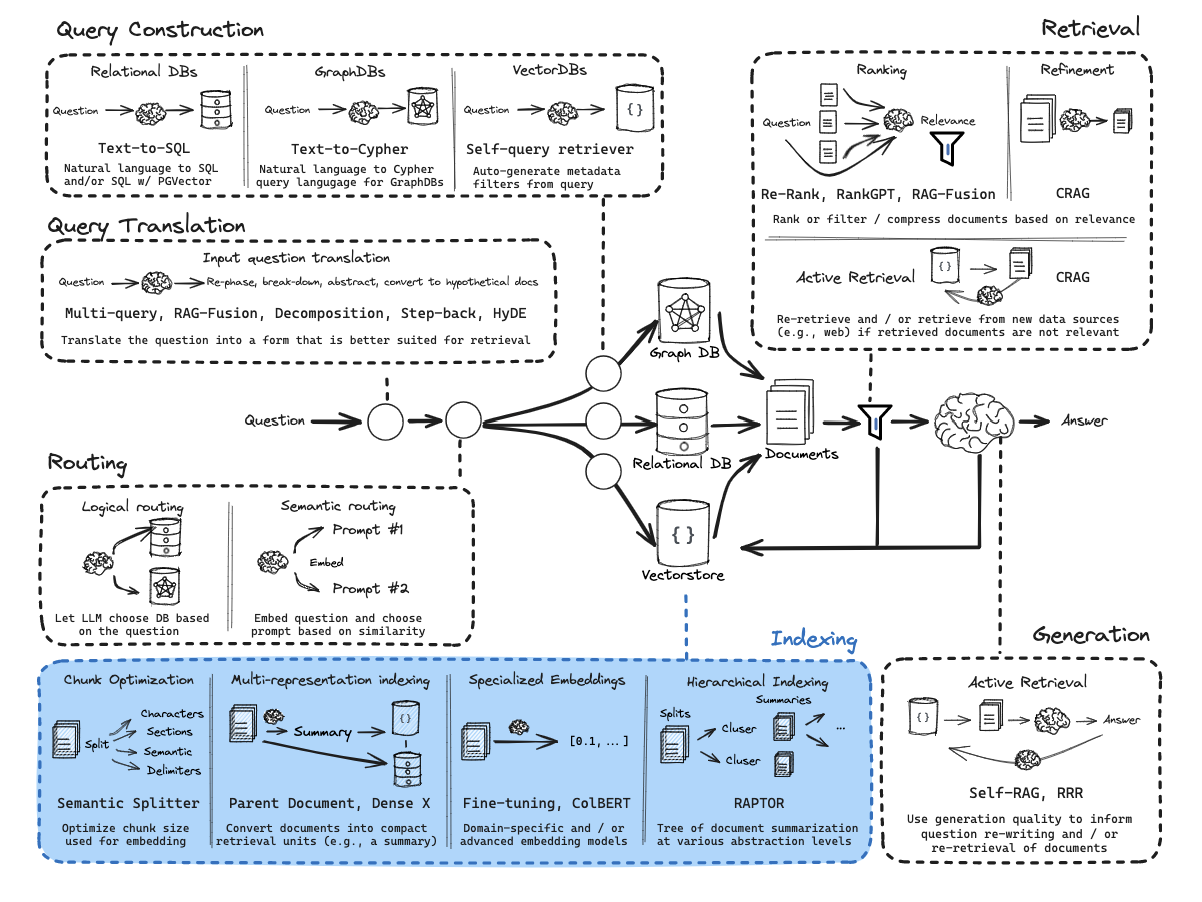
Multi-representation Indexing
参考资料:
Docs:
https://blog.langchain.dev/semi-structured-multi-modal-rag/
https://python.langchain.com/docs/modules/data_connection/retrievers/multi_vector
Paper:
1from langchain_community.document_loaders import WebBaseLoader 2from langchain_text_splitters import RecursiveCharacterTextSplitter 3 4loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/") 5docs = loader.load() 6 7loader = WebBaseLoader("https://lilianweng.github.io/posts/2024-02-05-human-data-quality/") 8docs.extend(loader.load()) 9 10import uuid 11 12from langchain_core.documents import Document 13from langchain_core.output_parsers import StrOutputParser 14from langchain_core.prompts import ChatPromptTemplate 15from langchain_openai import ChatOpenAI 16 17chain = ( 18 {"doc": lambda x: x.page_content} 19 | ChatPromptTemplate.from_template("Summarize the following document:\n\n{doc}") 20 | ChatOpenAI(model="gpt-3.5-turbo",max_retries=0) 21 | StrOutputParser() 22) 23 24summaries = chain.batch(docs, {"max_concurrency": 5}) 25 26from langchain.storage import InMemoryByteStore 27from langchain_openai import OpenAIEmbeddings 28from langchain_community.vectorstores import Chroma 29from langchain.retrievers.multi_vector import MultiVectorRetriever 30 31# The vectorstore to use to index the child chunks 32vectorstore = Chroma(collection_name="summaries", 33 embedding_function=OpenAIEmbeddings()) 34 35# The storage layer for the parent documents 36store = InMemoryByteStore() 37id_key = "doc_id" 38 39# The retriever 40retriever = MultiVectorRetriever( 41 vectorstore=vectorstore, 42 byte_store=store, 43 id_key=id_key, 44) 45doc_ids = [str(uuid.uuid4()) for _ in docs] 46 47# Docs linked to summaries 48summary_docs = [ 49 Document(page_content=s, metadata={id_key: doc_ids[i]}) 50 for i, s in enumerate(summaries) 51] 52 53# Add 54retriever.vectorstore.add_documents(summary_docs) 55retriever.docstore.mset(list(zip(doc_ids, docs))) 56 57query = "Memory in agents" 58sub_docs = vectorstore.similarity_search(query,k=1) 59sub_docs[0]
输出:
1Document(page_content='The document discusses the concept of building autonomous agents powered by Large Language Models (LLMs) as their core controllers. It covers components such as planning, memory, and tool use, along with case studies and proof-of-concept examples like AutoGPT and GPT-Engineer. Challenges like finite context length, planning difficulties, and reliability of natural language interfaces are also highlighted. The document provides references to related research papers and offers a comprehensive overview of LLM-powered autonomous agents.', metadata={'doc_id': 'cf31524b-fe6a-4b28-a980-f5687c9460ea'})
1retrieved_docs = retriever.get_relevant_documents(query,n_results=1) 2retrieved_docs[0].page_content[0:500]
输出:
1Number of requested results 4 is greater than number of elements in index 2, updating n_results = 2
1"\n\n\n\n\n\nLLM Powered Autonomous Agents | Lil'Log\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\nLil'Log\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\nPosts\n\n\n\n\nArchive\n\n\n\n\nSearch\n\n\n\n\nTags\n\n\n\n\nFAQ\n\n\n\n\nemojisearch.app\n\n\n\n\n\n\n\n\n\n LLM Powered Autonomous Agents\n \nDate: June 23, 2023 | Estimated Reading Time: 31 min | Author: Lilian Weng\n\n\n \n\n\nTable of Contents\n\n\n\nAgent System Overview\n\nComponent One: Planning\n\nTask Decomposition\n\nSelf-Reflection\n\n\nComponent Two: Memory\n\nTypes of Memory\n\nMaximum Inner Product Search (MIPS)\n\n"
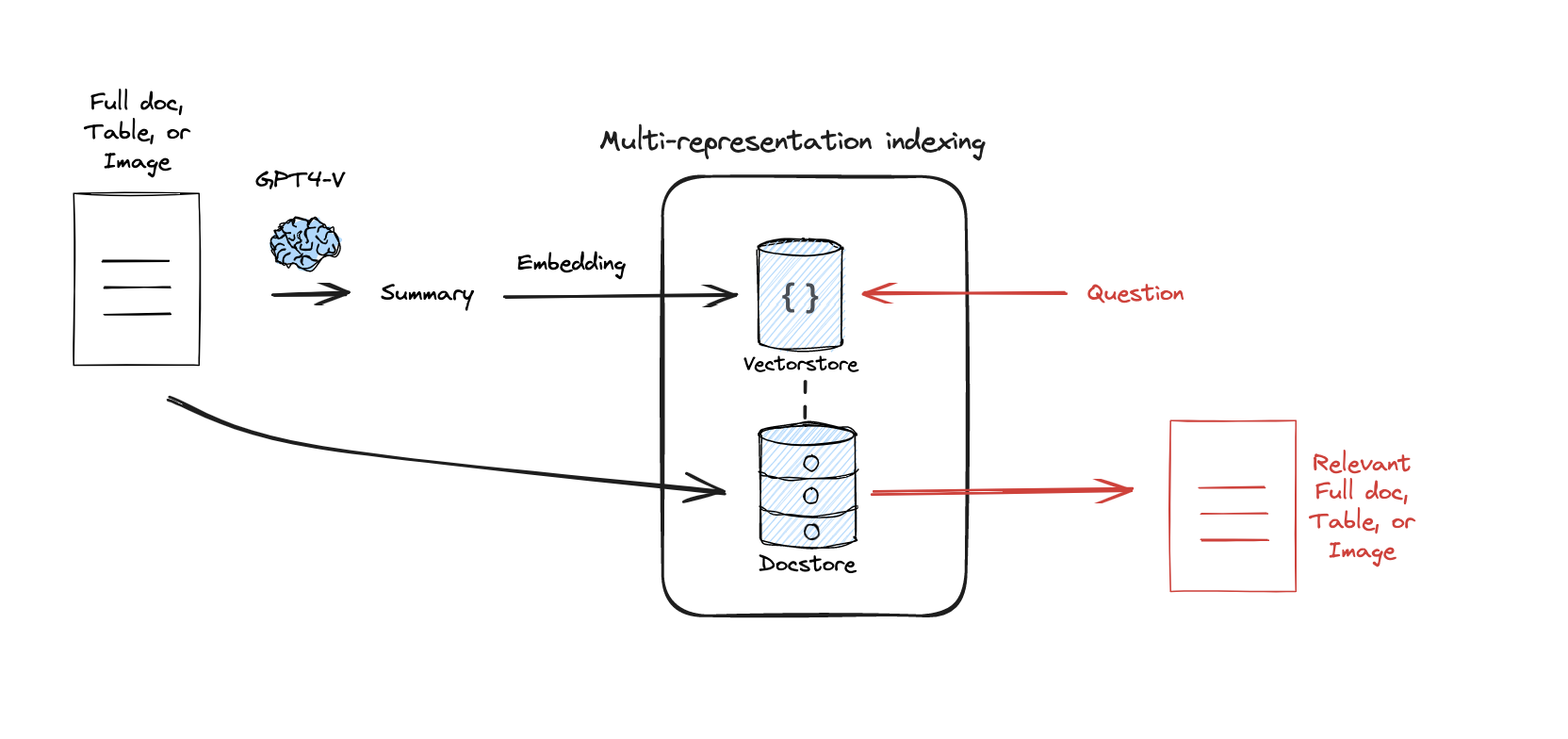
RAPTOR
参考资料:
Deep dive video:
https://www.youtube.com/watch?v=jbGchdTL7d0
Paper:
https://arxiv.org/pdf/2401.18059.pdf
Full code:
https://github.com/langchain-ai/langchain/blob/master/cookbook/RAPTOR.ipynb
ColBERT
RAGatouille 让 ColBERT 的使用变得非常简单。 ColBERT 为段落中的每个标记生成受上下文影响的向量。 ColBERT 类似地为查询中的每个标记生成向量。然后,每个文档的分数是每个查询嵌入与任何文档嵌入的最大相似度之和:
1from ragatouille import RAGPretrainedModel 2RAG = RAGPretrainedModel.from_pretrained("colbert-ir/colbertv2.0") 3 4import requests 5 6def get_wikipedia_page(title: str): 7 """ 8 Retrieve the full text content of a Wikipedia page. 9 10 :param title: str - Title of the Wikipedia page. 11 :return: str - Full text content of the page as raw string. 12 """ 13 # Wikipedia API endpoint 14 URL = "https://en.wikipedia.org/w/api.php" 15 16 # Parameters for the API request 17 params = { 18 "action": "query", 19 "format": "json", 20 "titles": title, 21 "prop": "extracts", 22 "explaintext": True, 23 } 24 25 # Custom User-Agent header to comply with Wikipedia's best practices 26 headers = {"User-Agent": "RAGatouille_tutorial/0.0.1 ([email protected])"} 27 28 response = requests.get(URL, params=params, headers=headers) 29 data = response.json() 30 31 # Extracting page content 32 page = next(iter(data["query"]["pages"].values())) 33 return page["extract"] if "extract" in page else None 34 35full_document = get_wikipedia_page("Hayao_Miyazaki") 36 37RAG.index( 38 collection=[full_document], 39 index_name="Miyazaki-123", 40 max_document_length=180, 41 split_documents=True, 42)
1results = RAG.search(query="What animation studio did Miyazaki found?", k=3) 2results
1retriever = RAG.as_langchain_retriever(k=3) 2retriever.invoke("What animation studio did Miyazaki found?")
Retrieval
Re-ranking
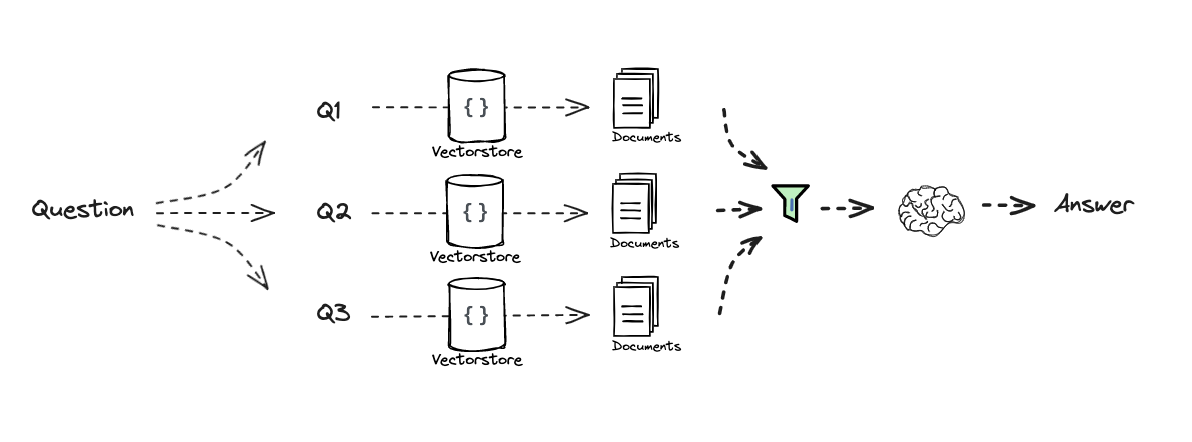
1#### INDEXING #### 2 3# Load blog 4import bs4 5from langchain_community.document_loaders import WebBaseLoader 6loader = WebBaseLoader( 7 web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",), 8 bs_kwargs=dict( 9 parse_only=bs4.SoupStrainer( 10 class_=("post-content", "post-title", "post-header") 11 ) 12 ), 13) 14blog_docs = loader.load() 15 16# Split 17from langchain.text_splitter import RecursiveCharacterTextSplitter 18text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder( 19 chunk_size=300, 20 chunk_overlap=50) 21 22# Make splits 23splits = text_splitter.split_documents(blog_docs) 24 25# Index 26from langchain_openai import OpenAIEmbeddings 27# from langchain_cohere import CohereEmbeddings 28from langchain_community.vectorstores import Chroma 29vectorstore = Chroma.from_documents(documents=splits, 30 # embedding=CohereEmbeddings() 31 embedding=OpenAIEmbeddings()) 32 33 34retriever = vectorstore.as_retriever() 35 36from langchain.prompts import ChatPromptTemplate 37 38# RAG-Fusion 39template = """You are a helpful assistant that generates multiple search queries based on a single input query. \n 40Generate multiple search queries related to: {question} \n 41Output (4 queries):""" 42prompt_rag_fusion = ChatPromptTemplate.from_template(template) 43 44from langchain_core.output_parsers import StrOutputParser 45from langchain_openai import ChatOpenAI 46 47generate_queries = ( 48 prompt_rag_fusion 49 | ChatOpenAI(temperature=0) 50 | StrOutputParser() 51 | (lambda x: x.split("\n")) 52) 53 54from langchain.load import dumps, loads 55 56def reciprocal_rank_fusion(results: list[list], k=60): 57 """ Reciprocal_rank_fusion that takes multiple lists of ranked documents 58 and an optional parameter k used in the RRF formula """ 59 60 # Initialize a dictionary to hold fused scores for each unique document 61 fused_scores = {} 62 63 # Iterate through each list of ranked documents 64 for docs in results: 65 # Iterate through each document in the list, with its rank (position in the list) 66 for rank, doc in enumerate(docs): 67 # Convert the document to a string format to use as a key (assumes documents can be serialized to JSON) 68 doc_str = dumps(doc) 69 # If the document is not yet in the fused_scores dictionary, add it with an initial score of 0 70 if doc_str not in fused_scores: 71 fused_scores[doc_str] = 0 72 # Retrieve the current score of the document, if any 73 previous_score = fused_scores[doc_str] 74 # Update the score of the document using the RRF formula: 1 / (rank + k) 75 fused_scores[doc_str] += 1 / (rank + k) 76 77 # Sort the documents based on their fused scores in descending order to get the final reranked results 78 reranked_results = [ 79 (loads(doc), score) 80 for doc, score in sorted(fused_scores.items(), key=lambda x: x[1], reverse=True) 81 ] 82 83 # Return the reranked results as a list of tuples, each containing the document and its fused score 84 return reranked_results 85 86question = "What is task decomposition for LLM agents?" 87retrieval_chain_rag_fusion = generate_queries | retriever.map() | reciprocal_rank_fusion 88docs = retrieval_chain_rag_fusion.invoke({"question": question}) 89len(docs)
1from operator import itemgetter 2from langchain_core.runnables import RunnablePassthrough 3 4# RAG 5template = """Answer the following question based on this context: 6 7{context} 8 9Question: {question} 10""" 11 12prompt = ChatPromptTemplate.from_template(template) 13 14llm = ChatOpenAI(temperature=0) 15 16final_rag_chain = ( 17 {"context": retrieval_chain_rag_fusion, 18 "question": itemgetter("question")} 19 | prompt 20 | llm 21 | StrOutputParser() 22) 23 24final_rag_chain.invoke({"question":question})
输出:
1'Task decomposition for LLM agents involves breaking down large tasks into smaller, manageable subgoals. This enables the agent to efficiently handle complex tasks by dividing them into smaller and simpler steps. Task decomposition can be achieved through techniques like Chain of Thought (CoT) and Tree of Thoughts, which prompt the model to think step by step and explore multiple reasoning possibilities at each step. Additionally, task decomposition can be done using simple prompting, task-specific instructions, or with human inputs.'
![]()
1from langchain_community.llms import Cohere 2from langchain.retrievers import ContextualCompressionRetriever 3from langchain.retrievers.document_compressors import CohereRerank 4 5from langchain.retrievers.document_compressors import CohereRerank 6 7retriever = vectorstore.as_retriever(search_kwargs={"k": 10}) 8 9# Re-rank 10compressor = CohereRerank() 11compression_retriever = ContextualCompressionRetriever( 12 base_compressor=compressor, base_retriever=retriever 13) 14 15compressed_docs = compression_retriever.get_relevant_documents(question)
Retrieval (CRAG)
参考资料:
1Deep Divehttps://www.youtube.com/watch?v=E2shqsYwxck
1Notebookshttps://github.com/langchain-ai/langgraph/blob/main/examples/rag/langgraph_crag.ipynb
https://github.com/langchain-ai/langgraph/blob/main/examples/rag/langgraph_crag_mistral.ipynb
Generation
Retrieval (Self-RAG)
参考资料:
https://github.com/langchain-ai/langgraph/tree/main/examples/rag
Impact of long context
原创声明:本文为本人原创作品,首发于AI ONES https://wuxiongwei.com,如果转载,请保留本文链接,谢谢。 标签:RAG,docs,question,langchain,下册,LangChain,https,query,import From: https://www.cnblogs.com/sunnywu/p/18172222参考资料:
1Deep divehttps://www.youtube.com/watch?v=SsHUNfhF32s
1Slides