论文提出了一种新的ViT位置编码CPE,基于每个token的局部邻域信息动态地生成对应位置编码。CPE由卷积实现,使得模型融合CNN和Transfomer的优点,不仅可以处理较长的输入序列,也可以在视觉任务中保持理想的平移不变性。从实验结果来看,基于CPE的CPVT比以前的位置编码方法效果更好
来源:晓飞的算法工程笔记 公众号
论文: Conditional Positional Encodings for Vision Transformers

Introduction
Transformer的自注意机制可以捕捉长距离的图像信息,根据图像内容动态地调整感受域大小。但自注意操作是顺序不变的,不能利用输入序列中的token顺序信息。为了让Transformer顺序可知,将位置编码加到输入的token序列中成为了常规操作,但这也为Tranformer带来两个比较大的问题:
- 虽然位置编码很有效,但会降低Transformer的灵活性。位置编码可以是可学习的,也可以是由不同频率的正弦函数直接生成的。如果需要输入更长的token序列,模型当前的位置编码以及权值都会失效,需要调整结构后再fine-tuning以保持性能。
- 加入位置编码后,绝对位置编码使得Transformer缺乏图像处理所需的平移不变性。如果采用相对位置编码,不仅带来额外的计算成本,还要修改Transformer的标准实现。而且在图像处理中,相对位置编码的效果没有绝对位置编码好。
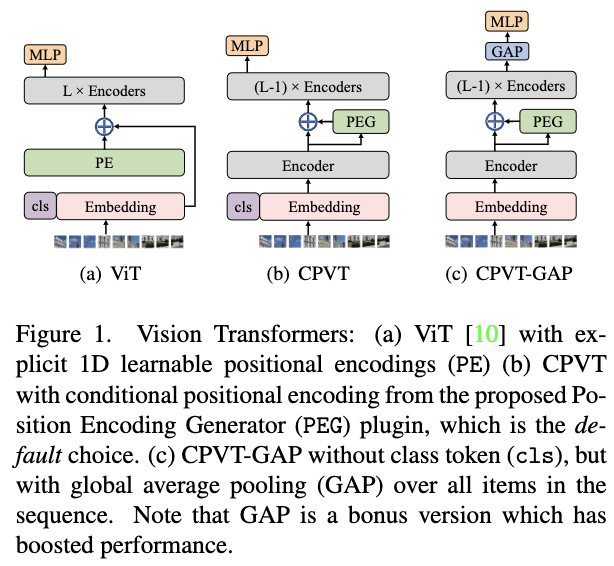
为了解决上述问题,论文提出了一个用于Vision Transformer的条件位置编码(CPE,conditional positional encoding)。与以往预先定义且输入无关的固定或可学习的位置编码不同,CPE是动态生成的,生成的位置编码中的每个值都与对应输入token的局部邻域相关。因此,CPE可以泛化到更长的输入序列,并且在图像分类任务中保持所需的平移不变性,从而提高分类精度。
CPE通过一个简单的位置编码生成器(PEG,position encoding generator)实现,可以无缝地融入当前的Transformer框架中。在PEG的基础上,论文提出了Conditional Position encoding Vision Transformer(CPVT),CPVT在ImageNet分类任务中达到了SOTA结果。
论文的贡献总结如下:
- 提出了一种新型的位置编码方案,条件位置编码(CPE)。CPE由位置编码生成器(PEG)动态生成,可以简单地嵌入到深度学习框架中,不涉及对Transformer的修改。
- CPE以输入token的局部邻域为条件生成对应的位置编码,可适应任意的输入序列长度,从而可以处理更大分辨率的图像。
- 相对于常见的绝对位置编码,CPE可以保持平移不变性,这有助于提高图像分类的性能。
- 在CPE的基础上,论文提出了条件位置编码ViT(CPVT),在ImageNet上到达了SOTA结果。
- 此外,论文还提供了class token的替代方案,使用平移不变的全局平均池(GAP)进行类别预测。通过GAP,CPVT可以实现完全的平移不变性,性能也因此进一步提高约1%。相比之下,基于绝对位置编码的模型只能从GAP中获得很小的性能提升,因为其编码方式本身已经打破了平移不变性。
Vision Transformer with Conditional Position Encodings
Motivations
在Vision Transformer中,尺寸为\(H\times W\)的输入图像被分割成\(N=\frac{HW}{S^2}\)个\(S×S\)的图像块,随后加上相同大小的可学习绝对位置编码向量。
论文认为常用的绝对位置编码有两个问题:
- 模型无法处理比训练序列更长的输入序列。
- 图像块平移后会对应新的位置编码,使得模型不具备平移不变性。

实际上,直接去掉位置编码就能将模型应用于长序列,但这种解决方案会丢失输入序列的位置信息,严重降低了性能。其次,可以像DeiT那样对位置编码进行插值,使其具有与长序列相同的长度。但这种方法需要对模型多做几次fine-tuning,否则性能也是会明显下降。对于高分辨率的输入,最完美的解决方案是在不进行任何fine-tuning的情况下,模型依然有显著的性能改善。
使用相对位置编码虽然可以解决上述两个问题,但不能提供任何绝对位置信息。有研究表明,绝对位置信息对分类任务也很重要。而在替换对比实验中,采用相对位置编码的模型性能也是较差的。
Conditional Positional Encodings
论文认为,一个完美的视觉任务的位置编码应该满足以下要求:
- 对输入序列顺序可知,但平移不变。
- 具有归纳能力,能够处理比训练时更长的序列。
- 能提供一定程度的绝对位置信息,这对性能非常重要。
经过研究,论文发现将位置编码表示为输入的局部领域关系表示,就能够满足上述的所有要求:
- 首先,它是顺序可知的,输入序列顺序也会影响到局部邻域的顺序。而输入图像中目标的平移可能不会改变其局部邻域的顺序,即平移不变性。
- 其次,模型可以应用更长的输入序列,因为每个位置编码都由对应token的局部邻域生成。
- 此外,它也可以表达一定程度的绝对位置信息。只要任意一个输入token的绝对位置是已知的(比如边界的零填充),所有其他token的绝对位置可以通过输入token之间的相互关系推断出来。
因此,论文提出了位置编码生成器(PEG),以输入token的局部邻域为条件,动态地产生位置编码。
-
Positional Encoding Generator
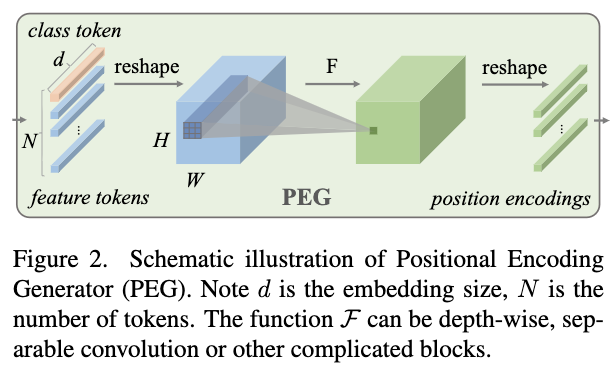
PEG的处理过程如图2所示。为了将局部领域作为条件,先将DeiT的输入序列\(X\in \mathbb{R}^{B\times N\times C}\)重塑为二维图像形状\(X^{'} \in\mathbb{R}^{B\times H\times W\times C}\),然后通过函数\(\mathcal{F}\)从\(X^{'}\)的局部图像中生成产生条件性位置编码\(E^{B\times H\times W\times C}\)。
PEG可以由一个核大小为\(k(k\ge 3)\)、零填充为\(\frac{k-1}{2}\)的二维卷积来实现。需要注意的是,零填充是为了位置编码包含绝对位置信息,从而提升模型性能。函数\(\mathcal{F}\)也可以是其它形式,如可分离卷积等。
Conditional Positional Encoding Vision Transformers

基于条件性位置编码,论文提出了条件位置编码Vision Transformer(CPVT),除了条件位置编码之外,其它完全遵循ViT和DeiT来设计。CPVT一共有三种尺寸:CPVT-Ti、CPVT-S和CPVT-B。
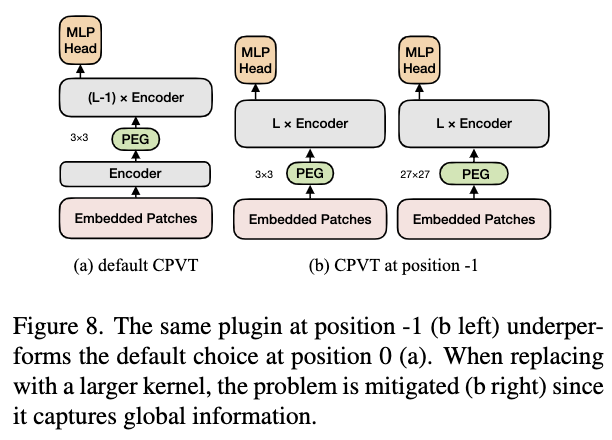
有趣的是,论文发现PEG的插入位置对性能也会有大影响。在第一个encoder之后插入的性能最佳,而不是直接在开头插入。
此外,DeiT和ViT都使用一个额外的可学习class token进行分类。但根据其结构设计,该token不是平移不变的,只能靠训练来尽可能学习平移不变性。一个简单的替代方法是直接换为全局平均池(GAP),因为GAP本身就是平移不变的。因此,论文也提出了CVPT-GAP,去掉class token,改为采用GAP输出进行预测。在与平移不变的位置编码配套使用时,CVPT-GAP是完全平移不变的,可以实现更好的性能。
Experiment
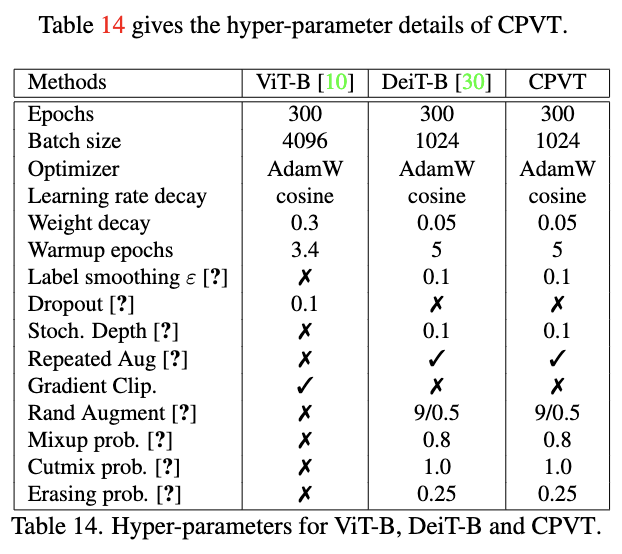
训练配置。
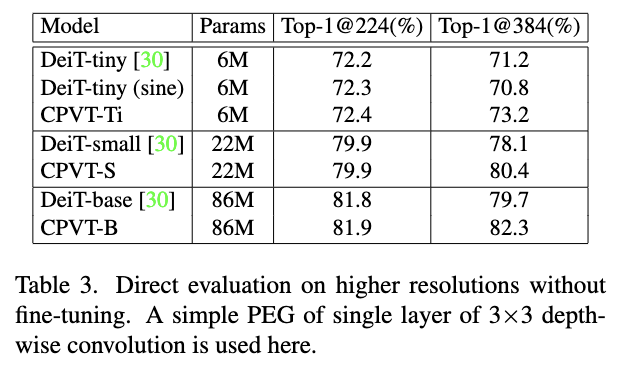
直接将224x224模型改为384x384输入进行测试。

class token与GAP的性能对比。
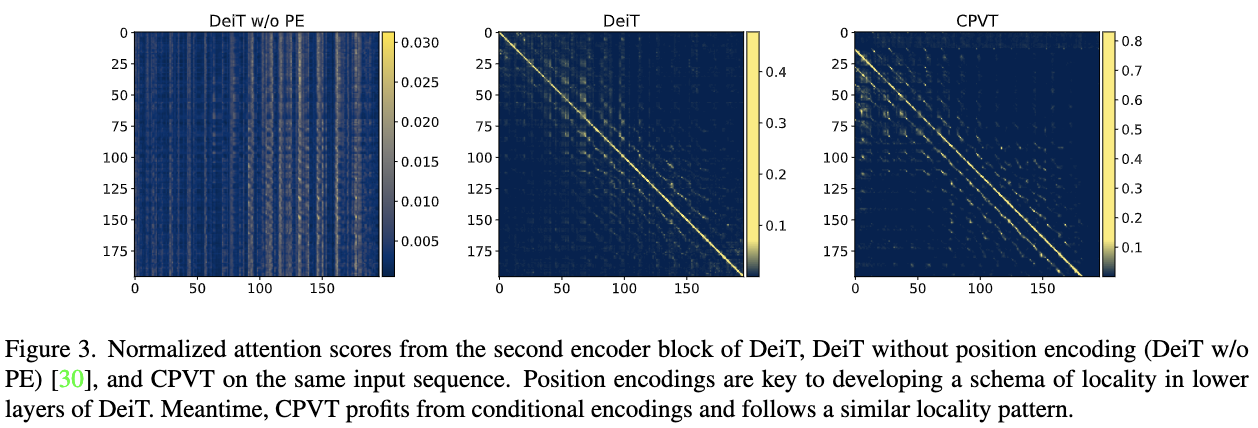
对第二个encoder的自注意力图进行可视化,CPVT的自注意力图明显更加多样化。
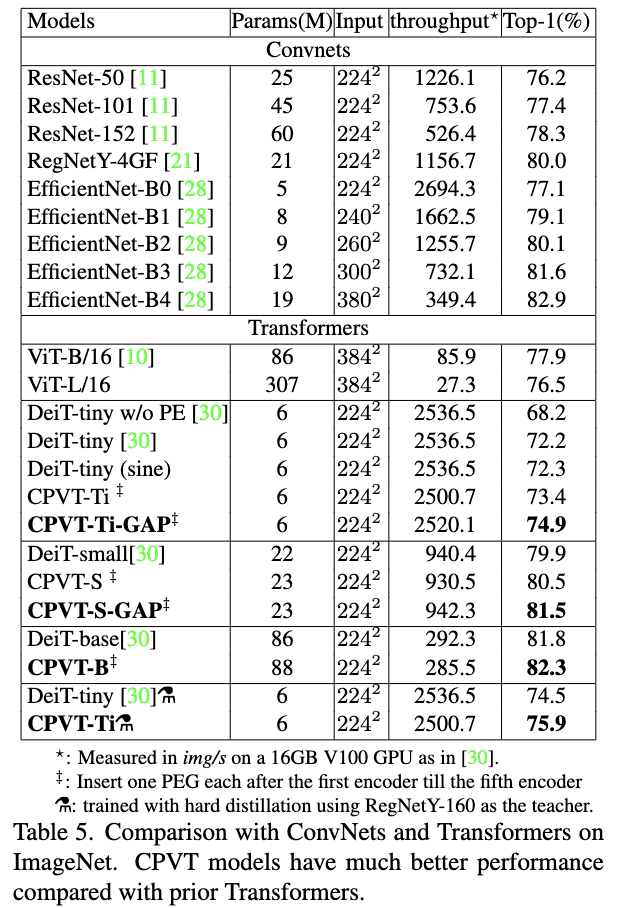
与SOTA网络进行对比,⚗为使用DeiT的蒸馏策略的结果。
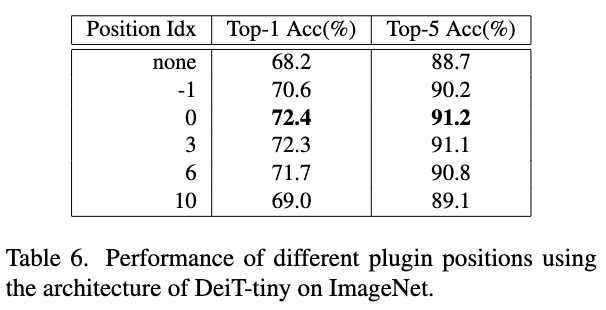
PEG插入位置对比,第一个encoder之后插入效果最好。
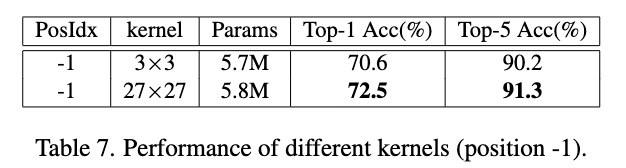
PEG的-1插入场景可能是由于原始图片需要更大的感受域,通过实验验证增大卷积核能显著提高性能。
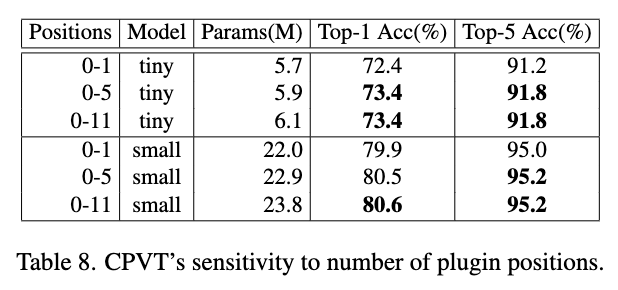
插入PEG个数的对比实验。
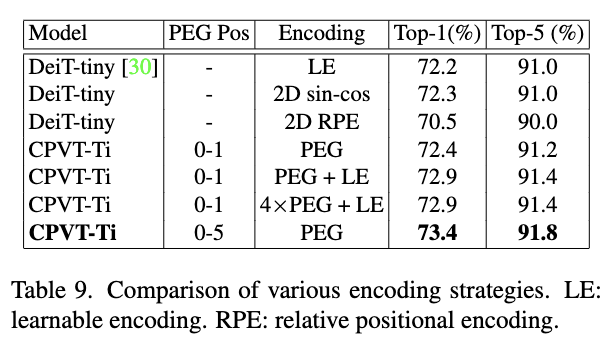
不同位置编码方式的对比实验。
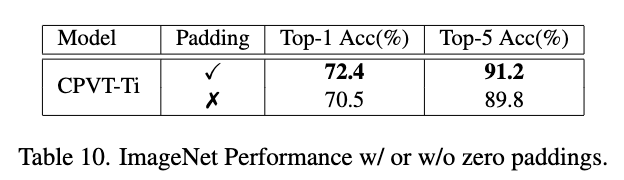
PEG生成位置编码时零填充的对比实验。
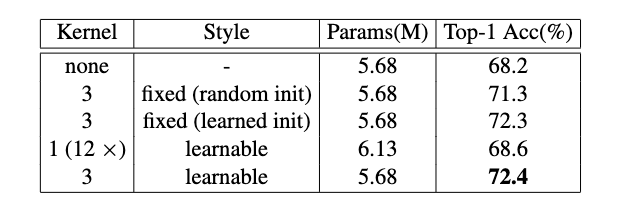
对PEG性能提升来源进行对比实验,PEG的确跟输入的领域关系有关,但跟卷积参数是否对应当前网络关系不大。

不同配置下的性能对比。

应用到PVT上的性能提升。
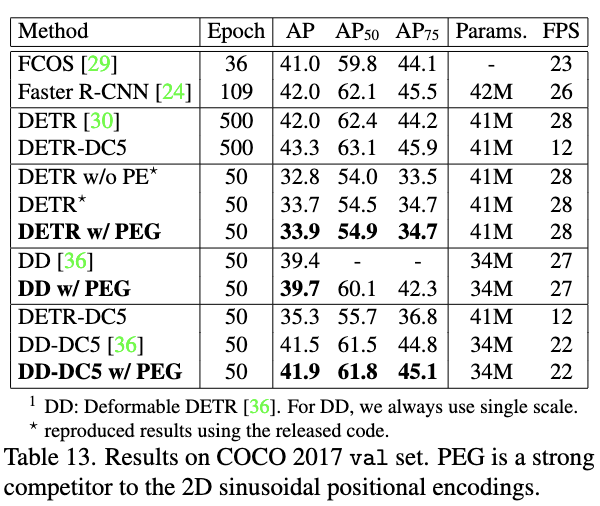
作为目标监测网络主干的性能对比。
Conclusion
论文提出了一种新的ViT位置编码CPE,基于每个token的局部邻域信息动态地生成对应位置编码。CPE由卷积实现,使得模型融合CNN和Transfomer的优点,不仅可以处理较长的输入序列,也可以在视觉任务中保持理想的平移不变性。从实验结果来看,基于CPE的CPVT比以前的位置编码方法效果更好。
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】
 。
。