Sparse稀疏检索介绍
在处理大规模文本数据时,我们经常会遇到一些挑战,比如如何有效地表示和检索文档,当前主要有两个主要方法,传统的文本BM25检索,以及将文档映射到向量空间的向量检索。
BM25效果是有上限的,但是文本检索在一些场景仍具备较好的鲁棒性和可解释性,因此不可或缺,那么在NN模型一统天下的今天,是否能用NN模型来增强文本检索呢,答案是有的,也就是我们今天要说的sparse 稀疏检索。
传统的BM25文本检索其实就是典型的sparse稀疏检索,在BM25检索算法中,向量维度为整个词表,但是其中大部分为0,只有出现的关键词或子词(tokens)有值,其余的值都设为零。这种表示方法不仅节省了存储空间,而且提高了检索效率。
向量的形式, 大概类似:
{
'19828': 0.2085,
'3508': 0.2374,
'7919': 0.2544,
'43': 0.0897,
'6': 0.0967,
'79299': 0.3079
}
key是term的编号,value是NN模型计算出来的权重。
稀疏向量与传统方法的比较
当前流行的sparse检索,大概是通过transformer模型,为doc中的term计算weight,这样与传统的BM25等基于频率的方法相比,sparse向量可以利用神经网络的力量,提高了检索的准确性和效率。BM25虽然能够计算文档的相关性,但它无法理解词语的含义或上下文的重要性。而稀疏向量则能够通过神经网络捕捉到这些细微的差别。
稀疏向量的优势
- 计算效率:稀疏向量在处理包含零元素的操作时,通常比密集向量更高效。
- 信息密度:稀疏向量专注于关键特征,而不是捕捉所有细微的关系,这使得它们在文本搜索等应用中更为高效。
- 领域适应性:稀疏向量在处理专业术语或罕见关键词时表现出色,例如在医疗领域,许多专业术语不会出现在通用词汇表中,稀疏向量能够更好地捕捉这些术语的细微差别。
稀疏向量举例
SPLADE 是一款开源的transformer模型,提供sparse向量生成,下面是效果对比,可以看到sparse介于BM25和dense之间,比BM25效果好。
| Model | MRR@10 (MS MARCO Dev) | Type |
|---|---|---|
| BM25 | 0.184 | Sparse |
| TCT-ColBERT | 0.359 | Dense |
| doc2query-T5 link | 0.277 | Sparse |
| SPLADE | 0.322 | Sparse |
| SPLADE-max | 0.340 | Sparse |
| SPLADE-doc | 0.322 | Sparse |
| DistilSPLADE-max | 0.368 | Sparse |
Sparse稀疏检索实践
模型介绍
国内的开源模型中,BAAI的BGE-M3提供sparse向量向量生成能力,我们用这个来进行实践。
BGE是通过RetroMAE的预训练方式训练的类似bert的预训练模型。
常规的Bert预训练采用了将输入文本随机Mask再输出完整文本这种自监督式的任务,RetroMAE采用一种巧妙的方式提高了Embedding的表征能力,具体操作是:将低掩码率的的文本A输入到Encoder种得到Embedding向量,将该Embedding向量与高掩码率的文本A输入到浅层的Decoder向量中,输出完整文本。这种预训练方式迫使Encoder生成强大的Embedding向量,在表征模型中提升效果显著。
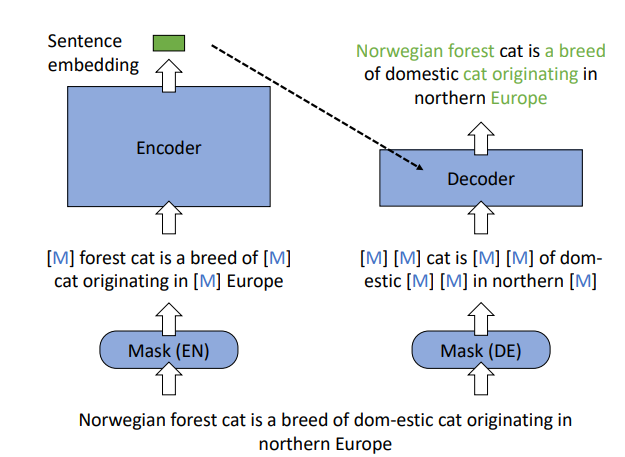
向量生成
-
先安装
!pip install -U FlagEmbedding
-
然后引入模型
from FlagEmbedding import BGEM3FlagModel
model = BGEM3FlagModel('BAAI/bge-m3', use_fp16=True)
编写一个函数用于计算embedding:
def embed_with_progress(model, docs, batch_size):
batch_count = int(len(docs) / batch_size) + 1
print("start embedding docs", batch_count)
query_embeddings = []
for i in tqdm(range(batch_count), desc="Embedding...", unit="batch"):
start = i * batch_size
end = min(len(docs), (i + 1) * batch_size)
if end <= start:
break
output = model.encode(docs[start:end], return_dense=False, return_sparse=True, return_colbert_vecs=False)
query_embeddings.extend(output['lexical_weights'])
return query_embeddings
然后分别计算query和doc的:
query_embeddings = embed_with_progress(model, test_sets.queries, batch_size)
doc_embeddings = embed_with_progress(model, test_sets.docs, batch_size)
然后是计算query和doc的分数,model.compute_lexical_matching_score(交集的权重相乘,然后累加),注意下面的代码是query和每个doc都计算了,计算量会比较大,在工程实践中需要用类似向量索引的方案(当前qdrant、milvus等都提供sparse检索支持)
# 检索topk
recall_results = []
import numpy as np
for i in tqdm(range(len(test_sets.query_ids)), desc="recall...", unit="query"):
query_embeding = query_embeddings[i]
query_id = test_sets.query_ids[i]
if query_id not in test_sets.relevant_docs:
continue
socres = [model.compute_lexical_matching_score(query_embeding, doc_embedding) for doc_embedding in doc_embeddings]
topk_doc_ids = [test_sets.doc_ids[i] for i in np.argsort(socres)[-20:][::-1]]
recall_results.append(json.dumps({"query": test_sets.queries[i], "topk_doc_ids": topk_doc_ids, "marked_doc_ids": list(test_sets.relevant_docs[query_id].keys())}))
# recall_results 写入到文件
with open("recall_results.txt", "w", encoding="utf-8") as f:
f.write("\n".join(recall_results))
最后,基于测试集,我们可以计算召回率:
import json
# 读取 JSON line 文件
topk_doc_ids_list = []
marked_doc_ids_list = []
with open("recall_results.txt", "r") as file:
for line in file:
data = json.loads(line)
topk_doc_ids_list.append(data["topk_doc_ids"])
marked_doc_ids_list.append(data["marked_doc_ids"])
# 计算 recall@k
def recall_at_k(k):
recalls = []
for topk_doc_ids, marked_doc_ids in zip(topk_doc_ids_list, marked_doc_ids_list):
# 提取前 k 个召回结果
topk = set(topk_doc_ids[:k])
# 计算交集
intersection = topk.intersection(set(marked_doc_ids))
# 计算 recall
recall = len(intersection) / min(len(marked_doc_ids), k)
recalls.append(recall)
# 计算平均 recall
average_recall = sum(recalls) / len(recalls)
return average_recall
# 计算 recall@5, 10, 20
recall_at_5 = recall_at_k(5)
recall_at_10 = recall_at_k(10)
recall_at_20 = recall_at_k(20)
print("Recall@5:", recall_at_5)
print("Recall@10:", recall_at_10)
print("Recall@20:", recall_at_20)
在测试集中,测试结果:
Recall@5: 0.7350086355785777
Recall@10: 0.8035261945883735
Recall@20: 0.8926130345462158
在这个测试集上,比BM25测试出来的结果要更好,但是仅凭这个尚不能否定BM25,需要综合看各自的覆盖度,综合考虑成本与效果。
参考
- Sparse Vectors in Qdrant: Pure Vector-based Hybrid Search https://qdrant.tech/articles/sparse-vectors/
- BGE(BAAI General Embedding)解读 https://zhuanlan.zhihu.com/p/690856333