生成式 AI 和大模型在 2024 年已经进入落地实践阶段。因此,围绕开发者在生成式应用程序开发中的主要痛点和需求,我们组织了这个 “Amazon Bedrock 实践” 的系列,希望可以帮助开发者高效地上手生成式 AI 和大模型的应用开发。本篇为第二篇(特别提示:本篇探讨的 Anthropic Claude 3 模型,目前仅在亚马逊云科技的海外账户可用)。
亚马逊云科技开发者社区为开发者们提供全球的开发技术资源。这里有技术文档、开发案例、技术专栏、培训视频、活动与竞赛等。帮助中国开发者对接世界最前沿技术,观点,和项目,并将中国优秀开发者或技术推荐给全球云社区。如果你还没有关注/收藏,看到这里请一定不要匆匆划过,点这里让它成为你的技术宝库!
在上一篇中,我们以 Claude 3 模型为例,探讨了如何使用 Amazon Bedrock 构建不同业务场景的生成式 AI 应用程序的实践开篇。在开篇中,我们介绍了如何在 Amazon Bedrock 中设置和获取模型访问权限、如何在 Amazon Bedrock 控制台中使用模型、以及如何调用 Amazon Bedrock API 来使用模型等基础内容。
本篇我们将继续深度探索 Claude 3 模型在三个不同行业场景的实践。这三个行业场景分别是:
-
工业场景:电路板缺陷检测实践
-
教育场景:辅助教学代码实践
-
金融场景:公开市场信息增强搜索问答实践
工业场景:电路板缺陷检测实践
本章将以一个动手实验的完整流程,演示如何使用 Claude 3 模型进行工业场景的电路板缺陷检测。
图 1 展示了是常见的电路板缺陷,例如:缺少孔洞 (Missing hole)、老鼠啃咬痕迹 (Mouse bite)、开路 (Open circuit)、短路 (Short)、多余铜皮 (Spur)、飞铜 (Spurious copper) 等。
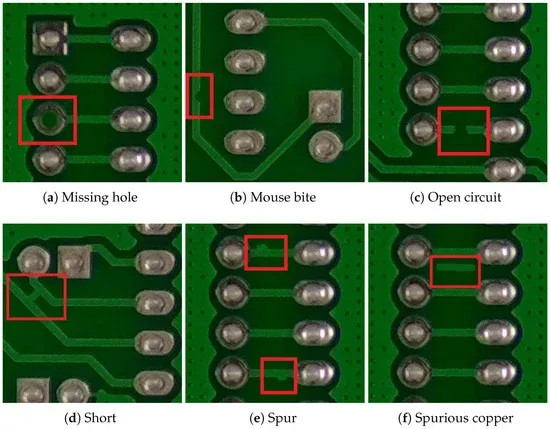
图1: 常见的电路板缺陷
图 2 展示了一块没有缺陷的正常电路板。

图2: 没有缺陷的正常电路板
图 3 展示了一块有“缺陷”的电路板。这个“缺陷”是我们故意在图上添加的绿色条段,以模拟电路板上“多余铜皮 (Spur)” 的缺陷场景。如下所示:

图3: 有多余铜皮 (Spur) 的缺陷电路板
我们计划使用的提示词如下:
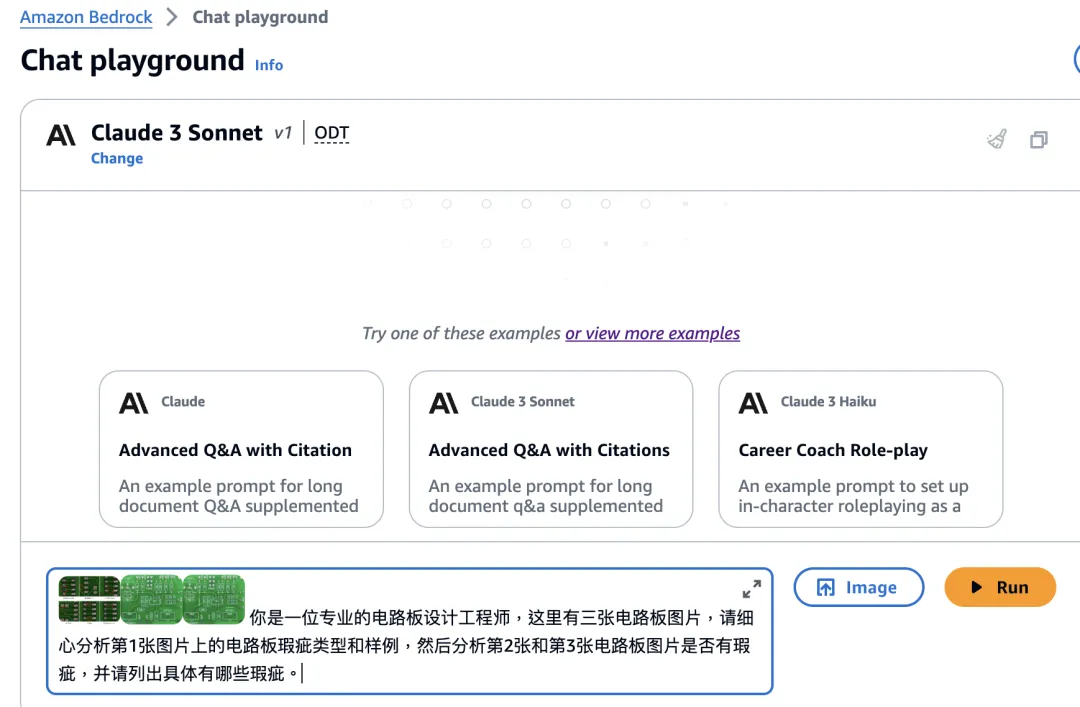
“你是一位专业的电路板设计工程师,这里有三张电路板图片,请细心分析第 1 张图片上的电路板瑕疵类型和样例,然后分析第 2 张和第 3 张电路板图片是否有瑕疵,并请列出具体有哪些瑕疵。”
我们将这三张图片和以上提示词,通过 Amazon Bedrock 的 Chat playground 提交给 Claude 3 Sonnet 模型,如下图所示:
数秒后,Claude 3 Sonnet 模型的输出结果如下:
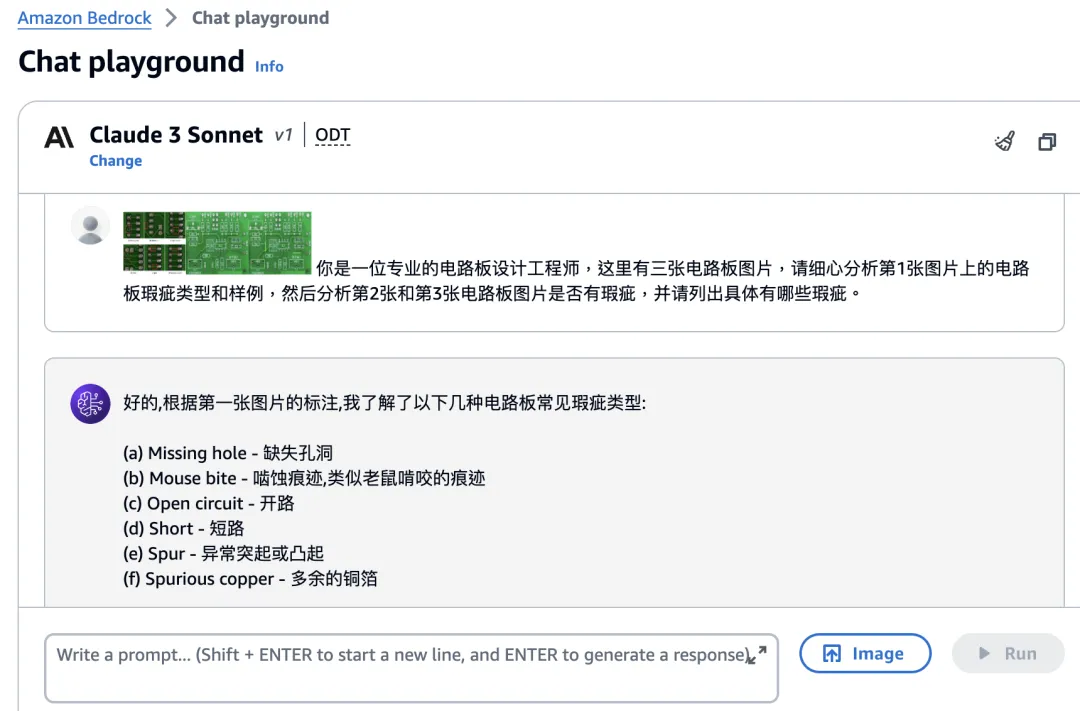
为了方便读者阅读,我们将 Claude 3 Sonnet 模型输出的文字结果复制出来,显示如下:
“好的,根据第一张图片的标注,我了解了以下几种电路板常见瑕疵类型:
(a) Missing hole - 缺失孔洞
(b) Mouse bite - 啮蚀痕迹,类似老鼠啃咬的痕迹
(c) Open circuit - 开路
(d) Short - 短路
(e) Spur - 异常突起或凸起
(f) Spurious copper - 多余的铜箔
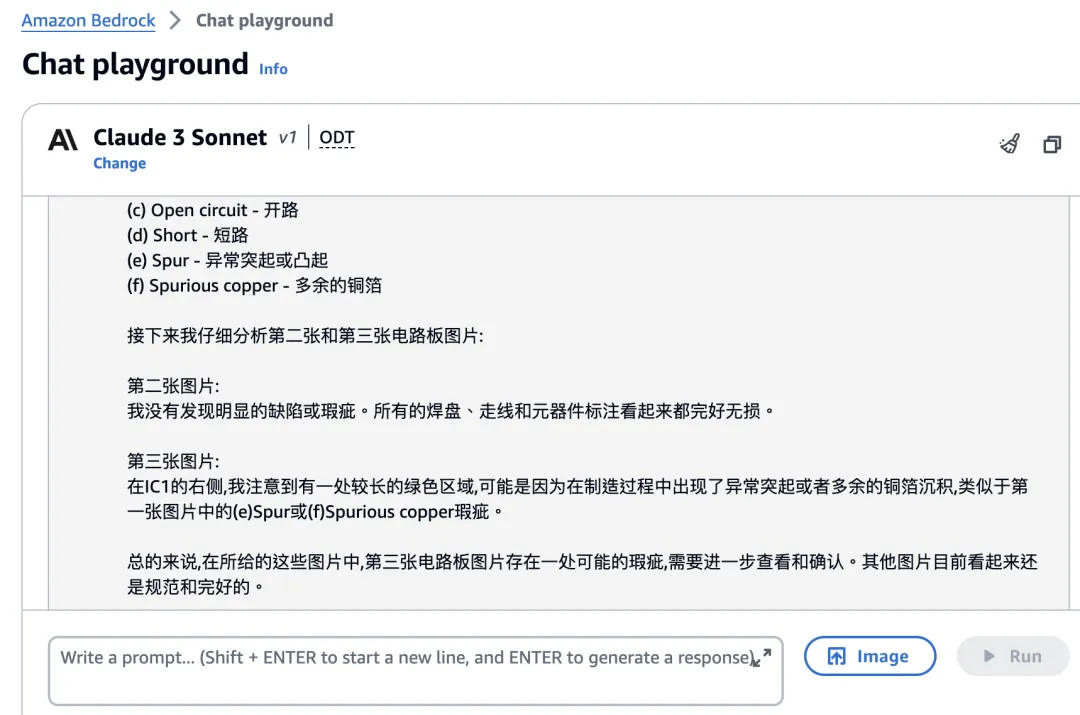
接下来我仔细分析第二张和第三张电路板图片:
第二张图片:
我没有发现明显的缺陷或瑕疵。所有的焊盘、走线和元器件标注看起来都完好无损。
第三张图片:
在 IC1 的右侧,我注意到有一处较长的绿色区域, 可能是因为在制造过程中出现了异常突起或者多余的铜箔沉积, 类似于第一张图片中的 (e) Spur 或 (f) Spurious copper 瑕疵。
总的来说,在所给的这些图片中, 第三张电路板图片存在一处可能的瑕疵, 需要进一步查看和确认。其他图片目前看起来还是规范和完好的。”
由 Claude 3 Sonnet 模型的输出结果可见:
模型已经在第三块有“缺陷”的电路板上,找到了我们故意添加的绿色条块,检测出了这处多余的“铜皮”!
本例小结
通过本例,笔者最深刻的感受是 Claude 3 模型由于具备了对多模态信息的支持,使得其可以适用的行业场景变得无比广阔,甚至未来会超出我们目前的想象力。
教育场景:辅助教学代码实践
本节将以 Claude 3 模型为例,阐述如何在 Amazon Bedrock 控制台中使用 Claude 3 Sonnet 模型,来辅助开发者实现所需学习知识的完整代码,以加深对所需学习知识的理解。
在以下演示示例中,我们将假设一位机器学习领域的初学者,他在阅读了许多卷积神经网络的书籍和资料后,非常渴望亲自尝试从头实现一个完整的卷积神经网络,以加深对卷积神经网络的学习理解。
我们计划使用的提示词如下:
“请使用 Python 从头实现一个卷积神经网络。最后提供如何使用已实现的 CNN 及样本值作为输入来预测模型输出的示例。鉴于这些代码针对的是初学者,请尝试满足以下条件:
-
提供详细的代码注释
-
绘制设计的卷积神经网络层的结构图
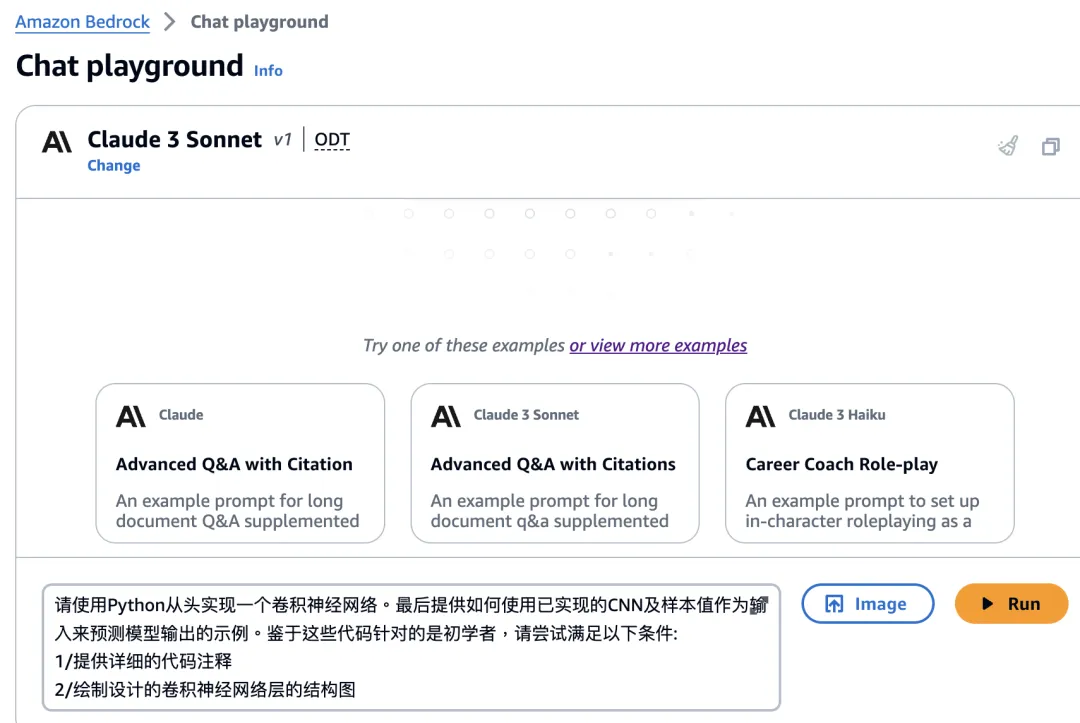
第一次模型返回的输出结果并不完整,还没显示完全就中断了,如下图所示:
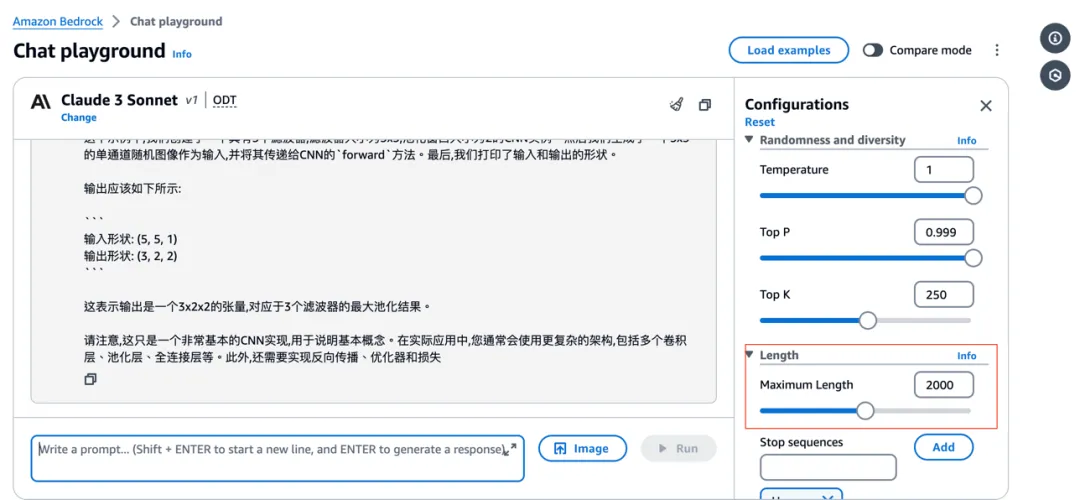
排查发现:目前使用的 Maximum Length 配置是缺省配置,即:2000。这可能是导致模型输出不全的主要原因。因此,我们尝试将 Maximum Length 设置为最大值(即 4096),如下所示:
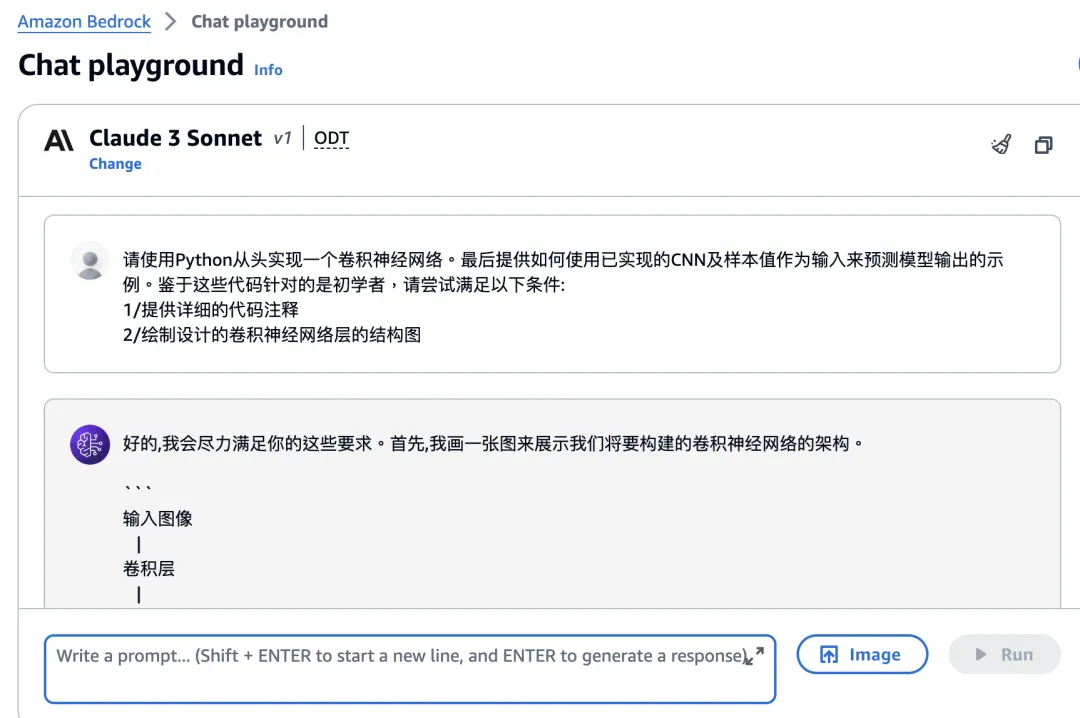
然后再次提交模型输入,得到模型的输出结果。模型首先就画了一张卷积神经网络的结构图,如下所示:
为了方便读者阅读,我们将 Claude 3 Sonnet 模型输出的结果复制出来,显示如下:
好的,我会尽力满足你的这些要求。首先,我画一张图来展示我们将要构建的卷积神经网络的架构。
输入图像
|
卷积层
|
激活层 (ReLU)
|
池化层 (最大池化)
|
扁平化
|
全连接层
|
输出层 (Softmax)
这是一个基础的卷积神经网络架构,包含以下主要组件:
1. 卷积层 (Convolution Layer)
2. 激活层 (Activation Layer,这里使用 ReLU)
3. 池化层 (Pooling Layer,这里使用最大池化)
4. 扁平化层 (Flattening Layer)
5. 全连接层 (Fully-Connected Layer)
6. 输出层 (Output Layer,这里使用 Softmax 作为分类)
下面是使用 Python 和 Numpy 从头实现这个卷积神经网络的代码,包含详细的代码注释:
import numpy as np
# 激活函数 - ReLU
def relu(x):
"""
ReLU(整流线性单元)激活函数
:param x: 输入数据
:return: 经过ReLU激活函数处理的输出
"""
return np.maximum(0, x)
# Softmax函数
def softmax(x):
"""
Softmax函数,用于多分类
:param x: 输入数据,形状为(batch_size, num_classes)
:return: Softmax输出
"""
exp_x = np.exp(x - np.max(x, axis=1, keepdims=True))
return exp_x / np.sum(exp_x, axis=1, keepdims=True)
# 卷积层
class ConvLayer:
def __init__(self, in_channels, out_channels, kernel_size, stride, padding):
"""
卷积层初始化
:param in_channels: 输入通道数
:param out_channels: 输出通道数
:param kernel_size: 卷积核大小,如(3,3)
:param stride: 步长
:param padding: 填充
"""
self.in_channels = in_channels
self.out_channels = out_channels
self.kernel_size = kernel_size
self.stride = stride
self.padding = padding
# 初始化卷积核权重,使用高斯分布初始化
self.weights = np.random.randn(out_channels, in_channels, *kernel_size) * 0.01
# 初始化偏置,所有偏置初始化为0
self.bias = np.zeros(out_channels)
def forward(self, input):
"""
卷积层前向传播
:param input: 输入数据,形状为(batch_size, in_channels, height, width)
:return: 卷积层输出
"""
batch_size, in_channels, height, width = input.shape
out_height = (height + 2 * self.padding - self.kernel_size[0]) // self.stride + 1
out_width = (width + 2 * self.padding - self.kernel_size[1]) // self.stride + 1
# 初始化输出张量
output = np.zeros((batch_size, self.out_channels, out_height, out_width))
# 执行卷积操作
for b in range(batch_size):
for oc in range(self.out_channels):
for oh in range(out_height):
for ow in range(out_width):
# 计算输出元素对应的输入区域
input_region = input[b, :, oh * self.stride:oh * self.stride + self.kernel_size[0],
ow * self.stride:ow * self.stride + self.kernel_size[1]]
# 执行卷积操作
output[b, oc, oh, ow] = np.sum(input_region * self.weights[oc]) + self.bias[oc]
return output
# 最大池化层
class MaxPoolLayer:
def __init__(self, kernel_size, stride):
"""
最大池化层初始化
:param kernel_size: 池化核大小
:param stride: 步长
"""
self.kernel_size = kernel_size
self.stride = stride
def forward(self, input):
"""
最大池化层前向传播
:param input: 输入数据,形状为(batch_size, in_channels, height, width)
:return: 最大池化层输出
"""
batch_size, in_channels, height, width = input.shape
out_height = (height - self.kernel_size) // self.stride + 1
out_width = (width - self.kernel_size) // self.stride + 1
# 初始化输出张量
output = np.zeros((batch_size, in_channels, out_height, out_width))
# 执行最大池化操作
for b in range(batch_size):
for c in range(in_channels):
for oh in range(out_height):
for ow in range(out_width):
# 计算输出元素对应的输入区域
input_region = input[b, c, oh * self.stride:oh * self.stride + self.kernel_size,
ow * self.stride:ow * self.stride + self.kernel_size]
# 执行最大池化操作
output[b, c, oh, ow] = np.max(input_region)
return output
# 全连接层
class FullyConnectedLayer:
def __init__(self, in_features, out_features):
"""
全连接层初始化
:param in_features: 输入特征数
:param out_features: 输出特征数
"""
self.in_features = in_features
self.out_features = out_features
# 初始化权重,使用高斯分布初始化
self.weights = np.random.randn(in_features, out_features) * 0.01
# 初始化偏置,所有偏置初始化为0
self.bias = np.zeros(out_features)
def forward(self, input):
"""
全连接层前向传播
:param input: 输入数据,形状为 (batch_size, in_features)
:return: 全连接层输出
"""
# 执行线性变换
output = np.dot(input, self.weights) + self.bias
return output
# 卷积神经网络
class ConvNet:
def __init__(self):
# 初始化网络层
self.conv1 = ConvLayer(1, 32, (3, 3), 1, 1) # 输入通道数为1(灰度图像), 输出通道数为32, 卷积核大小为3x3, 步长为1, 填充为1
self.relu1 = relu # ReLU激活函数
self.pool1 = MaxPoolLayer(2, 2) # 最大池化层,池化核大小为2x2, 步长为2
self.flatten = lambda x: np.reshape(x, (x.shape[0], -1)) # 扁平化层
self.fc1 = FullyConnectedLayer(32 * 14 * 14, 10) # 全连接层, 输入特征数为32*14*14 (经过池化后的特征图大小),输出特征数为10 (对应10个类别)
def forward(self, input):
"""
前向传播
:param input: 输入数据,形状为 (batch_size, 1, 28, 28)
:return: 网络输出
"""
# 卷积层
conv1_out = self.conv1.forward(input)
# 激活层
relu1_out = self.relu1(conv1_out)
# 池化层
pool1_out = self.pool1.forward(relu1_out)
# 扁平化层
flatten_out = self.flatten(pool1_out)
# 全连接层
fc1_out = self.fc1.forward(flatten_out)
# 输出层(Softmax)
output = softmax(fc1_out)
return output
# 示例使用
if __name__ == "__main__":
# 创建一个ConvNet实例
convnet = ConvNet()
# 定义一个示例输入, 形状为(batch_size, channels, height, width)
input_data = np.random.randn(10, 1, 28, 28) # 10张28x28的灰度图像
# 执行前向传播
output = convnet.forward(input_data)
# 输出结果
print(output)
在这个示例中,我们首先定义了一些辅助函数, 如 ReLU 激活函数和 Softmax 函数。然后, 我们实现了三个层类:
1. ConvLayer(卷积层)
2. MaxPoolLayer(最大池化层)
3. FullyConnectedLayer(全连接层)
每个层类都有一个forward方法, 用于执行前向传播计算。
最后, 我们定义了ConvNet类,它将上述层组合在一起, 构建了我们想要的卷积神经网络架构。ConvNet类的forward方法实现了整个网络的前向传播过程。
在__main__部分, 我们创建了一个ConvNet实例, 定义了一个示例输入数据 (10 张 28x28 的灰度图像),并执行前向传播,得到网络的输出。
你可以根据需要修改网络架构 (如添加更多层、调整参数等 ), 并使用真实的训练数据和标签来训练这个卷积神经网络模型。
本例小结
通过本例,笔者最深刻的感受是现代教育在大模型时代的扁平化。这个新时代中,只要你有强烈的驱动力和意志去学习一门知识或者手艺,借助于大模型的赋能和帮助,你最终一定能学有所成。以往,由于人类获取知识和信息的不对称,造成教育资源的倾斜情况将不再是最大的障碍了。
金融场景:公开市场信息增强搜索问答实践
终于又到了激动人心的代码时刻!前面的两个章节里,我们使用 Amazon Bedrock 的交互界面展示了工业场景和教育场景。本章将探讨另一个重要场景:金融场景。本章将实现一个金融场景的应用,即使用公开市场的信息来做增强搜索,来增强和大语言模型问答的效果。
在本章的示例中,我们将使用 Amazon Bedrock 提供的 API,来访问 Claude 3 的模型。本示例选择的公开市场信息,是亚马逊在 2019年-2022 年间写给股东的公开信,以 PDF 格式提供。如下图所示:
其中一个 PDF 文件的第一页,如下图所示(即 2022 年给 Amazon 全体股东的公开信):

该示例将讲解如何使用 Knowledge Bases for Amazon Bedrock 的检索 API,来构建问答应用程序。我们将根据相似性搜索查询知识库(即以上的四个写给股东的公开信 PDF 文件),以获取所需数量的文档片段。然后,我们将使用相关文档和查询来增强提示,并将其作为输入提供给 Claude 3 模型生成响应。
借助 Knowledge Bases for Amazon Bedrock,开发者可以安全地将 Amazon Bedrock 中的基础模型(例如:Claude 3)与公司已有的私有数据连接起来,以进行检索增强生成 (RAG)。访问额外的公司自身私有数据,可以帮助模型生成更加相关、更贴合上下文且准确的响应,而无需不断重新训练模型。
另外,我们还将在最后 Claude 3 模型的输出结果中展示:从知识库中检索到的信息都可以附带源头属性,以提高透明度并减少生成虚假信息的可能性。我们使用检索增强生成 (RAG) 模式来实现这个解决方案。RAG 模式从语言模型外部 (非参数) 检索数据,并通过添加相关的检索数据作为上下文来增强提示信息。
代码功能将主要涵盖两个部分:
-
将检索 API 与来自 Amazon Bedrock 的基础模型 Claude 3 Sonnet 配合使用
-
与 LangChain 集成
本示例使用的完整代码链接如下 (使用的 Claude 3 版本为 anthropic.claude-3-sonnet-20240229-v1:0):https://github.com/aws-samples/amazon-bedrock-workshop/blob/main/02_KnowledgeBases_and_RAG/3_Langchain-rag-retrieve-api-claude-3.ipynb
前置准备
-
运行环境:本示例需要基于 Python 3.10 以上环境来运行Notebook
-
增强数据源:需要将以上四个 PDF 文档加载到 Knowledge Bases for Amazon Bedrock 中,方法是连接 PDF 文件所在的 S3 存储桶(数据源)
-
数据摄取(Ingestion):知识库会根据选择的策略将文档分割成更小的块,然后生成对应的嵌入向量并存储到关联的向量数据库中, 本例使用的向量数据库是 Amazon Open Search 服务。篇幅所限,该步骤本文略过,有兴趣的读者可参考以下代码:https://github.com/aws-samples/amazon-bedrock-workshop/blob/main/02_KnowledgeBases_and_RAG/0_create_ingest_documents_test_kb.ipynb
数据摄取部分的整体流程图如下:

1.使用 Amazon Bedrock 的基础模型调用检索 API
定义一个检索函数,该函数调用由 Amazon Bedrock 的知识库提供的检索 API,此 API 将用户查询转换为嵌入向量,搜索知识库并返回相关结果,因此可以灵活地在语义搜索结果之上构建自定义的工作流。检索 API 的输出包括:检索到的文本块、源数据的定位类型和 URI、以及检索的相关性得分。如下图所示:
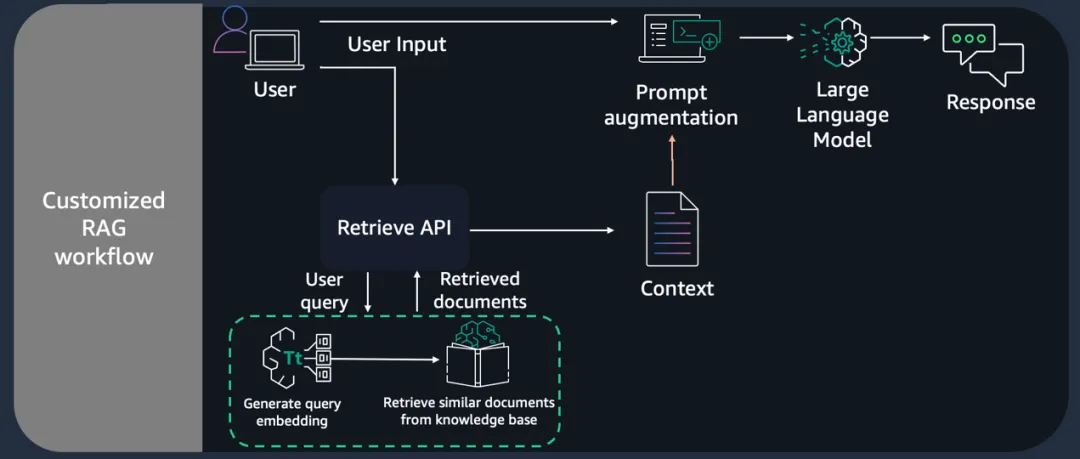
在查询初始化的 LLM 返回的响应之前,需要先初始化知识库 ID:
query = "What is Amazon doing in the field of Generative AI?"
response = retrieve(query, kb_id, 5)
retrievalResults = response['retrievalResults']
pp.pprint(retrievalResults)
然后从检索 API 的响应中提取文本块:
# fetch context from the response
def get_contexts(retrievalResults):
contexts = []
for retrievedResult in retrievalResults:
contexts.append(retrievedResult['content']['text'])
return contexts
contexts = get_contexts(retrievalResults)
pp.pprint(contexts)
然后为模型定制提示以个性化响应。我们将使用以下特定提示,使模型充当一个财务顾问人工智能系统,该系统将尽可能利用基于事实和统计信息来回答问题。我们将把上面检索 API 的响应作为提示中 {contexts} 的一部分提供给模型参考,同时还会提供用户的查询:
prompt = f"""
Human: You are a financial advisor AI system, and provides answers to questions by using fact based and statistical information when possible.
Use the following pieces of information to provide a concise answer to the question enclosed in <question> tags.
If you don't know the answer, just say that you don't know, don't try to make up an answer.
<context>
{contexts}
</context>
<question>
{query}
</question>
The response should be specific and use statistics or numbers when possible.
Assistant:"""
然后调用 Amazon Bedrock 上的基础模型。在这个例子中,我们将使用的基础模型是:anthropic.claude-3-sonnet-20240229-v1:0:
# payload with model paramters
messages=[{ "role":'user', "content":[{'type':'text','text': prompt.format(contexts, query)}]}]
sonnet_payload = json.dumps({
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 512,
"messages": messages,
"temperature": 0.5,
"top_p": 1
} )
modelId = 'anthropic.claude-3-sonnet-20240229-v1:0'
accept = 'application/json'
contentType = 'application/json'
response = bedrock_client.invoke_model(body=sonnet_payload, modelId=modelId, accept=accept, contentType=contentType)
response_body = json.loads(response.get('body').read())
response_text = response_body.get('content')[0]['text']
pp.pprint(response_text)
2.集成 LangChain
在这一部分,我们将用代码实现使用 Amazon Bedrock 和 LangChain 提供的知识库检索 API 构建问答应用程序。我们将根据相似性搜索查询知识库以获取所需数量的文档块,将其与 LangChain 检索器集成,并使用 Claude 3 Sonnet 模型来回答问题。
首先 import 所需的库:
# from langchain.llms.bedrock import Bedrock
import langchain
from langchain_community.chat_models.bedrock import BedrockChat
from langchain.retrievers.bedrock import AmazonKnowledgeBasesRetriever
llm = BedrockChat(model_id=modelId,
client=bedrock_client)
然后我们将创建一个来自 LangChain 的 AmazonKnowledgeBasesRetriever 对象,它将调用 Amazon Bedrock 的 Knowledge Bases 检索 API。该 API 会将用户查询转换为嵌入向量,搜索知识库并返回相关结果,以此来灵活地构建基于语义搜索结果的自定义工作流。检索 API 的输出包括检索到的文本块、源数据的 位置类型和 URI,以及检索的 相关性得分:
query = "What is Amazon doing in the field of Generative AI?"
retriever = AmazonKnowledgeBasesRetriever(
knowledge_base_id=kb_id,
retrieval_config={"vectorSearchConfiguration":
{"numberOfResults": 4,
'overrideSearchType': "SEMANTIC", # optional
}
},
)
docs = retriever.get_relevant_documents(
query=query
)
pp.pprint(docs)
接下来,我们将为模型设置特定提示以个性化响应。我们将使用以下特定提示,使模型充当一个金融顾问 AI 系统,并尽可能利用基于事实和统计信息来回答问题。
我们将把上面检索 API 的响应作为提示中的 {context} 的一部分,供模型与用户查询一起参考。
from langchain.chains import RetrievalQA
qa = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=retriever,
return_source_documents=True,
chain_type_kwargs={"prompt": claude_prompt}
)
answer = qa.invoke(query)
pp.pprint(answer)万事具备!现在终于可以将上述检索器(retriever)和大型语言模型(Claude 3),一起集成定义为一个检索链(RetrievalQA Chain)来构建问答应用程序了。
from langchain.chains import RetrievalQA
qa = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=retriever,
return_source_documents=True,
chain_type_kwargs={"prompt": claude_prompt}
)
answer = qa.invoke(query)
pp.pprint(answer)
笔者在 Amazon SageMaker Notebook Instance 运行的模型输出结果截图如下:

为方便大家阅读,我把文字结果去掉其中的换行符等符号,整理如下:
我们的问题是:
What is Amazon doing in the field of Generative AI?
'模型的输出结果是:
According to the context provided, Amazon has been working on developing its own large language models (LLMs) for Generative AI. The key points regarding Amazon's efforts in Generative AI are:
1. Amazon believes Generative AI based on very Large Language Models will "transform and improve virtually every customer experience and Amazon is investing substantially in these models across all its consumer, seller, brand, and creator experiences.
2. Like with its machine learning services on AWS, Amazon is democratizing this technology so companies of all sizes can leverage Generative AI.
3. Amazon Web Services is offering machine learning chips like Trainium and Inferentia to enable small and large companies to affordably train and run their LLMs in production.
4. Amazon Web Services is delivering applications like CodeWhisperer which uses Generative AI to provide real-time code suggestions, revolutionizing developer productivity.
5. It is stated that "LLMs and Generative AI are going to be a big deal for customers, our shareholders, and Amazon.
So in summary, Amazon views Generative AI as transformative and is investing heavily in developing its own LLM models, providing infrastructure and services to enable broad adoption of Generative AI by other companies, and creating applications that leverage Generative AI across Amazon's businesses.
本例小结
本例实现了一个 Claude 3 Sonnet 的金融场景应用:使用公开市场的信息(亚马逊 2019-2022 致全体股东函)来做增强搜索,增强和大语言模型(Claude 3 Sonnet)问答的效果。借助Knowledge Bases for Amazon Bedrock,开发者可以使用自己公司的私有数据,安全地将 Amazon Bedrock 中的基础模型与公司已有的私有数据连接起来,以进行检索增强生成 (RAG)。这将让大模型生成更相关、更贴合上下文的准确响应,无需重新训练模型。
全文总结
本文我们详细探讨和分析了 Claude 3 模型在三个不同行业场景的实践:
-
工业场景:电路板缺陷检测实践
-
教育场景:辅助教学代码实践
-
金融场景:公开市场信息增强搜索问答实践
希望对所有从事生成式 AI 应用的开发者,有所启发和帮助。下期关于 Amazon Bedrock 的实践真知内容会更加精彩,敬请期待。
参考资料
1.Amazon Bedrock 用户手册
https://docs.aws.amazon.com/bedrock/latest/userguide/what-is-bedrock.html?trk=cndc-detail
2.Amazon Bedrock API 参考手册
https://docs.aws.amazon.com/bedrock/latest/APIReference/welcome.html?trk=cndc-detail
3.在 Amazon Bedrock 上调用 Claude 3:
4.Amazon Bedrock Claude 3 workshop:
5.Anthropic’s Claude 3 Haiku model is now available on Amazon Bedrock

标签:Claude,模型,Amazon,Bedrock,size,self,out From: https://www.cnblogs.com/AmazonwebService/p/18131548