授权说明:本篇文章授权活动官方亚马逊云科技文章转发、改写权,包括不限于在 亚马逊云科技开发者社区, 知乎,自媒体平台,第三方开发者媒体等亚马逊云科技官方渠道。
前言:
在大数据时代的浪潮中,数据不再只是数字的堆积,而是成为我们理解世界、做出决策的关键元素。随着信息技术的飞速发展,我们进入了一个数字化的时代,其中机器学习作为处理和理解这些海量数据的利器,正变得日益重要。

亚马逊云科技开发者社区为开发者们提供全球的开发技术资源。这里有技术文档、开发案例、技术专栏、培训视频、活动与竞赛等。帮助中国开发者对接世界最前沿技术,观点,和项目,并将中国优秀开发者或技术推荐给全球云社区。如果你还没有关注/收藏,看到这里请一定不要匆匆划过,点这里让它成为你的技术宝库!
一、走进 Amazon SageMaker
在近期举行的 re:Invent 2023 大会上,亚马逊云科技宣布了一系列令人瞩目的新功能,其中着重强调了生成式 AI 对人工智能未来发展的引领作用。在深入了解大会内容后,我对亚马逊云科技发布的新功能,尤其是针对 Amazon SageMaker 的功能表现出浓厚兴趣。以下是我对这些功能的使用经验分享。

对于一些初次接触 Amazon SageMaker 的朋友,Amazon SageMaker 是一种全面托管的机器学习服务。这意味着用户无需过多关注底层的复杂性,而是可以专注于模型的构建和优化。通过 SageMaker,开发者可以快速、轻松地构建和训练机器学习模型,然后直接将模型部署到生产就绪的托管环境中。同时 SageMaker 也提供了一个集成的 Jupyter 编写 Notebook 实例,可以轻松访问数据源以便进行探索和分析,并且无需管理服务器。

此外,SageMaker 还可以提供常见的机器学习算法,这些算法经过了优化,可以在分布式环境中高效处理非常大的数据。借助对 bring-your-own-algorithms 和框架的本地支持,SageMaker 提供灵活的分布式训练选项,可根据开发者的特定工作流程进行调整;可以从 SageMaker Studio 或 SageMaker 控制台中单击几下鼠标按钮以启动模型,并将该模型部署到安全且可扩展的环境中。
我们可以看到 SageMaker 平台提供了众多的机器学习算法,可以帮助我们简化机器学习训练过程,提高机器学习的效率。在后文我会分享个人的亲测使用过程,帮助开发者更快上手使用。
二、Amazon SageMaker 新功能推出
Amazon SageMaker 在最新发布的 HyperPod、Inference、Clarify 和 Canvas 功能方面取得了显著的突破,为用户提供了更加强大、高效的机器学习工具。
SageMaker HyperPod 功能是专为大规模分布式训练而设计的创新性基础设施。SageMaker HyperPod 的引入消除了这些繁琐的任务,自动将训练工作负载分发到数千个加速器中,从而提高了模型的性能,并通过定期保存检查点确保了训练的连续性。
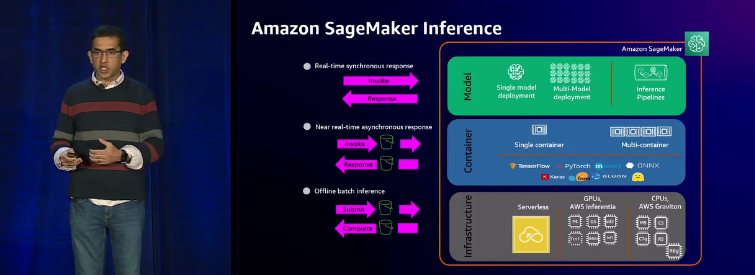
SageMaker Inference 方面通过优化加速器的使用,显著减少了基础模型部署的成本,同时,通过智能路由推理请求,它提高了实例的利用率,减少了成本,并改善了用户体验,降低了延迟约 20%,使得部署更加经济高效,用户获得更流畅的推理体验。
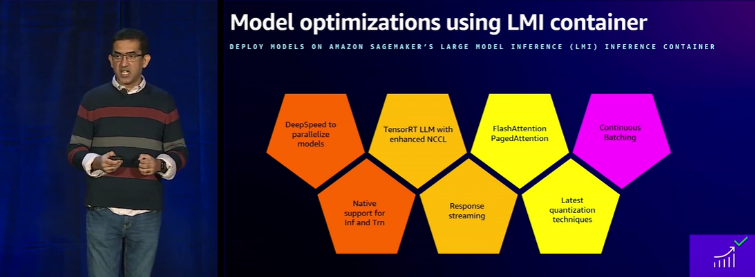
Amazon SageMaker Clarify 同时也提供了一种轻松的方式,使用户能够根据负责任使用 AI 的参数快速评估和选择基础模型。该功能的独特之处在于,它支持组织有效地评估模型,确保其符合负责任的 AI 标准。用户可以方便地提交模型进行评估,或通过 SageMaker JumpStart 选择适用于其用例的模型。SageMaker Clarify 还简化了评估参数的选择,并提供了详细的报告,使用户能够基于性能标准快速比较、评估和选择最佳模型。

Amazon SageMaker Canvas 引入了更直观的无代码界面,使用户更轻松、更快速地将生成式 AI 集成到其工作流程中。通过使用自然语言指令准备数据,用户可以以更直观的方式进行数据准备,将准备数据所需的时间从几小时缩短到几分钟。利用模型进行大规模业务分析的功能使用户能够在 SageMaker Canvas 上构建 ML 模型并为各种任务生成预测,实现了更广泛的应用。这一系列功能的整合标志着 SageMaker 在推动机器学习领域的创新方面取得了重要进展,为用户提供了更为便捷、高效的工具,助力其在 AI 领域取得更大的成功。
三、Amazon SageMaker 使用指南
Amazon SageMaker 是综合而高效的机器学习平台,提供面向数据科学家和业务分析师的友好工具,将培训时间缩短至几分钟,极大提高团队生产力。它强调数据处理的多样性,支持结构化和非结构化数据。接下来我将以为 ML 标记训练数据作为例子,来标记一系列图像,包括飞机、汽车、渡轮、直升机和摩托车等的案例。
1. 准备工作
1.进入官网,完成账号登录,没有账号的朋友需要先完成账号注册
2.来到个人控制台界面,通过搜索栏搜索 Amazon SageMaker 服务
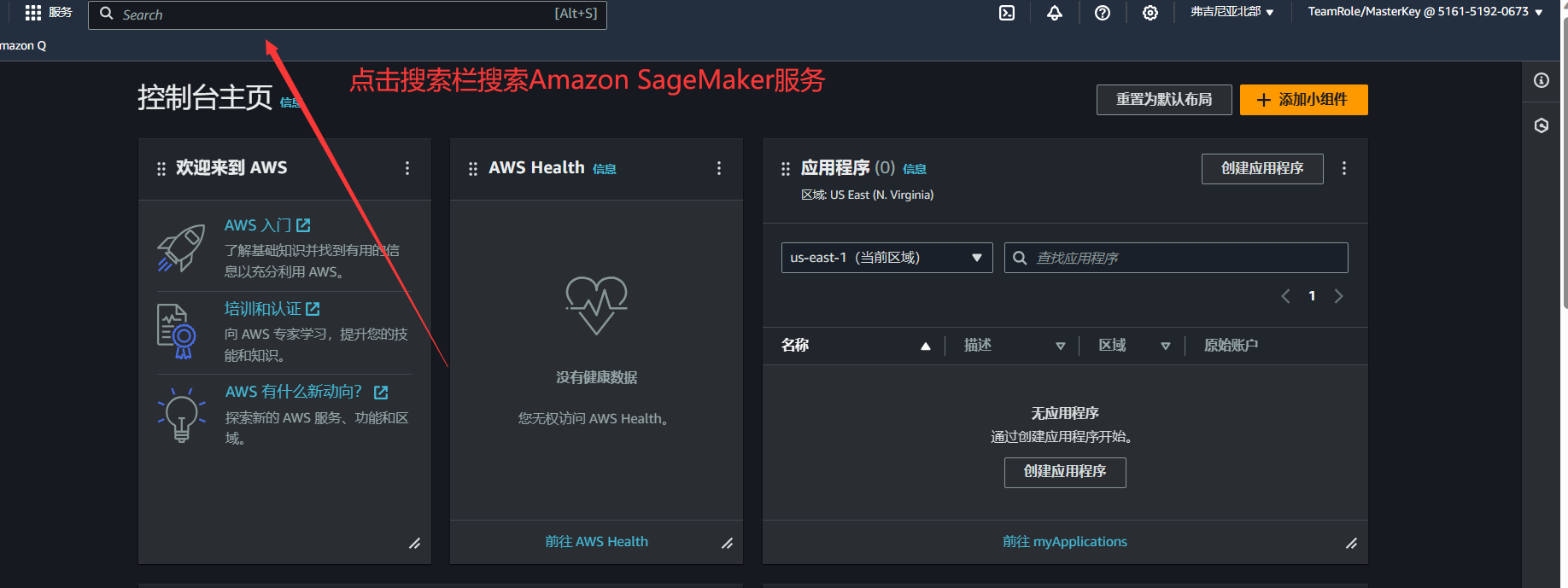
3.进入到 SageMaker 服务的主页,同时我们也可以根据主页功能栏的入门指导快速上手
2. 创建笔记本实例
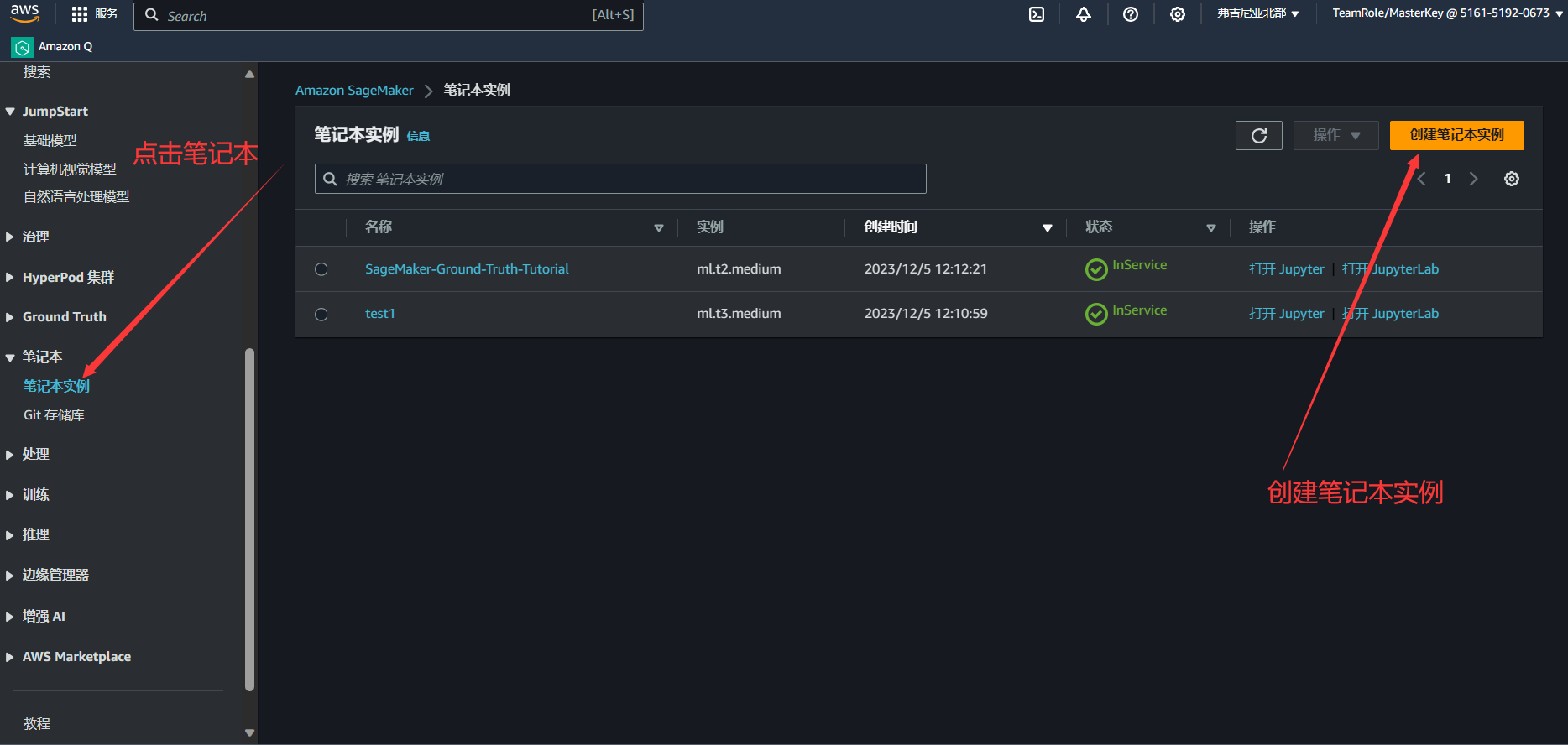
1.点击左侧导航栏中的笔记本模块,选中笔记本实例,然后创建实例
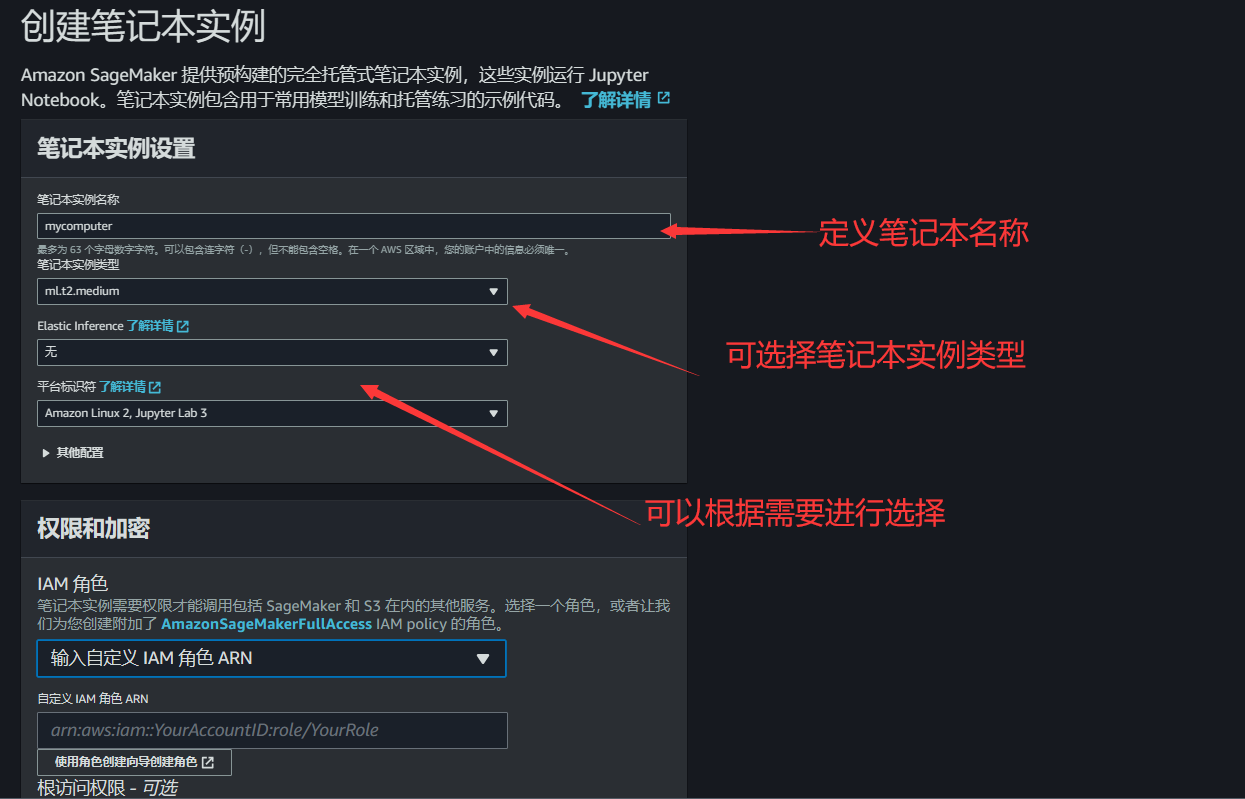
2.根据开发需要选择笔记本实例类型和平台标识符以及相关配置信息
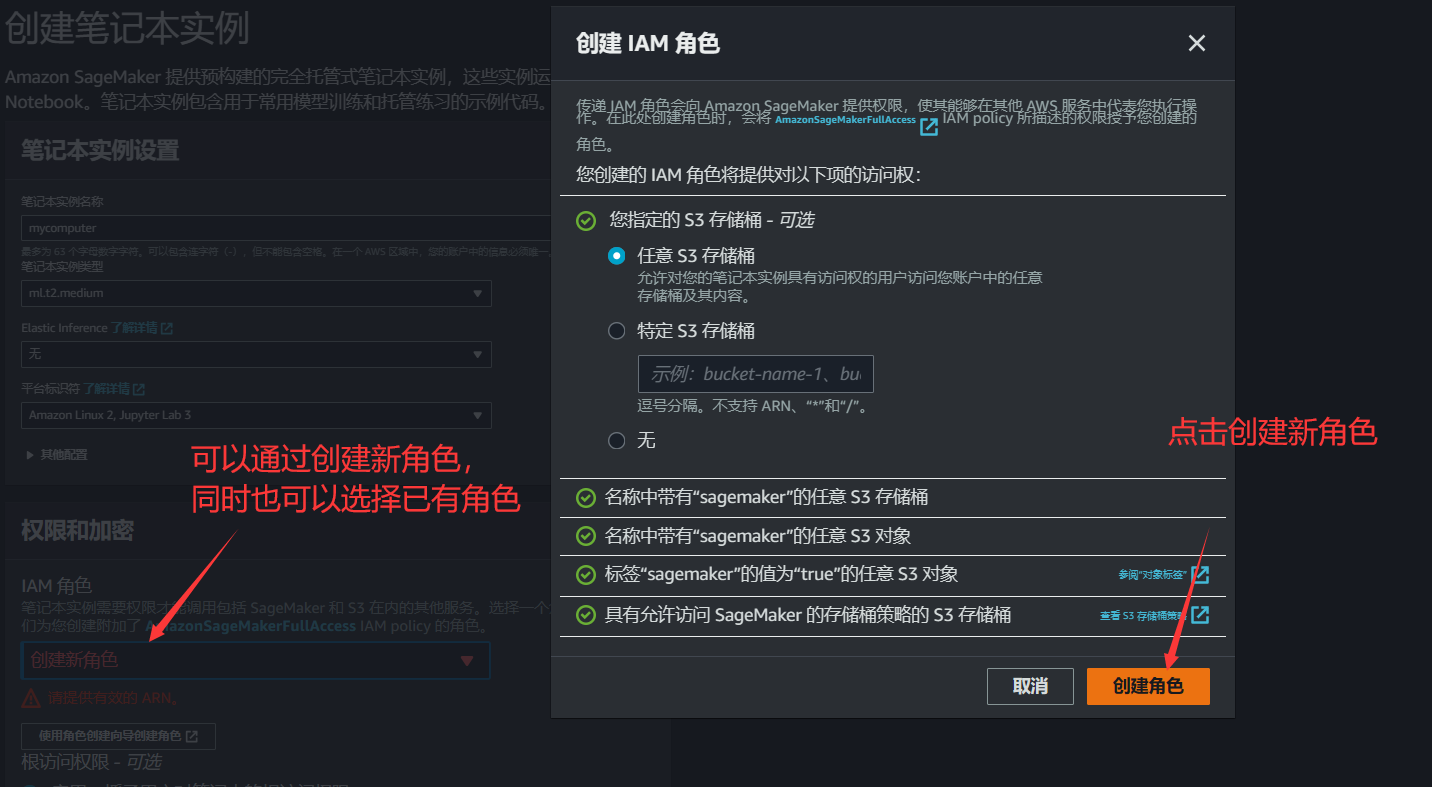
3.定义 IAM 角色信息,可以选择创建新的用户角色,同时也可以选择已有角色
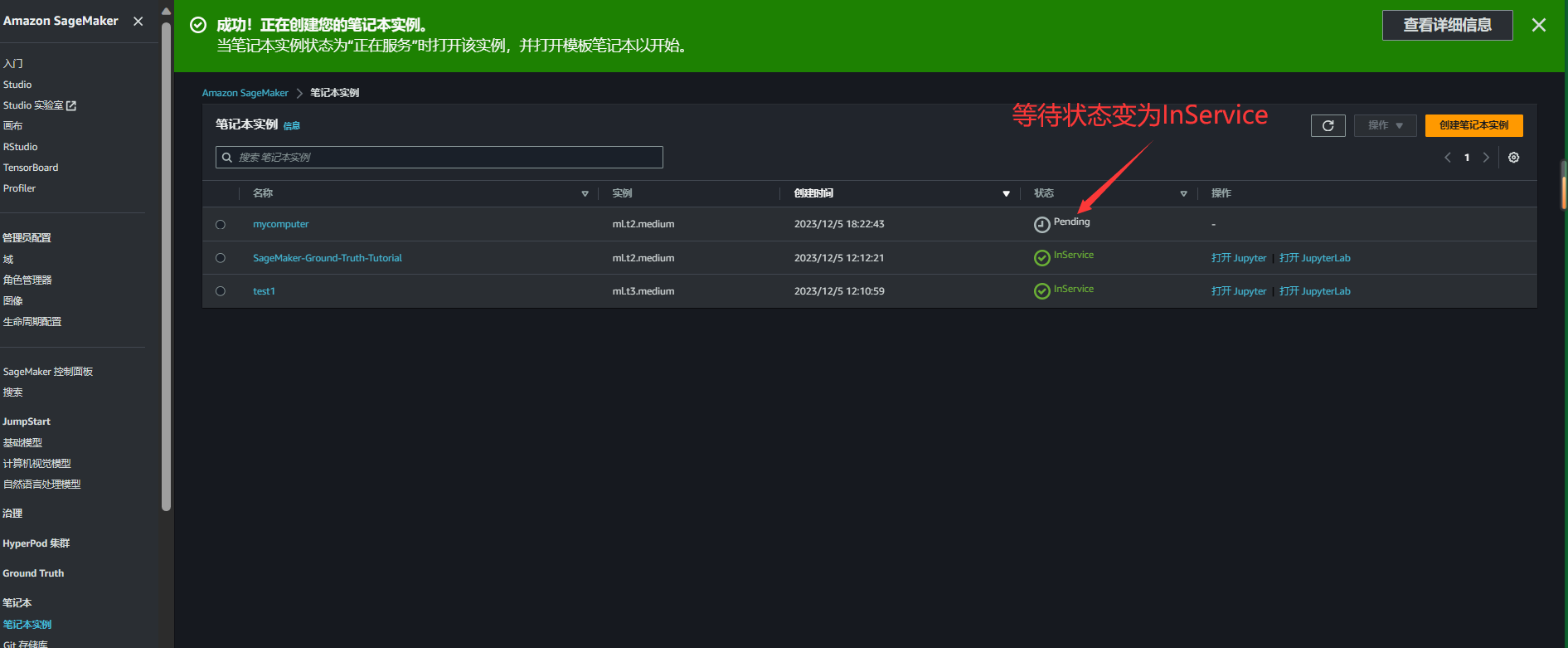
4.创建完毕后,等待状态变更为 InService 即可以使用
3. 数据处理
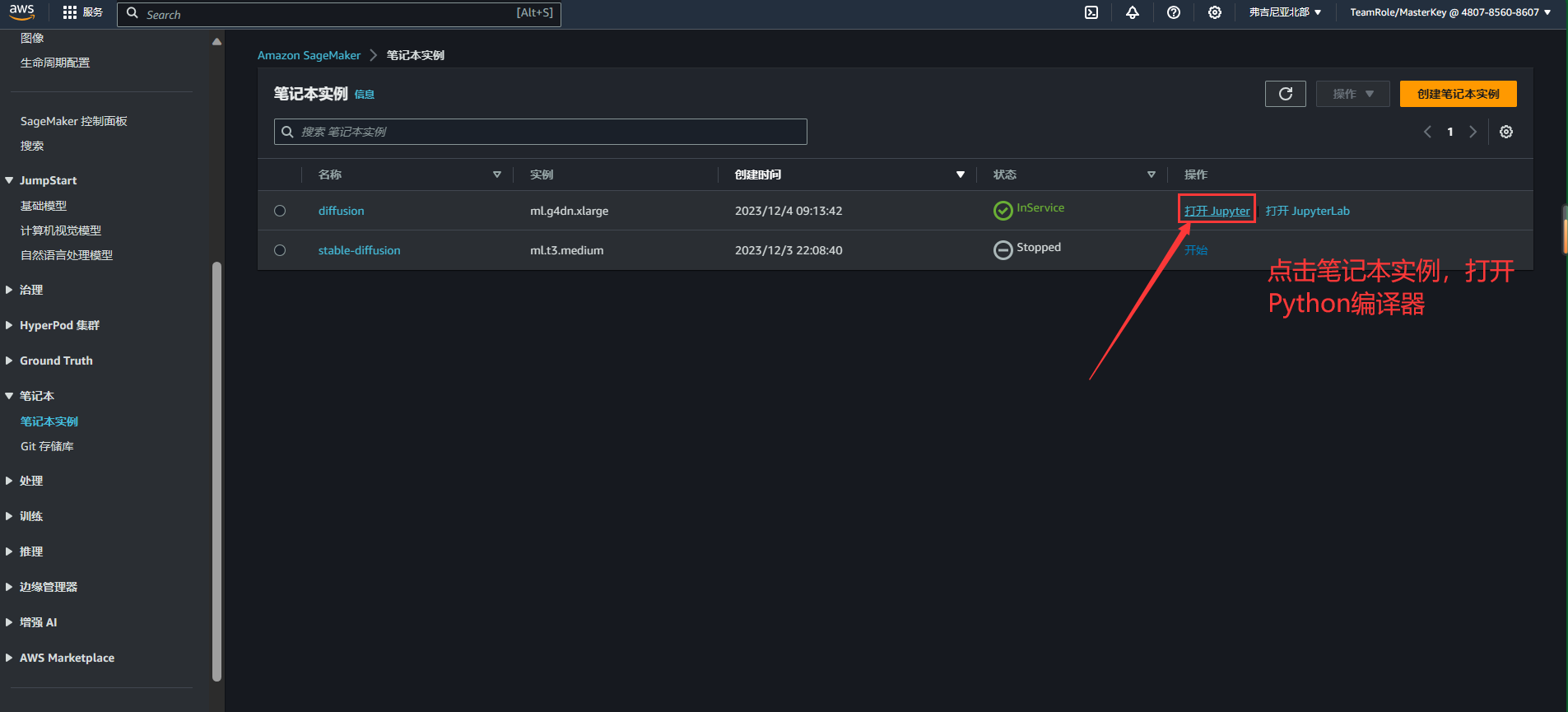
1.点击笔记本实例,打开 python 编译器
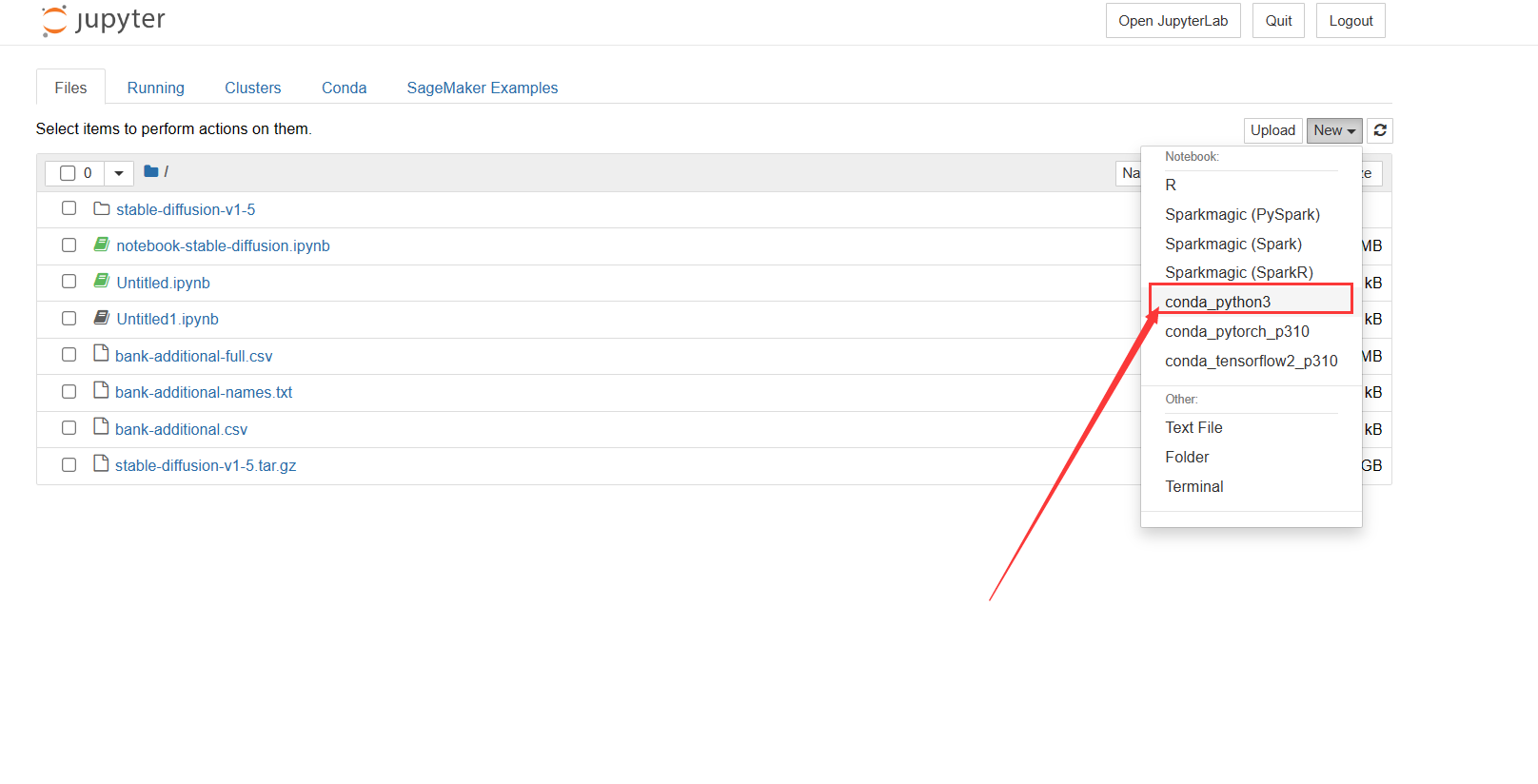
2.打开 jupyter 编译器之后,点击 new 创建 conda_python3 服务
3.点击 Untitled.ipynb 以打开笔记本。在 Jupyter notebook 的新代码单元格中,复制并粘贴以下代码,然后运行该单元格,注:在次给出示例,S3 存储桶具体信息根据个人情况修改
import sagemaker
sess = sagemaker.Session()
bucket = sess.default_bucket()
!xxx s3 sync
//这一块需要切换为自己的存储桶信息
s3://sagemaker-sample-files/datasets/image/caltech-101/inference/ s3://{bucket}/ground-truth-demo/images/
print('Copy and paste the below link into a web browser to confirm the ten images were successfully uploaded to your bucket:')
print(f'https://s3.console.xxx.amazon.com/s3/buckets/{bucket}/ground-truth-demo/images/')
print('\nWhen prompted by Sagemaker to enter the S3 location for input datasets, you can paste in the below S3 URL')
print(f's3://{bucket}/ground-truth-demo/images/')
print('\nWhen prompted by Sagemaker to Specify a new location, you can paste in the below S3 URL')
print(f's3://{bucket}/ground-truth-demo/labeled-data/')
4.在成功运行代码以后,使用存储桶 S3 桶存储文件,因为我们上面代码中10 张样本图像位于 Amazon S3 桶,具体信息可以更换为我们自己的存储桶。
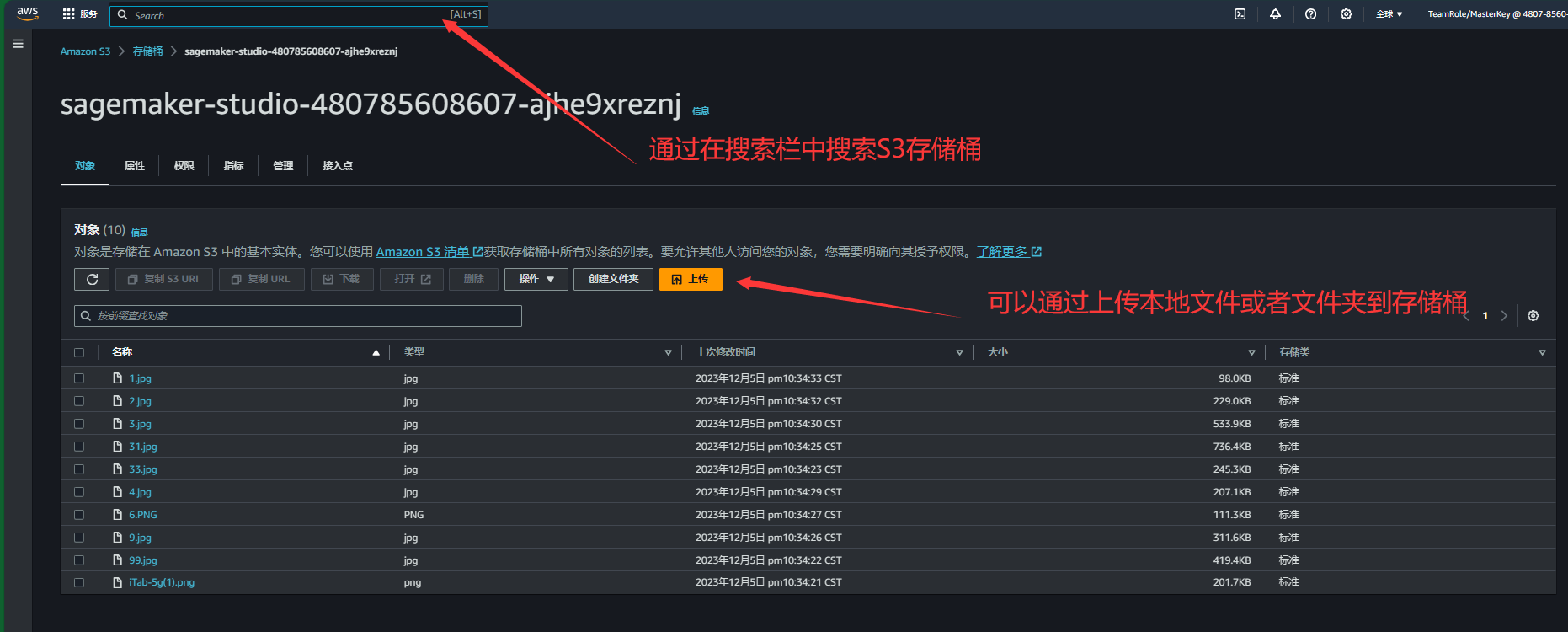
5.通过向 S3 桶中添加十张照片,如图,添加完毕成功
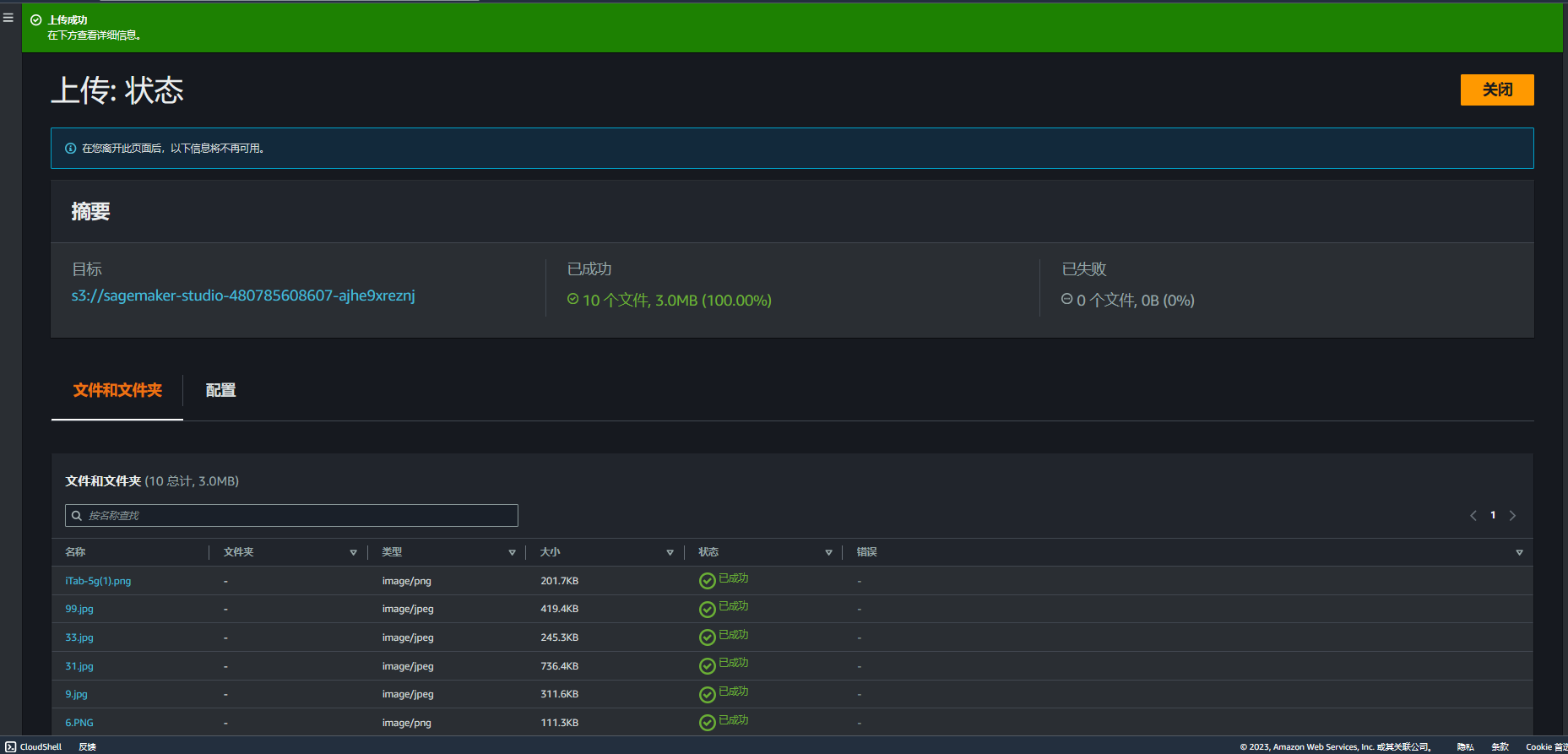
6.进入 Amazon SageMaker 服务界面,通过选择 Ground Truth 服务,创建标注作业
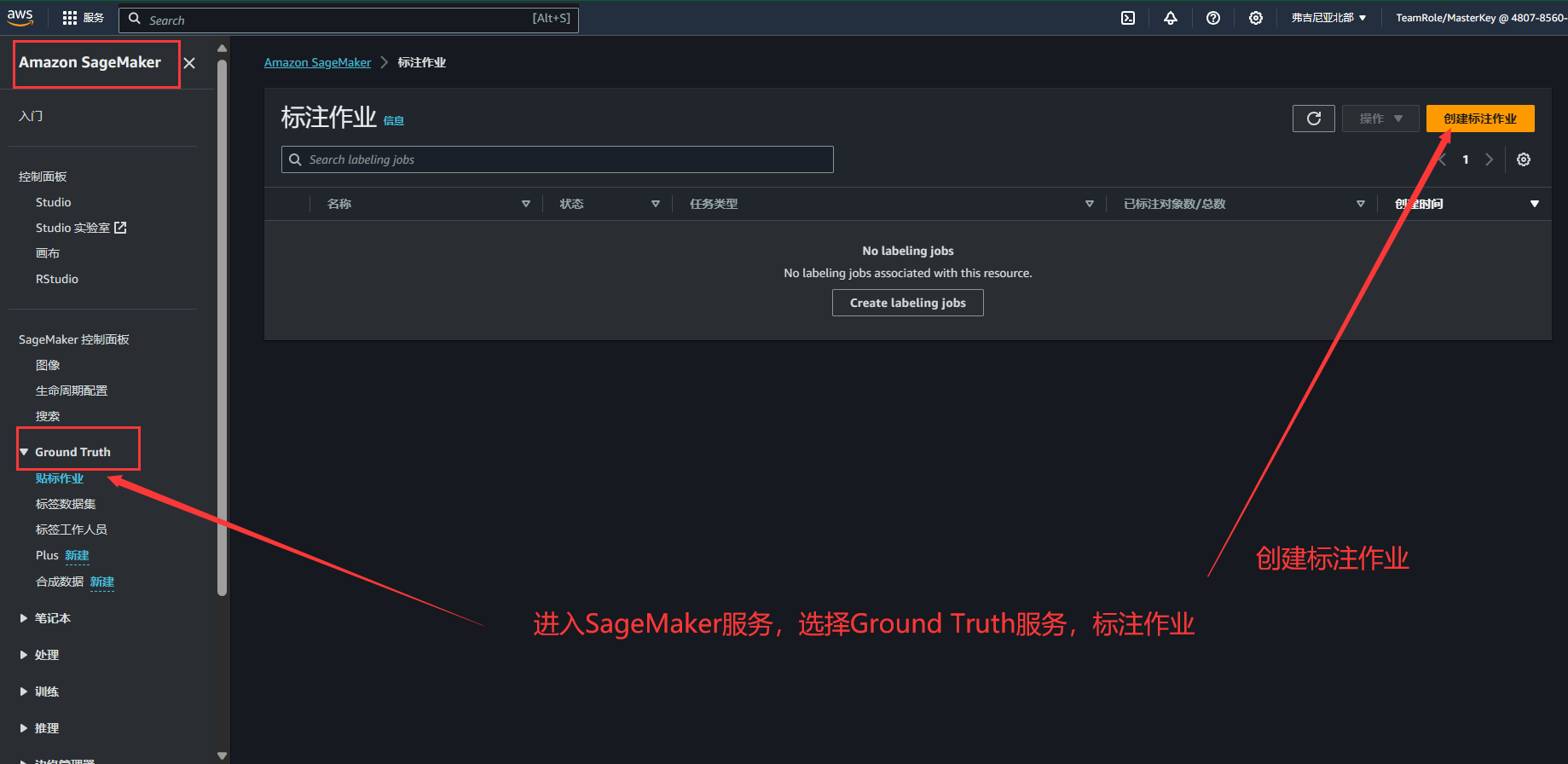
7.创建标注作业,并设置相关的配置信息,我们可以使用存储在 Amazon S3 存储桶中的图像、视频、视频帧、文本(.txt)文件和以逗号分隔的值(.csv)文件,并通过自动数据设置为您的标注作业创建清单文件
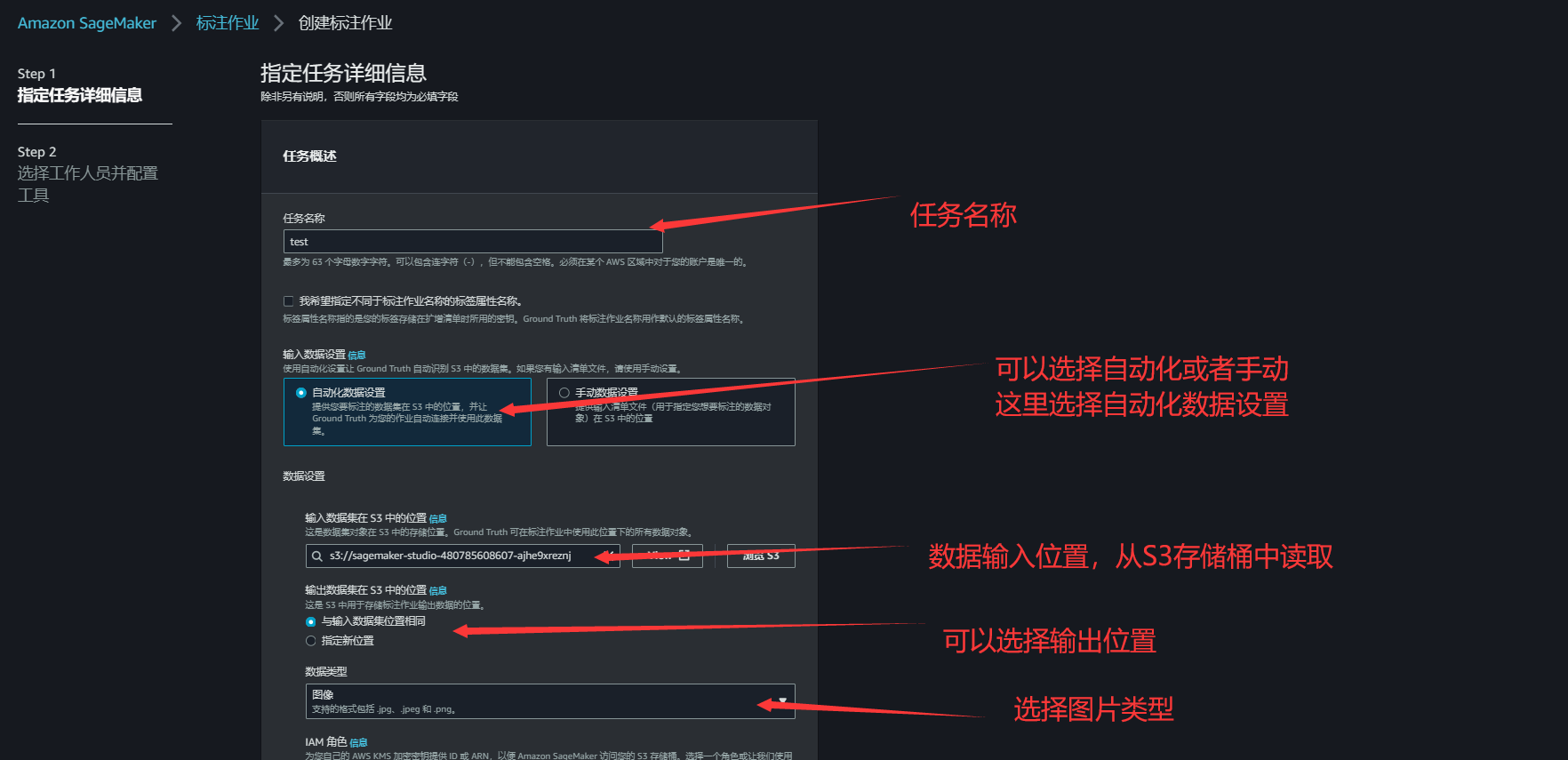
8.选择对应任务类型,任务类别选择图像,同时任务选择图像分类
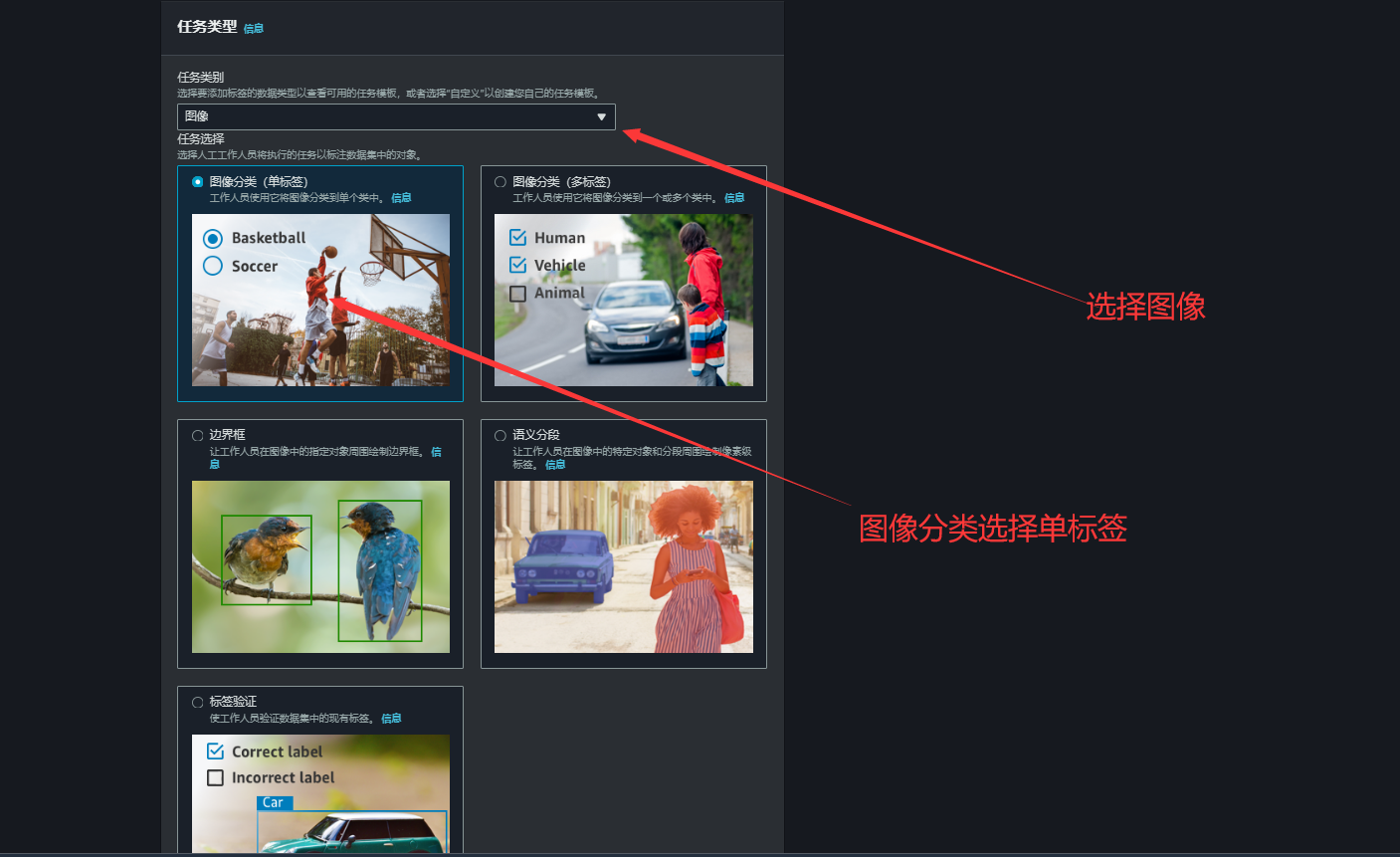
9.当我们看到标注作业的状态变更为完成即表示标注作业创建完毕
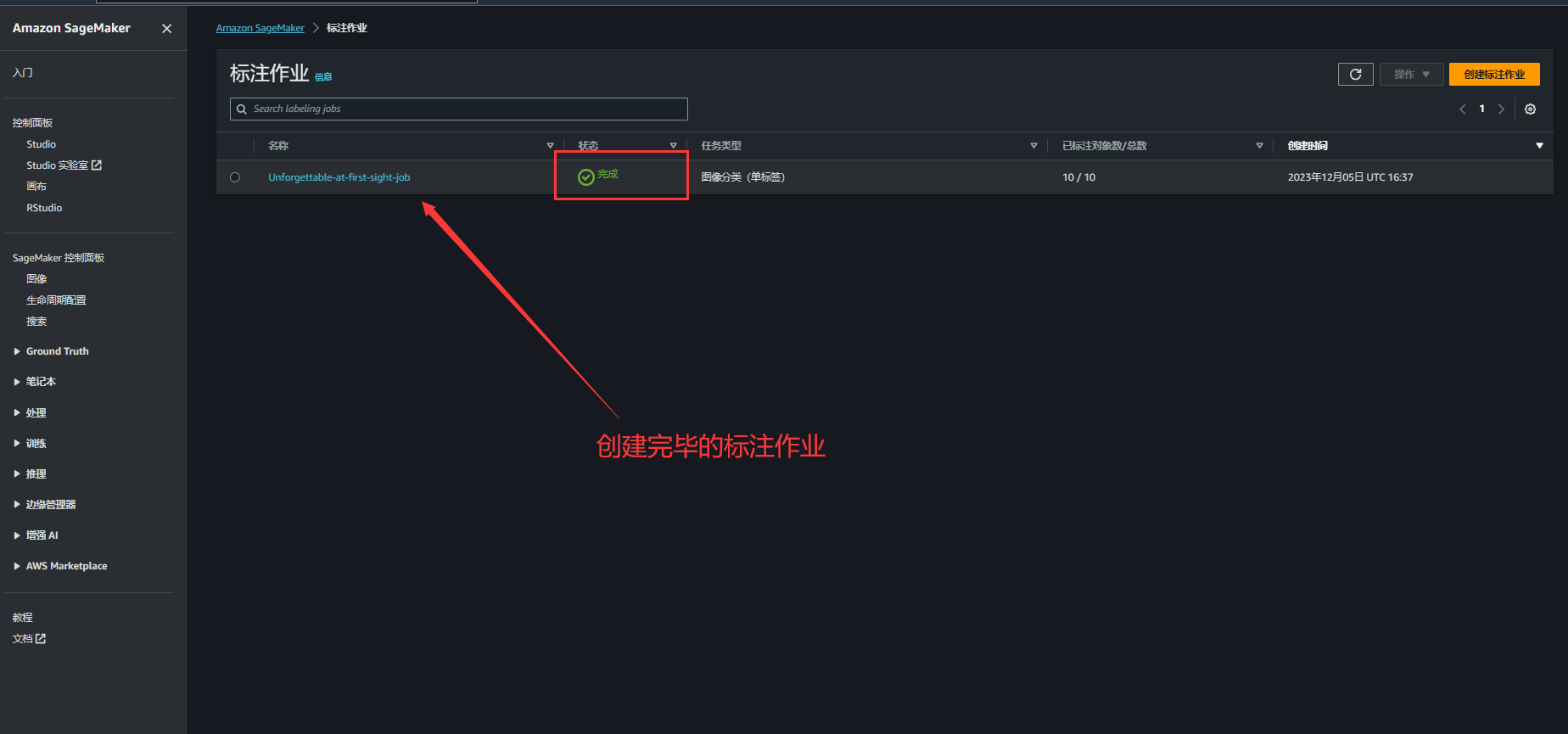
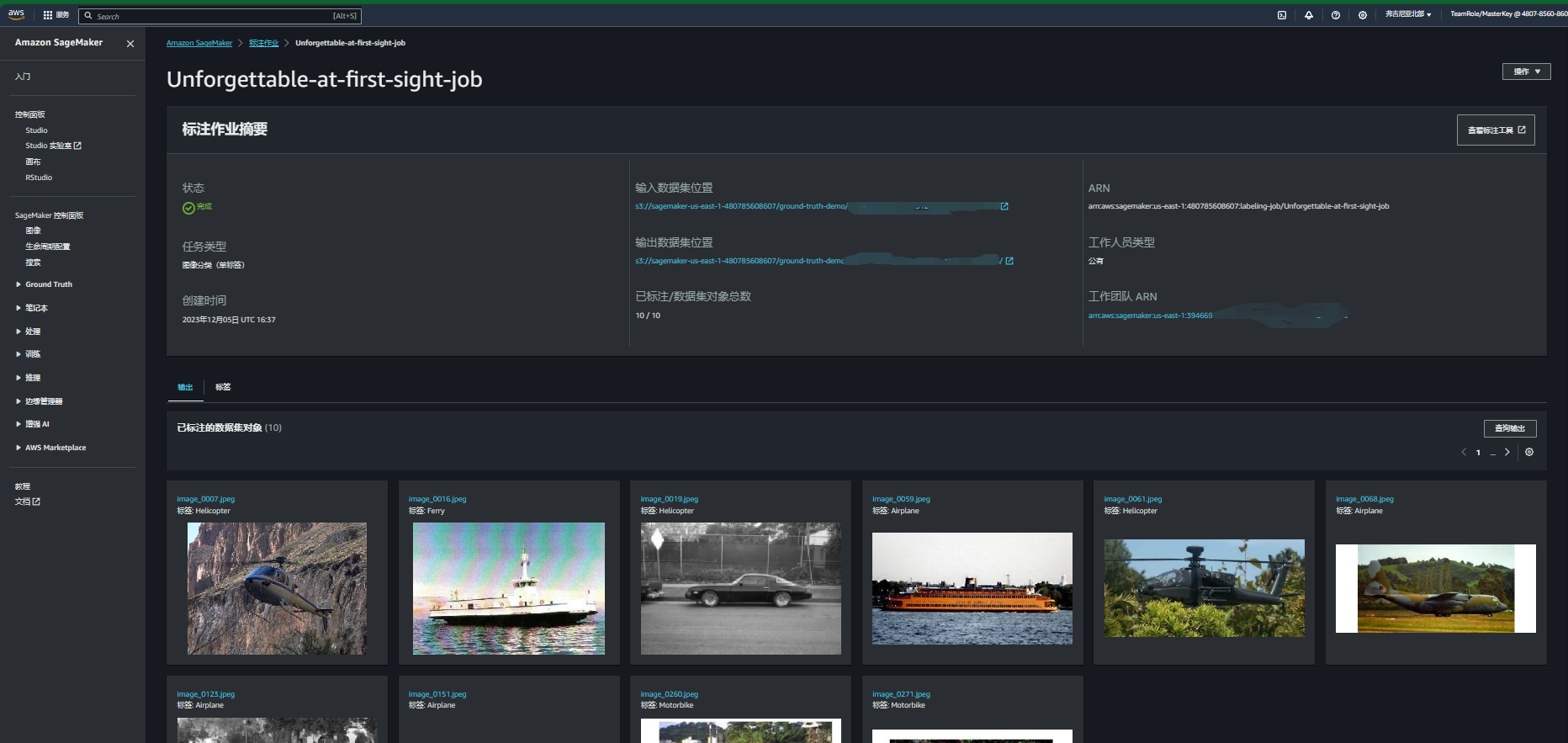
10.可以查看标注作业相关信息,审核标注作业结果对评估标记质量,以及确定您是否需要优化说明和数据来说十分重要。 在详细信息页面上,标记数据集对象部分将显示您的数据集图像的缩略图,并以对应标签作为标题。如果同时想要评估标注作业的完整结果,可以在标注作业摘要部分中,选择输出数据集位置链接。
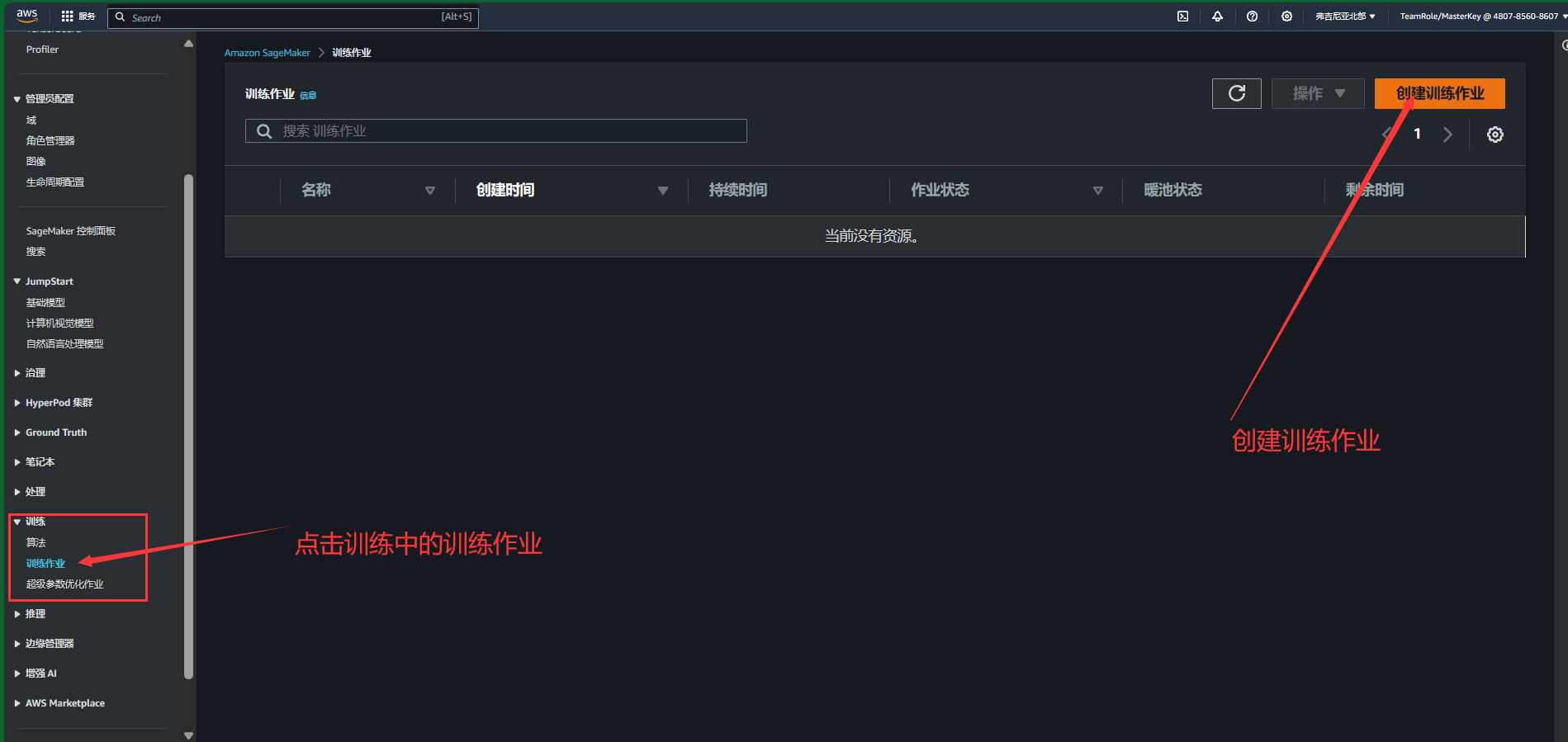
4.训练模型
1.点击训练模块中的训练任务,并且创建训练作业
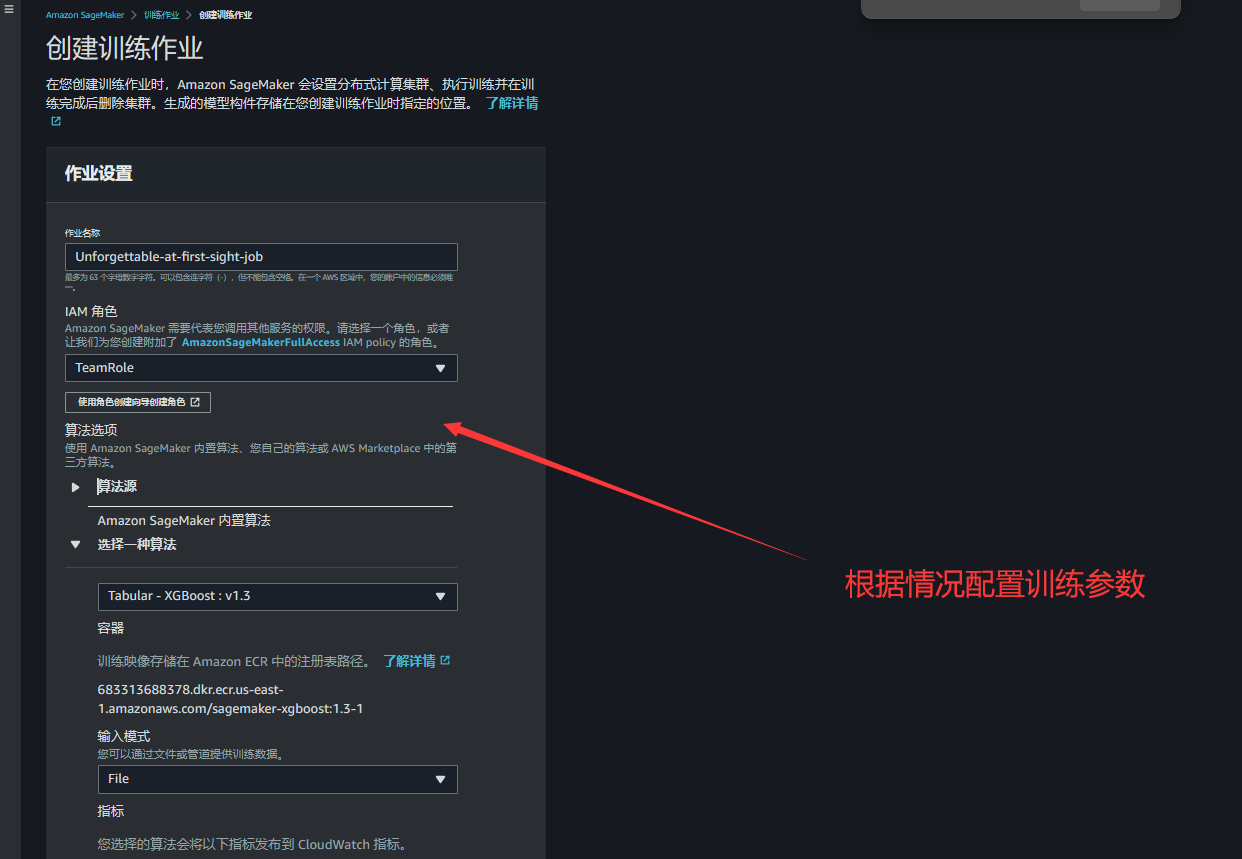
2.配置相关训练参数,这一块信息配置可以根据开发需要进行相关设置
3.完成训练作业,当我们看到作业状态变更为 success,即表示作业训练完成
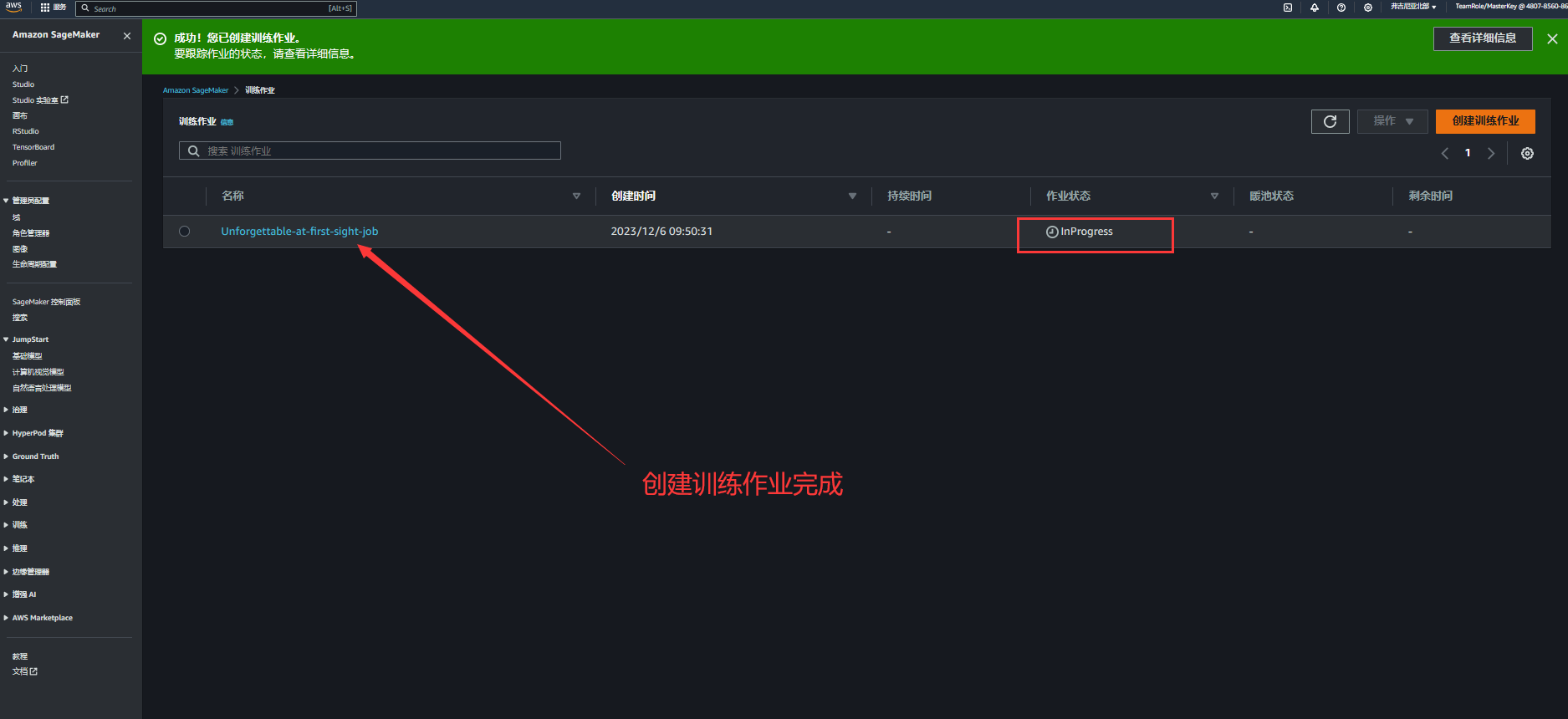
在这里贴出(SageMaker 官方文档),相关细节可以进行参考和细节学习。
四、使用体验和总结
Amazon SageMaker 通过有针对性的改进,成功地克服了当前机器学习应用中的多项挑战,为用户提供了更高效的解决方案。特别是在大规模监督训练方面,采用了全面托管的服务模式,使整个训练过程更为简化,从而在提高效率的同时降低了用户的操作负担。这种设计使得用户可以更专注于模型和业务的开发,而不用过多关注底层的技术细节。
在数据标记阶段,Amazon SageMaker 提供了多种灵活的方式和算法,显著提升了标记数据的准确性。这不仅为用户节省了时间,避免了在重复训练和调优上的不必要投入,同时也为模型的发展奠定了更为可靠的基础。我的个人感受是,在这个阶段,SageMaker 的用户体验得到了很好的优化,让整个数据标记流程更加直观和高效。
在工程实施方面,Amazon SageMaker 为模型开发提供了许多实用的功能,使算法工程师能够更轻松地将关注点集中在业务和模型本身上,提高了开发的效率。其基于容器的设计相较于流行的 Kubernetes 更为简化,减少了软件依赖和复杂性,为用户提供了更加友好的开发环境。通过这样全流程支持的设计,机器学习应用的实施变得更加高效,为企业带来了持续创新的动力。在实际使用中,我发现这种设计理念为我带来更加流畅和愉悦的开发体验。
总体而言,Amazon SageMaker 不仅仅是一款强大的机器学习工具,更是一个推动行业创新的引擎。其广泛的应用将为企业带来更多机会,将机器学习无缝融入各个领域,推动着创新步入崭新的时代。这种全面性和创新性的解决方案使得 Amazon SageMaker 成为当前机器学习领域的领军者,为用户提供了更多可能性和发展空间。
标签:机器,训练,模型,用户,Amazon,SageMaker From: https://www.cnblogs.com/AmazonwebService/p/18131142