https://zhuanlan.zhihu.com/p/679179913
计算机视觉研究院主要涉及AI研究和落地实践,主要致力于目标检测、目标跟踪、图像分割、OCR、模型量化、模型部署等研究方向。研究院每日分享最新的论文算法新框架,提供论文一键下载,并分享实战项目。研究院主要着重”技术研究“和“实践落地”!
公众号公众号ID|计算机视觉研究院
学习群|扫码在主页获取加入方式
开源地址:https://github.com/ultralytics/ultralytics
YOLOv8 是 ultralytics 公司在 2023 年 1月 10 号开源的 YOLOv5 的下一个重大更新版本,目前支持图像分类、物体检测和实例分割任务,在还没有开源时就收到了用户的广泛关注。
一、前言

YOLOv8
是一个 SOTA 模型,它建立在以前 YOLO
版本的成功基础上,并引入了新的功能和改进,以进一步提升性能和灵活性。具体创新包括一个新的骨干网络、一个新的 Ancher-Free
检测头和一个新的损失函数,可以在从 CPU 到 GPU 的各种硬件平台上运行。
YOLO: A Brief History
YOLO(You Only Look Once)是一种流行的对象检测和图像分割模型,由华盛顿大学的Joseph Redmon和Ali Farhadi开发。YOLO于2015年推出,以其高速度和高精度迅速走红。
- YOLOv2于2016年发布,通过合并批处理规范化、锚盒和维度集群来改进原始模型
- 2018年推出的YOLOv3使用更高效的骨干网络、多个锚点和空间金字塔池进一步增强了该模型的性能
- YOLOv4于2020年发布,引入了Mosaic数据增强、新的无锚检测头和新的丢失功能等创新
- YOLOv5进一步提高了模型的性能,并添加了超参数优化、集成实验跟踪和自动导出到流行导出格式等新功能
- YOLOv6于2022年由美团开源,目前正在该公司的许多自动配送机器人中使用
- YOLOv7在COCO关键点数据集上添加了额外的任务,如姿态估计
- YOLOv8是Ultralytics公司推出的YOLO的最新版本。作为一款尖端、最先进的(SOTA)车型,YOLOv8在之前版本的成功基础上,引入了新的功能和改进,以增强性能、灵活性和效率。YOLOv8支持全方位的视觉AI任务,包括检测、分割、姿态估计、跟踪和分类。这种多功能性允许用户在不同的应用程序和域中利用YOLOv8的功能
YOLOv8的新特性与可用模型
Ultralytics
并没有直接将开源库命名为 YOLOv8,而是直接使用 ultralytics 这个词,原因是 ultralytics
将这个库定位为算法框架,而非某一个特定算法,一个主要特点是可扩展性。其希望这个库不仅仅能够用于 YOLO 系列模型,而是能够支持非 YOLO
模型以及分类分割姿态估计等各类任务。总而言之,ultralytics 开源库的两个主要优点是:
- 融合众多当前 SOTA 技术于一体
- 未来将支持其他 YOLO 系列以及 YOLO 之外的更多算法
Ultralytics为YOLO模型发布了一个全新的存储库。它被构建为 用于训练对象检测、实例分割和图像分类模型的统一框架。
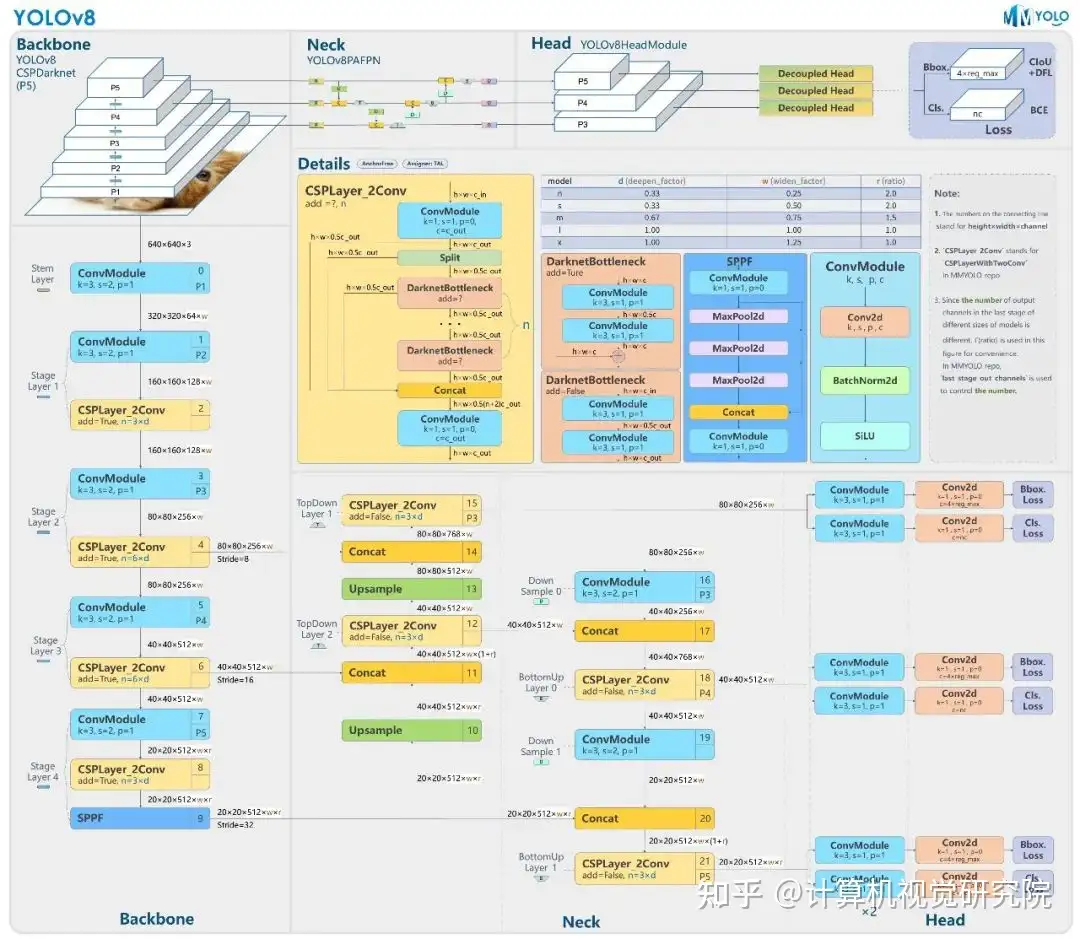
- 提供了一个全新的 SOTA 模型,包括 P5 640 和 P6 1280 分辨率的目标检测网络和基于 YOLACT 的实例分割模型。和 YOLOv5 一样,基于缩放系数也提供了 N/S/M/L/X 尺度的不同大小模型,用于满足不同场景需求
- 骨干网络和 Neck 部分可能参考了 YOLOv7 ELAN 设计思想,将 YOLOv5 的 C3 结构换成了梯度流更丰富的 C2f 结构,并对不同尺度模型调整了不同的通道数,属于对模型结构精心微调,不再是无脑一套参数应用所有模型,大幅提升了模型性能。不过这个 C2f 模块中存在 Split 等操作对特定硬件部署没有之前那么友好了
- Head 部分相比 YOLOv5 改动较大,换成了目前主流的解耦头结构,将分类和检测头分离,同时也从 Anchor-Based 换成了 Anchor-Free
- Loss 计算方面采用了 TaskAlignedAssigner 正样本分配策略,并引入了 Distribution Focal Loss
- 训练的数据增强部分引入了 YOLOX 中的最后 10 epoch 关闭 Mosiac 增强的操作,可以有效地提升精度
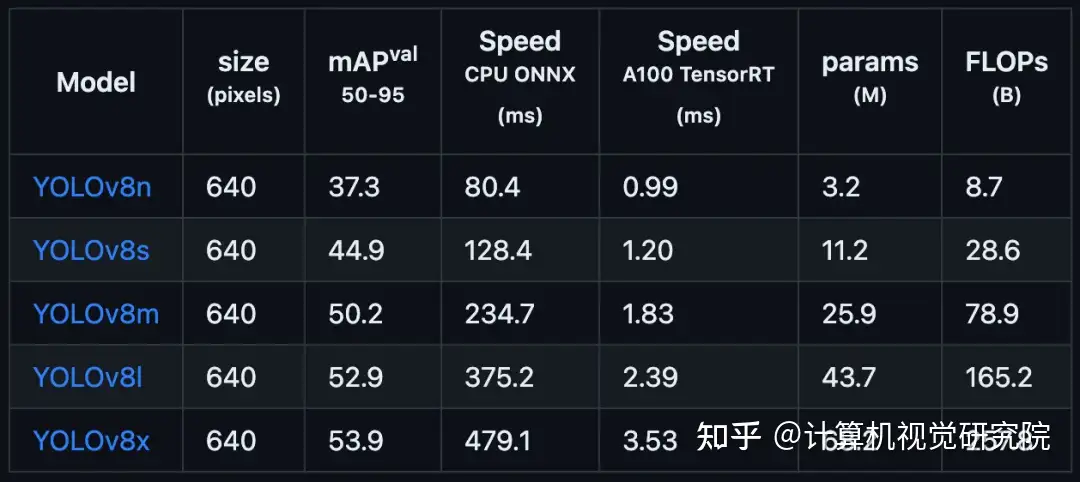
YOLOv8 还高效灵活地支持多种导出格式,并且该模型可以在 CPU 和 GPU 上运行。YOLOv8 模型的每个类别中有五个模型用于检测、分割和分类。YOLOv8 Nano 是最快和最小的,而 YOLOv8 Extra Large (YOLOv8x) 是其中最准确但最慢的。
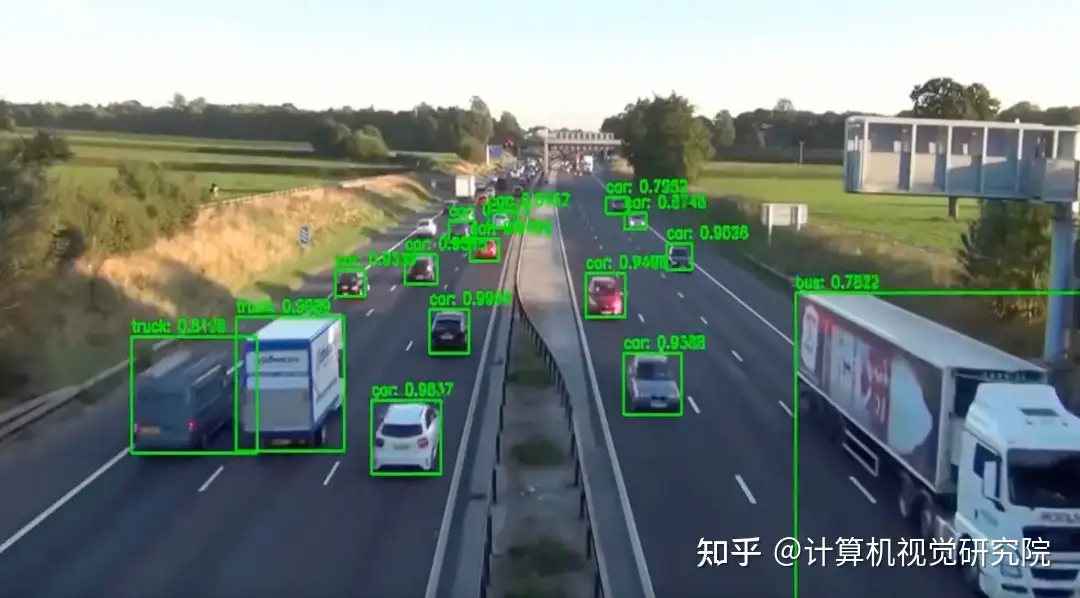
如下是使用YOLOv8x做目标检测和实例分割模型的输出:

如何使用YOLOv8
Pip install the ultralytics package including all requirements in a Python>=3.7 environment with PyTorch>=1.7.
pip install ultralyticsYOLOv8可以通过yolo命令直接在命令行界面(CLI)中使用:
yolo predict model=yolov8n.pt source='https://ultralytics.com/images/bus.jpg'yolo可以用于各种任务和模式,并接受额外的参数,即imgsz=640。有关示例,请参阅YOLOv8 CLI文档。
YOLOv8 CLI文档:https://docs.ultralytics.com/usage/cli/
YOLOv8也可以直接在Python环境中使用,并接受与上面CLI示例中相同的参数:
from ultralytics import YOLO
# Load a model
model = YOLO("yolov8n.yaml") # build a new model from scratch
model = YOLO("yolov8n.pt") # load a pretrained model (recommended for training)
# Use the model
model.train(data="coco128.yaml", epochs=3) # train the model
metrics = model.val() # evaluate model performance on the validation set
results = model("https://ultralytics.com/images/bus.jpg") # predict on an image
success = model.export(format="onnx") # export the model to ONNX format YOLO模型自动从最新的Ultralytics版本下载。有关更多示例,请参阅YOLOv8 Python文档。
https://docs.ultralytics.com/usage/python/
推理在笔记本电脑GTX1060 GPU上以接近105 FPS的速度运行。我们得到以下输出:(转自于 OpenCV与AI深度学习)

YOLOv8 Nano 模型在几帧中将猫混淆为狗。让我们使用 YOLOv8 Extra Large 模型对同一视频运行检测并检查输出:
yolo task=detect mode=predict model=yolov8x.pt source='input/video_3.mp4' show=TrueExtra Large模型在GTX1060 GPU上的平均运行速度为 17 FPS。

实例分割的推理结果
使用YOLOv8 实例分割模型运行推理同样简单。我们只需要更改上面命令中的task和model名称。
yolo task=segment mode=predict model=yolov8x-seg.pt source='input/video_3.mp4' show=True因为实例分割与对象检测相结合,所以这次的平均 FPS 约为 13。

分割图在输出中看起来非常干净。即使猫在最后几帧中躲在方块下,模型也能够检测并分割它。
图像分类推理结果
最后,由于YOLOv8已经提供了预训练的分类模型,让我们使用该yolov8x-cls模型对同一视频进行分类推理。这是存储库提供的最大分类模型。
yolo task=classify mode=predict model=yolov8x-cls.pt source='input/video_3.mp4' show=True
默认情况下,视频使用模型预测的前5个类进行注释。在没有任何后处理的情况下,注释直接匹配ImageNet类名。案例

快速检测缺陷并提供重要的安全功能
计算机视觉可以取代生产线上容易出错的手动零件组装和质量检查。在车内,计算机视觉可以为重要的安全功能提供动力,如分心的驾驶员监控、检测车道偏离、识别其他车辆和行人以及读取交通信号。收集用于训练的图像和视频数据。将从车辆和生产线摄像头收集的视频和图像转换为数据,以建立您的计算机视觉模型。

© THE END
在CV飞速发展的当下,如何更好地抓住机会,了解热点方向?我复盘并整理了CV领域学习脉络,整理了一份由多位CV领域顶尖导师授课资料包,包含CV时下热点方向24节系列课程、从复现CVPR best paper开始,手把手教你写一篇CVPR和100+篇顶会论文合集!扫下方二维码可获取!
转载请联系本公众号获得授权

计算机视觉研究院学习群等你加入!
计算机视觉研究院主要涉及深度学习领域,主要致力于人脸检测、人脸识别,多目标检测、目标跟踪、图像分割等研究方向。研究院接下来会不断分享最新的论文算法新框架,我们这次改革不同点就是,我们要着重”研究“。之后我们会针对相应领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!
扫码关注计算机视觉研究院公众号ID|ComputerVisionGzq
学习群|扫码在主页获取加入方式
往期推荐
- 字节跳动新框架:图片中遮挡关系如何判断?新方法刷新SOTA(附源代码)
- Apple团队:轻量级、通用且移动友好的网络框架(附论文下载)
- 多目标检测:基于YoloV4优化的多目标检测(附论文下载)
- Fast YOLO:用于实时嵌入式目标检测(附论文下载)
- 目标检测干货 | 多级特征重复使用大幅度提升检测精度(文末附论文下载)
- 多尺度深度特征(下):多尺度特征学习才是目标检测精髓(论文免费下载)
- 多尺度深度特征(上):多尺度特征学习才是目标检测精髓(干货满满,建议收藏)
- 半监督辅助目标检测:自训练+数据增强提升精度(附源码下载)
- 目标检测干货 | 多级特征重复使用大幅度提升检测精度(文末附论文下载)
标签:ultralytics,检测,模型,YOLO,YOLOv8,实操,上手,model From: https://www.cnblogs.com/ztguang/p/18117594