楔子
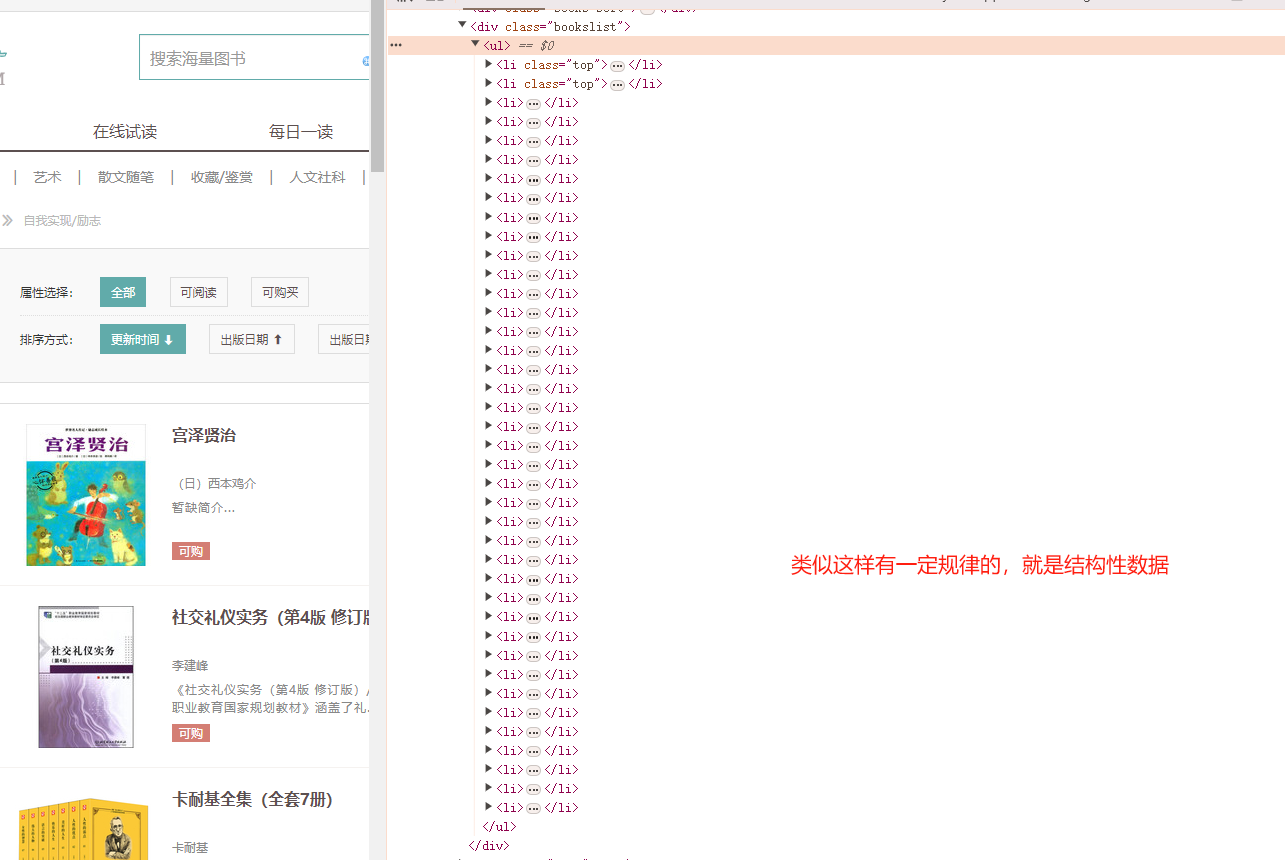
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。
安装
方式1
pip install scrapy
方式2
如果方式1安装不了,在看此方式,如果方式1能正常安装,那就不需要查看此方式了。
# 1. 安装wheel文件
pip3 install wheel
# 2. 安装 lxml 解析器
pip3 install lxml
# 3. 安装 pyopenssl
pip3 install pyopenssl
# 4. 下载并安装pywin32
下载并安装 pywin32 可以从其官网下载最适合您的版本:https://sourceforge.net/projects/pywin32/files/pywin32/
请根据您的操作系统和Python版本选择正确的安装文件进行下载。
下载完成后,按照安装向导进行安装。
# 5.下载twisted的wheel文件
要安装 Scrapy,需要先下载 twisted 的 wheel 文件。
可以从官方网站下载 twisted 的 wheel 文件:http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
请注意选择与您的Python环境相匹配的 wheel 文件进行下载。
# 6. 安装twisted
下载完成 twisted 的 wheel 文件后,可以使用以下命令安装 twisted:
pip3 install 下载目录\Twisted-17.9.0-cp36-cp36m-win_amd**.whl
将 下载目录 替换为您实际下载 twisted wheel 文件所在的目录
并根据您的 Python 环境选择正确的文件名进行替换。
报错解决方案
scrapy的基本使用
查看帮助 scrapy - h
- Project-only必须切到项目文件夹下才能执行
- Global的命令则不需要
Global commands:
startproject #创建项目
genspider #创建爬虫程序
settings #如果是在项目目录下,则得到的是该项目的配置
runspider #运行一个独立的python文件,不必创建项目
shell #scrapy shell url地址 在交互式调试,如选择器规则正确与否
fetch #独立于程单纯地爬取一个页面,可以拿到请求头
view #下载完毕后直接弹出浏览器,以此可以分辨出哪些数据是ajax请求
version #scrapy version 查看scrapy的版本,scrapy version -v查看scrapy依赖库的版本
Project-only commands:
crawl #运行爬虫,必须创建项目才行,确保配置文件中ROBOTSTXT_OBEY = False
check #检测项目中有无语法错误
list #列出项目中所包含的爬虫名
parse #scrapy parse url地址 --callback 回调函数 #以此可以验证我们的回调函数是否正确
bench #scrapy bentch压力测试
创建项目
须知:
- 路径不要包含中文
- 项目名称不要以数字开头
- 项目名称不建议包含汉字
# cd 到某一个目录下,然后执行 scrapy startproject 项目名
scrapy startproject spider
进入到项目里面
切换到爬虫项目录
cd spider
创建spider项目
创建自定义的爬虫程序脚本
# scrapy genspider 自定义爬虫名称 目标网址
# 这里的域名不需要添加协议,因为创建后scrapy会自动帮你加上协议
scrapy genspider QAQ www.QAQ.com
├── NewsPro # 项目名
│ ├── __init__.py
│ ├── items.py # 定义数据结构的地方,爬虫的数据包含哪一些 通俗的说 你要下载的数据都有哪一些
│ ├── middlewares.py # 中间件,用于处理请求和响应 也可以设置代理
│ ├── pipelines.py # 管道,用于数据持久化等操作 一般用来处理下载的数据
│ ├── settings.py # 项目配置文件,包含各种设置选项 比如robots协议 ua等
│ └── spiders # 存放自定义的爬虫,类似于应用程序
│ ├── __init__.py
│ ├── huanqiu.py # 自定义的爬虫文件 核心功能文件 *************
└── scrapy.cfg # Scrapy 项目配置文件
items.py:定义了项目中要抓取的数据模型,类似于 Django 中的 models.py 文件。您可以在这里定义项目需要爬取的数据结构。middlewares.py:中间件,用于在请求发送给服务器之前或从服务器返回给爬虫之后进行处理。您可以在这里添加各种中间件,例如代理、用户代理等。pipelines.py:管道,用于数据的后处理,比如数据的存储、清洗等操作。每个管道组件都是独立的,可以对数据进行不同的处理。settings.py:项目配置文件,包含了项目的各种配置选项,比如爬虫的设置、中间件的设置、管道的设置等。您可以在这里配置项目的各种参数。spiders目录:存放自定义的爬虫文件,用于实际的数据抓取工作。每个爬虫文件定义了一个独立的爬虫,用于从特定网站抓取数据。scrapy.cfg:Scrapy 项目配置文件,包含了项目的基本配置信息,比如项目的名称、版本号、部署设置等。
君子协议 robots.txt
# settings.py
# 默认为True,如果拿不到数据 改为False或者注释掉即可
ROBOTSTXT_OBEY = True
简单案例
# spider\mc.py
import scrapy
class McSpider(scrapy.Spider):
# 爬虫的名字,用于运行爬虫的时候 使用的值
name = "mc"
# 允许访问的域名,也就是除了这个域名以及子域名之外,其他的域名都不允许访问
allowed_domains = ["www.xx.com"]
# start_urls 是在allowed_domains前面加一个协议http/https, 后面加一个/【可选】
# 如果后缀是html的时候,后面是不允许加/的
start_urls = ["https://www.xx.com/"]
# parse是执行了start_urls之后执行的方法
# 方法中的response就是返回的那个对象
# 相当于 response = urllib.requests.urlopen()
# response = requests.get()
def parse(self, response):
print('小满最棒啦!')
如何运行
# cd到刚刚的爬虫项目的spider文件夹下,执行 scrapy crawl spider_name
scrapy crawl mc # 会打印日志
scrapy crawl mc --nolog # 不打印日志
scrapy的settings配置
基础配置
#1 项目名字,整个爬虫名字
BOT_NAME = "firstscrapy"
#2 爬虫存放位置的设置
SPIDER_MODULES = ["firstscrapy.spiders"]
NEWSPIDER_MODULE = "firstscrapy.spiders"
#3 是否遵循爬虫协议,一般都设为False
ROBOTSTXT_OBEY = False
# 4 User-Agent设置
USER_AGENT = "firstscrapy (+http://www.yourdomain.com)"
#5 日志级别设置
LOG_LEVEL='ERROR'
#6 DEFAULT_REQUEST_HEADERS 默认请求头
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
}
#7 SPIDER_MIDDLEWARES 爬虫中间件
SPIDER_MIDDLEWARES = {
'cnblogs.middlewares.CnblogsSpiderMiddleware': 543,
}
#8 DOWNLOADER_MIDDLEWARES 下载中间件
DOWNLOADER_MIDDLEWARES = {
'cnblogs.middlewares.CnblogsDownloaderMiddleware': 543,
}
#9 ITEM_PIPELINES 持久化配置
ITEM_PIPELINES = {
'cnblogs.pipelines.CnblogsPipeline': 300,
}
高级配置
#1 增加并发数,默认为16,可以根据需求进行调整
# 默认scrapy开启的并发线程为32个,可以适当进行增加。
# 值为100,并发设置成了为100。
# 在settings配置文件中修改
CONCURRENT_REQUESTS = 100
#2 降低日志级别,可设置为INFO或ERROR,减少日志输出,提高性能
# 在运行scrapy时,会有大量日志信息的输出,为了减少CPU的使用率。
# 可以设置log输出信息为INFO或者ERROR即可。
在配置文件中编写:
LOG_LEVEL = 'INFO'
# 3 禁止使用Cookie,默认为True,如果不需要使用Cookie可以设置为False
# 如果不是真的需要cookie,则在scrapy爬取数据时可以禁止cookie从而减少CPU的使用率,提升爬取效率。
COOKIES_ENABLED = False
# 4 禁止重试,默认为True,如果不需要进行重试请求可以设置为False
# 对失败的HTTP进行重新请求(重试)会减慢爬取速度,因此可以禁止重试。
RETRY_ENABLED = False
# 5 设置下载超时时间,默认180秒,可以根据需求进行调整
# 如果对一个非常慢的链接进行爬取,减少下载超时可以能让卡住的链接快速被放弃,从而提升效率。
# 超时时间为10s
DOWNLOAD_TIMEOUT = 10
持久化存储
parse的返回值
每个爬虫中的
parse方法以及其他后续解析方法通常需要返回一个可迭代对象(如列表),其中包含的是经过处理后的数据结构,通常是符合Item定义的字典。
def parse(self, response):
items = []
for element in response.css('some_selector'):
item = {
'field1': element.xpath('...').get(),
'field2': element.xpath('...').get(),
}
items.append(item)
return items
命令行导出json和csv
# settings.py
FEED_FORMAT = 'json' # 选择要导出的格式,可以选择 'json' 或 'csv'
FEED_URI = 'output_file.json' # 指定要保存的文件路径,可以是 'output_file.json' 或 'output_file.csv'
# 导出json文件
scrapy crawl your_spider_name -o output.json
# 导出csv
scrapy crawl your_spider_name -o output.csv -t csv
response的属性和方法
response.text # 结果源码,同response.text 一样 是字符串
respnse.body # 解码源码,同response.content 一样 结果是二进制
response.xpath() # 可以直接使用xpath语法来解析response中的内容 和正常的xpath一样,所有的selector都可以再次进行xpath
response.extract() # 提取selector对象的data属性值
response.extract_first() # 提取的是select列表的第一个数据
# 没有写extract()
[<Selector query='//div[@class="slist"]//li[1]' data='<li><a href="/tupian/34023.html" titl...'>]
# 写了没有写extract()
['<li><a href="/tupian/34023.html" title="报纸墙女孩粉色头发4K动漫壁纸" target="_blank"><span><img src="/uploads/allimg/240403/002821-1712075301366c.jpg" alt="报纸墙女孩粉色头发4K动漫壁纸"></span><b>报纸墙女孩粉色头发4K动漫壁纸</b></a></li>']
attributes # 请求的属性,包括方法、URL、头部信息等
body # 响应的正文内容
cb_kwargs # 在回调函数中传递额外的关键字参数
certificate # 响应中的 SSL 证书信息
copy # 复制当前的 Response 对象
css # 使用 CSS 选择器从响应中提取数据
encoding # 响应的编码格式
flags # 请求的标志,例如是否跟踪重定向等
follow # 根据响应的状态码决定是否跟踪重定向
follow_all # 跟踪所有重定向
headers # 响应的头部信息
ip_address # 请求的 IP 地址
jmespath # 使用 JMESPath 查询从响应中提取数据
json # 解析响应的 JSON 内容
meta # 请求和响应的元数据信息
protocol # 请求的协议,例如 HTTP 或 HTTPS
replace # 替换当前的 Request 对象
request # 当前的 Request 对象
selector # 使用 Selector 对象从响应中提取数据
status # 响应的状态码
text # 响应的文本内容
url # 请求的 URL
urljoin # 将相对 URL 转换为绝对 URL
xpath # 使用 XPath 从响应中提取数据
CSS选择器 response.css
# 获取属性 response.css("选择器 ::('属性值')")
response.css(".slist img ::attr('alt')") # 提取图片的alt属性
response.css(".slist b::text") # 提取文本的直接内容
extract()和extract_first()
extract() 和 extract_first() 方法都是用于从 Scrapy 的 Selector 对象中提取文本内容的方法。
extract()方法会提取所有匹配的内容,并将其以列表的形式返回。如果有多个匹配项,将返回多个文本内容。extract_first()方法会提取第一个匹配的内容,并将其作为字符串返回。如果没有匹配项,则返回None。
这两个方法通常与 XPath 或 CSS 选择器一起使用,用于从网页中提取所需的数据。例如:
# 使用 XPath 提取所有匹配的文本内容
texts = response.xpath('//div[@class="content"]/p/text()').extract()
# 使用 CSS 选择器提取第一个匹配的文本内容
first_text = response.css('h1::text').extract_first()
在这个例子中,extract() 和 extract_first() 方法用于提取网页中特定元素的文本内容,以供后续处理或存储。
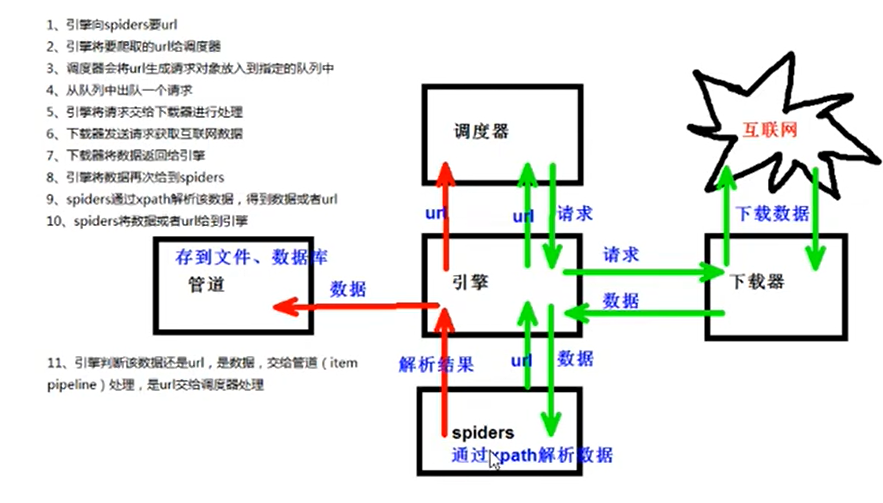
scrapy的工作原理
如果是数据,就交给管道下载,如果还是一个要请求的url,就在走一遍。
scrapy shell
- 什么是scrapy shell?
- scrapy终端,是一个交互终端,供您在未启动scrapy的情况下尝试及调试您的爬虫代码。其本意是用来测试提取数据的代码,不过您可以将其作为正常的python终端,在上面测试任何的python代码。
- 该终端是用来测试XPath或CSS表达式,查看他们的工作方式及从爬取的网页中提取的数据,在编写您的spider时,该终端提供了交互性测试您的表达代码的功能,免去了每次修改后运行spider的麻烦。
- 一旦熟悉了scrapy终端后,您会发现其在开发和调试spider时发挥的巨大作用。
- 安装ipython
- 安装:pip install ipython
- 简介:如果您安装了ipython,scrapy的终端将使用ipython(替代标准python终端), ipython终端与其他相比更为强大,提供了智能的自动补全,高亮输出,及其他特性。
如何进入终端
# 直接在cmd窗口中 输入 scrapy shell 域名
scrapy shell www.xx.com
yield
- 带有yield的函数不再是一个普通函数,而是一个生成器generator,可用于迭代
- yield是一个类似return的关键字,迭代一次遇到yield时,就返回yield后面(右边)的值,重点是:下一次迭代时,从上一次迭代遇到的yield后面的代码(下一行)开始执行
- 简要理解:yield就是return返回的一个值,并且记住这个值的返回位置,下次迭代就从这个位置后(下一行)开始。
梳理流程
# spider\book.py
import scrapy
from ..items import DangdangItem
class BookSpider(scrapy.Spider):
name = "book"
allowed_domains = ["xxx"]
start_urls = ["xxx"]
def parse(self, response):
# src = '//ul[@id="component_59"]//li/a/img/@src'
# title = '//ul[@id="component_59"]//li/a/img/@alt'
# price = '//ul[@id="component_59"]//li/p[@class="price"]/span[1]/text()'
li_list = response.xpath('//ul[@id="component_59"]//li')
for li in li_list:
src = li.xpath('./a/img/@data-original').extract_first()
name = li.xpath('./a/img/@alt').extract_first()
price = li.xpath('./p[@class="price"]/span[1]/text()').extract_first()
# print(src, name, price)
# 这个对象要交给管道pipelines去下载
book = DangdangItem(src=src, name=name, price=price)
# 获取一个book 就将book交给pipelines
yield book
# items.py
# 就相当于django里面的模型层
class DangdangItem(scrapy.Item):
# 名字
name = scrapy.Field()
# 图片
src = scrapy.Field()
# 价格
price = scrapy.Field()
# pipelines.py
# 如果想要使用管道的话,那么就必须在settings中开启管道
class DangdangPipeline:
# item 就是book后面的yield对象, 也就是你的spider下面的爬虫返回的数据的
def process_item(self, item, spider):
# 以下这种方法不推荐 因为操作IO太过频繁
# 1. write写入必须是一个字符串,而不能是其他的对象
# 2. w模式会覆盖写
with open('book.json', 'at', encoding='utf-8') as file:
file.write(str(item) + "\n")
# 默认的item类型是<class 'dangdang.items.DangdangItem'> 这里可以使用字典强转,然后操作就可以了
# data = dict(item)
return item
item
# 可以通过get取值,但是并不是字典的类型,参考上面
src = item.get('src')
name = item.get('name')
# 这个键就是你在item里面定义的
open_spider和close_spider
# pipelines.py
class DangdangPipeline:
# 在爬虫文件开始之前就执行的一个方法
# 名字不能写错 要指定参数
def open_spider(self, spider):
print('+++++++++++++++++++++++++++++++++++++++++++++++')
def process_item(self, item, spider):
return item
# 在爬虫执行完毕之后,执行的方法
def close_spider(self, spider):
print('-----------------------------------------------------')
"""
+++++++++++++++++++++++++++++++++++++++++++++++
下面全是spider里面的代码
//img3m3.ddimg.cn/71/16/29687003-1_b_1711521731.jpg 骄阳似我(下)(亲签版) ¥32.00
//img3m2.ddimg.cn/46/8/29124262-1_b_5.jpg 那个不为人知的故事 ¥20.10
//img3m8.ddimg.cn/72/12/23945598-1_b_1706687985.jpg 大哥(套装共2册) ¥32.00
//img3m4.ddimg.cn/72/17/29687004-1_b_1711521722.jpg 骄阳似我(上下 两册套装) ¥49.00
......
-----------------------------------------------------
"""
# 优化后的代码
import json
from itemadapter import ItemAdapter
# 如果想要使用管道的话,那么就必须在settings中开启管道
class DangdangPipeline:
# 在爬虫开始之前执行的方法
def open_spider(self, spider):
# 初始化一个空列表,用来存储爬取的数据
self.data_list = []
# 处理每个爬取到的数据项
def process_item(self, item, spider):
# 将每个数据项转换成字典格式
data = dict(item)
# 将数据项添加到列表中
self.data_list.append(data)
# 返回item,这样其他的pipeline组件(如果有的话)也能处理该item
return item
# 在爬虫执行完毕后执行的方法
def close_spider(self, spider):
# 将爬取到的数据列表写入到JSON文件中
with open('book.json', 'wt', encoding='utf-8') as file:
json.dump(self.data_list, file, ensure_ascii=False)
# settings.py
# 管道默认没有开启
# 开启管道,管道是有优先级的,优先级的返回是1-1000 数字越低 优先级越高 默认是300
ITEM_PIPELINES = {
"dangdang.pipelines.DangdangPipeline": 300,
}
开启多条管道 (模仿就行)
不同管道可以执行不同的任务,比如你保存数据,我下载图片到本地。
# 1. 在pipelines.py中 模仿默认的类去写,类名随意,里面定义一样的方法就行 process_item(self, item, spider).
# 例如
class ImageDownload:
def process_item(self, item, spider):
# 写逻辑
return item
# 2. 在settings中,一样模仿默认的去写
ITEM_PIPELINES = {
"dangdang.pipelines.DangdangPipeline": 300, # 这个是默认的,DangdangPipeline是创建scrapy就创建好的类名
"dangdang.pipelines.ImageDownload": 301 # 这个是自己新增的,ImageDownload 就是你自己定义的类名
}
# 完毕
# 引入必要的库
from pathlib import Path
import json
from urllib.request import urlretrieve
from itemadapter import ItemAdapter
# 设置存储图片的文件夹路径
BASE_DIR = Path(__file__).parent
path = BASE_DIR / 'images'
path.mkdir(parents=True, exist_ok=True)
# 定义第一个管道类,用于处理数据保存到 JSON 文件中
class DangdangPipeline:
# 在爬虫开始之前执行的方法
def open_spider(self, spider):
# 初始化一个空列表,用于存储爬取的数据
self.data_list = []
# 处理每个爬取到的数据项
def process_item(self, item, spider):
# 将每个数据项转换成字典格式
data = dict(item)
# 打印图片链接
print(item.get('src'))
# 将数据项添加到列表中
self.data_list.append(data)
# 返回 item,这样其他的 pipeline 组件(如果有的话)也能处理该 item
return item
# 在爬虫执行完毕后执行的方法
def close_spider(self, spider):
# 将爬取到的数据列表写入到 JSON 文件中
with open('book.json', 'wt', encoding='utf-8') as file:
json.dump(self.data_list, file, ensure_ascii=False)
# 定义第二个管道类,用于下载图片
# "dangdang.pipelines.ImageDownload": 301
class ImageDownload:
def process_item(self, item, spider):
# 获取书籍名称和图片链接
name = item.get('name')
src = f"http:{item.get('src')}"
# 使用 urllib 库下载图片,并保存到指定路径下
urlretrieve(src, filename=f'{path}/{name}.png')
# 返回 item,以便其他 pipeline 组件(如果有的话)继续处理该 item
return item
使用异步下载
import aiohttp
import aiofiles
import asyncio
import os
from itemadapter import ItemAdapter
class ImageDownload:
def __init__(self):
self.session = None
async def download_image(self, url, filename):
# 使用 aiohttp 库发送异步请求下载图片
async with self.session.get(url) as response:
# 如果响应状态为 200,则表示请求成功
if response.status == 200:
# 使用 aiofiles 库异步写入文件
async with aiofiles.open(filename, 'wb') as f:
await f.write(await response.read())
async def process_item(self, item, spider):
# 获取书籍名称和图片链接
name = item.get('name')
src = f"http:{item.get('src')}"
# 拼接图片文件路径
filename = os.path.join(path, f"{name}.png")
# 创建 aiohttp 的异步会话
async with aiohttp.ClientSession() as session:
self.session = session
# 调用异步下载图片的方法
await self.download_image(src, filename)
return item
多页下载
清楚一件事情:每一页的业务逻辑都是完全一样的,只需要开启多页就可以了,怎么开启?
- 我们只需要将执行页的那个请求,再次调用parse方法就可以了
# spider\your_spider.py
import scrapy
from ..items import DangdangItem
class BookSpider(scrapy.Spider):
name = "book"
# 如果是多页下载,那么必须要调整allowed_domains的范围,一般只写域名
allowed_domains = ["xx"]
start_urls = ["xx"]
base_url = "xx"
page = 1
def parse(self, response):
# src = '//ul[@id="component_59"]//li/a/img/@src'
# title = '//ul[@id="component_59"]//li/a/img/@alt'
# price = '//ul[@id="component_59"]//li/p[@class="price"]/span[1]/text()'
li_list = response.xpath('//ul[@id="component_59"]//li')
for li in li_list:
src = li.xpath('./a/img/@data-original').extract_first()
name = li.xpath('./a/img/@alt').extract_first()
price = li.xpath('./p[@class="price"]/span[1]/text()').extract_first()
# print(src, name, price)
# 这个对象要交给管道pipelines去下载
book = DangdangItem(src=src, name=name, price=price)
# 获取一个book 就将book交给pipelines
yield book
if self.page < 100:
self.page += 1
url = f"{self.base_url}{self.page}-cp01.01.02.00.00.00.html"
# 怎么去调用parse方法
# yield Request 这个就是scrapy的get请求
# url就是请求的地址 callback就是要执行的函数,放内存地址就行,不需要加括号
yield scrapy.Request(url, callback=self.parse)
meta的使用
在 Scrapy 中,yield scrapy.Request 方法用于发送HTTP请求,并且可以传递额外的元数据(metadata)信息给回调函数。这些额外的元数据可以在后续处理中使用。
具体来说,meta 参数是一个字典,可以包含任意键值对的信息。当你使用 yield scrapy.Request(url, callback=self.parse_detail, meta={'key': 'value'}) 发送请求时,你可以在 parse_detail 回调函数中通过 response.meta['key'] 来获取传递的值。
例如,假设你有一个爬虫,爬取网页中的标题和链接,并且想要将标题和链接一起保存到数据库中。你可以使用 meta 参数将标题传递给下一个回调函数。示例代码如下:
import scrapy
class MySpider(scrapy.Spider):
name = 'myspider'
def start_requests(self):
urls = ['https://example.com/page1', 'https://example.com/page2']
for url in urls:
yield scrapy.Request(url, callback=self.parse_title)
def parse_title(self, response):
title = response.css('h1::text').get()
yield scrapy.Request(response.url, callback=self.parse_detail, meta={'title': title})
def parse_detail(self, response):
title = response.meta['title']
link = response.url
# Save title and link to database or do other processing
在上面的示例中,parse_title 方法提取页面的标题,并将标题作为元数据传递给 parse_detail 方法。在 parse_detail 方法中,可以通过 response.meta['title'] 获取到传递过来的标题信息。
这样,通过使用 meta 参数,可以方便地在 Scrapy 中传递和共享数据信息。
连接提取器 CrawlSpider
1. 继承自scrapy.Spider
2. 独门秘籍
- crawlSpider可以自定义规则,在解析HTML内容的时候,可以根据连接规则提取出指定的连接,然后再向这些连接发送请求。
- 比如,不知道一共有多少页,就可以使用crawlspider
- 所以,如果有需要跟进连接的需求,意思就是爬取了网页之后,需要提取连接再次爬取,使用crawlSpider是非常合适的。
3. 提取链接
链接提取器,在这里就可以写规则提取指定连接
scrapy.linkextractors.LinkExtractor(
allow=(), # 正则表达式,提取符合正则规则的链接
deny=(), # (不用)正则表达式,不提取符合正则规则的链接
allow_domains=(), # (不用)允许的域名
deny_domains=(), # (不用)不允许的域名
restrict_xpaths=(), # XPath,提取符合XPath规则的链接
restrict_css=() # CSS选择器,提取符合CSS选择器规则的链接
)
4. 模拟使用
from scrapy.linkextractors import LinkExtractor # 导入必要的模块
正则用法:links1 = linkExtractor(allow='list_23_\d+\.html')
xpath用法:links2 = linkExtractor(restrict_xpaths=r'//div[@class="x"]') # 这里记得是xpaths不是xpath
css用法:links3 = LinkExtractor(restrict_css=".x")
5. 提取连接
link.extract_links(response) # link1.extract_links(response) ...
6. 注意事项
【注意1】callback只能写函数名字符串,callback="parse_item"
【注意2】在基本的spider中,如果重新发送请求,那里的callback写的是 callback=self.parse_item
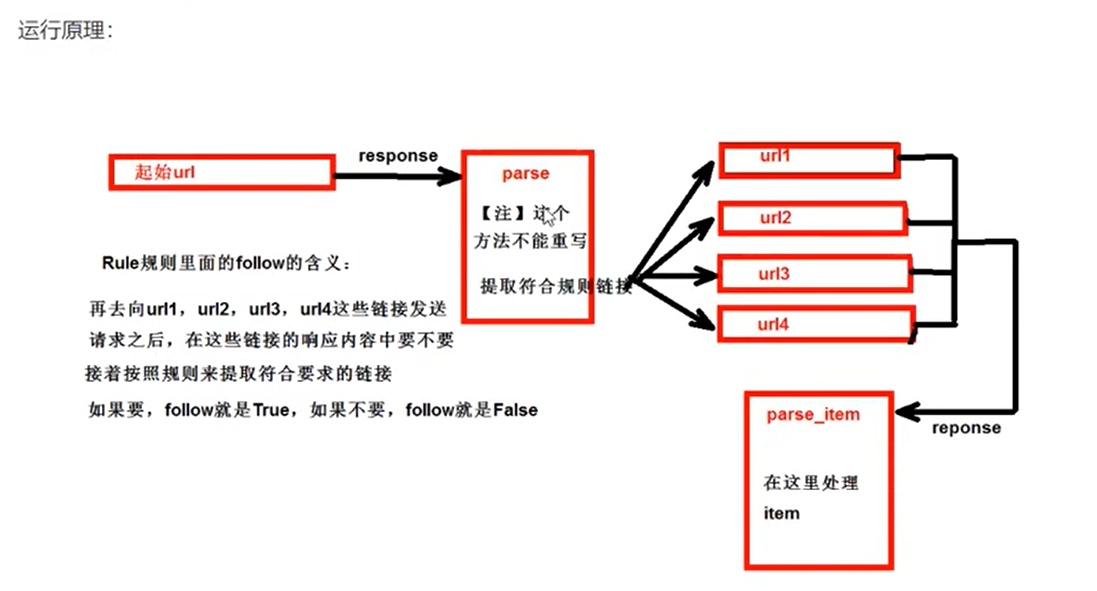
fllow=true # 是否更进,就是按照提取连接规则进行提取
fllow=True
CrawlSpider中的follow=True参数表示是否在爬取页面时遵循定义的规则(Rule)。如果follow=True,则爬虫会根据规则继续跟进页面,解析页面中的链接,并且对这些链接再次进行爬取。换句话说,它会让爬虫继续向下深入爬取新的页面。
通常情况下,当follow=True时,爬虫会继续爬取满足规则条件的链接,直到满足某种条件(比如达到指定的页数、深度等)或者没有新的链接可爬取为止。因此,这个参数可以用来控制爬虫的深度和范围。
总之,follow=True会使爬虫按照定义的规则继续爬取新的页面,直到满足指定条件为止。
如何使用crawlspider
1. cd到某个目录,然后正常创建爬虫项目
- scrapy startproject 项目的名字
2. 跳转到spiders文件夹的目录下
- cd项目名字\项目名字\spiders
3. 创建爬虫文件 (区别于一般的创建 --> scrapy genspider 爬虫的名字 爬取的域名)
- 要使用下面的创建语法
- scrapy genspider -t crawl 爬虫文件的名字 爬取的域名
# 使用crawlspider创建后的spider
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
class ReadSpider(CrawlSpider):
name = "read"
allowed_domains = ["www.xx.com"]
start_urls = ["https://www.xx.com/book/1188_1.html"]
rules = (Rule(LinkExtractor(allow=r"Items/"), callback="parse_item", follow=True),)
def parse_item(self, response):
item = {}
# 下面几个注释的是创建后就自动生成的,我们不适用这种,删除就行。
#item["domain_id"] = response.xpath('//input[@id="sid"]/@value').get()
#item["name"] = response.xpath('//div[@id="name"]').get()
#item["description"] = response.xpath('//div[@id="description"]').get()
return item
写入json文件
# spider\read.py
import scrapy
from ..items import ReadbookItem
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
class ReadSpider(CrawlSpider):
name = "read"
allowed_domains = ["www.xx.com"]
start_urls = ["https://www.xx.com/book/1188_1.html"]
rules = (Rule(LinkExtractor(
allow=r"/book/1188_\d+\.html"),
callback="parse_item", # callback只能写函数名字符串,callback="parse_item"
follow=True),)
def parse_item(self, response):
data_list = response.xpath("//div[@class='book-info']/div/a/img")
for line in data_list:
name = line.xpath("./@alt").extract_first()
src = line.xpath("./@data-original").extract_first()
print(name, src)
book = ReadbookItem(name=name, src=src)
yield book
# items.py
import scrapy
class ReadbookItem(scrapy.Item):
name = scrapy.Field()
src = scrapy.Field()
# pipelines.py
import json
from itemadapter import ItemAdapter
class ReadbookPipeline:
def open_spider(self, spider):
# 在爬虫启动时初始化一个空列表用来存储数据
self.data_list = []
def process_item(self, item, spider):
# 将Item对象转换为字典格式并添加到数据列表中
data = dict(item)
self.data_list.append(data)
return item # 返回Item对象
def close_spider(self, spider):
# 当爬虫关闭时,将数据列表写入到JSON文件中
with open('book.json', 'wt', encoding='utf-8') as file:
json.dump(self.data_list, file, ensure_ascii=False)
写入数据库 sqlalchemy
注意!commit一定要拿到一个数据就提交一次!!
数据库设置
# settings.py 中任意位置添加
DB_HOST = "localhost" # 数据库主机地址 localhost同107.0.0.1
DB_PORT = 3306 # 数据库端口号
DB_USER = "root" # 数据库用户名
DB_PASSWORD = "123456" # 数据库密码
DB_NAME = "spider1" # 数据库名称
DB_CHARSET = 'utf8' # 数据库字符集设置 这里不能加横杠 -
加载settings文件
如果用得到,因为我使用的是sqlalchemy,所以压根就不需要设置settings
from scrapy.utils.project import get_project_settings
核心代码
# items.py
import scrapy
class ReadbookItem(scrapy.Item):
# 定义您的数据项字段在这里,例如:
name = scrapy.Field() # 书名
src = scrapy.Field() # 链接地址
# spiders\read.py
import scrapy
from ..items import ReadbookItem # 导入自定义的数据项类 ReadbookItem
from scrapy.linkextractors import LinkExtractor # 导入 LinkExtractor 类
from scrapy.spiders import CrawlSpider, Rule # 导入 CrawlSpider 类和 Rule 类
class ReadSpider(CrawlSpider):
name = "read" # 爬虫的名称
allowed_domains = ["www.xx.com"] # 允许爬取的域名
start_urls = ["https://www.xx.com/book/1188_1.html"] # 爬虫启动的起始链接
rules = (Rule(LinkExtractor(
allow=r"/book/1188_\d+\.html"), # 定义规则,允许匹配的链接格式
callback="parse_item", # 指定回调函数为 parse_item 这里只能给字符串
follow=False),) # 不跟踪提取到的链接 ,如果要跟踪爬取设置为True即可,一般设置为True
def parse_item(self, response):
data_list = response.xpath("//div[@class='book-info']/div/a/img") # 使用 XPath 选择器提取书籍信息
for line in data_list:
name = line.xpath("./@alt").extract_first() # 提取书名
src = line.xpath("./@data-original").extract_first() # 提取链接地址
print(name, src) # 打印提取到的书名和链接地址
book = ReadbookItem(name=name, src=src) # 创建一个 ReadbookItem 实例
yield book # 返回提取的数据项
import scrapy
from ..items import ReadbookItem
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
class ReadSpider(CrawlSpider):
name = "read"
allowed_domains = ["www.dushu.com"]
start_urls = ["https://www.dushu.com/book/1188_1.html"]
rules = (Rule(LinkExtractor(
allow=r"/book/1188_\d+\.html"),
callback="parse_item", # callback只能写函数名字符串,callback="parse_item"
follow=False),)
def parse_item(self, response):
data_list = response.xpath("//div[@class='book-info']/div/a/img")
for line in data_list:
name = line.xpath("./@alt").extract_first()
src = line.xpath("./@data-original").extract_first()
print(name, src)
book = ReadbookItem(name=name, src=src)
yield book #
# pipelines.py
import json
import sqlalchemy
from sqlalchemy.orm import sessionmaker
from sqlalchemy.ext.declarative import declarative_base
from itemadapter import ItemAdapter
# 创建数据库引擎
engine = sqlalchemy.create_engine("mysql://root:243204@localhost/spider1?charset=utf8")
# 创建基础模型类
Base = declarative_base()
# 定义书籍类
class ReadBook(Base):
__tablename__ = "readbook"
id = sqlalchemy.Column(sqlalchemy.Integer, primary_key=True, autoincrement=True)
name = sqlalchemy.Column(sqlalchemy.String(128), nullable=True)
src = sqlalchemy.Column(sqlalchemy.String(255), nullable=True)
# 创建所有的表结构
Base.metadata.create_all(engine)
# 创建数据库会话
Session = sessionmaker(bind=engine)
class ReadbookPipeline:
def open_spider(self, spider):
self.data_list = []
def process_item(self, item, spider):
data = dict(item)
self.data_list.append(data)
return item
def close_spider(self, spider):
# 将数据写入 JSON 文件
with open('book.json', 'wt', encoding='utf-8') as file:
json.dump(self.data_list, file, ensure_ascii=False)
class MysqlPipeline:
def open_spider(self, spider):
# 在爬虫启动时创建数据库会话
self.session = Session()
def process_item(self, item, spider):
# 处理每个条目并将其添加到数据库会话中
book = ReadBook(
name=item['name'],
src=item['src']
)
self.session.add(book)
# 每次处理完一个条目就提交一次
self.session.commit()
def close_spider(self, spider):
# 在爬虫关闭时提交事务并关闭数据库会话
self.session.commit()
self.session.close() # 关闭数据库会话
日志信息和等级
1. 日志级别
- CRITICAL: 严重错误
- ERROR: 一般错误
- WARNING: 警告
- INFO: 一般信息
- DEBUG: 调试信息
默认的日志等级是DEBUG
只要出现了DEBUG或者DEBUG以上等级的日志
那么这些日志就会打印
2. settings.py文件设置
默认的级别为DEBUG,会显示上面所有的信息
在配置文件中 settings.py
LOG_FILE:将屏幕显示的信息全部记录到文件中,屏幕不再显示,注意文件后续一定是.log
LOG_LEVEL: 设置日志显示的等级,就是显示哪些,不显示哪些
eg:
- LOG_FILE = "logdemo.log"
- LOG_LEVEL = "LEVEL" # 一般不会设置等级, 而是写入到文件里面,方便查错,定义此项后,后续的日志记录就会追加到这个日志里面
- 执行语句后面添加 --nolog
- scrapy crawl xx --nolog
【*】 推荐使用LOG_FILE 的方式
scrapy的post请求
# 1. 重写start_requests方法
def start_requests(self)
# 2. start_requests的返回值
scrapy.FromFequest(url=url, headers=headers, callback=self.parse_item, formdata=data)
url: 要发送的post地址
headers: 可以定制头信息
callback: 回调函数
formdata: post所携带的数据,这是一个字典
import json
import scrapy
class TestpostSpider(scrapy.Spider):
name = "testpost"
allowed_domains = ["fanyi.baidu.com"]
# post请求 如果不写任何参数,那么写过请求将会没有任何的意义
# 所以 这个start_urls也没有用了
# 由于parse依赖于start_urls 所以 parse也没有用了
# start_urls = ["https://fanyi.baidu.com/sug"]
# def parse(self, response):
# pass
def start_requests(self):
url = "https://fanyi.baidu.com/sug"
data = {"kw": "cancer"}
yield scrapy.FormRequest(url=url, formdata=data, callback=self.parse_second)
def parse_second(self, response):
content = response.body
data = json.loads(content)
print(data)
爬虫中间件和下载中间件
爬虫中间件
# 爬虫中间件
class Day06StartSpiderMiddleware:
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the spider middleware does not modify the
# passed objects.
@classmethod
def from_crawler(cls, crawler):
# 该方法是Scrapy用于创建爬虫实例的方法。
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_spider_input(self, response, spider):
# 当响应从爬虫中间件进入爬虫时,调用该方法进行处理。
# 应返回None或引发异常。
# Called for each response that goes through the spider
# middleware and into the spider.
# Should return None or raise an exception.
return None
def process_spider_output(self, response, result, spider):
# 当爬虫处理完响应后,调用该方法对处理结果进行处理。
# 必须返回一个可迭代的Request对象或item对象。
# Called with the results returned from the Spider, after
# it has processed the response.
# Must return an iterable of Request, or item objects.
for i in result:
yield i
def process_spider_exception(self, response, exception, spider):
# 当爬虫中抛出异常时,调用该方法进行处理。
# 应返回None或者一个可迭代的Request对象或item对象。
# Called when a spider or process_spider_input() method
# (from other spider middleware) raises an exception.
# Should return either None or an iterable of Request or item objects.
pass
def process_start_requests(self, start_requests, spider):
# 在爬虫启动时,对初始请求进行处理。
# Called with the start requests of the spider, and works
# similarly to the process_spider_output() method, except
# that it doesn’t have a response associated.
# Must return only requests (not items).
for r in start_requests:
yield r
def spider_opened(self, spider):
spider.logger.info("Spider opened: %s" % spider.name)
这段代码是一个爬虫中间件,用于在Scrapy框架中对爬虫进行处理。下面是对每个方法的功能和用途的详细解释:
class Day06StartSpiderMiddleware: # Not all methods need to be defined. If a method is not defined, # scrapy acts as if the spider middleware does not modify the # passed objects. @classmethod def from_crawler(cls, crawler): # 该方法是Scrapy用于创建爬虫实例的方法。 s = cls() crawler.signals.connect(s.spider_opened, signal=signals.spider_opened) return s
from_crawler方法是一个类方法,它会在创建爬虫实例时被Scrapy调用,用于初始化爬虫中间件的实例。在该方法中,首先创建了一个中间件实例s,然后通过crawler.signals.connect方法连接了spider_opened信号和对应的处理方法。def process_spider_input(self, response, spider): # 当响应从爬虫中间件进入爬虫时,调用该方法进行处理。 # 应返回None或引发异常。 return None
process_spider_input方法会在响应从爬虫中间件传递到爬虫之前调用。它接收两个参数:response是响应对象,spider是当前爬虫实例。这个方法可以用来对响应进行预处理或检查。应该返回None或引发异常。def process_spider_output(self, response, result, spider): # 当爬虫处理完响应后,调用该方法对处理结果进行处理。 # 必须返回一个可迭代的Request对象或item对象。 for i in result: yield i
process_spider_output方法在爬虫处理完响应后会被调用。它接收三个参数:response是爬虫处理后的响应对象,result是爬虫的处理结果,spider是当前爬虫实例。这个方法主要用于对爬虫处理结果进行进一步处理或过滤,并将处理结果返回。必须返回一个可迭代的Request对象或item对象。def process_spider_exception(self, response, exception, spider): # 当爬虫中抛出异常时,调用该方法进行处理。 # 应返回None或者一个可迭代的Request对象或item对象。 pass
process_spider_exception方法在爬虫或process_spider_input()方法中抛出异常时会被调用。它接收三个参数:response是发生异常的响应对象,exception是抛出的异常对象,spider是当前爬虫实例。这个方法可以用来对爬虫处理过程中的异常进行处理,可以返回None或一个可迭代的Request对象或item对象。def process_start_requests(self, start_requests, spider): # 在爬虫启动时,对初始请求进行处理。 # Must return only requests (not items). for r in start_requests: yield r
process_start_requests方法在爬虫启动时被调用,用于对初始请求进行处理。它接收两个参数:start_requests是初始请求的列表,spider是当前爬虫实例。这个方法必须返回一个可迭代的Request对象,而不能返回item对象。def spider_opened(self, spider): spider.logger.info("Spider opened: %s" % spider.name)
spider_opened方法在爬虫打开时被调用。它接收一个参数spider,表示当前爬虫实例。在这个方法中,通过日志记录器(logger)输出 "Spider opened: 爬虫名称" 的信息。
下载中间件
# 下载中间件
class Day06StartDownloaderMiddleware:
# 不是所有的方法都需要定义。如果某个方法没有被定义,
# Scrapy会认为这个下载中间件不会修改传递的对象。
@classmethod
def from_crawler(cls, crawler):
# Scrapy使用该方法创建您的爬虫。
s = cls()
# 通过signals连接spider_opened信号和spider_opened方法
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
# 拦截处理所有的请求对象
# 参数:request就是拦截到的请求对象,spider爬虫文件中爬虫类实例化的对象
# spider参数的作用可以实现爬虫类和中间类的数据交互
def process_request(self, request, spider):
# 返回None:继续处理本次请求,执行下一个中间件的process_request方法
# 返回一个Response对象:执行当前中间件的process_response方法,重新回到引擎,被调度
# 返回一个Request对象:直接返回给引擎,被调度。进入调度器等待下次被调用
# 抛出IgnoreRequest异常:调用已安装的下载中间件的process_exception方法
return None
# 拦截处理所有的响应对象
# 参数:response就是拦截到的响应对象,request就是被拦截到响应对象对应的唯一的一个请求对象
def process_response(self, request, response, spider):
# - 返回一个Response对象:继续执行,进入引擎,被调度到爬虫进行解析
# - 返回一个Request对象:进入引擎,返回到调度器被重新调用
# - 或者抛出IgnoreRequest异常:抛出异常
return response
# 拦截和处理发生异常的请求对象
# 参数:reqeust就是拦截到的发生异常的请求对象
# 方法存在的意义:将发生异常的请求拦截到,然后对其进行修正
def process_exception(self, request, exception, spider):
# 当下载处理程序或process_request()方法(来自其他下载中间件)引发异常时调用。
# 必须返回以下之一:
# - 返回None:继续处理该异常
# - 返回一个Response对象:停止process_exception()链
# - 返回一个Request对象:停止process_exception()链
pass
# 控制日志数据的(忽略)
def spider_opened(self, spider):
spider.logger.info("Spider opened: %s" % spider.name)
from_crawler(cls, crawler)方法:该方法是Scrapy用来创建爬虫的入口点。它返回一个中间件对象,并通过crawler.signals连接到spider_opened信号,以便在爬虫开启时执行相应的操作。process_request(self, request, spider)方法:该方法在发送请求之前被调用。您可以在此方法中对请求进行处理和修改。返回值决定了后续处理的行为,可以是None继续处理当前请求,返回一个Response对象以便执行process_response方法,返回一个Request对象以便重新调度,或者抛出IgnoreRequest异常以调用其他下载中间件的process_exception方法。process_response(self, request, response, spider)方法:该方法在收到响应后被调用。您可以在此方法中对响应进行处理和修改。返回值决定了后续处理的行为,可以是返回Response对象以便进一步处理和解析,返回Request对象以便重新调度,或者抛出IgnoreRequest异常。process_exception(self, request, exception, spider)方法:当下载处理程序或其他下载中间件的process_request方法引发异常时调用该方法。您可以在此处处理异常,并根据需要返回值。spider_opened(self, spider)方法:在爬虫开启时被调用。在这个示例中,它会输出一个日志信息。
配置文件
# Enable or disable spider middlewares
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
SPIDER_MIDDLEWARES = {
"day06Start.middlewares.Day06StartSpiderMiddleware": 543,
}
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {
"day06Start.middlewares.Day06StartDownloaderMiddleware": 543,
请求头相关
修改请求头
在下载中间件的def process_request(self, request, spider):写代码
加代理
- 在下载中间件写process_request方法
def get_proxy(self):
import requests
res = requests.get('http://127.0.0.1:5010/get/').json()
if res.get('https'):
return 'https://' + res.get('proxy')
else:
return 'http://' + res.get('proxy')
def process_request(self, request, spider):
request.meta['proxy'] = self.get_proxy()
return None
- 代理可能不能用,会触发process_exception,在里面写
def process_exception(self, request, exception, spider):
# 第二步:代理可能不能用,会触发process_exception,在里面写
def process_exception(self, request, exception, spider):
print('-----', request.url) # 这个地址没有爬
return request
加cookies
def process_request(self, request, spider):
# 添加cookie
request.cookies['cookies'] = 'cookies'
print(request.url+':请求对象拦截成功!')
return None
修改请求头
def process_request(self, request, spider):
request.headers['referer'] = 'http://www.lagou.com'
return None
随机UA
# 动态生成User-agent使用
def process_request(self, request, spider):
# fake_useragent模块
from fake_useragent import UserAgent
request.headers['User-Agent']=str(UserAgent().random)
pprint(request.url+':请求对象拦截成功!')
return None
小结
def process_request(self, request, spider):
# 返回None:继续处理本次请求,执行下一个中间件的process_request方法
# 返回一个Response对象:执行当前中间件的process_response方法,重新回到引擎,被调度
# 返回一个Request对象:直接返回给引擎,被调度。进入调度器等待下次被调用
# 抛出IgnoreRequest异常:调用已安装的下载中间件的process_exception方法
# 构建代理池
# 第一步:构建代理池
def get_proxy(self):
import requests
res = requests.get('http://127.0.0.1:5010/get/').json()
if res.get('https'):
return 'https://' + res.get('proxy')
else:
return 'http://' + res.get('proxy')
def process_request(self, request, spider):
# 在 meta 中加入代理
request.meta['proxy'] = self.get_proxy()
# 代理可能不能用,会触发process_exception,在里面写
return None
# 添加cookie
request.cookies['cookies'] = 'cookies'
# 修改请求头
request.headers['referer'] = 'http://www.lagou.com'
# 动态生成User-agent使用
request.headers['User-Agent'] = str(UserAgent().random)
return None
def process_exception(self, request, exception, spider):
# 第二步:代理可能不能用,会触发process_exception,在里面写
def process_exception(self, request, exception, spider):
print('-----', request.url) # 这个地址没有爬
return request