2024.3.13 位置编码(Poitional Encoding)
Self-Attention:对于每个词而言都是位置关系,把每个词的顺序打乱,得到的注意力值依然不变
优点:
- 解决了长序列依赖问题
- 可以并行
缺点:
- 开销变大(需要算力增加)
- 既然可以并行,则词与词之间不存在顺序关系(打乱一句话,这句话里的每个词的词向量依然不会改变),既无位置关系(既然没有,就加一个,通过位置编码的形式加)
位置编码怎么做
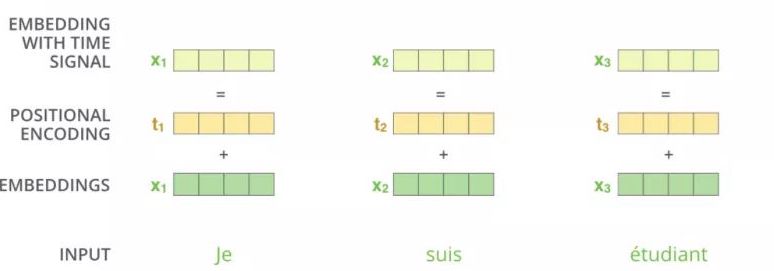
通过$t_1$告诉你,$x_1$是在前面,$x_2$在$x_1$的后面
为了解决 Attention 丢失的序列顺序信息,Transformer 的提出者提出了 Position Embedding,也就是对于输入 X进行 Attention 计算之前,在 X的词向量中加上位置信息,也就是说 X的词向量为
$X_{final\quad embedding}=Embedding+Positional\quad Embedding$
其中位置编码公式如下图所示:
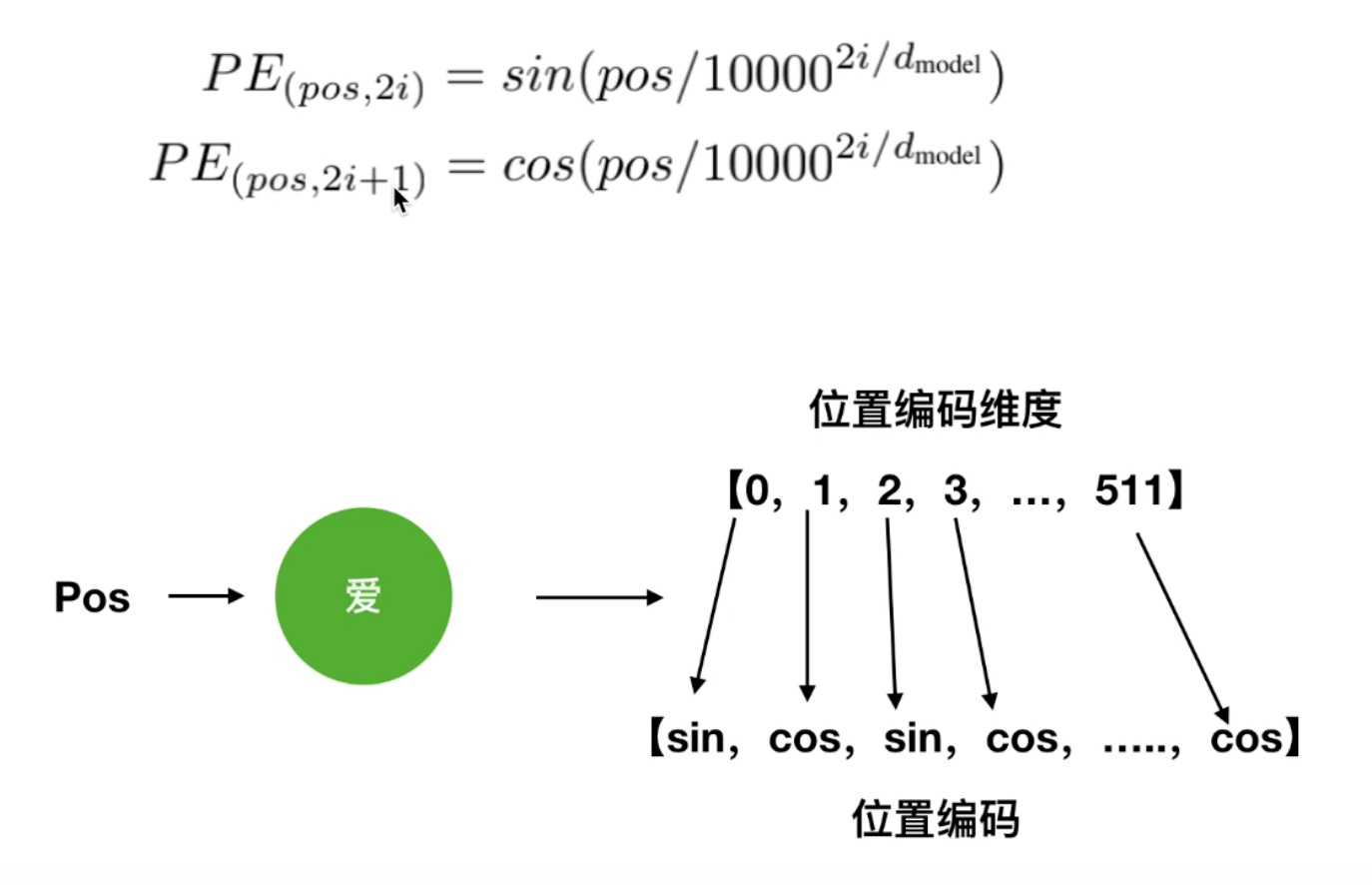
其中 pos 表示位置、i 表示维度、$d_{model}$表示位置向量的向量维度 、2i、2i+1表示的是奇偶数(奇偶维度),上图所示就是偶数位置使用 sin函数,奇数位置使用 cos 函数。
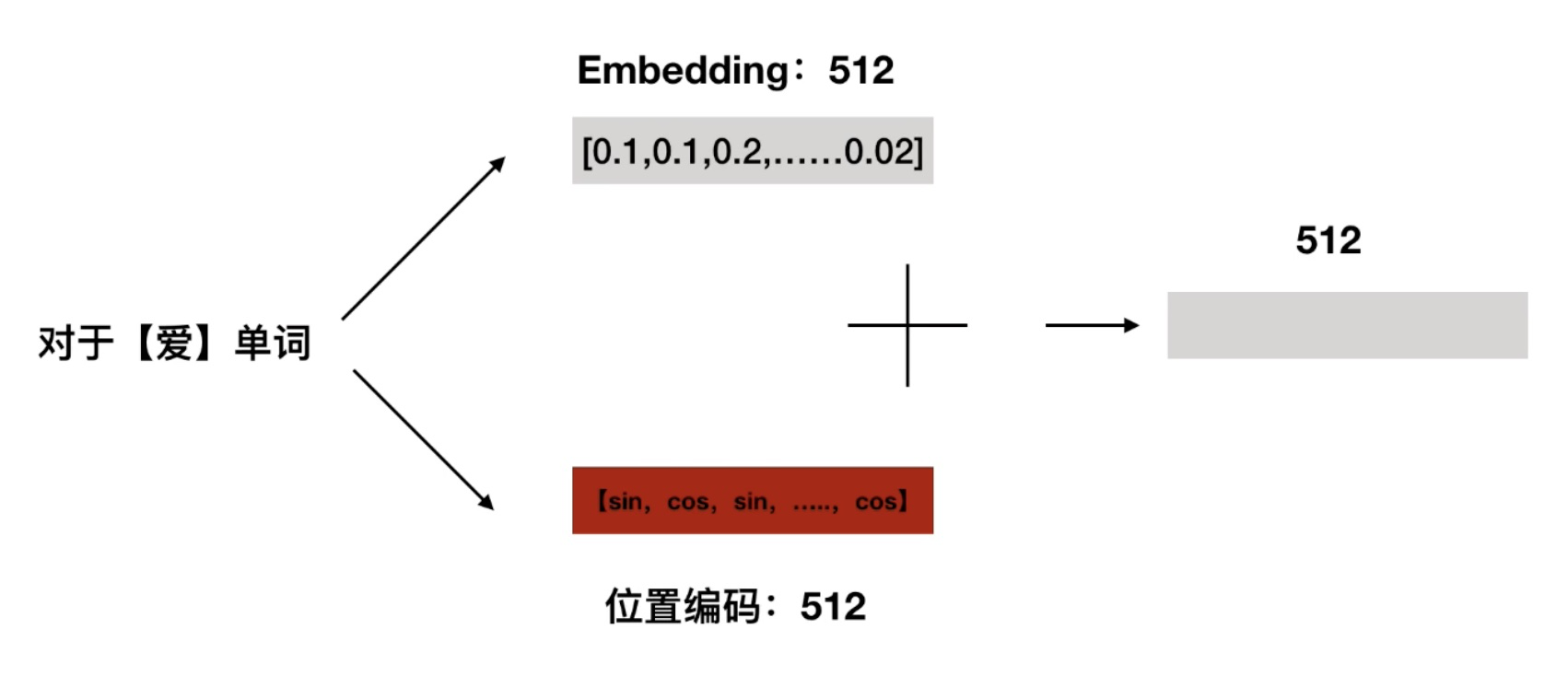
过把单词的词向量和位置向量进行叠加,这种方式就称作位置嵌入,如下图所示:
z

$PE(pos+k,2i)=sin(pos+k) \quad $$PE(pos+k,2i+1)=cos(pos+k)$
$sin$ ---->2$i$,$cos$ ------>2$i+1$
公式里面蕴含相对位置信息
pos+k是pos和k的线性组合
pos+k=5,我在计算第五个单词的位置编码的时候
pos=1,k=4
pos=2,k=3
标签:编码,Encoding,Poitional,位置,pos,2i,向量 From: https://www.cnblogs.com/adam-yyds/p/18071589