2024.3.12 自-注意力机制(向量)

首先可以看到 Self Attention 有三个输入 Q、K、V:对于 Self Attention,Q、K、V 来自句子 X 的 词向量 x 的线性转化,即对于词向量 x,给定三个可学习的矩阵参数$W_Q$ ,$W_K$,$W_V$,x 分别右乘上述矩阵得到 Q、K、V。
Self-Attention的关键点在于,不仅仅是k$\approx$V$\approx$Q来源同一个X,这三者是同源的
可以通过X找到X里面的关键点
并不是K=V=Q=K=X,而是通过三个参数$W_Q$ ,$W_K$,$W_V$
$z_1$表示的就是thinking 的新的向量表示
对于thinking,初始词向量$x_1$
现在通过thinking machines这句话去查询这句话里的每个单词和thinking之间的相似度
新的$z_1$依然是thinking的词向量表示,只不过这个词向量的表示蕴含了thinking machines这句话对于thinking而言哪个信息为更重要的信息
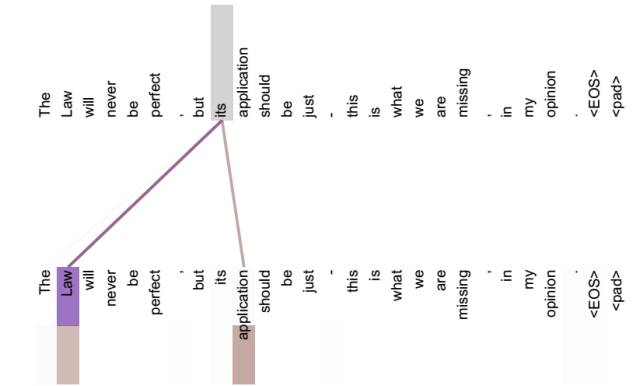
不做注意力,its的词向量就只有本身,没有任何附加消息
但是做了之后,也就是说its有law这层意思,而通过自注意力机制得到新的its的词向量,则会包含一定的laws和application的信息
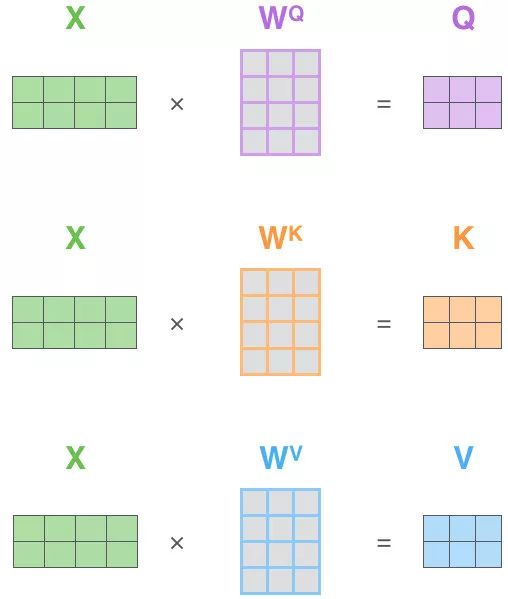
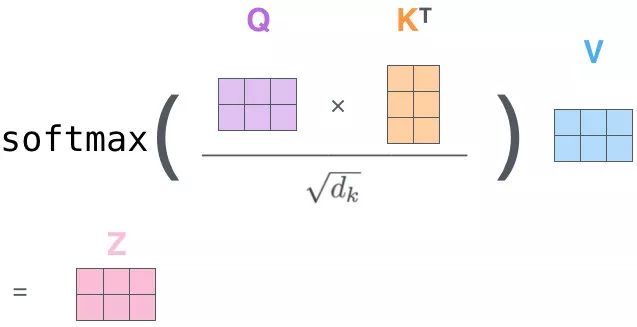

每一个单词对应每一个单词都会有一个权重,这也是 Self Attention 名字的来源,即 Attention 的计算来源于 Source(源句) 和 Source 本身,通俗点讲就是 Q、K、V 都来源于输入 X(句子) 本身
标签:thinking,Self,Attention,its,机制,注意力,向量 From: https://www.cnblogs.com/adam-yyds/p/18068744