tensor.gather()的作用就是按照索引取对应的数据出来。之前看图解PyTorch中的torch.gather函数,那个图示看得我有点懵逼,所以自己画了两张图总结了一下规律来理解一下。
首先新建一个3*3的二维矩阵。
import torch
t1 = torch.tensor([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])tensor.gather()主要有两个参数,第一个是dim,用来判断是对行还是列进行索引;第二个是索引的矩阵(这个必须是tensor,不能是list类型),这个索引是令人不太好理解的地方,下面我用两三个例子帮助理解一下。
按列取 -> "上下结构"
按列取,那么dim = 0。
t1.gather(dim = 0, index = torch.tensor([[1, 2, 0]]))
# tensor([[4, 8, 3]])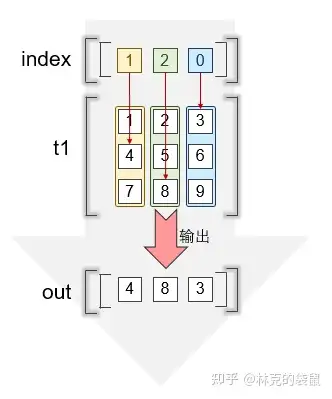 ▲这是一个常规的例子,分别对每一列拿一个值出来组成新的矩阵,注意图中标示的颜色对应
▲这是一个常规的例子,分别对每一列拿一个值出来组成新的矩阵,注意图中标示的颜色对应
t1.gather(dim = 0, index = torch.tensor([[1],
[2],
[0]]))
# tensor([[4],
# [7],
# [1]])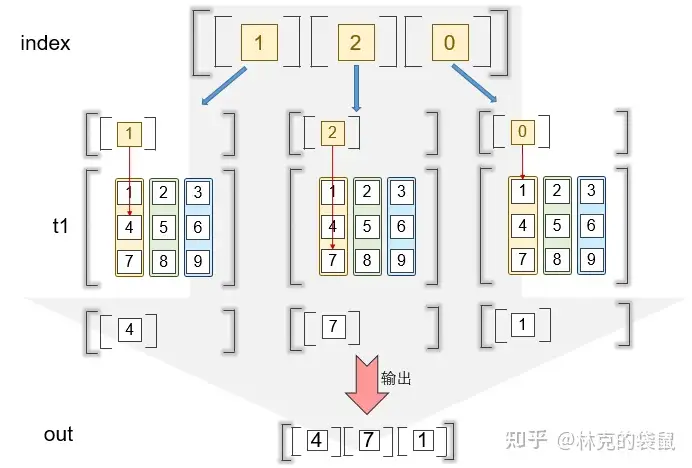 ▲这个实际上是一个奇怪的例子,只取第一列的值,注意结合上图进行理解
▲这个实际上是一个奇怪的例子,只取第一列的值,注意结合上图进行理解
按照上面的逻辑,你就可以尝试各种奇怪的索引:
t1.gather(dim = 0, index = torch.tensor([[1, 0],
[2, 1],
[0, 0]]))
# tensor([[4, 2],
# [7, 5],
# [1, 2]])按行取 -> "左右结构"
这里需要将dim=1。
t1.gather(dim = 1, index = torch.tensor([[1, 2, 0]]))
# tensor([[2, 3, 1]])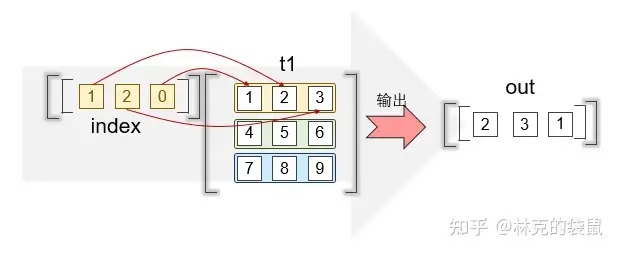 ▲因为设置的是按行索引,自然我们的矩阵要放到左边来成为“左右结构”
▲因为设置的是按行索引,自然我们的矩阵要放到左边来成为“左右结构”
t1.gather(dim = 1, index = torch.tensor([[1], [2], [0]]))
# tensor([[2],
# [6],
# [7]])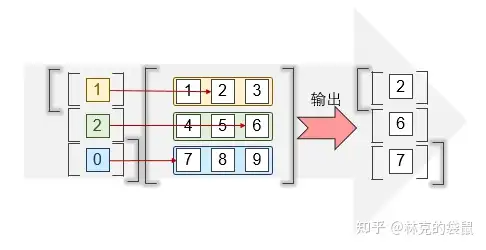 ▲对每一行取一个数值
▲对每一行取一个数值
不过我感觉按行还是按列是异曲同工,按照你自己的习惯来吧。
除此之外也可以类似于numpy的直接用索引值去抓:
t1[[0, 2], [2, 1]]
# tensor([3, 8])