1、强化学习介绍
强化学习是指智能体通过与环境进行交互,不断的通过试错,以获得更大的累计奖励为目的,得到更好的策略。强化学习的学习路线比较陡峭,因为涉及到的数学知识更多一些,需要概率论、随机过程的知识。这里通过我自己的一些学习经验以及看过的一些资料,整理了一条逐渐深入的学习路线,可以大幅度提高学习效率。
2、基础知识
基础知识是最重要也首先需要掌握的部分,涉及到强化学习中的具体定义以及数学模型等。这里推荐阅读Sutton的《强化学习导论》【1】的第三章内容。了解强化学习中最基本的马尔科夫过程,状态、动作、转移概率、奖励等基本概念。
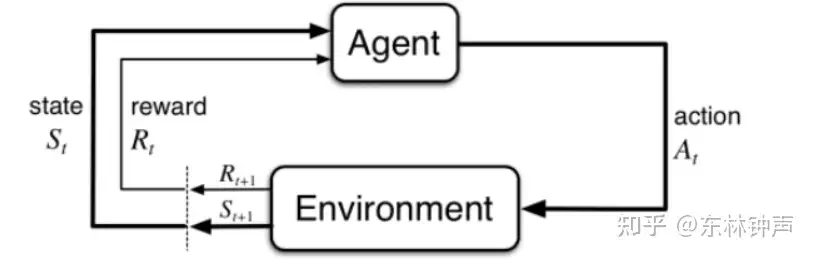
3、核心知识
在了解了强化学习的基础知识之后,需要掌握其核心要点,也是后续相关算法的支撑基石。
- 值函数 state value function、action value function
- Bellman最优方程
- 策略评估、提升、迭代
推荐阅读《强化学习导论》的第四章内容。
4、Q-Learning
在掌握了基础知识和核心要点之后,需要开始深入核心算法,其中Q-Learning是影响力较为广泛的算法之一。这里推荐《强化学习导论》中Q-Learning的详细描述以及莫烦的Q-Learning视频【2】。
5、时间差分(TD)
时间差分,Temporal Difference(TD)是强化学习中最为核心的方法,一定要充分理解,Q-Learning也是TD学习中的一种形式。推荐《强化学习导论》的第六章内容。
6、DQN
DQN是真正在深度学习时代,让强化学习迸发出了全新的活力的算法,也是必须掌握的基本算法。这里推荐莫烦的DQN视频【3】先做一个基本的了解。然后阅读论文掌握DQN的核心改进:
- 经验回放 Experience Replay
- 目标网络 Target Network
- 如何构建值损失函数,通过梯度下降更新值网络
7、策略梯度(Policy Gradient)
策略梯度是强化学习中也必须掌握的算法,他是解决后来强化学习中连续动作问题的关键,也是后续很多先进算法的构建损失函数的基础。策略梯度的数学推导相对来说要复杂一些,这里推荐李宏毅老师的深度强化学习课程系列【4】,其详细的讲解了策略梯度的数学推导与后续发展。
8、Actor Critic
Actor-Critic也是非常经典的强化学习方法,他构建了一种后来广为应用的学习范式,通过策略评估和策略提升交替的方式更新值网络与策略网络。这里推荐阅读【5】。了解不同方法是如何构建策略损失函数。

9、全局学习
在对核心知识有了全盘的了解之后,需要对强化学习进行一个全局的学习与了解,这里推荐周博磊的IntroRL教程【6】。
10、具体算法
强化学习的算法学习,最好的方式是通过论文配合代码的方式进行学习,推荐必须掌握的算法:
离散动作:DQN、Double DQN、Dueling DQN、Rainbow
连续动作:DDPG、TD3、PPO、SAC、A3C
这里推荐OpenAI的Spinning Up系列【7】,里面有详细的算法详解与实现。
资源:
【1】https://rl.qiwihui.com/zh_CN/latest/index.html
【2】https://www.bilibili.com/video/BV1kx411E7Yq
【3】https://www.bilibili.com/video/BV1kx411E72M
【4】https://www.bilibili.com/video/BV124411S7au/?spm_id_from=333.788.videocard.0
【5】https://towardsdatascience.com/understanding-actor-critic-methods-931b97b6df3f
【6】https://github.com/zhoubolei/introRL
【7】https://spinningup.openai.com/e
标签:路线,学习,算法,https,强化,com,DQN From: https://www.cnblogs.com/zhangxianrong/p/18052069