思路
《AWS上的生成式人工智能》书中对于训练模型所需的内存有一个很好的经验法则。正如他们解释的那样,对于模型的每10亿个参数,我们需要6GB的内存(使用16位半精度)来加载和训练模型。请记住,内存大小只是训练故事的一部分。完成预训练所需的时间也是另一个重要部分。举个例子,最小的 Llama2 模型(Llama2 7B)具有70亿个参数,它花费了184320 GPU 小时才完成训练。
- 首先要弄清楚的是,消耗显存的都有哪些?
- 模型的参数 $P_p$。
- 前向过程中,一些中间计算结果以及激活值(即激活函数的执行结果)。
- 后向过程中,每个参数的梯度值 $P_g$。
- 优化器的状态$P_{os}$(Optimizer state)。比如 adam 算法,需要为每个参数再保存一个一阶动量和二阶动量。
- 接下来,思考如何解决内存不足的问题。核心思路其实很简单,主要有两个方向:
- 先不把全部数据加载到 GPU 显存,暂时存放在别的地方,需要的时候再同步到 GPU 显存中,用完就扔掉。把参数放到 CPU 内存中或者高速SSD中(支持NVMe的ssd,走的PCI-E总线),这就是 deepspeed 中的 offload 技术;多张GPU卡,每张卡保存一部分,需要的时候再从其他卡同步过来,这就是参数分割。
- 降低内存的需求。原来每个参数都是 float32 类型,占用4个字节。改成半精度,用2个字节的 float16 替代4个字节 float32,显存需求一下就降低一半。用量化技术,用2个字节的 int16 或者1个字节的 int8 代替4字节的 float32 。
显然,每种方法都不是完美的,都有一定的局限性并且会引入新的问题,比如:
- 参数进行多卡分割或者 offload,比如会增加大量数据同步通信时间,不要小看这部分时间消耗,相对于 GPU 的显存访问速度而言, 多机器之间的网络通信、单机多卡之间通信、cpu内存到GPU内存的通信,这些都是巨大的延迟。
- 模型运行中,大量的浮点数乘法,产生很多很小的浮点数,降低参数精度,会造成数据溢出,导致出问题,即使不溢出,也损失了数据准确性。 模型训练时,梯度误差大,导致损失不收敛。模型推理时,误差变大,推理效果变差。
参数分割策略:说到分割参数,无论是多GPU之间分割参数(比如ZeRO),还是 offload 到CPU内存(比如ZeRO-Offload),都需要对参数进行分割分组。 这就涉及到多种划分策略。
- 按照模型的层(Layer)进行分割,保留每一层(Layer)为整体,不同层存储在不同的 GPU 中, 多个层(GPU)串行在一起,需要串行执行,这就是所谓的 流水线并行(Pipeline Parallel,PP)。时间效率很差, 并且如果某一层的参数量就很大并超过了单卡的显存就尴尬。当然可以通过异步执行一定程度解决时间效率差的问题,有兴趣的读者可以研读相关资料。
- 把参数张量切开,切开张量分开存储很容易,但切开之后,张量计算的时候怎么办?这里可以分两种策略。
- 张量的计算过程也是可以切割,这样把一个大的张量,切分成多个小张量,每张 GPU 卡只保存一个小片段,每个小张量片段(GPU卡)独立进行相关计算,最后在需要的时候合并结果就行了。这种思路就称为 张量并行(Tensor Parallel,TP) , Megatron 就是走的这个路线。
- 同样是把参数张量分割,每张卡只保存一个片段。但是需要计算的时候,每张卡都从其他卡同步其它片段过来,恢复完整的参数张量,再继续数据计算。Deepspeed 选取的这个策略,这个策略实现起来更简单一些。 PS:ZeRO是一种显存优化的数据并行(data parallelism, DP)方案,它可以显著降低模型训练所需的内存。ZeRO通过在多个GPU之间分散模型参数、优化器状态和梯度,从而降低了单个GPU上的内存需求。此外,ZeRO还通过高效的通信算法最小化了跨GPU的数据传输。
降低精度:降低参数精度也有讲究,有些地方可以降低,有些地方就不能降低,所以一般是混合精度。 半精度还有另一个好处,就是 计算效率更高,两个字节的计算速度自然是高于4个字节的。 在模型训练过程中,参数的梯度是非常重要的,参数更新累积梯度变化时,如果精度损失太多会导致模型不收敛。 所以优化器的状态一般需要保留 float32 类型。实际上,GPU 显存不足的问题更多的是靠上面的参数分割来解决,半精度的应用更多的是为了提高计算速度。
流水线并行、张量并行,把模型一次完整的计算过程(前后向)分拆到多个 GPU 上进行, 所以这两者都被称为模型并行(Model Parallel,MP)。 而如果每张卡都能进行模型一次完整前后向计算,只是每张卡处理不同的训练数据批次(batch), 就称为数据并行(Data Parallel,DP)。 deepspeed 对参数进行了分割,每张卡存储一个片段,但在进行运算时, 每张卡都会恢复完整的参数张量,每张卡处理不同的数据批次, 因此 deepspeed 属于数据并行。
最后总结一下, 针对大模型的训练有三种并行策略,理解起来并不复杂:
- 数据并行:模型的计算过程没有分割,训练数据是分割并行处理的。
- 模型并行:模型的计算过程被分割。
- 流水线并行:模型按照层(Layer)切分。
- 张量并行:把参数张量切分,并且将矩阵乘法分解后多 GPU 并行计算。
训练框架
虽然支持大模型训练的分布式框架仍有不少,但是社区主流的方案主要还是
- DeepSpeed,这是一个用于加速深度学习模型训练的开源库,由微软开发。它提供了一种高效的训练框架,支持分布式训练、模型并行和数据并行。DeepSpeed 还包括内存优化技术,如梯度累积和激活检查点,以降低内存需求。DeepSpeed 可以与流行的深度学习框架(如 PyTorch)无缝集成
- Megatron,Megatron 是 NVIDIA 开发的一个用于训练大规模 transformer 模型的项目。它基于 PyTorch 框架,实现了高效的并行策略,包括模型并行、数据并行和管道并行。Megatron 还采用了混合精度训练,以减少内存消耗并提高计算性能。
- Megatron-LM:Megatron-LM 是在 Megatron 的基础上,结合了 DeepSpeed 技术的NVIDIA做的项目。它旨在进一步提高训练大规模 transformer 模型的性能。Megatron-LM 项目包括对多种 transformer 模型(如 BERT、GPT-2 和 T5)的支持,以及一些预训练模型和脚本, 主导Pytorch。
- Megatron-DeepSpeed : 采用了一种名为 ZeRO (Zero Redundancy Optimizer) 的内存优化技术,以降低内存占用并提高扩展性,提供了一些其他优化功能,如梯度累积、激活检查点等。Megatron-DeepSpeed 支持多个深度学习框架,包括 PyTorch、TensorFlow 和 Horovod。这使得 Megatron-DeepSpeed 对于使用不同框架的用户具有更广泛的适用性。
目前被采纳训练千亿模型最多的还是3和4, Megatron-LM(大语言模型训练过程中对显存的占用,主要来自于 optimizer states, gradients, model parameters, 和 activation 几个部分。DeepSpeed 的 ZeRO 系列主要是对 Optimizer, Gradients 和 Model 的 State 在数据并行维度做切分。优点是对模型改动小,缺点是没有对 Activation 进行切分。Megatron-LM 拥有比较完备的 Tensor 并行和 Pipeline 并行的实现。)。那么为什么大模型训练偏爱 3D 并行呢,比如Megatron-Turing NLG(530B), Bloom(176B)?相信对大模型训练感兴趣的同学,都会熟悉和了解一些使用分布式训练的具体策略和 tricks。我们不如来算一笔账,看看这些 tricks 是为什么。
- ZeRO-Offload 和 ZeRO-3 增加了带宽的压力,变得不可取
- 使用 3D 并行来降低每卡显存占用,避免 recomputation
- GA>1,主要是为了 overlap 和减少 bubble
- Flash Attention2 (显存的节省上面等效于 Selective Activation Recompute)
- ZeRO1 Data Parallel + Tensor Parallel(Sequence Parallel) + Interleave Pipeline Parallel
- 为什么不用 ZeRO2,因为在 GA 的基础上面 Gradient 切分反而多了通信次数
- FP16/BF16/FP8 训练,通信压缩
- Overlapped distributed optimizer
DeepSpeed
DeepSpeed 实现的 ZeRO ,出发点是为了减少显存使用,跨机器跨节点进行更大模型的训练。按层切分模型分别载入参数,看起来好像是模型并行。但是运行时其实质则是数据并行方式,不同的数据会在不同的卡运行,且同一组数据一般会在一块卡上完成全部前向和后向过程。而被切分的参数和梯度等数据会通过互联结构在运行态共享到不同节点,只是复制出的数据用后即焚删除了,不再占用空间。
整体设计
普通数据并行时GPU 内存的占用情况
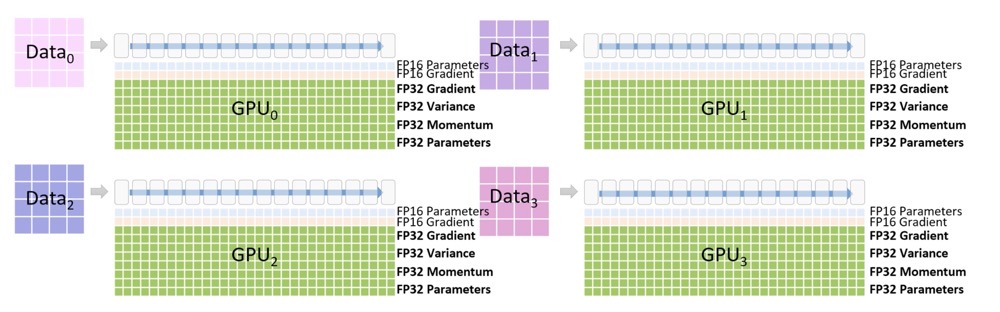
在DeepSpeed下,ZeRO训练支持了完整的ZeRO Stages1, 2和3,以及支持将优化器状态、梯度和模型参数从GPU显存下沉到CPU内存或者硬盘上,实现不同程度的显存节省,以便训练更大的模型。不同Stage对应的做法:
- Stage 1: 把 优化器状态(optimizer states) 分片到每个数据并行的工作进程(每个GPU)下
- Stage 2: 把 优化器状态(optimizer states) + 梯度(gradients) 分片到每个数据并行的工作进程(每个GPU)下
- Stage 3: 把 优化器状态(optimizer states) + 梯度(gradients) + 模型参数(parameters) 分片到每个数据并行的工作进程(每个GPU)下
- Optimizer Offload: 在Stage2的基础上,把梯度和优化器状态下沉到CPU内存或硬盘上
- Param Offload: 在Stage3的基础上,把模型参数下沉到CPU内存或硬盘上
假如GPU卡数为N=64,$\psi$是模型参数,假设$\psi$=7.5B,假设使用Adam优化器,在64个GPU下K=12,则:
- 如果不用ZeRO,需要占用120GB的显存,A100最大才80GB,塞不下
- 如果用ZeRO Stage1,则占用31.4GB,A100 40GB或者80GB卡都能跑,单机多卡或多机多卡训练的通信量不变
- 如果用ZeRO Stage2,则占用16.6GB,大部分卡都能跑了,比如V100 32GB,3090 24GB,通信量同样不变
- 如果用ZeRO Stage3,分片到每个数据并行的工作进程(每个GPU)下),则占用1.9GB,啥卡都能跑了,但是通信量会变为1.5倍
PS:从计算过程的角度讲,先正向后反向,再优化器,正向的时候,反向所需的数据不需要在显存中。从层的角度讲,正向反向的时候,计算前面的层时后面层的参数不需要在显存中,所以就可以用通信换省空间。
DeepSpeed 使用
config = {
"train_batch_size": 8,
"gradient_accumulation_steps": 1,
"optimizer": {
"type": "Adam",
"params": {
"lr": 0.00015
}
},
"fp16": {
"enabled": True,
}
"zero_optimization": {
}
}
model_engine,optimizer, _, _ = deepspeed.initialize(config=config, model=model, model_parameters=model.parameters())
for step,batch in enumerate(data_loader):
loss = model_engine(batch) # 前向传播
model_engine.backward(loss) # 反向传播
model_engine.step() # 参数更新
if step % args.save_interval:
client_sd['step'] = step # 新增当前step信息与模型一并保存
ckpt_id = loss.item() # 使用loss值作为模型标识
model_engine.save_checkpoint(args.save_dir, ckpt_id, client_sd = client_sd) # 保存模型deepspeed.initialize 会选择不同的engine(对应不同的模式),DeepSpeedEngine分布式训练引擎 是最基本的模式, 它本身是 torch.nn.Module 的子类,也就是说它是对输入模型的一个封装。 DeepSpeedEngine 的 __init__ 方法中进行了大量的初始化操作, 其中最重要的就是对优化器(Optimizer)的初始化, ZeRO 的核心特性的实现都在优化器(Optimizer)中。
class DeepSpeedEngine(Module):
def __init__(self,args,model,optimizer=None,model_parameters=None,training_data=None,config=None,...):
...
# 优化器的初始化
if has_optimizer: # 入参传入了 optimizer 或者配置文件中指定了 optimizer
self._configure_optimizer(optimizer, model_parameters)
self._configure_lr_scheduler(lr_scheduler)
self._report_progress(0)
elif self.zero_optimization(): # 启用 zero 优化,即 zero_optimization_stage > 0
# 创建 ZeRO 优化器
self.optimizer = self._configure_zero_optimizer(optimizer=None)
elif self.bfloat16_enabled(): # bf16 模式
self.optimizer = self._configure_bf16_optimizer(optimizer=None)
...
参数分割之后,在执行前向、后向之前,需要先把参数再还原回来。 同理,在执行前向后向之后,还要释放掉各自不需要的参数。 这里利用 pytorch 的 hook 功能在上述四个关键节点插入相关的动作。 pytorch 的 Module 类型提供了一系列 register_xxx_hook 方法来实现 hook 功能。PS:deepspeed 的优化主要是参数的存取,不用动模型结构本身。
Megatron-LM
Megatron-LM是一种优雅的高性能训练解决方案。Megatron-LM中提供了张量并行(Tensor Parallel,TP,把大乘法分配到多张卡并行计算)、流水线并行(Pipeline Parallel,PP,把模型不同层分配到不同卡处理)、序列并行(Sequence Parallel, SP,序列的不同部分由不同卡处理,节约显存)、DistributedOptimizer优化(类似DeepSpeed Zero Stage-2,切分梯度和优化器参数至所有计算节点)等技术,能够显著减少显存占用并提升GPU利用率。Megatron-LM运营着一个活跃的开源社区,持续有新的优化技术、功能设计合并进框架中。
资源调度
OpenAI 在 1024 个 NVIDIA A100 GPU 上训练 GPT-3 大约需要 34 天。训练节点越多,耗时越长,训练期间节点故障概率就越大。据我们在蚂蚁 GPU 训练集群上观察,一个月内,单卡的故障率约 8%,那么一天单卡的故障率约为 0.27%。常见的故障原因有 Xid、ECC、NVLINK error 和 NCCL error 故障等。对于一个千卡训练作业来说,卡故障导致一天内训练失败的概率高达到 93%。所以训练作业几乎每天都会失败。作业失败后,用户需要手动重启作业,运维成本很高。如果用户重启不及时,中间间隔的时间就会导致 GPU 卡空闲,浪费昂贵的算力资源。
弹性训练是指在训练过程中可以伸缩节点数量。当前支持 PyTroch 弹性训练的框架有 Torch Elastic 和 Elastic Horovod。二者显著的区别在于节点数量变化后是否需要重启训练子进程来恢复训练。Torch Elastic 感知到新节点加入后会立刻重启所有节点的子进程,集合通信组网,然后从 checkpoint 文件里恢复训练状态来继续训练。而 Elastic Horovod 则是每个训练子进程在每个 step 后检查新节点加入,子进程不退出的情况下重新集合通信组网,然后有 rank-0 将模型广播给所有 rank。
- 集合通信动态组网。动态组网是指训练进程可以自动根据动态变化的节点数量来组网集合通信,无需固定给各个节点指定集合通信的 rank 和 world size。动态组网是弹性容错训练必须的,因为弹性容错作业中,节点的失败、扩容或者缩容都会导致节点的 rank 和 world size 变化。所以我们无法在作业启动前给节点指定 rank 和 world size。PS: Rendezvous 机制:Rendezvous Manager/Rendezvous Agent/共享存储。 DLRover ( ElasticJob )会启动一个Master 存CPU pod,负责运行Rendezvous Manager,且会踢掉用不到的pod(让worker pod 进程退出?)。
- 分布式训练容错,训练容错是指训练出现故障后能在无人工介入的情况下快速恢复训练。训练恢复需要如下步骤:定位错误原因,判断错误是否可以恢复;启动训练进程加载训练代码,训练进程能重新集合通信组网;训练进程能加载模型导出的 checkpoint 来恢复训练状态;如果存在故障机,要及时将故障机排除,以便新节点继续调度在故障机。
- 对于无故障机的错误,DLRover 重启进程来恢复训练。
- 对于故障机的错误,DLRover 会通知 SRE 隔离故障机并重新拉起 Pod 来替换出错的 Pod
- 对于正常运行的 Pod 重启其训练进程,减少 Pod 调度时间开销。
- 在训练进程恢复后,DLRover 为了方便用户恢复训练dataset 的消费位点,提供了ElasticDistributedSampler方便用户在对模型做checkpoint时也对 Dataloader做checkpoint。从而实现模型和训练样本数据的一致性。
- 故障机检测
- 错误日志收集,在 PyTorch 分布式训练中,一个节点的进程出错后,Torch Elastic 会停止所有节点的进程。各个进程的日志都是单独存在各自日志文件中。为了找到训练失败是哪个进程出错导致的,我们需要搜索所有进程的日志。这个工作对于千卡作业是十分耗时且繁琐的。为此,我们在 ElasticAgent 中开发了错误日志收集供功能。当 ElasticAgent 发现子进程失败后,后将其错误日志的 message 发送给 Job Master。Job Master 会在其日志中展示具体哪个节点的那个进程失败了,以及错误日志。这样用户只需看下 Job Master 的节点日志就可以定位训练失败原因了。 PS:
- 故障检测,踢掉故障worker,踢掉多余worker(有时用户要求worker数必须是N的整数倍),worker 被踢掉之后,由controller来创建新的pod? 若worker 被踢掉之后,新的pod 因为资源不够一直pending,当前集群不满足客户要求的最小worker数,如何处理呢?
- 除了controller、crd等,代码上,DLRover 提供了 ElasticTrainer 来封装训练过程,dlrover-run 来启动训练代码(只要是能用 torchrun 启动的任务,都是支持用 dlrover-run 来跑的。dlrover-run 是扩展了torchrun,所以原生的torchrun的配置都支持。)。
训练程序一般采用周期 checkpoint 方案来将训练状态持久化到存储。为了保证训练状态的一致性,checkpoint 的时候训练需要暂停。常规的 checkpoint 当前面临以下问题:
- 耗时与模型大小和存储的 IO 性能密切相关,需要几分钟到几十分钟。
- 太频繁的 checkpoint 会大幅降低训练可用时间。
- 低频的 checkpoint 的间隔太长,会导致故障后浪费的迭代步数太多。
DLRover 推出了 Flash Checkpoint (FCP) 方案,同步将训练状态写到共享内存(比如每 10 步一次),然后异步从共享内存写到存储系统(每隔 250 步持久化到 CPFS),将 checkpoint 时间开销降低到秒级。如果非机器宕机故障,DLRover 可以直接重启训练进程,这时可以直接从主机内存中加载 Checkpoint,省去读存储文件的 IO 开销。
其它
大模型训练需要多少算力?训练总算力(Flops)= 6 * 模型的参数量 * 训练数据的 token 数。
- 6 * 模型的参数量 * 训练数据的 token 数就是所有训练数据过一遍所需的算力。这里的 6 就是每个 token 在模型正向传播和反向传播的时候所需的乘法、加法计算次数。
- 正向传播的时候: l 把它的输出乘上 l 和 r 之间的权重 w,发给 r;r 不可能只连一个神经元吧,总要把多个 l 的加到一起,这就是 reduce,需要一次加法。
- r 把它收到的梯度乘上 l 和 r 之间的权重 w,发给 l;l 也不可能只连一个 r,需要把梯度 reduce 一下,做个加法;别忘了权重 w 需要更新,那就要计算 w 的梯度,把 r 收到的梯度乘上 l 正向传播的输出(activation);一个 batch 一般有多个 sample,权重 w 的更新需要把这些 sample 的梯度加到一起。
- 一共 3 次乘法,3 次加法,不管 Transformer 多复杂,矩阵计算就是这么简单,其他的向量计算、softmax 之类的都不是占算力的主要因素,估算的时候可以忽略。
- 有了模型训练所需的总算力,除以每个 GPU 的理论算力,再除以 GPU 的有效算力利用比例,就得到了所需的 GPU-hours,这块已经有很多开源数据。
- 训练需要的内存包括模型参数、反向传播的梯度、优化器所用的内存、正向传播的中间状态(activation)。
- 优化器所用的内存其实也很简单,如果用最经典的 Adam 优化器,它需要用 32 位浮点来计算,否则单纯使用 16 位浮点来计算的误差太大,模型容易不收敛。因此,每个参数需要存 4 字节的 32 位版本(正向传播时用 16 位版本,优化时用 32 位版本,这叫做 mixed-precision),还需要存 4 字节的 momentum 和 4 字节的 variance,一共 12 字节。如果是用类似 SGD 的优化器,可以不存 variance,只需要 8 字节。
- 正向传播的中间状态(activation)是反向传播时计算梯度必需的,而且跟 batch size 成正比。Batch size 越大,每次读取模型参数内存能做的计算就越多,这样对 GPU 内存带宽的压力就越小。划重点:正向传播的中间状态数量是跟 batch size 成正比的。
- 大家也发现正向传播中间状态占的内存太多了,可以玩一个用算力换内存的把戏,就是不要存储那么多梯度和每一层的正向传播的中间状态,而是在计算到某一层的时候再临时从头开始重算正向传播的中间状态,这样这层的正向传播中间状态就不用保存了。如果每一层都这么干,那么就只要 2 个字节来存这一层的梯度。但是计算中间状态的算力开销会很大。因此实际中一般是把整个 Transformer 分成若干组,一组有若干层,只保存每组第一层的中间状态,后面的层就从该组第一层开始重新计算,这样就平衡了算力和内存的开销。
- 当然有人说,GPU 内存放不下可以换出到 CPU 内存,但是就目前的 PCIe 速度,换出到 CPU 内存的代价有时候还不如在 GPU 内存里重算。
- 对于 LLaMA-2 70B 模型,模型参数需要 140 GB,反向传播的梯度需要 140 GB,优化器的状态(如果用 Adam)需要 840 GB。
- Tensor、Pipeline、Data Parallelism 就像是这样的不可能三角,相互牵制,只要集群规模够大,模型结构仍然是 Transformer,就很难逃出内存容量和网络带宽的魔爪。
- 推理所需的计算量大概就是 2 * 输出 token 数量 * 参数数量 flops。
- 70B 推理的时候最主要占内存的就是参数、KV Cache 和当前层的中间结果。当 batch size = 8 时,中间结果所需的大小是 batch size * token length * embedding size = 8 * 4096 * 8192 * 2B = 0.5 GB,相对来说是很小的。70B 模型的参数是 140 GB,140 GB 参数 + 40 GB KV Cache = 180 GB
- 算子拆分 单个矩阵乘法可以分到两个device上计算
Y = WX = [W1,W2]X = [W1X,W2X]。我们在工程上要做的就是:将切分到两个device上,将复制到两个device上,然后两个device分别做矩阵乘法即可。有的时候,切分会带来额外的通信,比如矩阵乘法切到了reduction维度上,为了保持语义正确,就必须再紧跟一个AllReduce通信。 这里复杂之处在于,你不能无脑地将所有算子全部做拆分,因为拆分可能会引入一些额外通信,降低总体吞吐。所以你得做些分析,决定哪些算子被拆分,现在大部分框架都不支持这种全自动化策略,要么是半自动或纯手工,要么是针对某种模型把它的拆分方案写死。所以只能造轮子解决这个事 - 流水并行 不切算子,而是将不同的Layer切分到不同的Device上,就可以形成Pipeline方案,GPipe就是这样一种方案,提出了将一个batch拆分成若干个micro-batch,依次推入到Pipeline系统中,即可消除Bubble time。和算子拆分类似,全自动化方案工作量不小,比如Pipeline怎么切,才能让通信量小,计算还能均匀,这需要一定的算法和工程量
我们的模型可能会很大,或者数据量会很大。仅仅用一块GPU卡可能连模型都放不下,或者batch size只能设置的很小,但是我们知道有些情况下大的batch size往往会提供更好的效果。
- 假设我们只有一个GPU,我们的模型一次只能输入batch size为8的数据,那么我们怎么样实现batch size为32的更新呢?那就需要时间换空间了,即我们训练32/8=4步才去更新模型,也就是所谓的梯度累积。
- Gradient-Checkpointing, 那么如果你的GPU连batch size为1都跑不了怎么办?我们在训练深度学习模型的时候,需要先做前向传播,然后将中间得到的激活值存储在内存中,然后反向传播的时候再根据loss和激活值计算梯度。也就是说内存消耗其实跟模型的层数线性相关。那么怎么减少这个内存消耗呢?最简单的想法就是我不存这些中间信息,计算梯度的时候,到了某一层我重新计算它的激活值,这个方法虽然可以让内存消耗是个常量,但是运行时间会是
O(n^2),这是没法接受的。那么就有一个折中的办法,我不存全部的中间数据,只存部分,那么我们在计算梯度的时候不需要从头计算了,只需要从最近的checkpoint点计算就好。 - 我们训练模型一般都是用单精度(FP32)的参数,但是其实我们还使用半精度(FP16)。半精度可以降低内存消耗,从而训练更大的模型或者使用更大的batch size;同时运算时间受内存和算术带宽的限制,在有些gpu(Tensor cores)上可以为半精度提供更大的算术带宽,从而提高训练效率,减少inference用时。