在OpenAI的GPT,Meta的Llama和Google的BERT等大型语言模型(LLM)发布之后,它们可以生成类似人类的文本,理解上下文并执行广泛的自然语言处理(NLP)任务。LLM将彻底改变我们构建和维护人工智能系统和产品的方式。因此,一种被称为“LLMOps”的新方法已经发展并成为每个AI / ML社区的话题,以简化我们应该如何在生产中开发,部署和维护LLM。
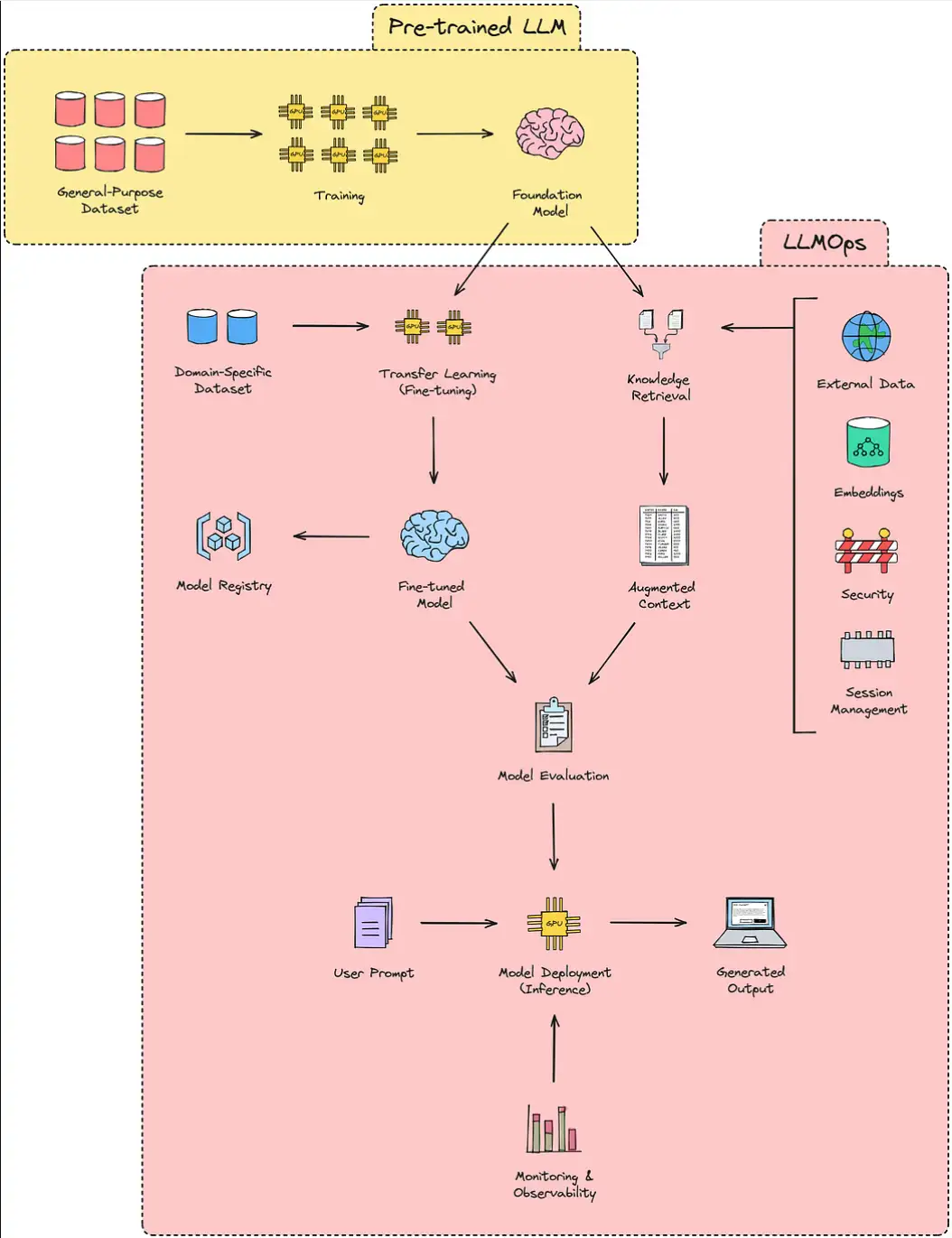
什么是LLMOps?
LLMOps 代表大型语言模型操作,字面意思是“LLM 的 MLOps”,这意味着它是 MLOps 的一个子类别,专注于新的工具集、架构原则和最佳实践,以操作基于 LLM 的应用程序的生命周期。
以下是LLMOps的关键方面,证明了它们在成功实施基于LLM的应用程序中的重要性。
- 数据管理:摄取、清洁、贴标签、储存。
- 模型开发:选择基础模型,微调,评估。
- 模型部署:监控、维护、优化。
- 安全和隐私:护栏、访问控制、加密、合规性、机密性。
- 道德和公平:解决偏见,负责任,透明。
MLOps vs LLMOps
MLOps 和 LLMOps 有许多相似之处,但是,它们之间的差异是基于我们使用经典 ML 模型与 LLM 构建 AI 产品的方式。
1) 数据管理
在 MLOps 中,数据预处理是 ML 模型开发过程中最关键的步骤,因为它会影响模型的质量和性能。它通常需要大量的标记数据来从头开始训练神经网络,但是,微调预训练模型所需的数据量相对较少。
在LLMOps中,数据质量和多样性对于有效的大型语言模型非常重要。但是,微调预训练模型与 MLOps 非常相似。此外,快速工程引入了零镜头和少镜头学习等新技术,这些技术涉及使用精心挑选的样本和精确策划的数据,而不是大量潜在的不规则数据,最终提高模型完成特定任务的能力。
2) 模型实验
在 MLOps 中,开发过程涉及运行许多试验并将其结果与其他试验进行比较,并开发性能最佳的配置,其中包括跟踪输入(如代码、训练和验证数据、模型体系结构和超参数)以及输出(如评估指标和模型权重)。
在LLMOps中,由于LLM能够有效地从原始数据中学习,特征工程的重要性变得不那么重要了。微调与 MLOps 中的路径类似,但是,它旨在使用特定于域的数据集提高模型在特定任务上的性能。即时工程在LLM中也越来越受欢迎,其中输入的调整方式是输出以更少的精力和资源符合期望。
3) 模型评估
在 MLOps 中,模型性能是通过评估其对维持验证集执行的能力来评估的,该评估指标包括准确性、精度、召回率、F1 分数或均方误差 (MSE),具体取决于问题类型(分类、回归等)和其他技术,如交叉验证、学习曲线、基线模型比较、交叉验证、超参数优化和混淆矩阵。
在LLMOps中,使用ROUGE,BERT和BLEU分数等内在指标来评估模型性能,这些指标侧重于衡量响应与提供的参考答案的相似性。人工评估涉及专家或众包工作者在特定背景下评估LLM的产出或绩效。特定于任务的基准,如GLUE或SuperGLUE使用一组预定义的任务来评估LLM,每个任务都有完善的指标。
4) 成本
在 MLOps 中,成本因素包括与数据收集和准备、试验计算资源、特征工程和超参数优化相关的费用。
而在LLMOps中,主要的成本因素是生产中的模型推理,这需要昂贵的基于GPU的计算资源,并且使用OpenAI的GPT-3.5和GPT-4模型等闭源专有LLM也会产生许可成本。
5) 延迟
在 MLOps 中,由于计算复杂性、模型大小、硬件限制、数据预处理开销、网络延迟、并发用户需求以及与软件相关的效率低下等因素,可能会出现延迟问题。它可能会阻碍依赖于及时预测的应用程序的实时或近实时性能,从而影响自治系统、实时决策和快速响应至关重要的场景中的用户体验等领域。
在LLMOps中,由于LLM的巨大大小和复杂性,再加上文本理解和生成所需的大量计算,延迟问题更加突出,这可能导致大量的处理时间,影响使用这些模型的应用程序的响应能力。此类延迟问题可能会影响实时交互、聊天机器人、内容生成和其他与语言相关的任务,在这些任务中,快速无缝的语言理解和生成对于令人满意的用户体验至关重要。
简而言之
LLMOps仍然是一个相对较新的领域,预计它将继续发展并与计算机视觉和语音识别等人工智能的其他领域集成,这将允许创建更复杂的AI / ML驱动的系统,能够处理各种任务。
总之,LLMOps 是 MLOps 的一个特殊用例,具有新的维度,正在以惊人的速度增长。在某种程度上,LLMOps 可以被视为 MLOps 关键方面的重大偏差,包括培训、部署和维护,这就是为什么它需要一种独特的方法和理解话语。
标签:记录,模型,学习,任务,LLMOps,LLM,MLOps,评估 From: https://www.cnblogs.com/muzinan110/p/18048347