在《Kubernetes架构及核心部件》一文中,介绍了Kubernetes的核心部件-控制器的作用:当客户端通过API Server 提交请求时,控制器驱动对象的当前状态逼近提交的期望状态。
Kubernetes的资源对象包括Pod、Node、Namespace、Endpoints、Service等,Kubernetes也提供了各种资源对象的控制器,用来驱动对象的当前状态(status)逼近提交的期望状态(spec)。本文从原理、类型、使用这3个方面说说控制器。
1、控制器的原理
1.1、大致原理
在Kubernetes 集群中,Controller通过 API Server提供的(List & Watch)接口实时监控集群中资源对象的状态变化,当发生故障,导致资源对象的状态变化时,Controller会尝试将其状态调整为期望的状态。
比如当某个Pod出现故障时,Deployment Controller会及时发现故障并执行自动化修复流程,确保集群里的Pod始终处于预期的工作状态。
具体流程见下图:
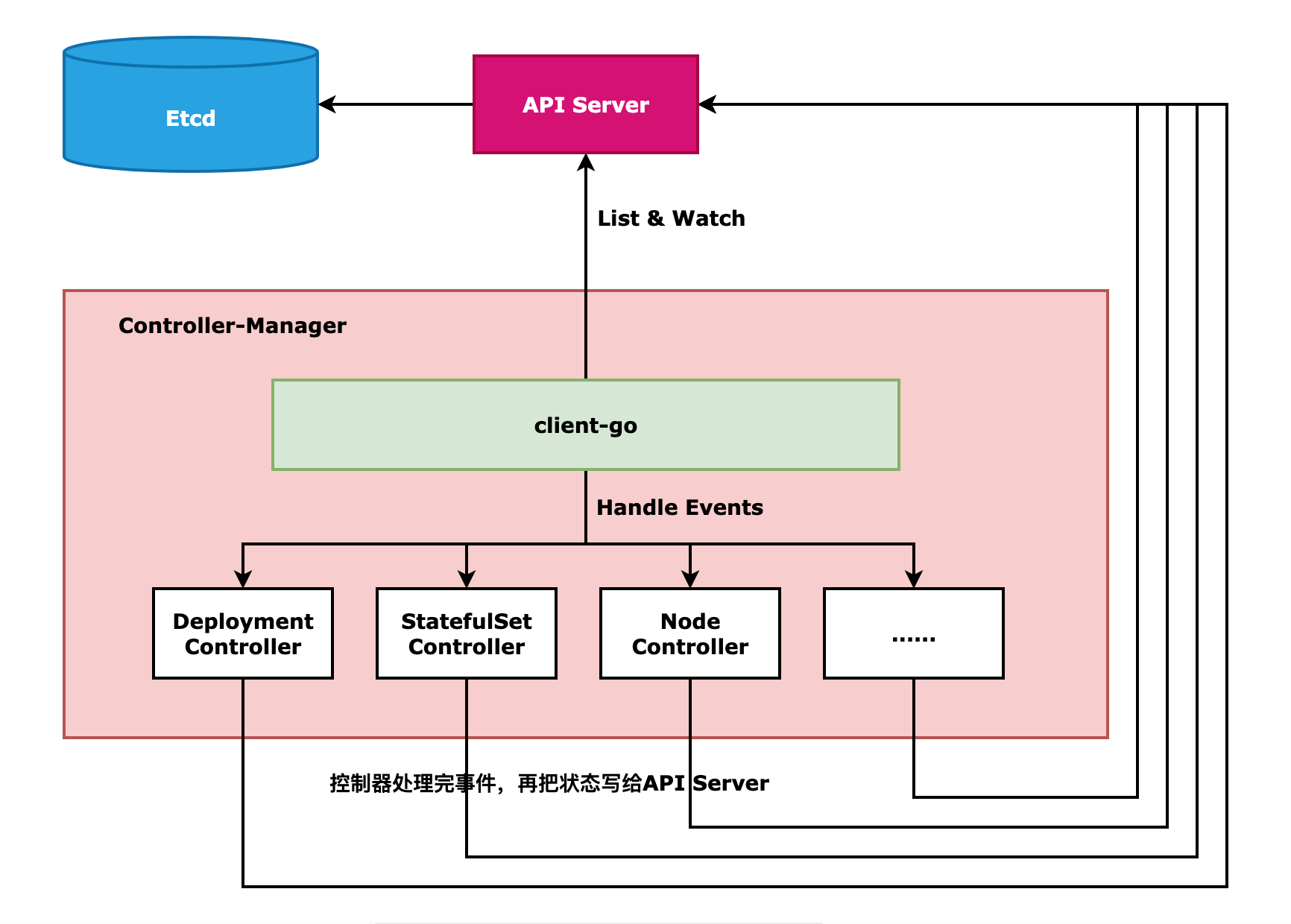
Kubernetes控制器是通过定期重复执行如下 3 个步骤来完成控制任务的:
- 从API Server读取资源对象的期望状态和当前状态。
- 比较两者的差异,然后运行控制器操作现实中的资源对象,将资源对象的真实状态修正为Spec中定义的期望状态。
- 变动执行成功后,将结果状态写回到在API Server上的目标资源对象的status字段中。
1.2、Controller Manager
Kubernetes 提供了名种资源对象的控制器,每种Controller 都负责一种特定资源的控制流程,而Controller Manager是这些控制器的管理者。
Controller Manager 发现资源的实际状态和期望状态有偏差之后,会触发相应Controller注册的Event Handler,让它们去根据资源本身的特点进行调整。之所以叫Controller Manager,是因为Controller Manager 由负责不同资源的多种Controller组成,如 Deployment Controller、Node Controller、Namespace Controller、Service Controller等,这些Controllers各自明确分工,负责集群内各种资源的管理。
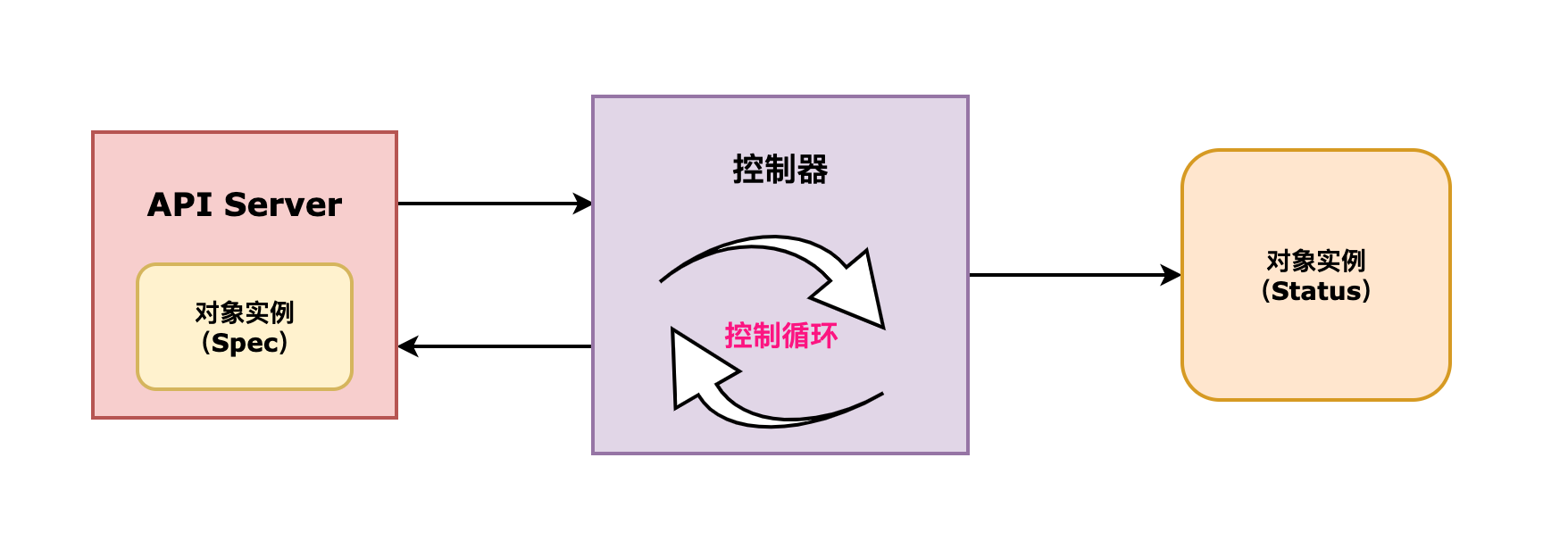
1.3、循环控制和立即控制
Kubernetes集群上运行着大量的控制循环,每个循环都有一组特定的任务要处理,为了避免API Server被大量的请求拖垮,需要设置控制循环以较低的频率运行,默认每5分钟一次。
同时,为了能及时触发由客户端提交的期望状态,控制器向API Server注册监听资源对象事件,这些资源对象的期望状态的任何变动都会由Informer组件通知给控制器立即执行而无须等到下一轮的控制循环。
控制器使用工作队列将需要运行的控制循环进行排队,从而确保在受控资源对象很多时 或 资源对象变动频繁时,不会漏掉控制任务。
这个流程类似于做大数据统计时,一方面利用实时计算及时统计出结果,一方面利用批计算按日统计,重新比对和矫正实时计算的结果。
整体流程如下图:

2、控制器的类型
Kubernetes 提供了Replication Controller、Node Controller、ResourceOuota Controller、Namespace Controller、ServiceAccount Controller、Service Controller、Endpoint Controller、Deploymont Controller等各种资源对象的控制器。常用的控制器有以下几种。
2.1、ReplicaSet Controller
ReplicaSet保证在所有时间内,都有特定数量的Pod副本在运行。如果数量太多,ReplicaSet会删除几个;如果数量太少,ReplicaSet将创建几个。与直接创建的Pod不同的是,ReplicaSet会替换掉那些被删除或者被终止的Pod。
建议通过Deployment管理ReplicaSet,一般无须直接操作ReplicaSet。
ReplicaSet Controller中的 Pod 模板就像一个模具,模具制作出来的东西一旦离开模具,它们之间就再也没关系了。同样,一旦Pod被创建完毕,无论模板如何变化也不会影响到已经创建的 Pod 。
2.2、Deployment Controller
Deployment是管理应用副本的API对象。管理员只需要在Deployment中描述期望的状态,Deployment就能根据一定的策略将ReplicaSet与Pod更新到管理员预期的状态。Deployment提供了运行Pod的能力,并且为Pod提供滚动升级、伸缩、副本等功能,一般用于运行无状态的应用。
需要说明的是,Deployment并不直接控制Pod,而是通过上面介绍的ReplicaSet实现对Pod的管理。
在创建 Deployment 资源对象之后,Deployment Controller 也默默创建了对应的ReplicaSet,Deployment 的滚动升级是Deployment Controller通过自动创建新的ReplicaSet来支持的。
2.3、StatefulSet Controller
StatefulSet用来管理一组Pod集合的部署和扩缩容,并为这些Pod提供持久化存储和持久化标识符。与Deployment不同的是,StatefulSet为每个Pod维护了一个固定的ID。这些Pod是基于相同的模板来创建的,但是不能相互替换,无论怎么调度,每个Pod都有一个固定的ID。
2.4、DaemonSet Controller
DaemonSet确保全部Node上运行一个Pod的副本。当有Node加入集群时,会自动为它们新增一个Pod;当有Node从集群移除时,这些Pod也会被回收。删除DaemonSet将会删除它创建的所有Pod。
2.5、Job Controller
Job负责批量处理短暂的一次性任务,即仅执行一次的任务,它保证批处理任务的一个或多个Pod成功结束。
2.6、CronJob Controller
CronJob负责周期性的处理任务,根据Cron表达式定时执行Job。
2.7、Node Controller
kubelet进程在启动时通过 API Server 注册自身节点信息,并定时向API Server汇报状态信息,API Server 在接收到这些信息后,会将这些信息更新到etcd中。在etcd 中存储的节点信息包括节点健康状况、节点资源、节点名称、节点地址信息、操作系统版本、Dooker版本、kubelet版本等。
节点健康状况包含就绪(True)、未就绪(False)、未知(Unknown)三种。
Node Controller通过API Server实时获取 Node的相关信息,实现管理和监控集群中各个Node的相关控制功能。
2.8、ResourceQuota Controller
ResourceQuota Controller(资源配额管理)确保指定的资源对象在任何时候都不会超量占用系统物理资源,避免由于某些业务在设计或实现上的缺陷,导致整个系统运行紊乱甚至宕机。比如可以对容器运行的CPU和Memory进行限制。对Namespace下的Pod数量、Service数量、PV数量等进行限制。
2.9、Service Controller 与 Endpoints Controller
我们先看看Service、Endpoints与Pod 的关系。如图下图所示,Endpoints表示一个Service对应的所有Pod副本的访问地址,Endpoints Controller就是负责生成和维护所有Endpoints对象的控制器。
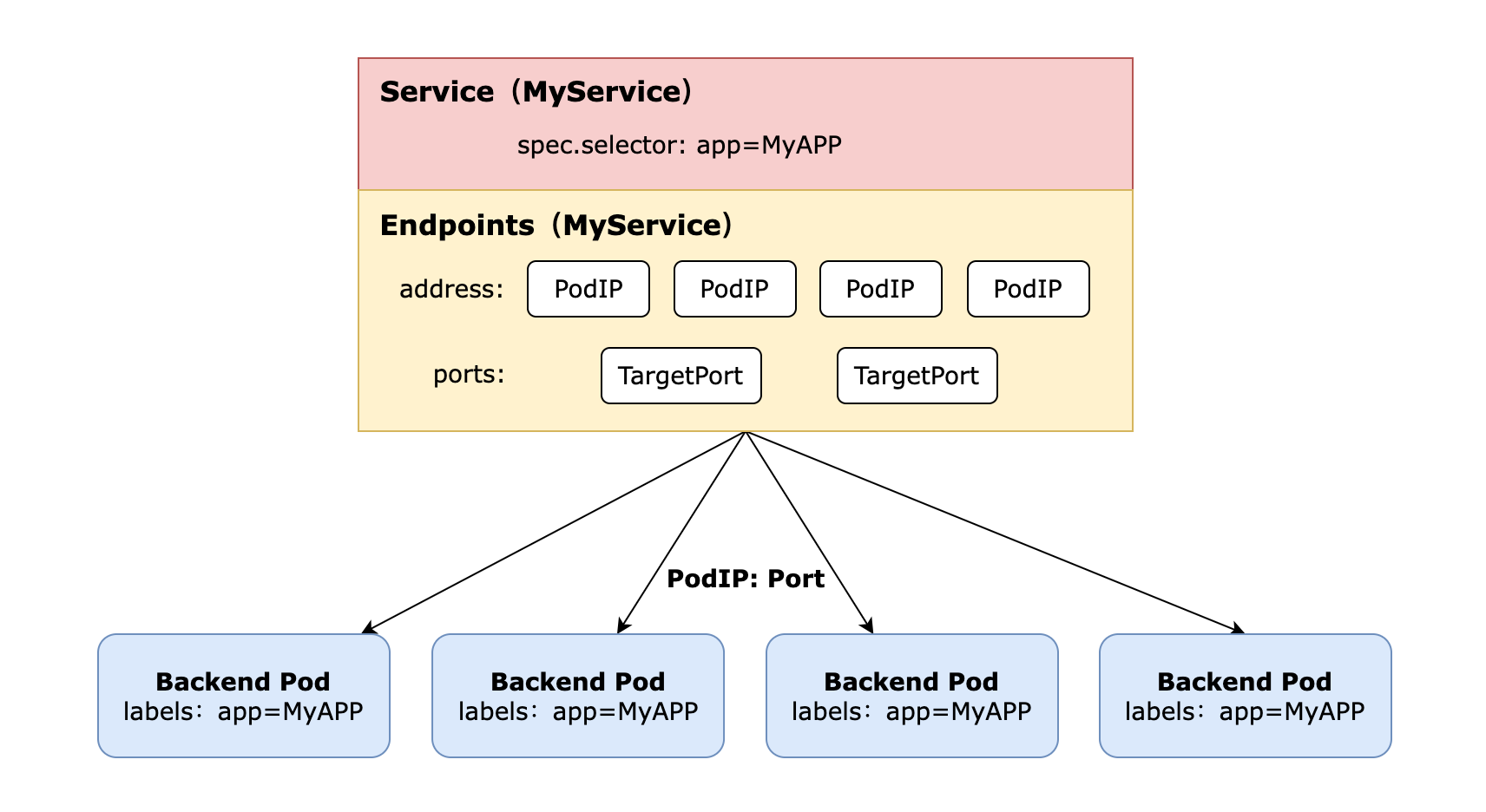
Endpoints Controller负责监听Service和对应的Pod副本的变化,如果监测到Service被删除,则删除和该Service同名的Endpoints对象。如果监测到新的 Service 被创建或者修改,则根据该 Service 信息获得相关的Pod列表,然后创建或者更新 Service 对应的Endpoints 对象。如果监测到Pod的事件,则更新它所对应的Service的Endpoints对象(增加、删除或者修改对应的 Endpoint 列表)。
那么,Endpoints对象是在哪里被使用的呢?答案是每个 Node 上的kube-proxy进程,kube-proxy进程获取每个Service的Endpoints,实现了Service的负载均衡功能。
Service Controller则是监听Service的变化,相应地创建、删除或者更新路由转发表(根据Endpoints的列表)。
3、控制器的使用
一个工作负载控制器资源通常包含3 个基本的组成部分。
- 选择器:匹配并关联 Pod 对象
- 期望的副本数:期望在集群中运行受控的 Pod 数量。
- Pod模板:用于新建 Pod 对象使用的模板。
工作负载控制器的资源的spec字段通常要包含如下字段:replicas、selector和template,其中template是用于定义 Pod模板。
常用控制器的编排yaml如下。
3.1、Deployment
管理一组Pod,假设设置副本数 replicas=2,这时 node01和node02上会各自分配一个Pod,现在将node02关闭,则会发现node01上会部署两个Pod。
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
namespace: test
labels:
app: nginx-deployment
spec:
replicas: 2
selector:
matchLabels:
app: nginx-deployment-tp
template:
metadata:
labels:
app: nginx-deployment-tp
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
tolerations:
- key: "node.kubernetes.io/unreachable"
operator: "Exists"
effect: "NoExecute"
tolerationSeconds: 30
3.2、StatefulSet
StatefulSet是几种工作负载当中较为复杂的一种,当然核心也是管理一组Pod。举个例子:假设设置副本数replicas=2,那么这一组Pod有如下特性:
1、启动的有序性:pod-0启动之后,再启动pod-1。
2、停止的有序性:pod-1停止之后,再停止pod-0。
3、有状态:pod的id不变,创建的PVC是是跟Pod绑定的,有独特的volumeClaimTemplate配置,会利用storgeClass自动创建PVC和PV 。
4、稳定服务发现: Service可以找到自己想找到的pod,因为Pod的id是固定的有状态的。例如要访问某个Pod,可以直接使用curl pod名称.svc名称.命名空间.svc.cluster.local。
apiVersion: v1
kind: Service
metadata:
name: nginx-statefulset-svc
namespace: test
spec:
# ClusterIP | LoadBalancer |
type: ClusterIP
# headless service
clusterIP: None
selector:
app: nginx-statefulset-tp
ports:
- name: http
port: 80
targetPort: 80
# nodePort: 30080
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: nginx-statefulset
namespace: test
labels:
app: nginx-statefulset
spec:
replicas: 2
serviceName: nginx-statefulset-svc
selector:
matchLabels:
app: nginx-statefulset-tp
template:
metadata:
labels:
app: nginx-statefulset-tp
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
volumeMounts:
- name: www
mountPath: /usr/share/nginx/html
tolerations:
- key: "node.kubernetes.io/unreachable"
operator: "Exists"
effect: "NoExecute"
tolerationSeconds: 30
volumeClaimTemplates:
- metadata:
name: www
spec:
resources:
requests:
storage: 100Mi
accessModes:
- ReadWriteOnce
storageClassName: nfs-client
3.3、DaemonSet
管理一组Pod,相比Deployment和StatefulSet,没有副本数的概念。它有如下特性:
- 每个node上部署一个pod
- node上部署的pod不会被驱逐,默认添加对所有节点污点的容忍
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: nginx-daemonset
namespace: test
labels:
app: nginx-daemonset
spec:
selector:
matchLabels:
app: nginx-daemonset-tp
template:
metadata:
labels:
app: nginx-daemonset-tp
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
3.4、Job
执行一次就结束的Pod
apiVersion: batch/v1
kind: Job
metadata:
name: hello
namespace: test
spec:
# 尝试backoffLimit+1次 没有成功 则退出Job
backoffLimit: 2
completions: 3
template:
spec:
# 仅支持 OnFailure Never
restartPolicy: Never
containers:
- name: busybox
image: busybox
imagePullPolicy: IfNotPresent
command:
- /bin/sh
- -c
- echo "Hello My Job"
3.5、CronJob
Job的基础上定义Cron表达式,定时执行Job
apiVersion: batch/v1
kind: CronJob
metadata:
name: hello
namespace: test
spec:
# ┌───────────── 分钟 (0 - 59)
# │ ┌───────────── 小时 (0 - 23)
# │ │ ┌───────────── 月的某天 (1 - 31)
# │ │ │ ┌───────────── 月份 (1 - 12)
# │ │ │ │ ┌───────────── 周的某天 (0 - 6)(周日到周一;在某些系统上,7 也是星期日)
# │ │ │ │ │ 或者是 sun,mon,tue,web,thu,fri,sat
# │ │ │ │ │
# │ │ │ │ │
# * * * * *
schedule: "* * * * *"
# Allow - 允许并发
# Forbid - 不允许并发 丢弃新的job
# Replace - 不允许并发 丢弃老的job
concurrencyPolicy: Allow
# 记录成功的job数量
successfulJobsHistoryLimit: 3
# 记录失败的job数量
failedJobsHistoryLimit: 1
jobTemplate:
spec:
template:
spec:
# 仅支持 OnFailure Never
restartPolicy: Never
containers:
- name: busybox
image: busybox
imagePullPolicy: IfNotPresent
command:
- /bin/sh
- -c
- echo "Hello My Cron Job"
总结:本文主要介绍了Kubernetes控制器的原理、类型、使用,控制器的核心功能:驱动对象的当前状态逼近提交的期望状态。希望对你有帮助!本文部分内容查阅自《Kubernetes进阶实战》和《kubernetes权威指南》。
本篇完结!感谢你的阅读,欢迎点赞 关注 收藏 私信!!!
原文链接:http://www.mangod.top/articles/2023/08/30/1693367533460.html、https://mp.weixin.qq.com/s/QIgu4eh48yCNs7HdrL32iw
