据东方国信发布的消息,该公司联同紫光股份、新华三集团签署了一份协议,其中新华三集团将向东方国信 供应英伟达特供版H20 GPU算力服务器。这是英伟达特供版AI芯片在中国市场的第一个订单。此外,据报道,百度、字节跳动、腾讯和阿里巴巴四家企业共同向英伟达订购了价值50亿美元的AI芯片,其中包括特供版芯片。这也表明了中企对英伟达特供版AI芯片的高度信任和支持。
ChinaStarMarket.cn报道称,英伟达计划在2024年第二季度启动针对中国市场特供AI芯片的量产,这包括HGX H20、L20 PCle 和 L2 PCle GPU三款产品。其中,H20是性能最为强大的型号。为响应美国出口管制的最新规定,这三款新品的算力都进行了相应的降低。
据悉,H20是配备96 GB HBM3内存的HGX形式的加速卡,使用了性能有所削弱的旗舰H100硅片,也可能是基于Hopper的新型AI和HPC GPU设计。H20芯片的综合性能为4800,刚好达到了美国政府的出口限制的上限。这也意味着,H20芯片是英伟达能够向中国出售的最强大的AI芯片。
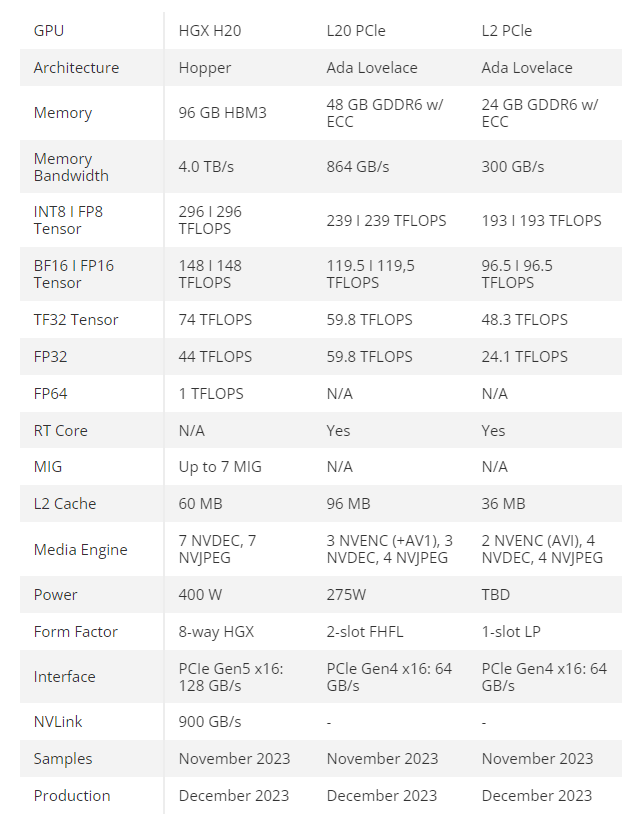 作为一款专注于训练和推理的芯片,H20在大语言模型推理任务上比H100快20%。然而,H20的性能在多个方面受到限制,包括仅提供FP64精度1 TFLOPS(相比H100的34 TFLOPS)和FP16/BF16精度148 TFLOPS(相比H100的1,979 TFLOPS),这导致在带宽和计算速度等关键指标上存在限制,整体算力理论上比H100降低约80%。
英伟达的特供版AI芯片虽然在性能上有所缩水,但是仍然有一定的优势,尤其是在模型训练和软件生态方面,因此,英伟达的特供版AI芯片并不是没有市场需求,只是需求量可能没有原版的芯片那么大。如果需要使用英伟达H20、H100、H800、4090等GPU,可以点击【联系】英伟达全球官方合作伙伴NPN——英智未来公司。
作为一款专注于训练和推理的芯片,H20在大语言模型推理任务上比H100快20%。然而,H20的性能在多个方面受到限制,包括仅提供FP64精度1 TFLOPS(相比H100的34 TFLOPS)和FP16/BF16精度148 TFLOPS(相比H100的1,979 TFLOPS),这导致在带宽和计算速度等关键指标上存在限制,整体算力理论上比H100降低约80%。
英伟达的特供版AI芯片虽然在性能上有所缩水,但是仍然有一定的优势,尤其是在模型训练和软件生态方面,因此,英伟达的特供版AI芯片并不是没有市场需求,只是需求量可能没有原版的芯片那么大。如果需要使用英伟达H20、H100、H800、4090等GPU,可以点击【联系】英伟达全球官方合作伙伴NPN——英智未来公司。
