https://zhuanlan.zhihu.com/p/439633733 内存带宽应该是 9.6*1024*6 算出来来的
实际值 4.8TB/S 和内存141G 应该是进行了一些删减
理论上是六个 24GB的HBM3e的内存. 应该是为了安全和稳定进行了限速
不然理论上可以达到 接近 6BG的带宽和 144G的HBM3e的内存大小.
英伟达在 2023 年全球超算大会上发布了备受瞩目的新一代 AI 芯片——H200 Tensor Core GPU。相较于上一代产品 H100,H200 在性能上实现了近一倍的提升,内存容量翻倍,带宽也显著增加。
据英伟达称,H200 被冠以当世之最的芯片的称号。不过,根据发布的信息来看,H200 Tensor Core GPU 并没有让人感到意外。在 2023 年 8 月 30 日,英伟达就发布了搭载 HBM3e 技术的 GH200 Grace Hopper 的消息,而 HBM3e 也是 H200 芯片的升级重点。
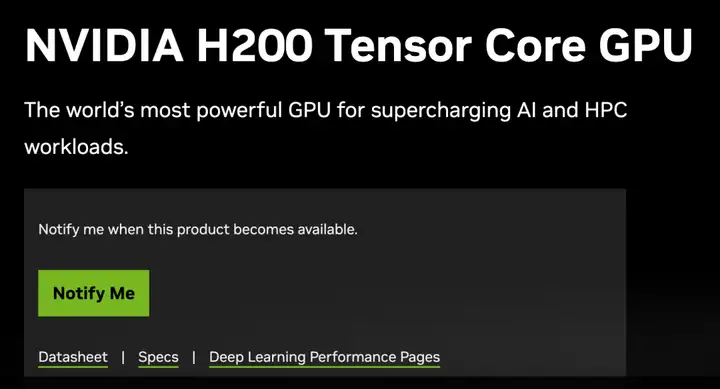
HBM3E——H200升级重点
NVIDIA H200 是首款提供 HBM3e 的 GPU,HBM3e 是更快、更大的内存,可加速生成式 AI 和大型语言模型,同时推进 HPC 工作负载的科学计算。借助 HBM3e,NVIDIA H200 的显存带宽可以达到 4.8TB/秒,并提供 141GB 的内存。相较于 H100,H200 在吞吐量、能效比和内存带宽等方面均有所提升。

HBM3E 到底是什么技术,让 H200 有了如此大的提升?接下来我们就来详细了解下 HBM3E。
HBM3E(High Bandwidth Memory 3E)是最新一代的高带宽内存技术,它是 HBM(High Bandwidth Memory)系列的进一步改进和升级版本。HBM3E 在速度和容量方面都有显著提升,旨在满足处理大规模数据和高性能计算的需求。
相较于 HBM,HBM3E 内存具有更快的数据传输速度,可实现更高的带宽。同时,HBM3E 可以提供更高密度的内存芯片,从而使系统能够拥有更大的内存容量。这非常有利于大型数据集和复杂计算任务。
在架构上,HBM3E 继续采用了堆叠式设计,将多个存储层叠加在一起,以实现更高的带宽和更低的能耗。相较于传统的内存技术,HBM3E 在给定带宽的情况下能够提供更高的能效。HBM3E 内存芯片的堆叠层数更多,从而实现更高的存储密度。这使得在相对较小的物理空间内实现更大的内存容量成为可能。
HBM3E 的引入旨在满足处理大规模数据和高性能计算的需求,尤其适用于人工智能、机器学习、深度学习等领域。它提供了更高的带宽、更大的容量和更高的能效,能够加速数据处理和计算任务,推动各种应用的发展。
HBM3E 不仅满足了用于 AI 的存储器所需的速度规格,而且在发热控制和客户使用便利性等各个方面达到了全球最高水平。在速度方面,它能够每秒处理 1.15TB 的数据,相当于在 1 秒内可以处理 230 部全高清(FHD)级别的电影(每部 5GB)。通过使用即将推出的 HBM3E 内存,NVIDIA 将能够提供在内存带宽受限的工作负载中具有更好实际性能的加速器,同时也能够处理更大的工作负载。在2023 年 8 月份,我们就看到 NVIDIA 计划发布配备 HBM3 的 Grace Hopper GH200 超级芯片版本。这次 NVIDIA 宣布的 H200,其实就是配备 HBM3E 内存的独立 H100 加速器的更新版本。
H200 VS H100
接下来我们就来具体看看,相较于 H100,H200 的性能提升到底体现在哪些地方。
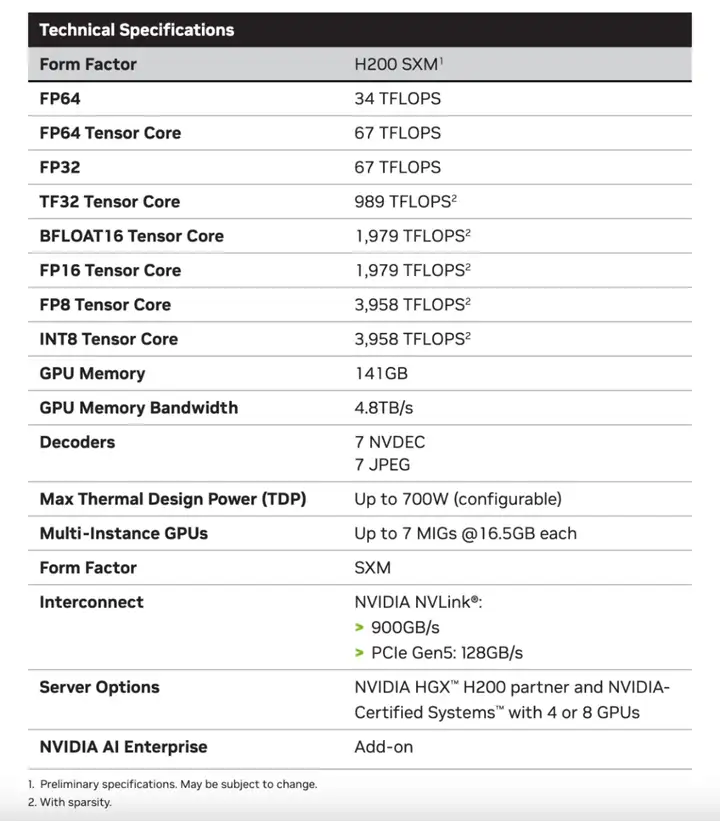 △ H200的相关参数
△ H200的相关参数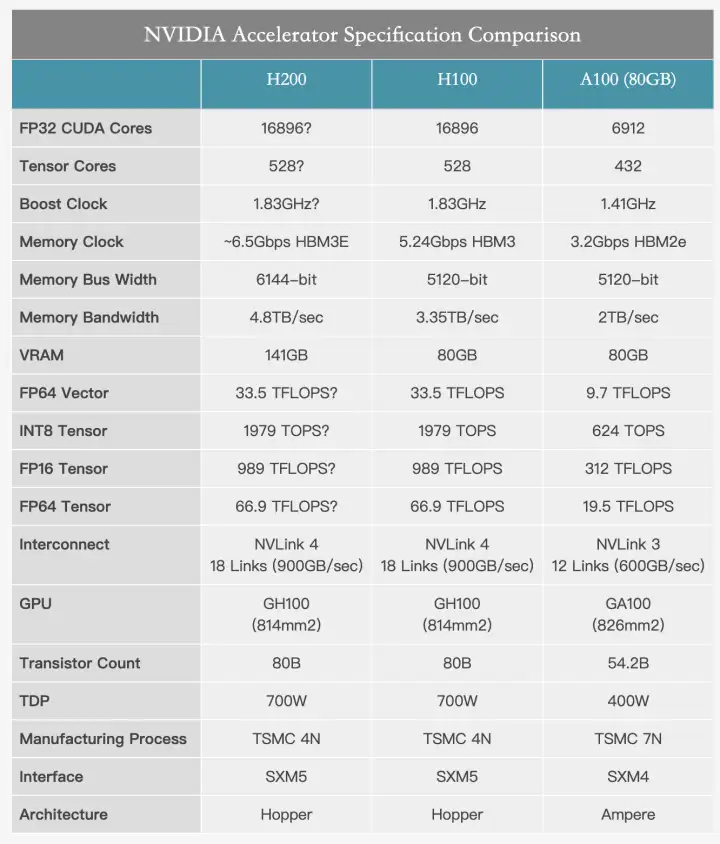
性能计算
H200 具备超过 460 万亿次的浮点运算能力,可支持大规模的AI模型训练和复杂计算任务。HGX H200采用了NVIDIA NVLink 和 NVSwitch 高速互连技术,为各种应用工作负载提供最高性能,包括对超过 1750 亿个参数的最大模型进行的 LLM 训练和推理。借助 HBM3e 技术的支持,H200 能够显著提升性能。
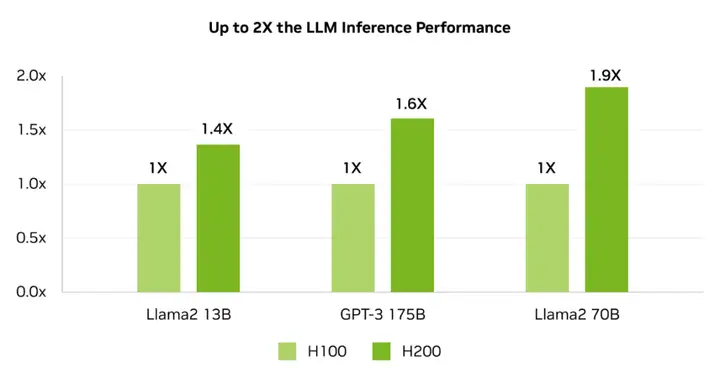
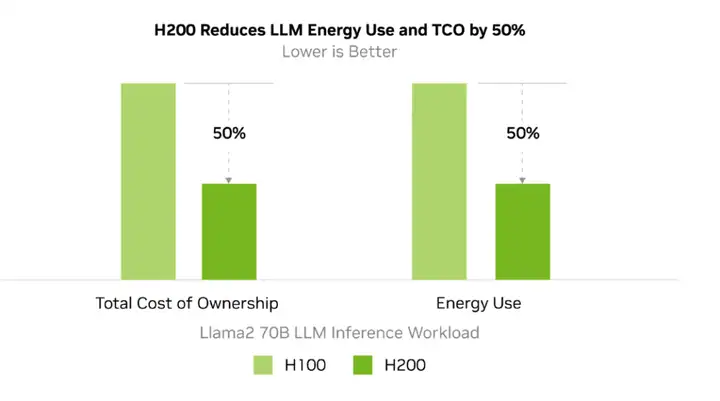
在 HBM3e 的加持下,H200 能够将 Llama-70B 推理性能提升近两倍,并将运行 GPT3-175B 模型的性能提高了60%。对于具有 700 亿参数的 Llama 2 大模型,H200 的推理速度比 H100 快一倍,并且推理能耗降低了一半。此外,H200 在 Llama 2 和 GPT-3.5 大模型上的输出速度分别是 H100 的 1.9 倍和 1.6 倍。
高速内存
NVIDIA 的 H200 芯片支持高达 48GB 的 GDDR6X 内存,其内存带宽可达 936GB/s,有效提高了数据传输速度并降低了延迟。同时,借助 HBM3e技术,NVIDIA H200 每秒可以提供 141GB 的内存容量和 4.8GB的内存带宽。对比 H100 的 SXM 版本,显存从 80GB 提升 76%,带宽从每秒 3.35TB 提升了 43%。
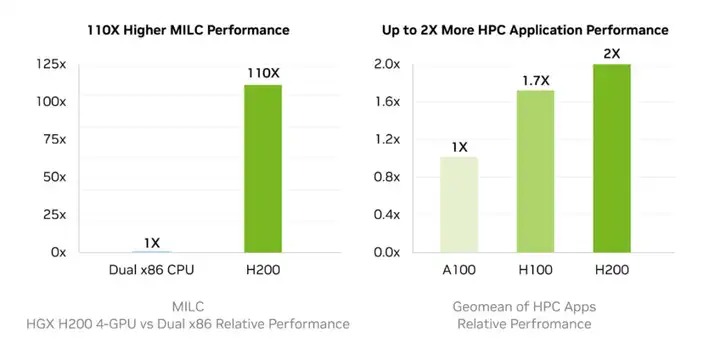
内存带宽对于高性能计算(HPC)应用程序非常重要,因为它可以实现更快的数据传输,减少复杂处理过程中的瓶颈。对于模拟、科学研究和人工智能等内存密集型HPC应用,H200的更高内存带宽可以确保高效地访问和操作数据。与传统的CPU相比,使用 H200 芯片可以将获取结果的时间加速多达 110 倍。
硬件加速
H200 是一款内置了强大的 AI 加速器的芯片,它能显著提高神经网络的训练和推理速度。该芯片采用了先进的 7 纳米制程工艺,拥有超过 1000 亿个晶体管,整个芯片的面积达到 1526 平方毫米。
NVIDIA H200 芯片将应用于具有四路和八路配置的 NVIDIA HGX H200 服务器主板,这些主板与 HGX H100 系统的硬件和软件兼容。H200 芯片还可用于采用 HBM3e 内存的 NVIDIA GH200 Grace Hopper 超级芯片。八路配置的 HGX H200 主板提供超过 32 petaflops 的 FP8 深度学习计算能力和 1.1TB 的聚合高带宽内存。

能源效率
H200 芯片采用先进的散热技术,以确保在高性能计算的同时保持较低的功耗。这使得 H200 在功耗配置与 H100 相当。
训练能力
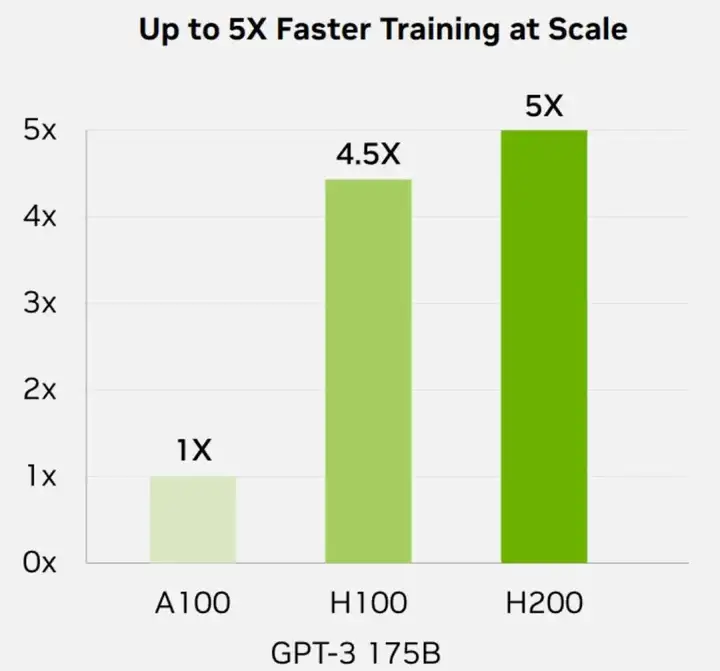
在之前用于评估 AI 芯片性能的一个重要指标——训练能力方面,H200 并没有明显的提升。根据英伟达提供的数据,对于 GPT-3 175B 大模型的训练任务而言,H200 只比 H100 强 10%。
H200 和 H100 芯片都基于英伟达的 Hopper 架构开发,因此这两款芯片是相互兼容的。对于已经使用 H100 的企业来说,无需进行任何调整,可以直接进行更换。此外,就峰值算力而言,H100 和 H200 实际上是相同的,它们的 FP64 矢量计算能力为 33.5TFlops,FP64 张量计算能力为 66.9TFlops,提升的参数主要是显存容量和内存带宽。
聊了这么多,相信大家对英伟达新推出的 H200 有了一定了解。近期,又拍云与厚德云联合推出了全新的 GPU 产品,新用户注册即可免费体验 RTX4090 GPU。您可以通过一键搭建 CUDA、Stable Diffusion 等开发环境,轻松快捷地体验强大的 GPU 算力,有兴趣的同学扫描下方二维码发送“体验 4090”,即可免费体验 RTX4090 GPU。
标签:芯片,带宽,HBM3E,转帖,H100,NVIDIA,H200,内存 From: https://www.cnblogs.com/jinanxiaolaohu/p/17986963