Improving Graph Collaborative Filtering with Neighborhood-enriched Contrastive Learning论文阅读笔记
Abstract
目前的对比方法通常采用随机抽样的方式构建对比对,忽略了用户之间的相邻关系,不能充分利用对比学习作为推荐的潜力
为了解决上面的问题,我们提出了一种新的对比学习方式,即邻域丰富对比学习(Neighbor-enriched Contrastive Learning NCL),它明确地将潜在的邻居合并到对比对中。具体来说,我们分别从图结构和语义空间中引入一个用户(或一个项目的)邻居。对于交互图上的结构邻居,我们开发了一个新的结构对比目标,它将用户(或项目)和它们的结构邻居视为正对比对。在实现中,用户(或项目)和邻居的表示对应于不同GNN层的输出。此外为了挖掘语义空间中潜在的邻域关系,我们假设具有相似表示的用户在语义邻域内,并将这些语义邻域纳入原型对比目标,提出的NCL可以用EM算法进行优化
Introduction
这里首先讲一下现存方法的缺点,通过随机抽样节点或破坏子图来构造对比对。缺乏考虑如何为推荐任务构建更有意义的对比学习任务。
除了直接的用户-项目交互外,还存在多种对推荐任务有用的潜在关系,我们的目标是设计更有效的持续学习方法,在神经图协同过滤中利用这些有用的关系。特别地,我们考虑节点级关系,它比图级关系更有效。我们将这些附加关系描述为节点的丰富邻域,这可以从两个方面来定义:
- 结构邻居指的是通过高阶路径进行结构连接的节点
- 语义邻居指的是语义上可能在图上无法直接到达的相似邻居。
我们的目标是利用这些丰富的节点关系来改善节点表示的学习,即编码用户偏好或项目特征
为了对丰富的邻域进行整合和建模,我们提出了邻域丰富的对比学习,这是一个与模型无关的对比学习框架。NCL基于两种扩展邻居构建节点级对比目标。但是节点级的对比目标通常需要对每个节点进行两两学习,是很耗时的。所以考虑到效率问题,我们为每种邻居学习一个有代表性的嵌入,这样一个节点的对比学习就可以通过两个有代表性的嵌入(结构或语义)来完成。
具体来说,对于结构邻居,我们注意到GNN的第k层输入涉及到k跳邻居的聚合信息。因此我们利用GNN的第k层输入作为一个节点的k跳邻居的表示(这里好怪啊)。我们设计了一个结构感知的对比一个学习目标,它提取一个节点的表示和其结构邻居的代表性嵌入,对于语义邻居,我们设计了一个典型的对比学习目标来捕获节点与其原型之间的相关性。粗略的说,一个原型可以看作是表示空间中语义相似的邻居簇的质心。由于原型是潜在的,我们进一步提出使用期望最大化算法来推断原型。本文的主要贡献如下:
- 提出了一个名为NCL的与模型无关的对比学习框架,它结合了结构邻居和语义邻居,以改进神经图的协同过滤。
- 提出学习两种邻居的代表性嵌入,这样对比学习只能在一个节点和相应的代表性嵌入之间进行,这在很大程度上提高了算法的效率
Method
NCL的模型结构如下:
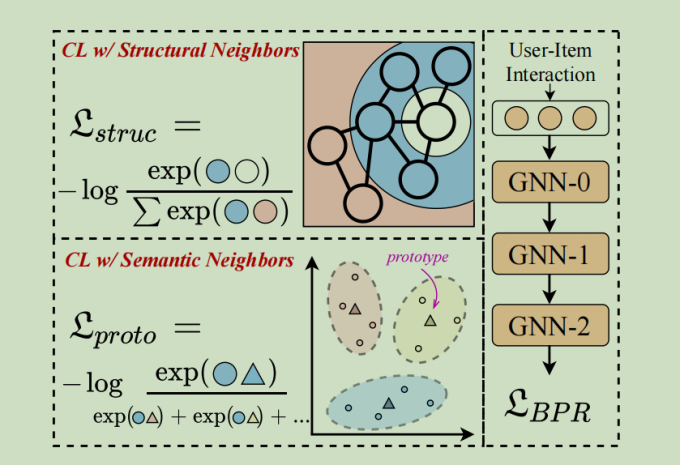
Graph Collaborative Filtering BackBone
就是采用了LightGCN
Contrastive Learning with Structural Neighbors
将每个用户或项目和它的结构邻居进行对比,结构邻居的表示通过GNN的层传播进行聚合,base-GNN模型的第l层输出\(z(l)\)是每个节点的l跳邻居的加权和
因为交互图是一个二部图,我们可以从GNN的偶数层输出中得到齐次邻域的表示。然后将用户自身的嵌入和偶数层GNN的相应输出的嵌入视为正对
也就是最初的用户嵌入和第偶数跳的用户嵌入进行对比
Contrastive Learning with Semantic Neighbors
结构对比损失对用户和项目的齐次邻居平等对待,会在噪声中引入对比对。为了减少结构邻居的噪声影响,我们通过合并语义邻居来扩展对比对,语义邻居是指图上不可到达的节点,但是具有相似的特征或偏好
可以通过学习每个用户和项目的潜在原型来识别语义邻居。在此基础上,进一步提出了原型对比目标来探索潜在的语义邻居。因为相似的用户/项目倾向于落在邻近的嵌入空间中,而原型是代表一组语义邻居的集群的中心。因此对用户和项目的嵌入应用聚类算法来获得用户或项目的原型。但是由于这个过程不能端到端优化,所以学习了EM算法的原型对比目标。(说是加了个EM算法,实际上最后就是搞成InfoNCE损失嘛)
也就是用户嵌入和对所有用户进行聚类后的该用户所属的聚类中心进行对比
Conclusion
在这项工作中,提出了一种新的对比学习的凡是,名为邻域丰富对比学习,以明确地捕获潜在的节点相关性到对比学习,用于图协同过滤。我们分别从图的结构和语义空间的两个方面来考虑用户(或项目)的邻居。首先,为了利用交互图上的结构邻居,我们开发了一个新的结构对比目标,可以基于gnn的协同过滤方法相结合。其次,为了利用语义邻居,我们通过将嵌入进行聚类,并将语义邻居合并到原型对比目标中,来推导出用户/项目的原型
标签:嵌入,论文,语义,用户,笔记,节点,NCL,邻居,对比 From: https://www.cnblogs.com/anewpro-techshare/p/17977608