1、背景
魔笛活动平台目前在采集每个活动的用户行为数据并进行查询,解决线上问题定位慢,响应不及时的问题,提升客诉的解决效率。目前每天采集的数据量5000万+,一个月的数据总量15亿+,总数据量40亿+,随着接入的活动越来越多,采集上报的数据量也会越来越大。目前采用ClickHouse来存储数据,可以在秒级别内处理数十亿条数据,能够达到50MB-200MB/s的写入吞吐能力,按照每行100Byte估算,大约相当于50W-200W条/s的写入速度。这里关于ClickHouse就不再赘述,感兴趣的可以看上篇文章。这里是我在实际使用过程中,发现了一些写入和查询的相关问题,并进行了相应的优化。
2、写入优化
2.1 历史方案
为了更好的收集活动数据,自己开发了一款埋点sdk用于收集各业务的活动埋点数据,埋点数据统一异步发送MQ,然后活动平台消费MQ数据,经过一定处理后通过MybatisPlus方式批量写入clickhouse,每次批量写入5000条。
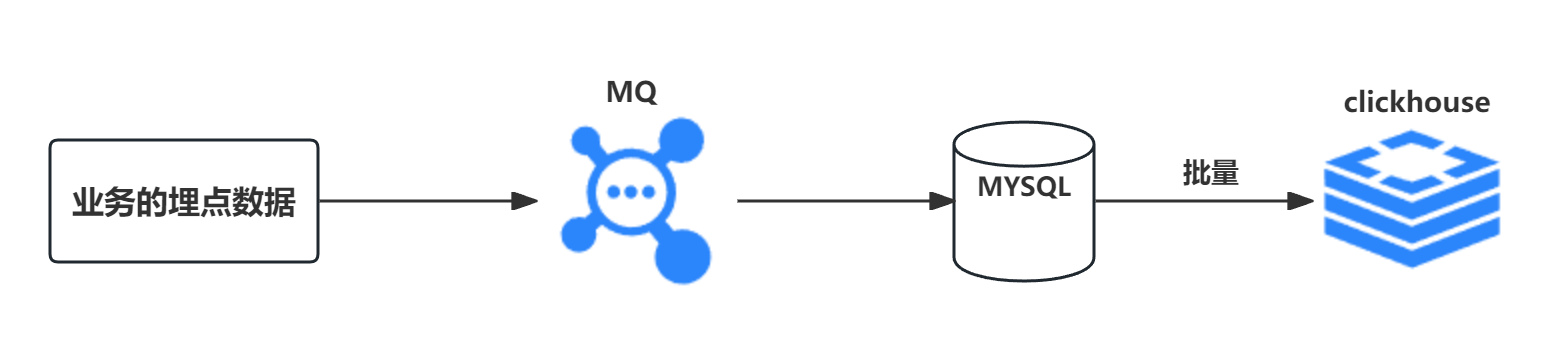
2.2 出现的问题
当消费MQ的TPS超过3000的时候,出现了以下问题:
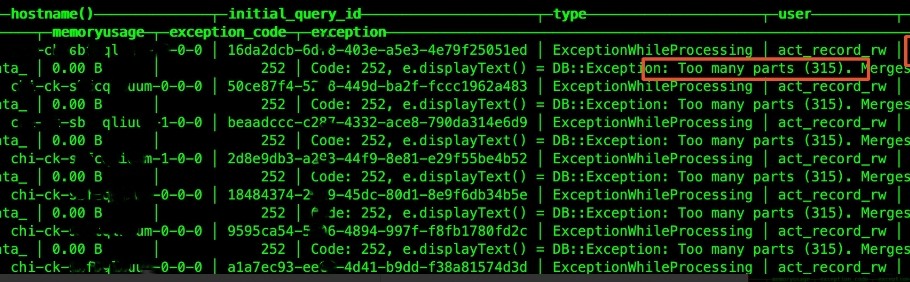
1. 出现报错:写入量大的时候会报这个错误:too many parts。
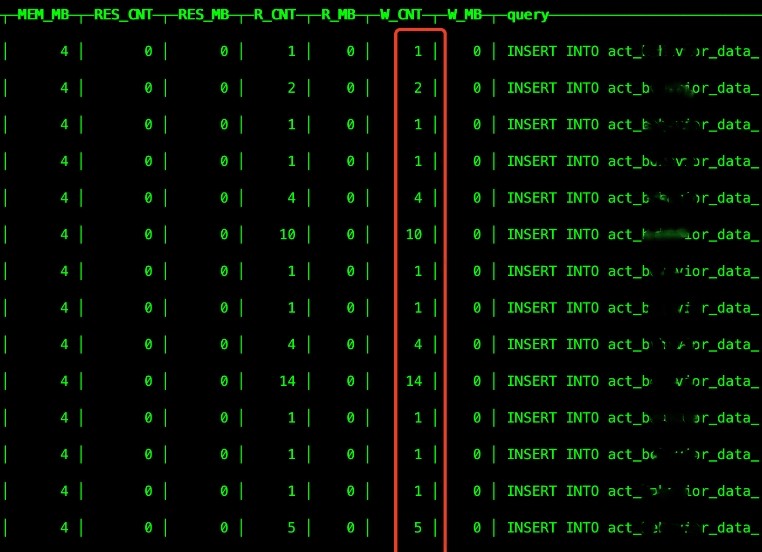
2. 单次写入条数少:我明明配置的每次批量写入5000条,但是每次基本都是一条一条写入。
3. 性能很差:单次写入最大耗时居然有250000毫秒,平均也超过50000毫秒!

2.3 出现问题的原因
(1)单次写入条数少原因:MybatisPlus的savebatch单次最大写入SQL是4M,按照单条活动的数据大小,最大单次也就写1000条数据,再多就会一次一次写入。所以虽然配置的是每次写入5000,但是实际看是每次写入一条或者几条。
(2)too many parts错误:clickhouse操作数据的最小操作单元是block,每次写入都会按照zookeeper记录的唯一自增的blockId,按照PartitionId_blockId_blockId_0生成data parts,也就是小文件,然后后台会有merge线程,不定时(分钟级别)的将多个小文件进行合并,生成PartitionId_MinBlockNum_MaxBlockBum_Level的文件,未达到data parts最小rows或者大小限制前,会持续merge,每次merge的耗时大概5分钟左右。由于merge线程池是固定的,默认32,所以如果插入过于频繁,merge压力过大,处理不了,就会出现too many parts的报错。例如并发数为 200,这样一批写入到 ClickHouse 中就会产生 200 个文件,几批下来如果 ClickHouse 内部线程没来及合并相同分区,就会抛异常。而 ClickHouse 默认一次合并超过 300 个文件就会报错。
(3)性能差的原因:因为写clickhouse底层都是使用httpclient的方式写入的,所以对于clickhouse来说单条频繁写入效率很低。

2.4 改造方案
(1)写入clickhouse的并发数调小,批处理的数据size间隔调大,比如之前200并发调整到50并发,从之前一批1条数据调整到10000条数据,clickhouse官网建议每批次写入100000+条(要视flink TM 内存大小调整,防止批量过大出现oom)。从而减少clickhouse文件的个数,避免超过parts_to_throw_insert默认值。一般最好一秒钟写入一次clickhouse。
(2)将由MybatisPlus的savebatch批量写入改为其他方式写入。采用clickhouse原生的jdbc写入或者flink摄入,flink我这边自定义了sink 用于摄入clickhouse,达到一定批次或者执行checkpoint时就写入一次。
(3)为了保证批量,我这边采用实时双buffer缓冲队列方式写入,这个队列可以是本地缓存队列,也可以是redis缓存队列。根据时间窗口期和固定写入阈值(针对波动大的可以按照二次指数平滑函数去确定阈值)进行写入与否的判断。设置一个读队列,一个写队列,并设置一个开关,一个阈值,一个定时器,当数据来时,默认放入写队列中,当队列中数据的数量大于阈值,将开关关闭,将写队列数据放到读队列中,从读队列拿出数据批量写入clickhouse,将开关打开,清空队列中数据。如果队列中数据在一定时间内,比如10秒,一直没有达到阈值,也关闭开关,写队列数据放到读队列中,从读队列拿出数据批量写入clickhouse,将开关打开,清空队列中数据。
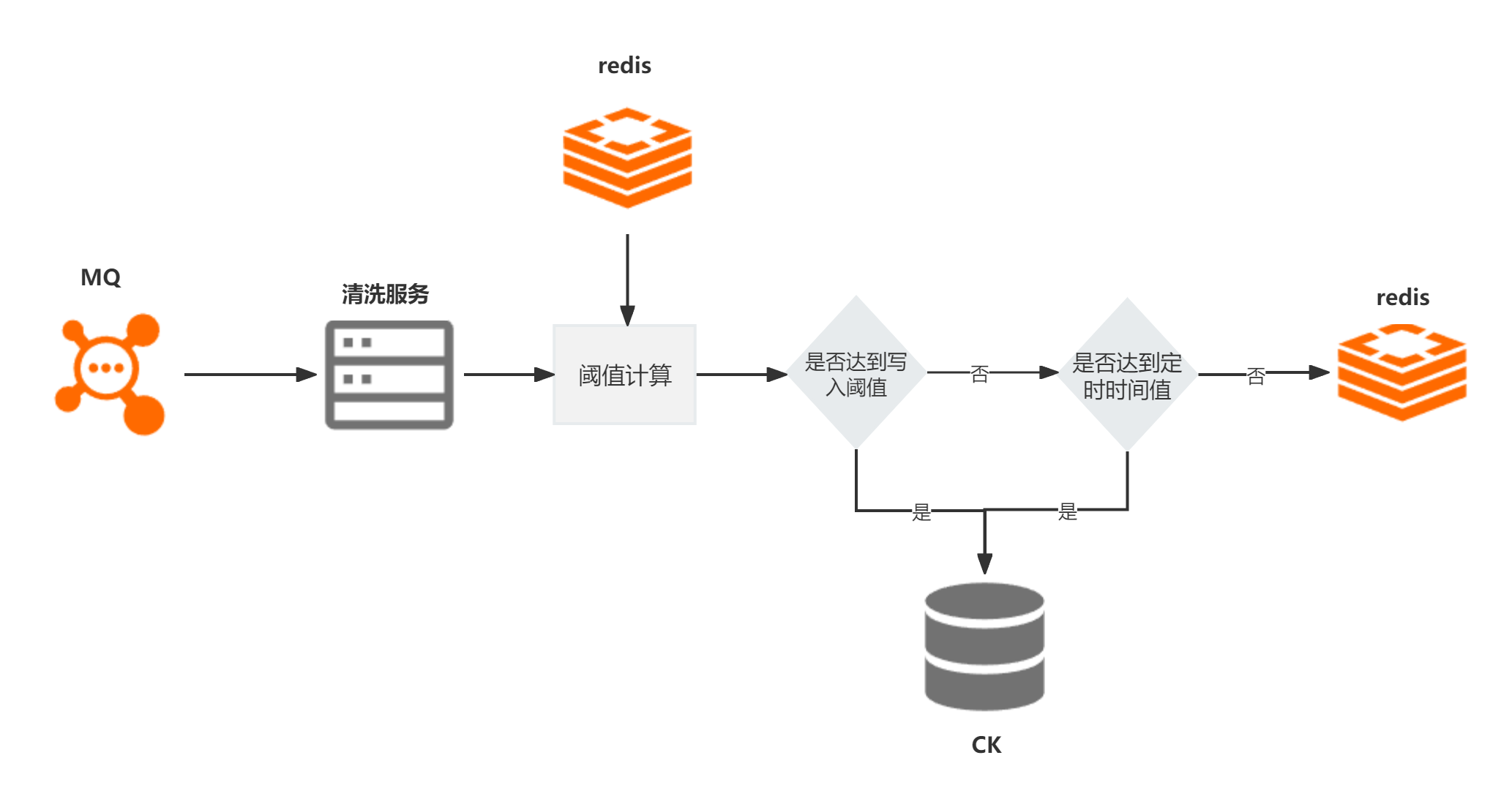
2.5 效果
MQ消费的TPS最高是2万+,也就是每秒写入的条数最高超过了俩万,在此情况下,保证了每秒只写入clickhouse一次,写入性能也稳定在50毫秒左右,写入性能相比较于之前方案提升了5000倍,吞吐量相较于之前也提升了几十倍。


3、查询优化
3.1 历史方案
索引:一级索引是时间,二级索引是id,因为大部分是根据时间来查询,id作为排序。
字段值:写入时候将字段值默认为空。
查询:查询时候查询所有列的数据,再线性查询每条数据的活动信息、奖励信息等。
3.2 出现的问题
目前生产环境有40亿+数据,耗时很长,达到了30秒,非常非常慢。
3.3 出现问题的原因
尝试通过SQL执行计划来确定一个sql 的查询瓶颈。目前查看sql 执行计划有两种方法:
方法一(20.6之前版本):clickhouse-client -u xxxx --password xxxxxx --send_logs_level=trace <<< 'your query sql' > /dev/null;
方法二(20.6与20.6之后版本):explain SQL。
方法一是指定clickhouse 执行日志级别为trace,这样可以打印出来sql 各个阶段执行的日志,通过日志型来分析SQL执行情况,能够详细的了解到SQL执行情况。方法二有点像mysql那样,但这个只能打印部分SQL执行情况,不够详细。所以我们最终使用了方法一。
通过分析发现这几方面原因:
(1)查询缓慢的都是固定维度查询的,例如:用户pin、活动id等。分析了查询sql 的执行计划,主键索引和分区都没有用到。没有用到主键索引是导致查询慢的主要原因。至于为什么,这个要从clickhouse的底层存储结构说了,这里不详细说明,想了解的可以去看看我上篇文章。
(2)因为ClickHouse对于空值,在底层存储是用了单独的文件存储。相对于没有空值的情况,存在空值会稍微影响查询性能。
(3)没有分区查询,跟hive一样,表分区后,底层也会有相关的分区目录,筛选的时候添加分区过滤,提升查询性能。
3.4 改造方案
1.索引优化:clickhouse 的存储结构决定对于大数据量查询时,使用主键索引能够精确的找到所需的数据块,减少不必要的数据块扫描,这样更够极大的提高查询效率。将用户pin作为一级索引,将时间作为二级索。 2.填充有空值的字段:对于一些表字段,若存在空值,则可以考虑使用无业务场景意义的字符进行填充。 3.主键查询:减少查询字段:将select * 改为查询关键字段,select operate_time,id。 4.多线程:多条活动数据,多线程查询出活动和奖励的相关信息。 5.分区存储:将每7天数据放入一个分区中,查询时候根据不同时间查询不同分区的数据。 6.count优化:因为clickhouse对每个表的数据量,在底层文件中提供了预数据。所以能直接使用count()则避免使用count(col_name)。 7.聚合外推:如将sum(money * 2) 变成 sum(money) * 2。对数据库来说,后者的计算量明显少一点。 8.高级函数:ClickHouse中有很多很好用的函数。如:使用multiIf()替代多重case when,对于版本数据的获取使用argMax()函数,而非用子查询关联取最大值。3.5 效果
40亿+的数据量,由之前13-20秒提升为800-1200毫秒返回,约提升15-20倍。
4、思考
如果后续数据量超过百亿,达到几百亿甚至千亿级别的数据量,性能还会不会这么好呢?这时候可以考虑分表策略,将用户pin进行hash,例如分十张表存储数据,将每张表数据控制在50-100亿级别。在数据写入这块,使用分表了策略后还需要自定义分表摄入的策略。
作者:京东科技 苗元
来源:京东云开发者社区 转载请注明来源
标签:队列,数据,写入,查询,秒级,数据量,QPS,级别,clickhouse From: https://www.cnblogs.com/Jcloud/p/17958051