What is State
虽然数据流中的许多操作一次只查看一个单独的事件(例如事件解析器),但某些操作会记住多个事件的信息(例如窗口算子)。 这些操作称为有状态的(stateful)。
有状态操作的一些示例:
- 当应用程序搜索某些事件模式(event patterns)时,状态(state)将存储迄今为止遇到的事件序列。
- 当每分钟/小时/天 聚合事件时,状态(state)保存待处理的聚合。
- 当通过流中的数据点训练机器学习模型时,状态(state)保存模型参数的当前版本。
- 当需要管理历史数据时,状态(state)允许有效访问过去发生的事件。
Flink 需要了解状态(state),以便使用检查点(checkpoint)和保存点(savepoint)实现容错(fault-tolerant)。
额外的,状态(state)还允许重新扩展 Flink 应用程序,这意味着 Flink 负责跨并行实例重新分配状态(state)。
在处理状态(state)时,了解 Flink 的状态后端(state-backends)也可能很有用。 Flink 提供了不同的状态后端(state-backends)来指定状态的存储方式和位置。
Keyed State
键控状态(Keyed State)被维护在可以被认为是嵌入式键/值存储中。 状态(state)与有状态算子(the stateful operators)读取的流一起严格分区和分布。 因此,对键/值状态的访问只能在键控流(Keyed Stream)上进行,即在键控/分区数据交换之后,并且仅限于与当前事件的键关联的值。对齐 流和状态的键(keys of stream and state)可确保所有状态更新都是本地操作,从而保证一致性而无需事务开销。 这种对齐还允许 Flink 重新分配状态并透明地调整流分区。
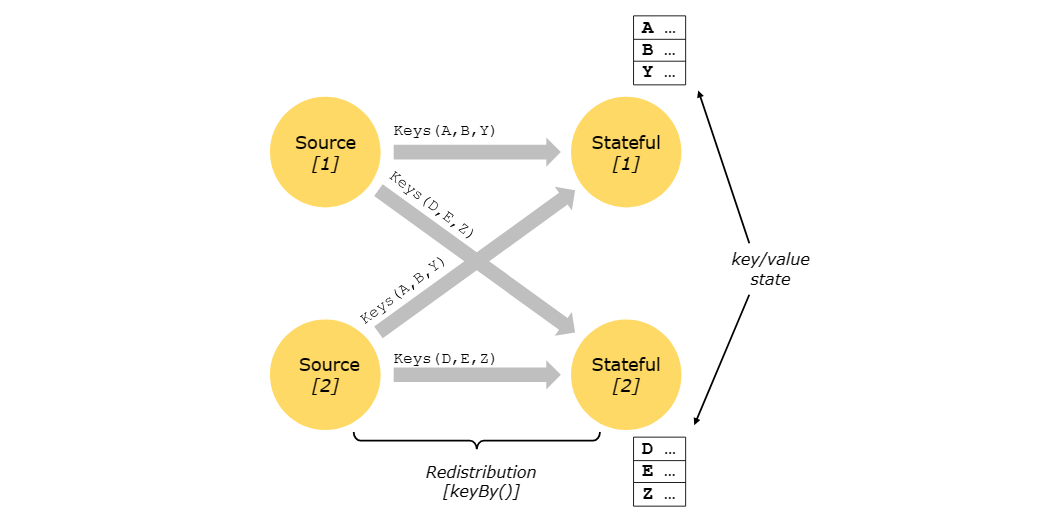
键控状态(Keyed State)进一步组织成所谓的键组(Key Groups)。 Key Groups 是 Flink 可以重新分配 Keyed State 的原子单元; 键组(Key Groups)的数量与定义的最大并行度完全相同。在执行期间,键控(Keyed)算子的每个并行实例都使用一个或多个键组的键。
State Persistence
Flink 使用流重放(stream replay)和检查点(checkpoint)的组合来实现容错。检查点(checkpoint)标记每个输入流中的特定点以及每个算子的相应状态。通过恢复算子的状态并从检查点(checkpoint) 重放(replay)记录,可以从检查点(checkpoint)恢复数据流,同时保持一致性(仅一次处理语义)。
检查点(checkpoint)间隔是一种权衡执行期间容错开销与恢复时间(需要重放(replay)的记录数)的方法。
容错机制不断地绘制分布式流数据流的快照(snapshots)。 对于小状态的流式应用程序来说,这些快照非常轻量,可以频繁绘制,而不会对性能产生太大影响。 流应用程序的状态存储在可配置的位置,通常存储在分布式文件系统中。
如果发生程序故障(由于机器、网络或软件故障),Flink 会停止, 然后根据最近的检查点(checkpoint)恢复Operators(算子)重启应用。输入流重置为状态快照点,作为重新启动的并行数据流的一部分进行处理的任何记录都保证不会影响之前的检查点(checkpoint)状态。
Checkpointing
Flink 容错机制的核心部分是绘制分布式数据流和算子状态的一致快照。 这些快照充当一致的检查点(checkpoint),系统在发生故障时可以回退到这些检查点(checkpoint)。 Flink 绘制这些快照的机制在"分布式数据流的轻量级异步快照"中进行了描述。它受到分布式快照标准 Chandy-Lamport 算法的启发,专门针对 Flink 的执行模型量身定制。
请记住,与检查点(checkpoint)有关的所有事情都可以异步完成。 检查点(checkpoint)屏障(checkpoint barrier)不会以锁定(lock)步骤运行,并且可以异步快照Operators(算子)状态。
Barriers
Flink 分布式快照的核心元素是stream barrier。 这些barrier被注入到数据流中,并作为数据流的一部分与record一起流动。 barrier永远不会超越record,它们严格按照顺序流动。barrier将数据流中的record分为进入当前快照的records和进入下一个快照的记录集records。 每个barrier都带有其record推送到其前面的快照的ID。 record不会中断数据的传输,因此非常轻。 来自不同快照的多个barrier可以同时存在于流中,这意味着各种快照可能同时发生。
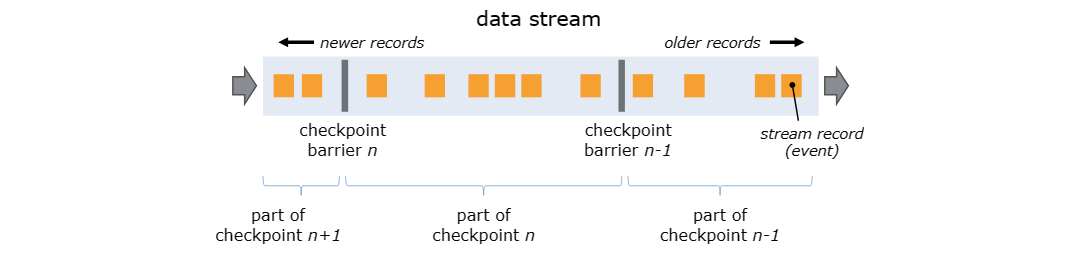
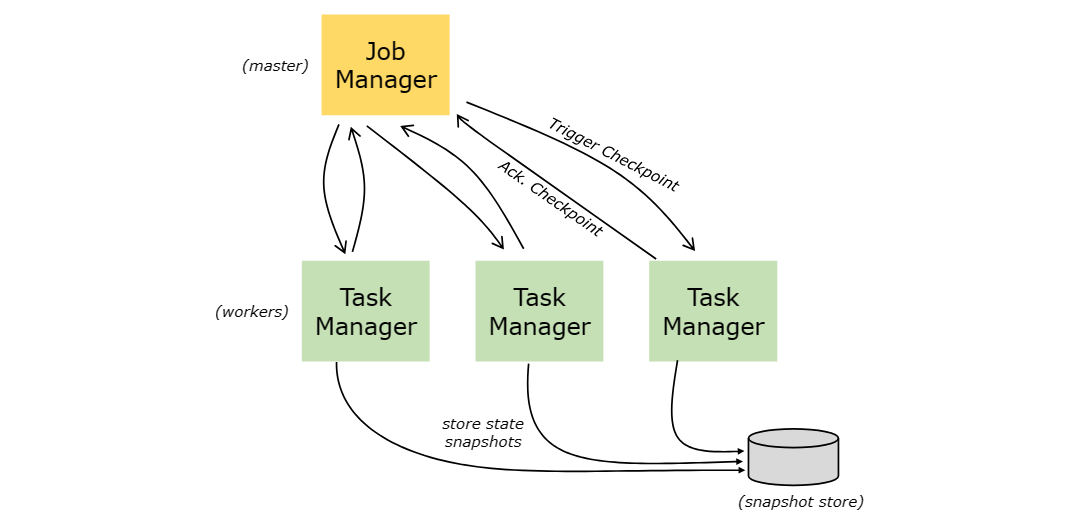
stream barrier被注入到流源处的并行数据流中。 快照 n 的barrier被注入的点(我们称之为 Sn)是源流中快照覆盖数据的位置。 例如,在 Apache Kafka 中,该位置将是分区中最后一条记录的偏移量。 这个位置 Sn 被报告给检查点(checkpoint)协调器(Flink 的 JobManager)。
然后barrier流向下游。 当中间Operators(算子)从其所有输入流接收到快照 n 的屏障时,它将向其所有输出流发出快照 n 的barrier。 一旦sink Operator(Stream DAG 的末端)从其所有输入流接收到barrier n,它就会向检查点(checkpoint)协调器确认该快照 n. 当所有接收器都确认快照后,该快照就被认为已完成。
一旦快照 n 完成,作业将不再向源请求 Sn 之前的record,因为此时这些record(及其后的record)将已经穿过整个数据流拓扑。

接收多个输入流的Operators(算子)需要在快照barrier上对齐输入流。 上图说明了这一点:
- 一旦Operators(算子)从输入流接收到快照barrier n,它就无法处理该流中的任何进一步record,直到它也从其他输入接收到barrier n。 否则,它将混合属于快照 n 的记录和属于快照 n+1 的记录。
- 一旦最后一个流接收到barrier n,Operators(算子)就会发出所有挂起的传出records,然后发出快照 n barrier本身。
- 它对状态进行快照并恢复处理来自所有输入流的records,在处理来自流的records之前处理来自输入缓冲区的记录。
- 最后,Operators(算子)将状态异步写入状态后端。
请注意,具有多个输入的所有算子以及在 shuffle 后消耗多个上游子任务的输出流的算子都需要对齐。
Snapshotting Operator State
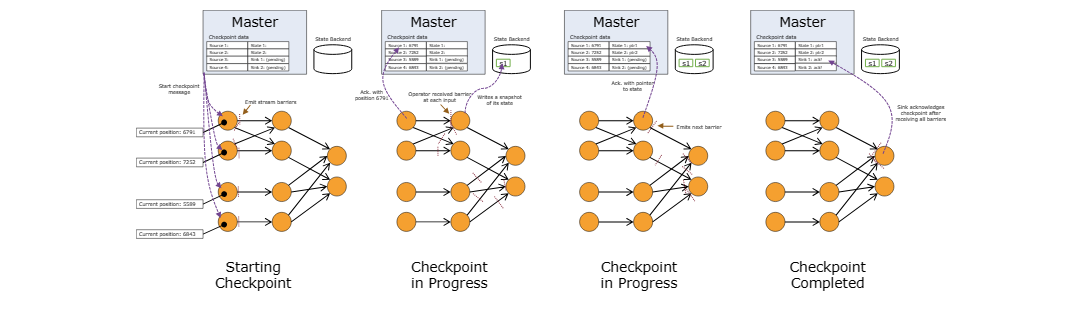
当算子包含任何形式的State时,该State也必须是快照的一部分。
算子在从输入流接收到所有快照barrier时以及在将barrier发送到输出流之前对其状态进行快照。 此时,所有来自barrier之前的records的状态更新都已经完成,并且没有依赖于应用barrier之后的记录的更新。 由于快照的状态可能很大,因此它存储在可配置的状态后端中。 默认情况下,存储在 JobManager 的内存,但对于生产使用,应配置分布式可靠存储(例如 HDFS)。 存储状态后,算子确认checkpoint,将快照barrier发送到输出流中,然后继续。
快照的结果包含:
- 对于每个并行流数据源,启动快照时流中的offset/position
- 对于每个算子,其内的state也会作为快照的一部分存储
Recovery
这种机制下的恢复很简单:发生故障时,Flink 选择最新完成的checkpoint k。然后,系统重新部署整个分布式数据流,并为每个算子提供作为checkpoint k的一部分快照的状态。source端从位置 Sk 开始读取流。 例如,在 Apache Kafka 中,这意味着告诉消费者从offset Sk 开始获取。
如果state是增量快照的,则算子从最新完整快照的state开始,然后对该state应用一系列增量快照更新。
Unaligned Checkpointing
检查点(checkpoint)也可以不对齐地执行。 基本思想是,只要流中的数据成为算子 state的一部分,checkpoint就可以取代所有流中的数据。
请注意,这种方法实际上更接近 Chandy-Lamport 算法,但 Flink 仍然在source中插入barrier以避免checkpoint协调器过载。
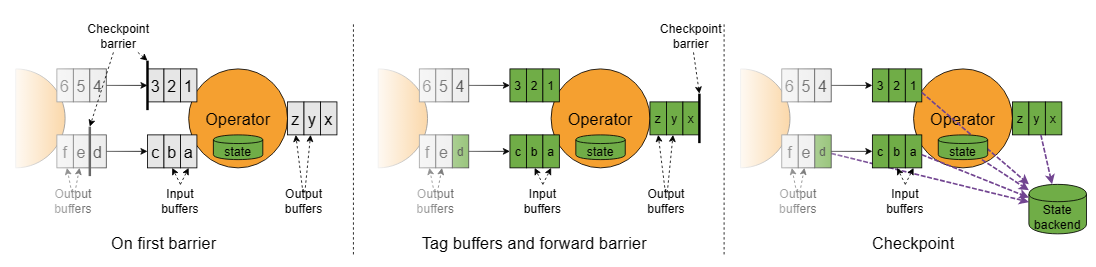
该图描述了算子如何处理未对齐的checkpoint barrier:
- 算子对存储在其输入缓冲区中的第一个barrier做出反应。
- 它通过将barrier添加到输出缓冲区的末尾,立即将barrier转发给下游算子。
- 算子将所有被超越的record标记为异步存储,并创建其自身state的快照。
因此,算子仅短暂停止输入处理以标记缓冲区、转发barrier并创建其他state的快照。
未对齐的checkpoint可确保barrier尽快到达sink端。 它特别适合具有至少一条缓慢移动数据路径的应用程序,其中对齐时间可能长达数小时。 然而,由于它增加了额外的 I/O 压力,因此当状态后端的 I/O 成为瓶颈时,它就无济于事了。
Unaligned Recovery
首先恢复算子运行中的数据,然后开始处理来自未对齐checkpoint的上游算子的任何数据。 除此之外,与Recovery的步骤是一致的
State Backends
存储键/值索引的具体数据结构取决于所选的状态后端。 一个状态后端将数据存储在内存中的哈希映射中,另一个状态后端使用 RocksDB 作为键/值存储。 除了定义保存状态的数据结构之外,状态后端还实现了获取键/值状态的时间点快照并将该快照存储为checkpoint的一部分的逻辑。 可以在不更改应用程序逻辑的情况下配置状态后端。
Savepoints
所有使用checkpoint的程序都可以从savepoint恢复执行。savepoint允许更新您的程序和 Flink 集群,而不会丢失任何状态。
savepoint是手动触发的checkpoint,它进行程序snapshot并将其写入状态后端。 为此,他们依赖定期checkpoint机制。
savepoint与checkpoint类似,不同之处在于它是由用户触发的,并且在新的checkpoint完成时不会自动过期。
Exactly Once vs. At Least Once
对齐步骤可能会增加stream程序的延迟。 通常,这种额外的延迟约为几毫秒,但我们已经看到一些异常值的延迟明显增加的情况。 对于所有记录都需要一致超低延迟(几毫秒)的应用程序,Flink 有一个开关可以在checkpoint期间跳过 流对齐。 一旦算子 看到来自每个输入的checkpoint barrier,仍然会绘制checkpoint快照。
当跳过对齐时,算子会继续处理所有输入,即使在checkpoint n 的一些checkpoint barrier到达之后也是如此。 这样,在获取checkpoint n 的状态快照之前,算子还会处理属于checkpoint n+1 的元素。在恢复时,这些record将作为重复项出现,因为它们都包含在checkpoint n 的状态快照中,并且将在checkpoint n 之后作为数据的一部分重放。
标签:状态,快照,barrier,必知,Flink,checkpoint,聊聊,算子 From: https://www.cnblogs.com/zhiyong-ITNote/p/17921445.html