前言 本文经过练习时长3年终于做出一个超好玩的真实世界Burst Super-Resolution数据集,数据集仍在持续采集,后续会坚持更新迭代。
本文转载自我爱计算机视觉
仅用于学术分享,若侵权请联系删除
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【CV技术指南】CV全栈指导班、基础入门班、论文指导班 全面上线!!

首先介绍一下我们的task—— Real-world Burst Super-Resolution 。尽管这几年底层视觉的超分辨率任务搞得如火如荼,但是大部分工作仍然是基于合成数据来做的(也就是给定高分辨率图像之后,经过bicubic/bilinear/...函数下采样获得对应的低分辨率图像)。
这样做的好处是,可以很容易get到训练数据;但是坏处也很明显,就是 合成数据将超分中的退化函数 (degradation model) 建模得过于理想化了,因此用合成数据训练出来的模型往往在面对真实世界场景的退化时会发生性能剧变 ,比如下图中的合成结果(更详细的对比可以参考子不语:Real-world Super-Resolution | 真实世界超分辨率)
 在合成数据上训练出的sota模型,泛化到真实场景时出现了一些崩坏
在合成数据上训练出的sota模型,泛化到真实场景时出现了一些崩坏
在很多其他工作中,也讨论了这种合成数据的泛化问题(比如做单帧real-world sr的LP-KPN[1]和CDC[2])。但是,即使在这种情况下, 基于完全真实的数据进行超分的工作也非常少 (这里暂时先不谈用随机noise/blur kernel建模degradation的工作),一个很大的原因就是 真实数据太难获取和处理了 。
无论是配对场景的拍摄,再到图像后期的处理、矫正、对齐,再到最后的成像,每一步都是深渊巨坑(而且超分数据面临着比常规同分辨率配对数据更加难解决的问题,比如畸变等,可以参考zoom to learn[3]等文章)。
与此同时,另一个值得关注的问题是, 单帧图像提供的信息总归是有限的 ,尤其是对超分这种要面临“无中生pixel”的任务。如果能在输入时提供更多的采样信息,让模型能够“见到”更多信息,那么预测pixel的过程将变得更加可靠合理。
举一个简单的例子,如果我们将 拍摄一个场景的过程简单地理解为一次离散化采样的过程,那么利用单帧离散信息进行原始连续图像重建和利用多帧信息重建的对比大概可以用下图来表示 :

多帧信息的输入,意味着对同一个场景进行了多次采样。在重建原场景的时候,采样点越多,采样率越高,意味着对原始信息的恢复更准确
这种设想在很多年前就已经提出了,但当时囿于技术的桎梏,很难做到同一个场景的连续多次采样。但随着硬件设备的提升,目前,几乎所有的成像设备厂商都可以做到 在按下快门的一瞬间,让设备在底层捕捉到多张相隔不过毫秒级别的照片 。
这也意味着我们不再局限于单帧图像,而是拥有了一系列同一场景的数据可以使用(也就是burst data,即连拍数据),Burst photography也慢慢进入了大众视野[4][5]。
尽管Burst super-resolution工作有很大的发展前景,但是 依然被前文所提到的真实数据问题所困扰 。其实在2021年,就已经有工作提出了一版真实的burst数据集[6],但是在使用过程中,却发现有很多难以弥补的问题:
1)严重的不对齐问题: 如下图(a)所示,这种低分辨率input和高分辨率ground-truth之间的不对齐,会直接误导模型的学习,更不要提在对应位置生成准确的pixel了。
2)跨设备的domain gap: 如下图(b)所示,由于低分辨率input和高分辨率ground-truth是采用不同设备拍摄(手机+相机),因此在成像上出现了跨设备分布的问题,也就是手机和相机之间不同的成像方式导致了最终的LR和HR出现了很大的颜色差异。对于pixel级别的任务来说,也同样是一个容易误导模型的问题。
 此前的burst数据集存在的问题
此前的burst数据集存在的问题
3)评测的不规范: 由于上述的两个问题,导致了模型根据低分辨率input直接生成的SR结果会和真正的ground-truth之间出现空间不对齐、颜色不匹配等问题,所以此数据集对应的评测方法不得不先将SR结果和ground-truth之间做一个空间和颜色矫正,才能计算PSNR,如下图所示。这显然和我们常规能接受的评测方式不太在一个次元里。
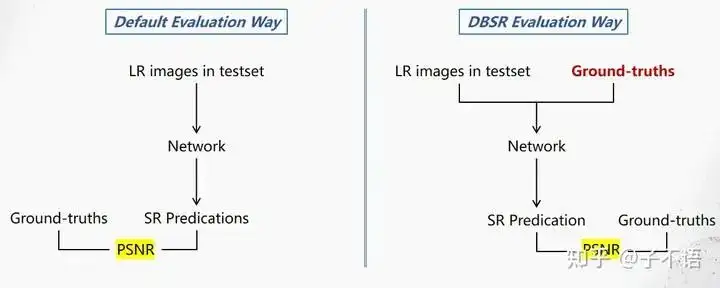 左边是常规的测试流程;右边是此前burst数据集对应的测评流程
左边是常规的测试流程;右边是此前burst数据集对应的测评流程
考虑到以上种种问题,尽管这个数据集为领域做出了很大的贡献,我们却更加深了做一个Real-world Burst Super-Resolution数据集的想法。目前,我们所提出的 RealBSR数据集包含RAW和RGB两个版本 ,总体情况可以参考下图:
 RealBSR数据集的采集方式和规模
RealBSR数据集的采集方式和规模
 RealBSR数据集包含室内、室外场景,囊括植物、建筑等不同纹理
RealBSR数据集包含室内、室外场景,囊括植物、建筑等不同纹理
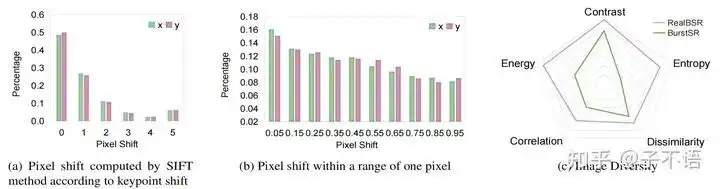 RealBSR数据集基本的statistics分析
RealBSR数据集基本的statistics分析
除了提出RealBSR数据集之外,我们同时思考了现有burst sr方法中存在的问题。目前 burst sr的整体范式 可以概括为:输入-->对齐-->融合-->重建-->输出。
其中,在融合模块中,通常的做法是 在输入的多帧图像中选定一帧(通常为第一帧)作为参考帧,然后计算输入序列中的其他帧和参考帧之间的相似度。如果相似度高,则对应的该帧将被赋予更高的权重;否则则被赋予较低的权重 。这样的做法可以有效避免由于运动、噪声等带来的伪影和模糊,但是也会让多帧中的很多信息被抹掉。
以下图为例,假设第一帧(1-Frame)为参考帧,对于Pixel-A,如果按照传统的融合方式(Vanilla Affinity Fusion),最终的重建结果中将包含3帧中的信息;但是对于Pixel-B,如果仍然按照传统的融合方式,将会发现来自其他帧的重要信息将被忽略(原因就是这些细节在参考帧中没有出现。但参考帧也不过是一次离散采样,很难包括一个场景中所有的重要信息)。
而我们希望的有效融合方式是右侧的Federated Affinity Fusion,能够 将参考帧忽略的重要信息同样融合到最终的结果 中。
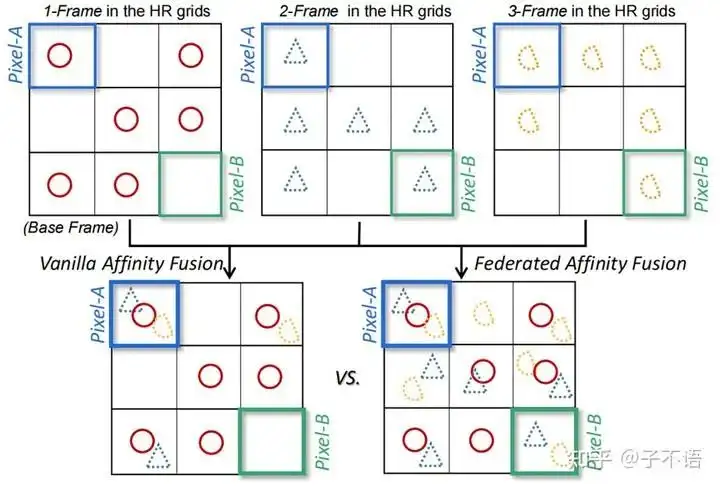 Vanilla Affinity Fusion即传统融合方式;Federated Affinity Fusion为本文提出的融合方式
Vanilla Affinity Fusion即传统融合方式;Federated Affinity Fusion为本文提出的融合方式
另一种从信号的角度理解我们的融合方式(Federated Affinity Fusion,FAF)和传统融合方式(Vanilla Affinity Fusion, VAF)的示意图如下所示:
 从信号的角度对比传统融合和我们的融合方式
从信号的角度对比传统融合和我们的融合方式
想要实现这样的效果的处理方式也非常简单。就是在传统融合过程中计算每一帧和参考帧之间的similarity之后,再在similarity/affinity之间计算它们的difference,以此表征帧间的差异信息。如下图中的Federated Affinity Fusion部分所示(具体公式可以参考论文Section4.3):
 我们所提出的FBANet架构。其中Federated Affinity Fusion是主要创新点
我们所提出的FBANet架构。其中Federated Affinity Fusion是主要创新点
最终,我们对比了提出的FBANet模型和其他SOTA模型(包括单帧/多帧/video)的定量和定性效果,具体结果如下。可以发现, 无论是在PSNR还是可视化效果上,FBANet都能够显著超越SOTA模型 。
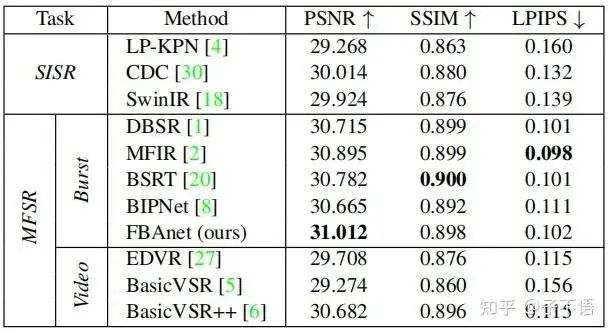 RealBSR数据集上的性能对比。所有模型都为RealBSR数据集from scratch训练
RealBSR数据集上的性能对比。所有模型都为RealBSR数据集from scratch训练
 FBANet vs. SOTA models
FBANet vs. SOTA models
参考文献
- ^Cai, Jianrui, Hui Zeng, Hongwei Yong, Zisheng Cao, and Lei Zhang. "Toward real-world single image super-resolution: A new benchmark and a new model." In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 3086-3095. 2019.
- ^Wei, Pengxu, Ziwei Xie, Hannan Lu, Zongyuan Zhan, Qixiang Ye, Wangmeng Zuo, and Liang Lin. "Component divide-and-conquer for real-world image super-resolution." In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part VIII 16, pp. 101-117. Springer International Publishing, 2020.
- ^Zhang, Xuaner, Qifeng Chen, Ren Ng, and Vladlen Koltun. "Zoom to learn, learn to zoom." In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 3762-3770. 2019.
- ^Wronski, Bartlomiej, Ignacio Garcia-Dorado, Manfred Ernst, Damien Kelly, Michael Krainin, Chia-Kai Liang, Marc Levoy, and Peyman Milanfar. "Handheld multi-frame super-resolution." ACM Transactions on Graphics (ToG) 38, no. 4 (2019): 1-18.
- ^Hasinoff, Samuel W., Dillon Sharlet, Ryan Geiss, Andrew Adams, Jonathan T. Barron, Florian Kainz, Jiawen Chen, and Marc Levoy. "Burst photography for high dynamic range and low-light imaging on mobile cameras." ACM Transactions on Graphics (ToG) 35, no. 6 (2016): 1-12.
- ^Bhat, Goutam, Martin Danelljan, Luc Van Gool, and Radu Timofte. "Deep burst super-resolution." In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 9209-9218. 2021.
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:470899183。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
LSKA注意力 | 重新思考和设计大卷积核注意力,性能优于ConvNeXt、SWin、RepLKNet以及VAN
CVPR 2023 | TinyMIM:微软亚洲研究院用知识蒸馏改进小型ViT
ICCV2023|涨点神器!目标检测蒸馏学习新方法,浙大、海康威视等提出
ICCV 2023 Oral | 突破性图像融合与分割研究:全时多模态基准与多交互特征学习
HDRUNet | 深圳先进院董超团队提出带降噪与反量化功能的单帧HDR重建算法
南科大提出ORCTrack | 解决DeepSORT等跟踪方法的遮挡问题,即插即用真的很香
1800亿参数,世界顶级开源大模型Falcon官宣!碾压LLaMA 2,性能直逼GPT-4
SAM-Med2D:打破自然图像与医学图像的领域鸿沟,医疗版 SAM 开源了!
GhostSR|针对图像超分的特征冗余,华为诺亚&北大联合提出GhostSR
Meta推出像素级动作追踪模型,简易版在线可玩 | GitHub 1.4K星
CSUNet | 完美缝合Transformer和CNN,性能达到UNet家族的巅峰!
AI最全资料汇总 | 基础入门、技术前沿、工业应用、部署框架、实战教程学习
标签:FBANet,数据,模型,超分,融合,Fusion,Affinity,ICCV2023,CV From: https://www.cnblogs.com/wxkang/p/17810433.html