第四章学习笔记
第四章 并发编程
- 本章论述了并发编程,介绍了并行计算的概念,并指出了并行计算的重要性;比较了顺序算法与并行算法,以及并行性与并发性;解释了线程的原理及其相对于进程的优势;介绍了Pthread中的线程操作,包括线程管理函数,互斥量、连接、条件变量和屏障等线程同步工具;解释了死锁问题,并说明了如何防止并发程序中的死锁问题;讨论了信号量,并论证了它们相对于条件变量的优点;还解释了支持Linux中线程的独特方式,让我们更加深入地了解多任务处理、线程同步和并发编程的原理及方法。
1.并行计算导论
- 在早期,大多数计算机只有一个处理组件,称为处理器或中央处理器(CPU)。受这种硬件条件的限制,计算机程序通常是为串行计算编写的.
- 要求解某个问题,先要设计一种算法,描述如何一步步地解决问题,然后用计算机程序以串行指令流的形式实现该算法。在只有一个CPU的情况下,每次只能按顺序执行某算法的一个指令和步骤。但是,基于分治原则(如二叉树查找和快速排序等)的算法经常表现出高度的并行性,可通过使用并行或并发执行来提高计算速度。并行计算是一种计算方案,它尝试使用多个执行并行算法的处理器更快速地解决问题。
1). 顺序算法与并行算法
- 顺序算法
begin
step_1
step_2
···
step_n
end
- 并行算法
cobegin
task_1
task_2
···
task_n
coend
- 顺序算法begin-end代码块中的顺序算法可能包含多个步骤。所有步骤都是通过单个任务依次执行的,每次执行一个步骤。当所有步骤执行完成时,算法结束。相反,并行算法使用cobegin-coend代码块来指定并行算法的独立任务。在cobegin-coend块中,所有任务都是并行执行的。紧接着cobegin-coend代码块的下一个步骤将只在所有这些任务完成之后执行。
2). 并行性与并发性
- 通常,并行算法只识别可并行执行的任务,但是它没有规定如何将任务映射到处理组件。在理想情况下,并行算法中的所有任务都应该同时实时执行。然而,真正的并行执行只能在有多个处理组件的系统中实现,比如多处理器或多核系统。在单 CPU 系统中—次只能执行一个任务。在这种情况下,不同的任务只能并发执行,即在逻辑上并行执行。在单CPU 系统中,并发性是通过多任务处理来实现的。
2.线程
1). 线程的原理
- 线程是某进程同一地址空间上的独立执行单元。创建某个进程就是在一个唯一地址空间创建一个主线程。当某进程开始时,就会执行该进程的主线程。如果只有一个主线程,那么进程和线程实际上并没有区别。但是,主线程可能会创建其他线程。每个线程又可以创建更多的线程等。某进程的所有线程都在该进程的相同地址空间中执行,但每个线程都是一个独立的执行单元。
- 在线程模型中,如果一个线程被挂起,其他线程可以继续执行。除了共享共同的地址空间之外,线程还共享进程的许多其他资源,如用户id、打开的文件描述符和信号等。
2). 线程的优点
- 线程创建和切换速度更快
- 线程的响应速度更快
- 线程更适合并行计算
3). 线程的缺点
- 由于地址空间共享,线程需要来自用户的明确同步。
- 许多库函数可能对线程不安全,例如传统 strtok()函数将一个字符串分成一连串令牌。通常,任何使用全局变量或依赖于静态内存内容的函数,线程都不安全。为了使库函数适应线程环境,还需要做大量的工作。
- 在单CPU系统上,使用线程解决问题实际上要比使用顺序程序慢,这是由在运行时创建线程和切换上下文的系统开销造成的。
3.线程操作
- 线程的执行轨迹与进程类似。线程可在内核模式或用户模式下执行。
- 在用户模式下,线程在进程的相同地址空间中执行,但每个线程都有自己的执行堆栈。线程是独立的执行单元,可根据操作系统内核的调度策略,对内核进行系统调用,变为挂起、激活以继续执行等。
4.进程管理函数
1). 创建线程
- 使用pthread_create()函数创建线程
int pthread_create (pthread_t *pthread_id, pthread_attr_t *attr,
void *(*func)(void *), void *arg);
- pthread_id是指向pthread_t类型变量的指针。它会被操作系统内核分配的唯一线程ID填充。在POSIX中,pthread_t是一种不透明的类型。程序员应该不知道不透明对象的内容,因为它可能取决于实现情况。线程可通过pthread_self()函数获得自己的ID。在 Linux 中,pthread_t类型被定义为无符号长整型,因此线程ID可以打印为%lu。
- attr是指向另一种不透明数据类型的指针,它指定线程属性,下面将对此进行更详细的说明。
- func是要执行的新线程函数的入口地址。 arg是指向线程函数参数的指针,可写为:void *func(void *arg)
- attr参数
- (1)定义一个pthread属性变量pthread_attr_t attr。
- (2)用pthread_attr_init (&attr)初始化属性变量。
- (3)设置属性变量并在pthread_create()调用中使用。
- (4)必要时,通过pthread_attr_destroy (&attr)释放attr资源。
2). 线程ID
- 线程ID是一种不透明的数据类型,取决于实现情况。因此,不应该直接比较线程ID。如果需要,可以使用pthread_equal()函数对它们进行比较。
int pthread_equal (pthread_t t1, pthread_t t2);
如果是不同的线程,则返回0,否则返回非0。
3). 线程终止
线程函数结束后,线程即终止。或者,线程可以调用函数
int pthread_exit (void *status);
进行显式终止,其中状态是线程的退出状态。通常,0退出值表示正常终止,非0值表示异常终止。
4). 线程连接
一个线程可以等待另一个线程的终止,通过
int pthread_join (pthread_t thread, void **status ptr);
终止线程的退出状态以status_ptr返回
5.线程同步
1).互斥量
最简单的同步工具是锁,它允许执行实体仅在有锁的情况下才能继续执行。在Pthread中,锁被称为互斥量。在使用之前必须对他们进行初始化。
- 静态方法:
pthread_mutex_t m = PTHREAD_MUTEX_INITIALIZER
定义互斥量m,并使用默认属性对其进行初始化。
- 动态方法:使用
pthread_mutex_init()函数,可通过attr参数设置互斥属性。
pthread_mutex_init(pthread_mutex_t m,pthread_mutexattr_t,attr);
通常attr参数可以设置位NULL,作为默认属性。
初始化完成后,线程可以通过以下函数使用互斥量。

2)死锁预防
互斥量使用封锁协议。如果某线程不能获取互斥量,就会被阻塞,等待互斥量解锁后再继续。在任何封锁协议中,误用加锁可能会产生一些问题。最常见和突出的问题是死锁。
有多种方法可以解决可能的死锁问题,其中包括死锁预防、死锁规避、死锁检测和恢复等。
在实际系统中,唯一可行的方法是死锁预防,试图在设计并行算法时防止死锁的发生。一种简单的死锁预防方法是对互斥量进行排序,并确保每个线程只在一个方向请求互斥量,这样请求序列中就不会有循环。
条件加锁和退避预防死锁

3).条件变量
作为锁,互斥量仅用于确保线程只能互斥地访问临界区中的共享数据对象。条件变量提供了一种线程协作的方法。在Pthread中,使用类型pthread_cond_t来声明条件变量,而且必须在使用前进行初始化。
- 静态方法
pthread_cond_t con = PTHREAD_COND_INITALLIZER;
- 动态方法
使用pthread_cond_init()函数,通过attr参数设置条件变量。
在互斥量的临界区中,线程可通过以下函数使用条件变量来相互协作。
pthread_cond_wait(conditlon,mutex):该函数会阻塞调用线程,直到发出指定条件的信号。当互斥量被加锁时、应调用该例程。它会在线程等待时自动释放互斥量。互斥量将在接收到信号并唤醒阻塞的线程后自动锁定。
pthread cond signal(condition);该函数用来发出信号,即唤醒正在等待条件变量的线程或解除阻塞。它应在互斥量被加锁后调用,而且必须解锁互斥量才能完成pthread_cond_wait ()。
pthread cond broadcast(condition)∶该函数会解除被阻塞在条件变量上的所有线程阻塞。所有未阻塞的线程将争用同一个互斥量来访问条件变量。它们的执行顺序取决于线程调度。
4).信号量
信号量和条件变量之间的主要区别是,前者包含一个计数器,可操作计数器,测试计数器值以做出决策等,所有这些都是临界区的原子操作或基本操作,而后者需要一个特定的互斥量来执行临界区。在 Pthreads 中,互斥量严格用于封锁。而条件变量可用于线程协作。相反,可以把使用初始值1计算信号量当作锁。带有其他初始值的信号量可用于协作。因此,信号量比条件变量更通用、更灵活。下面的示例说明了信号量相对于条件变量的优势。
信号量是进程同步的一般机制。(计数)信号量是一种数据结构
struct sem{
int value;
struct process *queue
}s;
最有名的信号量操作时P和V,定义见下文:

5).屏障
线程连接操作允许某线程(通常是主线程)等待其他线程终止。在等待的所有线程都终止后,主线程可创建新线程来继续执行并行程序的其余部分。创建新线程需要系统开销。在某些情况下,保持线程活动会更好,但应要求它们在所有线程都达到指定同步点之前不能继续活动。
生产者—消费者问题
我们将使用线程和条件变量来实现一个简化版的生产者-消费者问题,也称有限缓冲问题。生产者-消费者问题通常将进程定义为执行实体,可看作当前上下文中的线程。下面是该问题的定义。
一系列生产者和消费者进程共享数量有限的缓冲区。每个缓冲区每次有一个特定的项目。最开始,所有缓冲区都是空的。当一个生产者将一个项目放人一个空缓冲区时,该缓冲区就会变满。当一个消费者从一个满的缓冲区中获取一个项目时,该缓冲区就会变空。如果没有空缓冲区,生产者必须等待。同样,如果没有满缓冲区,则消费者必须等待。此外,当等待事件发生时、必须允许等待进程继续。
二、知识点挑战
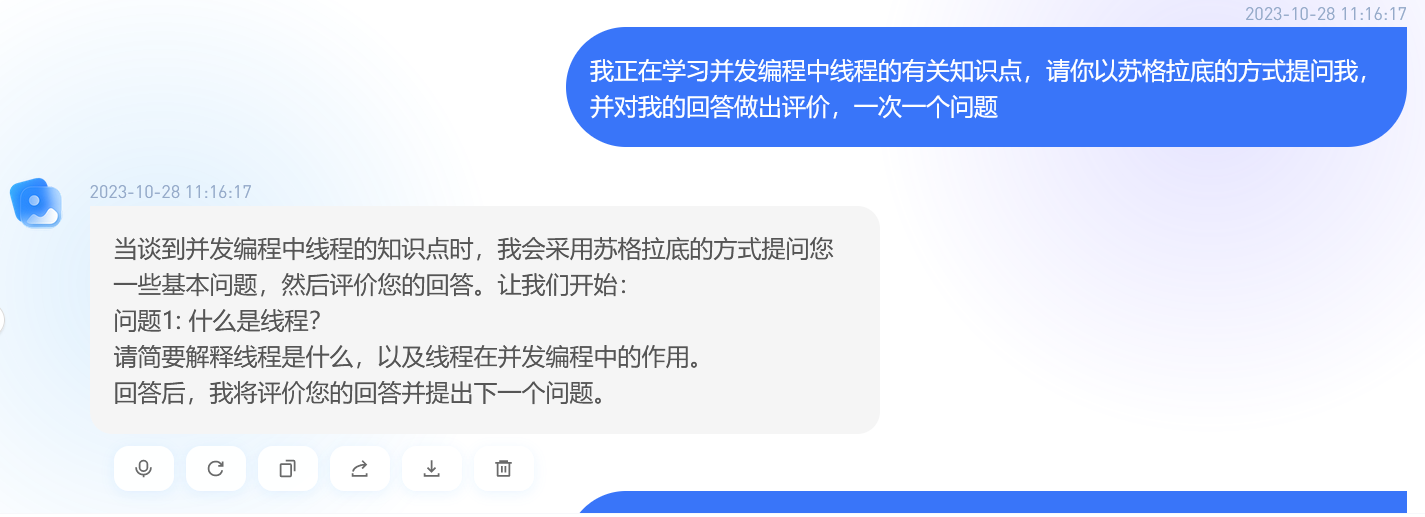
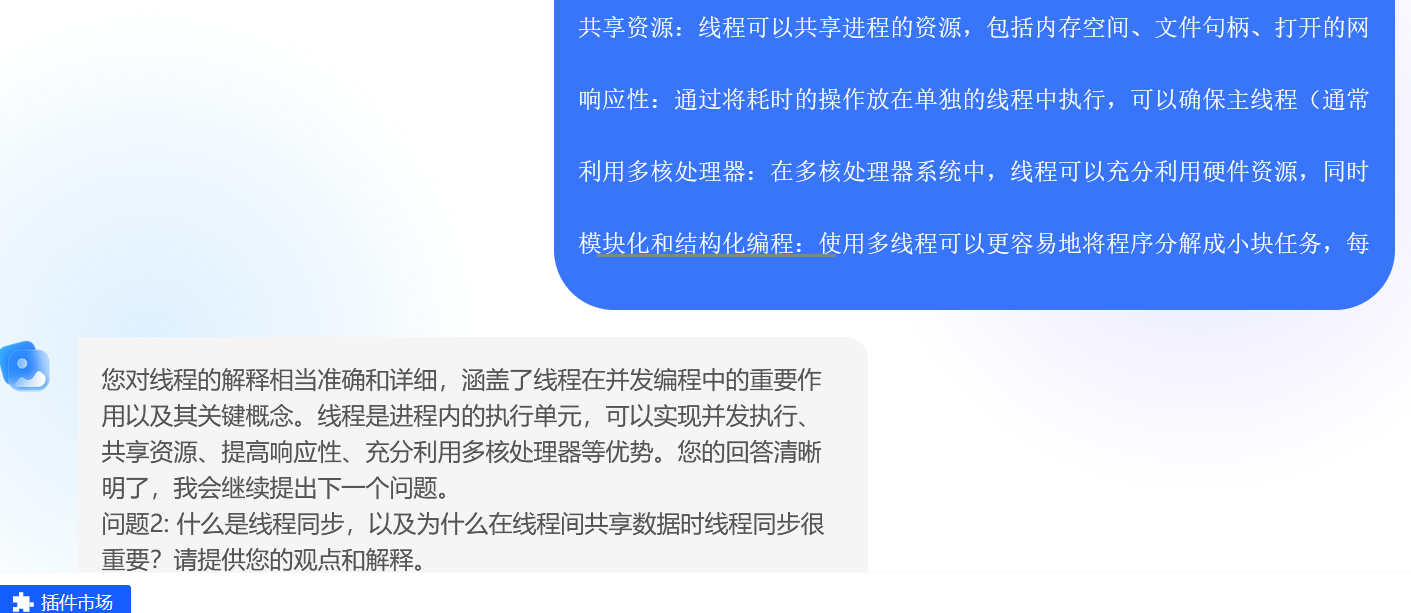
1.并发编程中线程内容


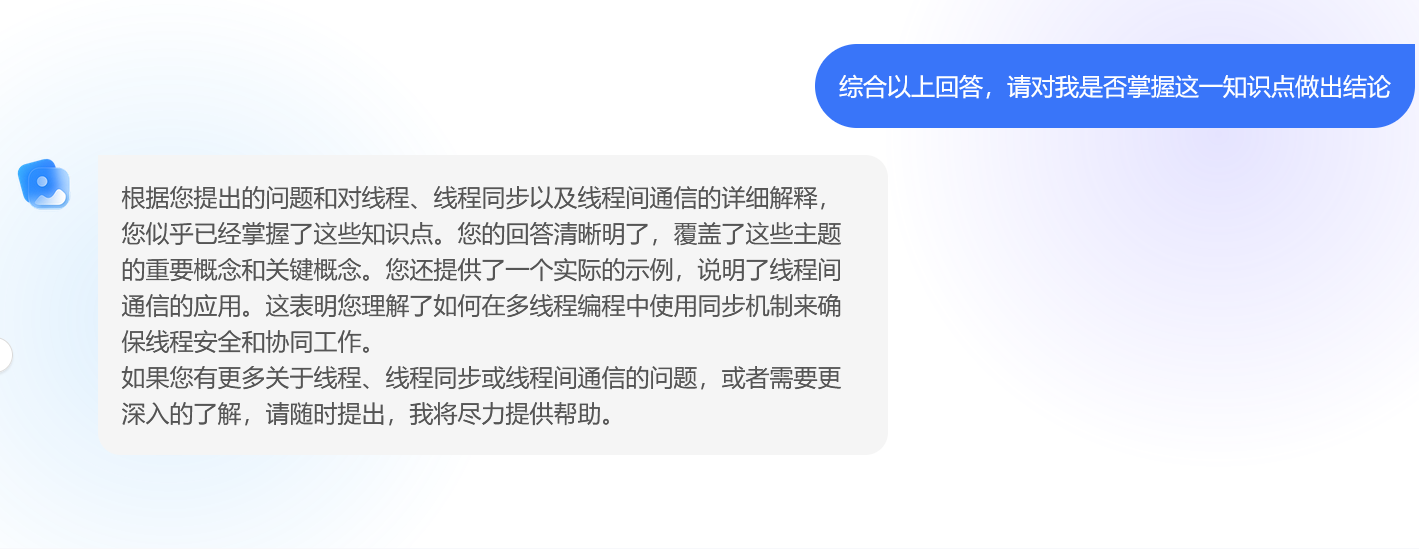
2.线程同步