GPU 虚拟化 [一]
 兰新宇
talk is cheap
兰新宇
talk is cheap
对于 GPU 这样的高速 PCIe 设备,虽然也可以借助 virtio 的方式来实现 guest VM 对 GPU 资源的共享,但因为需要 hypervisor 参与 emulation,效率不高。性能更佳的方案是将物理 GPU 以整体或部分的形式,“透传”给 VM。
独吞
先来说整体 pass-through 的方案,也就是将一整个物理 GPU 完全划给一个 guest VM 使用。这是图啥呢,这还能叫虚拟化么?
有种情况是一台机器有多个物理 GPU,也运行了多个 VM,分一分正好,互不影响。即便一台机器只有一个物理 GPU,整体 pass-through 也可以带来如下好处:
一是在 VM 里面做 GPU 驱动的一些实验,这样即便 driver 不小心把内核弄 crash 了,那也只是导致虚拟机 hang 住,重启 VM 可比重启物理机快捷多了。
二是可以测试 GPU 卡 hotplug 时对应驱动的加载情况,这比在物理机上真正的“热插拔”也方便多了。那怎么对 VM 实施设备的 hotplug 呢?
以 libvirt 管理的 VM 为例,编辑下面这样一段描述设备的 xml 文件(假设命名为 "gpu-pt.xml"):
<hostdev mode='subsystem' type='pci' managed='yes'>
<source>
<address domain='0x0000' bus='0x02' slot='0x00' function='0x0'/>
</source>
</hostdev> 然后把该设备动态地 assign 给正在运行的 VM:
virsh attach-device --file gpu-pt.xml --live <gvm-name>
接下来在 VM 里 "lspci" 就可以看到这张 GPU 卡了。
上述 xml 文件里的 "bus", "slot", "function" 基本就等同于 PCIe 设备的 BDF 号,而 "managed=yes" 表示 VM 启动时,libvirt 会自动将这张 GPU 卡与 host driver 解绑,然后绑定 vfio-pci 驱动。
有意思的是,虽然此时这张 GPU 卡已经 assign 给 VM 了,但在 host 上还是可以看到它,但是 host 不能再使用它了。如果想切换给 host 使用(交回 GPU 卡的控制权),需要先 virsh detach 移除这个设备,然后 unbind 掉 之前绑定的 vfio-pci 驱动。
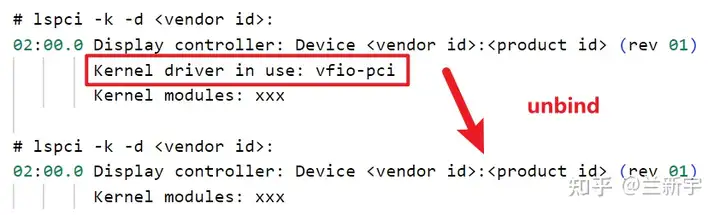
这里 libvirt/qemu 所使用的 vfio-pci 驱动【注-1】,除了可以像早期的 pci-stub 那样作为 dummy driver 阻止 host driver 占用设备,还可以借助 IOMMU Group 来实现设备的隔离(需使能 IOMMU 并开启 pt 模式【注-2】,以使用 VT-d 的 Intel CPU 为例,在内核启动参数中加入"intel_iommu=on iommu=pt")。
IOMMU Group 是将设备分配给 VM 的最小单位,即一个 Group 内的设备必须 pass-through 给同一个 VM。比如下图红框部分(或使用 "find /sys/kernel/iommu_groups/ -type l" 命令):

分享
再来说说部分 pass-through 的方案。
如果一个 GPU 本身支持 SR-IOV 的话,那么现实中更常用的方式是利用 PCIe 提供的 SR-IOV 特性,从硬件上将物理 GPU 资源进行一定的划分,形成 PF (Physical Function) 和 VF (Virtual Function)。
一张 GPU 卡内部包含多个 engine,比如用于地址翻译的 GpuMmu,用于数据拷贝的 DMA,以及一些视频/图形的编解码 IP。假设 DMA 引擎包含 8 个 channels,GpuMmu 包含 4 个地址转换单元,那么可以生成 4 个 VF,一个 VF 包含 1 个 MMU 单元和 2 个 DMA channel。
VF 可视作一个独立的设备,在 PCIe 里,有一种特性叫做 FLR (Function Level Reset),就是可以在 VF 的级别做复位。VF 除了能透传给 VM 使用,也可供 host 上的 container 使用(对应为 Application)。
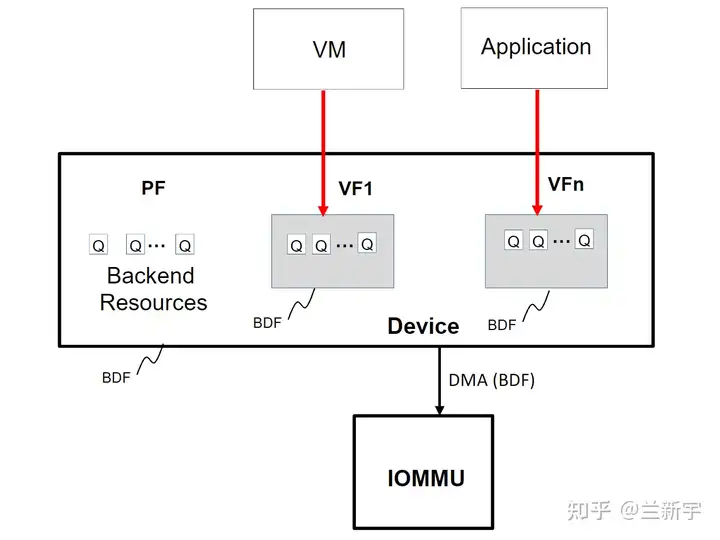
为什么要叫 function 呢?这可能和 BDF 的命名有关,同一物理设备划分出的不同 VF 共享相同的 Bus 和 Deivce 编号,但拥有不同的 Function 编号。
SR-IOV 这种固定的划分方式,灵活性似乎差了点,有没有更 flexible 的方案呢?请看下文分解。
注-1:需要系统中包含 vfio-pci.ko 驱动文件,如果在 "/lib/modules" 路径下找不到,可以看下是不是已经被编译进内核了,一种方法是查看内核配置的 config 文件,另一种是查看 "modules.builtin" 文件。
注-2:IOMMU 概况起来主要有两个功能:translation 和 isolation。IOMMU 的 pt 模式侧重于 isolation(比如 IOMMU group),而 bypass 了 DMA Remapping 功能(但保留了 Interrupt Remapping)。
参考:
- RHEL-9 Managing GPU devices in virtual machines
- https://pve.proxmox.com/wiki/PCI_Passthrough
- IOMMU Groups - What You Need to Consider - Heiko's Blog - VFIO
原创文章,转载请注明出处。
标签:VF,虚拟化,实现,IOMMU,VM,host,GPU,设备 From: https://www.cnblogs.com/wcxia1985/p/17782575.html