MVCC机制是什么
MVCC,即**Multi-Version Concurrency Control **(多版本并发控制)。它是一种并发控制的方法,一般在数据库管理系统中,实现对数据库的并发访问,在编程语言中实现事务内存。
个人理解
- MySQL 的 InnoDB 存储引擎支持事务。
- 事务的四大特性:A 原子性、C 一致性、I 隔离性、D 持久性
- 原子性:事务是一组sql,这组sql要么全部执行成功,要么全都不执行。
- 而事务的并发会带来并发问题,脏读、不可重复读、幻读。
- 为了解决事务并发问题,MySQL提供了不同的隔离级别,来控制并发事务之间的隔离程度。不同的隔离级别在并发性能和数据一致性方面具有不同的权衡。例如,较低的隔离级别可以提高并发性能,但可能会导致数据一致性问题;而较高的隔离级别可以保证数据一致性,但可能会降低并发性能。
- 四种隔离级别:读未提交 RU、读已提交 RC、可重复读 RR、串行化 S
- 现在回答MVCC 机制是什么,MVCC 机制是为了控制事务并发产生的并发问题的一种机制,并且根据隔离级别不同,所表现出来的机制是不同的。
MVCC机制解决了什么问题
MVCC 机制,
在RC 级别下,解决了不可重复读的问题。
在RR 级别下,解决了不可重复读的问题。
两种隔离级别下的解决思路不同。
MVCC 的实现
MVCC 通过undolog日志和ReadView实现。
隐藏字段
InnoDB 存储引擎的每一行都有两个隐藏字段trx_id、roll_pointer,如果表中没有主键索引或者唯一索引列,那么还会增加一个row_id字段。
| 列名 | 是否必须 | 描述 |
|---|---|---|
trx_id |
是 | 事务 id,创建事务时生成 |
roll_pointer |
是 | 回滚点,指向回滚段的undo日志 |
row_id |
否 | 单调递增的行ID,不是必需的,占用6个字节. |
- 有数字主键索引时,值为主键索引列
- 没有数字主键索引,但是有一列数字唯一索引,值为数字唯一索引列
- 没有数字主键索引,并且有两列数字唯一索引,按照数字唯一索引的定义顺序,值为先定义的那一列
- 没有数字主键索引,并且没有数字唯一索引,值不可被查询到
select _rowid from aaa;
|
undolog 日志
undo log,回滚日志,用于记录数据被修改前的信息。在表记录修改之前,会先把数据拷贝到undo log里,如果事务回滚,即可以通过undo log来还原数据。
可以这样认为,当delete一条记录时,undo log 中会记录一条对应的insert记录,当update一条记录时,它记录一条对应相反的update记录。
**undolog **的作用 :
- 事务回滚:保证原子性和一致性
- 用于MVCC 的快照读
版本链
当多个事务,对同一条记录进行修改时,会产生不同的版本,这些不同的版本通过隐藏字段roll_pointer连接。
主体是记录,事务并发时,每一条记录都是一个链表的形式。

以一个流程讲解版本链的生成流程
- 版本链的头结点是最新的值
- 最新的值存在数据库中
- 除最新的值之外的值,存在undolog日志中
**update user set name ="李四" where id=1**
- 首先获得一个事务ID=100,
**trx_id = 102**(事务开始时,生成事务id) - 把user表修改前的数据,拷贝到undo log(更新undolog日志)
- 修改user表中,id=1的数据,名字改为李四 (修改数据表中的数据)
- 把修改后的数据事务Id=
**102**改成当前事务版本号,并把roll_pointer指向undo log数据地址。

快照读和当前读
快照读:读取的是记录数据的可见版本(有旧的版本)。不加锁,普通的select语句都是快照读
**select** * **from** core_user **where** id > 2;
当前读:读取的是记录数据的最新版本,显式加锁的都是当前读
select * from core_user where id > 2 for update; 排他锁 / 写锁
select * from account where id>2 lock in share mode; 共享锁 / 读锁
ReadView
ReadView 是什么?
在innodb 存储引擎中,每个SQL语句执行前都会得到一个Read View。它就是事务执行SQL语句时,产生的读视图。
主要用来做可见性判断,判断当前事务可以看到的哪个版本的数据
Readview 的几个重要字段
每个SQL语句执行前都会得到一个Read View。
creator_trx_id:创建当前read view的事务IDm_ids:当前系统中那些活跃(未提交)的读写事务ID, 它数据结构为一个List。min_limit_id:表示在生成ReadView时,当前系统中活跃的读写事务中最小的事务id,即m_ids中的最小值。max_limit_id:表示生成ReadView时,系统中应该分配给下一个事务的id值。
数据可见性算法:
可见性算法看到的数据就是这个SQL语句能看到的数据行的版本。(在多个版本的数据中,根据事务IDtrx_id,选出适合当前SQL语句的数据行)。
通过这四个数据和版本链上的数据作对比。(遍历链表)
当执行SQL的时候会生成事务ID,并且同时生成ReadView。
- 当
trx_id < min_limit_id时,表明修改该数据行的事务提交发生在SQL查询之前,所以该行数据可以被SQL查询出来 - 当
trx_id >= max_limit_id时,表明修改该数据行的事务发生在SQL查询之后,所以该行数据不能被SQL查询出来 - 当
min_limit_id <= trx_id < max_limit_id时,分三种情况讨论- 如果
m_ids包含trx_id,表明修改该数据行的事务还未提交,- 如果
trx_id = creator_trx_id时,表明修改该数据行的事务就是当前的SQL的事务,所以可以看到该数据行 - 如果
trx_id != creator_trx_id时,表明修改该数据行的事务不是当前的SQL的事务,所以不能看到该数据行
- 如果
- 如果
m_ids不包含trx_id,表明修改该数据行的事务已经被提交了,所以可以看到该数据行
- 如果
MVCC的执行流程
MVCC 查询一条记录(SQL)的大致流程
- 获取事务自己的版本号,即事务ID
- 获取Read View (在RC隔离级别下,存在)
- 查询得到的数据,然后Read View中的事务版本号进行比较。
- 如果不符合Read View的可见性规则, 即就需要Undo log中历史快照;
- 最后返回符合规则的数据
在RC隔离级别下,存在不可重复读的问题分析
先准备数据
DROP TABLE IF EXISTS `student`;
CREATE TABLE `student` (
`id` int(11) NOT NULL,
`name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of student
-- ----------------------------
INSERT INTO `student` VALUES (1, '小明');
设置当前隔离级别为RC
# 查看隔离级别
show variables like 'transaction_isolation';
# 全局修改隔离级别
SET GLOBAL TRANSACTION ISOLATION LEVEL READ COMMITTED;
# SET GLOBAL TRANSACTION ISOLATION LEVEL REPEATABLE READ;
事务并发SQL语句
# 事务A,两次查看同一条数据
BEGIN; # 1
select * from student; # 2 输出 name为 aaa
select * from student; # 6 输出 name为 bbb
COMMIT; # 7
# 事务B,修改数据
BEGIN; # 3
UPDATE student SET name = 'bbb' WHERE id = 1; # 4
COMMIT; # 5
两个事务开两个会话
流程分析:
- 生成事务A的id,假设为100
- 生成该SQL的ReadView,
m_ids |
min_limit_id |
max_limit_id |
creator_trx_id |
|---|---|---|---|
| [100] | 100 | 101 | 100 |
- 生成事务B的id,假设为101
- 生成该SQL的ReadView,
m_ids |
min_limit_id |
max_limit_id |
creator_trx_id |
|---|---|---|---|
| [100,101] | 100 | 102 | 101 |
- 事务B提交
- 生成该SQL的ReadView,因为是RC隔离级别,所以每一次执行SQL都重新生成ReadView
m_ids |
min_limit_id |
max_limit_id |
creator_trx_id |
|---|---|---|---|
| [100] | 100 | 103 | 100 |
查找所有记录行的版本链,从链表头开始遍历,此时的版本链如下,
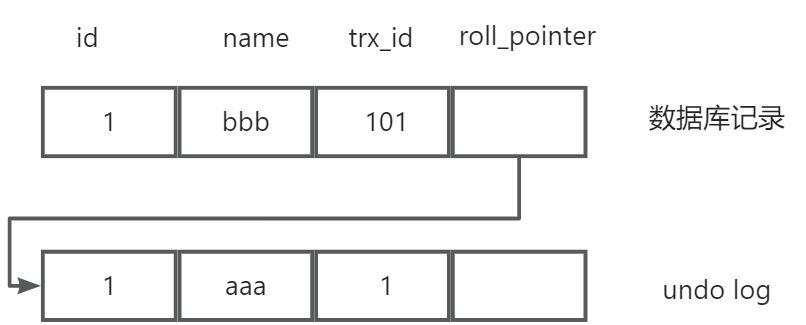
使用ReadView 和 每一行数据的版本链做比较,比较过程如下
min_limit_id(100) <= trx_id (101) < max_limit_id(103)并且m_ids不包含trx_id,说明在生成ReadView时,记录的修改已经提交,所以对最新的数据行bbb对该SQL是可见的。- 返回数据库的bbb那一行的数据。
- 事务A提交
结论:可以看到,第2步和第6步返回的数据不同,发生了不可重复的问题。
在RR隔离级别下,解决不可重复读
修改全局隔离级别,需要新开一个会话
SET GLOBAL TRANSACTION ISOLATION LEVEL REPEATABLE READ;
show variables like 'transaction_isolation';
之前的过程是相同的,进行到第6步时,发生了不同
因为是RR 的隔离级别,所以只会生成一次ReadView
所以,第6步的ReadView 和 第2步是相同的
1-5 同上 。。。
- 生成该SQL的ReadView,因为是RR隔离级别,所以只会生成一次ReadView,使用第2步时的ReadView
m_ids |
min_limit_id |
max_limit_id |
creator_trx_id |
|---|---|---|---|
| [100] | 100 | 101 | 100 |
版本链还是上面的
比较过程如下:
trx_id(101) >= max_limit_id(101),说明这个版本的数据的修改,发生在生成ReadView之后,所以对该ReadView 来说,这个版本的数据是不可见的,根据roll_pointer遍历上一个版本trx_id(1) < min_limit_id(100),说明这个版本的数据的修改,发生在生成ReadView之前,所以对该ReadView 来说,这个版本的数据是可见的,所以返回 aaa 这一行的数据
- 同上,事务A提交