第十一章EXT2文件系统—学习笔记
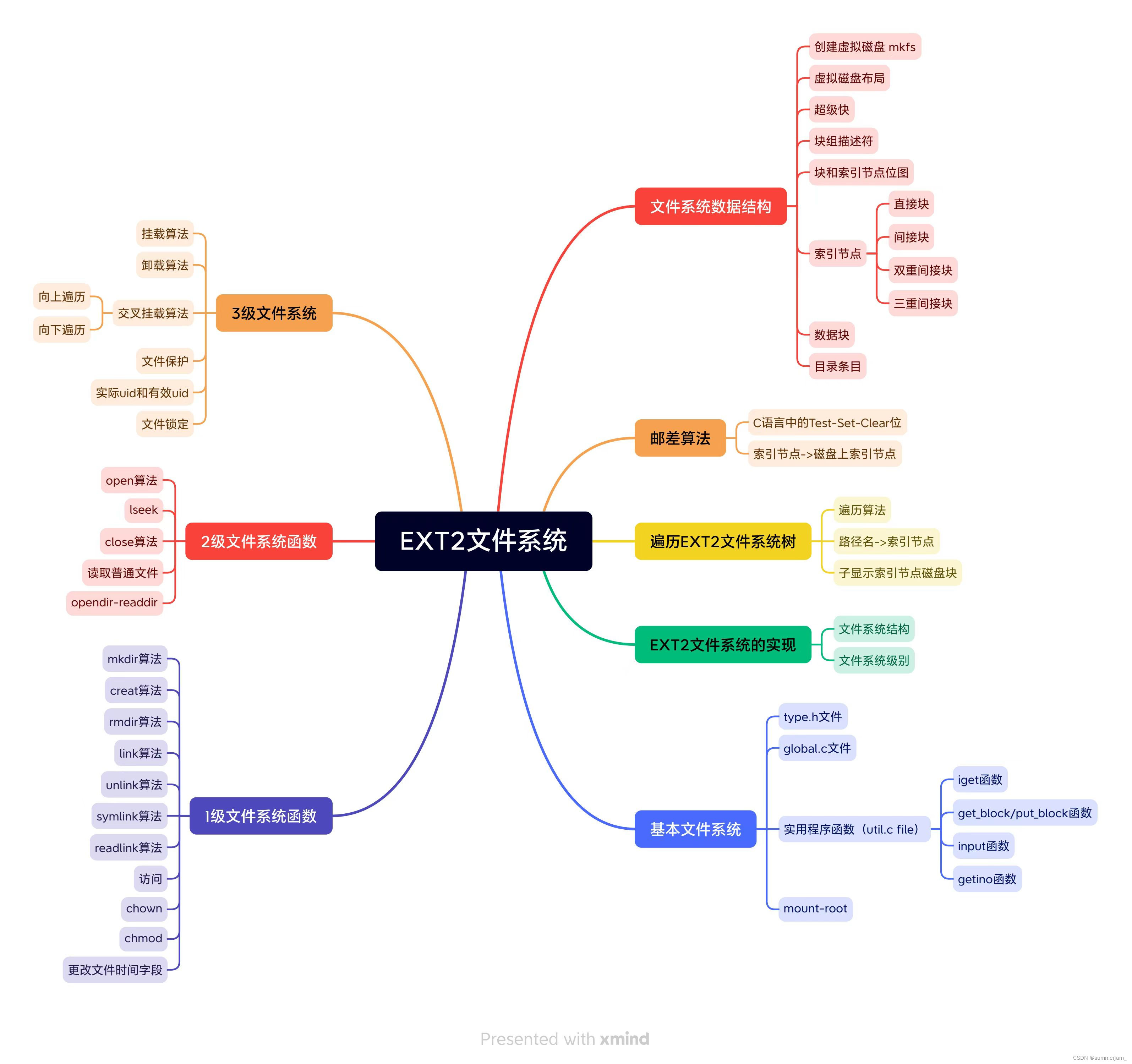
〇、本章思维导图
一、文件系统数据结构
- 通过 mkfs 创建虚拟磁盘
在Linux下,命令
mke2fs [-b blkesize -N ninodes] device nblocks
在设备上创建一个带有nblocks个块(每个块大小为blksize字节)和ninodes个索引节点的EXT2文件系统。设备可以是真实设备,也可以是虚拟磁盘文件。如果未指定blksize,则默认块大小为1KB。如果未指定ninoides,mke2fs将根据 nblocks 计算一个默认的ninodes数。得到的EXT2文件系统可在Linux中使用。
使用命令
dd if=/dev/zero of=myfirstdisk bs=1024 count=1440 - 虚拟磁盘布局
一个磁盘可以分成多个分区,每个分区必须先用格式化工具格式化成某种格式的文件系统,才能存储文件,在格式化的过程中会在磁盘上写一些管理存储布局的信息。
Block#0:
引导块,文件系统不会使用它。它用于容纳从磁盘引导操作系统的引导程序。
Block#1:
超级块(在硬盘分区中字节偏移量为1024)。用于容纳关于整个文件系统的信息。
超级块中一些重要字段
s_first_data_block:0表示4KB块大小,1表示1KB块大小。它用于确定块组描述符的起始块,即s_first_data_block +1。
s_log_block_size确定文件块大小,为1KB*(2**s_log_block_size),例如0表示 1KB块大小,1表示2KB块大小,2表示4KB块大小,等等。最常用的块大小是用于小文件系统的1KB和用于大文件系统的4KB。
s_mnt_count:已挂载文件系统的次数。当挂载计数达到max_mount_count时,fsck会话将被迫检查文件系统的一致性。
s_magic是标识文件系统类型的幻数。EXT2/3/4文件系统的幻数是OxEF53。
Block#2
块组描述符(硬盘上的s_first_data_blocks-1)
EXT2将磁盘块分成几个组,每个组有8192个块(硬盘上的大小为32K)
由于一个软盘只有1440个块,B2只包含一个块组描述符。其余的都是0。在有大量块组的硬盘上,块组描述符可以跨越多个块。块组描述符中最重要的字段是bg_block_bitmap.bg_inode_bitmap和 bg_inode_table,它们分别指向块组的块位图、索引节点位图和索引节点起始块。对于Linux格式的EXT2文件系统,保留了块3到块7。所以,bmap=8,imap=9,inode_table= 10。
Block #8 块位图(Bmap)
用来表示某种项的位序列。0表示对应项处于FREE状态,1表示处于IN_USE状态。1个软盘有1440个块,但Block#0未被文件系统使用,所以对应位图只有1439个有效位,无效位视作IN_USE处理,设置为1.
Block #9 索引节点位图(Imap)
一个索引节点就是用来代表一个文件的数据结构。EXT2文件系统是使用有限数量的索引节点创建的。各索引节点的状态用B9 中 Imap中的一个位表示。在EXT2 FS 中,前10个索引节点是预留的。所以,空EXT2FS的Imap 以10个1开头,然后是0。无效位再次设置为1。
Block #10 索引(开始)节点块(bg_inode_table)
每个文件都用一个128字节(EXT4中的是256字节)的独特索引节点结构体表示。
在i mode 字段中,前4位指定了文件类型,例如∶tt=1000表示REG文件,0100表示 DIR文件等。接下来的3位ugs表示文件的特殊用法。最后9位是用于文件保护的rwx 权限位。
i_size字段表示文件大小(以字节为单位)。各时间字段表示自1970年1月1日0时0分0秒以来经过的秒数。所以,每个时间字段都是一个非常大的无符号整数。可借助以下库函数将它们转换为日历形式;
char *ctime(&time_field)
将指针指向时间字段,然后返回一个日历形式的字符串。
例如:printf("%s",ctime(&inode.i_atime);// note∶ pass & of time field prints i_atime in calendar form.
i_block[15]数组包含指向文件磁盘块的指针,这些磁盘块有∶
直接块∶iblock[0] 至i block[11],指向直接磁盘块。
2. 间接块∶i block[12]指向一个包含256个块编号(对于1KB BLKSIZE)的磁盘块,每个块编号指向一个磁盘块。
3. 双重间接块∶i block[13]指向一个指向256个块的块,每个块指向 256个磁盘块。
三重间接块∶i_block[14]是三重间接块。对于"小型"EXT2文件系统,可以忽略它。索引节点大小(128或256)用于平均分割块大小(1KB或4KB),所以,每个索引节点块都包含整数个索引节点。在简单的EXT2文件系统中,索引节点的数量是184个(Linux默认值)。索引节点块数等于184/8=23个。因此,索引节点块为B10至B32。每个索引节点都有一个唯一的索引节点编号,即索引节点在索引节点块上的位置+1。注意,索引节点位置从0开始计数,而索引节点编号从1开始计数。0索引节点编号表示没有索引节点。根目录的索引节点编号为2。同样,磁盘块编号也从1开始计数,因为文件系统从未使用块0。块编号0表示没有磁盘块。
数据块
紧跟在索引节点块后面的是文件存储数据块。假设有184个索引节点,第一个实际数据块是B33,它就是根目录/的i_block[0]。
根据不同文件类型有一下几种情况:
(1)对于常规文件,文件的数据存储在数据块中。
(2)对于目录,该目录下的所有文件名和目录名存储在数据块中,除文件名之外,ls -l命令中看到的信息则存储在inode中;目录也是一种文件,是一种特殊类型的文件。
(3)对于符号链接,如果目标路径名较短则直接保存在inode中以便更快的查找,如果目标路径名较长则分配一个数据块来保存。
(4)设备文件,FIFO和socket等特殊文件没有数据块,设备文件的主设备号和次设备号保存在inode中。
数据块寻址
二、邮差算法
在计算机系统中,经常出现下面这个问题。一个城市有M个街区,编号从0到M-1。每个街区有N座房子,编号从0到N-1。每座房子有一个唯一的街区地址,用(街区,房子)表示,其中0≤街区<M,0≤房子<N。来自外太空的外星人可能不熟悉地球上的街区寻址方案,倾向于采用线性方法将这些房子地址编为0,1,…,N-1,N,N+1等。已知某个街区地址 BA =(街区,房子),怎么把它转换为线性地址 LA,反过来,已知线性地址,怎么把它转换为街区地址?如果都从0开始计数,转换就会非常简单。
只有都从0开始计数时,转换才有效。如果有些条目不是从0开始计数的,则不能直接在转换公式中使用。
下面是邮差算法的几种应用。
- C语言中的 Test-Set-Clear 位
在标准C语言程序中,最小的可寻址单元是一个字符或字节。在一系列位组成的位图中,通常需要对位进行操作。考虑字符 buf[1024],它有1024个字节,用buf[i]表示,其中i=0,1,…,1023。它还有8192个位,编号为0,1,2,…,8191。
注意,一些C语言编译器允许在结构体中指定位,如∶
struct bits{
unsigned int bit0
: 1; // bit0 field is a single bit
unsigned int bit123
:3;// bit123 field is a range of 3 bits
unsigned int otherbits:27;// other bits field has 27 bits
unsigned int bit31
: 1;// bit31 is the highest bit
}var;
该结构体将var.定义为一个32位无符号整数,具有单独的位或位范围。那么,var.bit0=0;将1赋值给第0位,则有var.bit123=5;将101赋值给第1位到第3位等。但是,生成的代码仍然依赖于邮差算法和位屏蔽来访问各个位。我们可以用邮差算法直接操作位图中的位,无须定义复杂的C语言结构体。
2. 将索引节点号转换为磁盘上的索引节点
在EXT2文件系统中,每个文件都有一个唯一的索引节点结构。在文件系统磁盘上,索引节点从 inode table 块开始。每个磁盘块包含INODES_PER_BLOCK = BLOCK_SIZE/slzeof(INODE)
个索引节点。每个索引节点都有一个唯一的索引节点号,ino=1,2,…,从1开始线性计数。
已知一个ino,如1234,那么哪个磁盘块包含该索引节点,以及哪个索引节点在该块中呢?我们需要知道磁盘块号,因为需要通过块来读/写一个真正的磁盘。
block =(ino - 1) / INODES_PER_BLOCK + inode_table;
inode =(ino - 1) % INODES_PER_BLOCK;
同样,将 EXT2文件系统中的双重和三重间接逻辑块号转换为物理块号也依赖于邮差算法。 将线性磁盘块号转换为 CHS=(柱面、磁头、扇区)格式∶软盘和旧日硬盘使用CHS 寻址,但文件系统始终使用线性块寻址。在调用BIOS INT13时,可用该算法将磁盘块号转换为CHS。
三、遍历EXT2文件系统树
- 遍历算法
(1)读取超级块。检查幻数s_magic(0xEF53),验证它确实是 EXT2 FS。
(2)读取块组描述符块(1 + s_first_data_block),以访问组0描述符。从块组描述符的bg_inode_table条目中找到索引节点的起始块编号,并将其称为InodesBeginBlock。
(3)读取 InodeBeginBlock,获取/的索引节点,即 INODE#2。
(4)将路径名标记为组件字符串,假设组件数量为n。例如,如果路径名 =/a/b/c,则组件字符串是"a""b""c",其中n=3。用name[0],name[1],…,name[n-1]来表示组件。
(5)从(3)中的根索引节点开始,在其数据块中搜索 name[0]。为简单起见,我们可以假设某个目录中的条目数量很少,因此一个目录索引节点只有12个直接数据块。有了这个假设,就可以在12个(非零)直接块中搜索 name[0]。目录索引节点的每个数据块都包含以下形式的 dir entry 结构体;
[ino rec_len name_len NAME] [ino rec_len name_len NAME]....
其中NAME是一系列nlen字符,不含终止NUL。对于每个数据块,将该块读入内存并使用 dir_entry *dp指向加载的数据块。然后使用 name_len将NAME提取为字符串,并与name[0]进行比较。如果它们不匹配,则通过以下代码转到下一个dir_entry:
dp =(dir_entry*)((char *)dp + dp->rec_len);
继续搜索。如果存在 name[0],则可以找到它的 dir_entry,从而找到它的索引节点号。
(6)使用索引节点号ino来定位相应的索引节点。回想前面的内容,ino 从1开始计数。使用邮差算法计算包含索引节点的磁盘块及其在该块中的偏移量
(6)使用索引节点号ino来定位相应的索引节点。回想前面的内容,ino 从1开始计数。使用邮差算法计算包含索引节点的磁盘块及其在该块中的偏移量。
blk =(ino - 1) / INODE8_PER_BLOCK + InodesBeginBlock;
offset = (ino - 1) % INODES_PER_BLOCK;
然后在索引节点中读取/a,从中确定它是否是一个目录(DIR)。如果/a不是目录,则不能有/a/b,因此搜索失败。如果它是目录,并且有更多需要搜索的组件,那么继续搜索下一个组件 name[1]。现在的问题是∶在索引节点中搜索/a的 name[1],与第(5)步完全相同。
(7)由于(5)~(6)步将会重复n次,所以最好编写一个搜索函数∶
u32 search (INODE *inodePtr, char *name)
{
// search for name in the data blocks of current DIR inode
// if found, return its ino; else return 0 )
}
然后我们只需调用 search()n次,如下所示。
Assume:n,name[0],....,name[n-1] are globals
INODE *ip points at INODE of /
for(i=0; i<n; i++)
{
ino = search(ip, name[4])
if(!ino){ // can't find name[i], exit;}
use ino to zead in INODE and let ip point to INODE
}
如果搜索循环成功结束,ip必须指向路径名的索引节点。遍历有多个组的大型 EXT2/3 文件系统也是类似操作。
四、EXT2文件系统的实现
在ext2系统中,所有元数据结构的大小均基于“块”,而不是“扇区”。块的大小随文件系统的大小而有所不同。而一定数量的块又组成一个块组,每个块组的起始部分有多种多样的描述该块组各种属性的元数据结构。ext2系统中对各个结构的定义都包含在源代码的include/linux/ext2_fs.h文件中。
五、基本文件系统
- typh.h文件
这类文件包含EXT2文件系统的数据结构类型,比如超块、组描述符、索引节点和目录条目结构。此外,它还包含打开文件表、挂载表、PROC结构体和文件系统常数。 - global.c文件
这类文件包含文件系统的全局变量。全局变量的例子有;
MINODE minode [NMINODE]; // in memory INODEs
MTABLE mtable[NMTABLE]; // mount tables
OFT oft[NOPT]; // Opened file instance
PROC proc[NPROC] // PROC structures
PROC *running; // current executing PROC
当文件系统启动时,我们初始化所有全局数据结构,并让运行点位于PROC[0],即超级用户的进程P0(uid = 0)。在实际系统中,每个操作都是由当前运行的进程决定的。我们从超级用户进程开始,因为它不需要任何文件保护。通过权限检查以保护文件将在第3级别的FS实现中执行。
文件系统操作过程中,全局数据结构被视为系统资源,可灵活使用和释放。每一组资源都由一对分配和释放函数管理。例如,mialloc()分配一个空闲的minode供使用,而midalloc()则释放一个使用过的minode。其他资源管理函数与此类似。
3. mount-root
mount_root.c文件:该文件包含mount_root()函数,在系统初始化期间调用该函数来挂载根文件系统。它读取根设备的超级块,以验证该设备是否为有效的EXT2文件系统。然后,它将根设备的根INODE (ino =2)加载到minode中,并将根指针设置为根minode。它还将所有进程的当前工作目录设置为根minode。分配一个挂载表条目来记录挂载的根文件系统。根设备的一些关键信息,如inode和块的数量、位图的起始块和 inode,表,也记录在挂载表中,以便快速访问。
六、1级文件系统函数
- mkdir算法
mkdir命令:mkdir pathname
创建了一个带路径名的新目录。将新目录的权限位设置为默认值0755(所有人可以访问和读写,其他人可以访问但只能读取)。
mkdir使用包含默认.和..条目的数据块创建一个空目录。 - creat算法
creat将创建一个空的普通文件 - rmdir算法
rmdir命令: rmdir dirname
可删除目录。在Unix/Linux中,要想删除目录,目录必须为空,原因如下。首先,删除非空目录意味着删除该目录中的所有文件和子目录。虽然可以实现rmdir递归操作,即删除整个目录树,但基本操作仍然是一次删除一个目录。其次,非空目录可能包含正在使用的文件,例如,打开进行读/写的文件等。显然,删除这类目录是不可接受的。虽然可以检查目录中是否有在用文件,但是这样做会产生过多的系统操作。最简单的方法是要求目录必须为空才能删除。
七、2级文件系统函数
- open算法
在 Unix/Linux中,系统调用int open(char *filename,int flags);打开一个文件进行读或写,标记是O_RDONLY、O_WRONLY、O_RDWR其中之一,可与O_CREAT、O_APPEND、O_TRUNC标记逐位进行or组合。这些符号常数在 fcntl.h文件中定义。如果成功,openO会返回一个文件描述符(编号),用于后续系统调用中,如 readO、write()、lseek0)和 close()等。为简单起见,我们将假设参数标记O|1|2|3或RD|WR|RW|AP 分别表示读|写|读写|追加。 - lseek
在 Linux 中,系统调用
`lseek(fd,position,whence);// whence=SEEK_SET or SEEK_CUR
将打开的文件描述符在OFT中的偏移量设置为从文件开头(SEEK SET)或当前位置(SEEK CUR)开始的字节位置。 - close算法
close(int fd)操作可关闭文件描述符。
八、3级文件系统
- 挂载算法
挂载操作命令mount tilesys mount_point可将某个文件系统挂载到mount_point目录上。它允许文件系统包含其他文件系统作为现有文件系统的一部分。挂载中使用的数据结构是挂载表和mount point目录的内存minode。 - 卸载算法
卸载文件系统操作可卸载已挂载的文件系统。它将挂载的文件系统与挂载点分开,其中文件系统可以是虚拟的diak名称或挂载点目录名称。若要检查挂载的文件系统是否包含正在使用的文件,可搜索内存minode中是否有任何条目的设备与挂载文件系统的设备号匹配。 - 交叉挂载点
虽然可以轻松实现挂载和卸载,但是会有一定的影响。对于挂载,我们必须修改getino(pathname)函数,来支持交叉挂载点。假设某文件系统newfs已被挂载到目录/a/b/c/上。当遍历一个路径名时,两个方向的挂载点可能会出现交叉。
(1)向下遍历:当遍历路径名/a/b/c/x时,一旦到达/a/b/e的 minode,我们就能看到minode已经被挂载(挂载标志=1)。我们不是在/a/b/c的索引节点中搜索x,而是必须要:
跟随minode的mntPtr 指针来定位挂载表条目。
从挂载表的设备号中,将其根索引节点(ino=2)放入内存。·然后,继续在挂载设备的根索引节点下搜索x。
(2)向上遍历:假设我们在目录/a/b/c/x/上,然后向上遍历,例如 cd ..l..l、将会与挂载点/a/b/c交叉。当到达挂载文件系统的根索引节点时,我们就能看到它是一个根目录(ino=2),但是它的设备号与实根的设备号不同,因此它现在还不是实根。我们可以使用它的设备号,找到它的挂载表条目,它指向/a/bici的minode。然后,切换到/a/b/c/的minode,继续向上遍历。因此,交叉挂载点就像一只猴子或松鼠从一棵树跳到另一棵树上,然后又跳了回来。
九、苏格拉底挑战
1.邮差算法
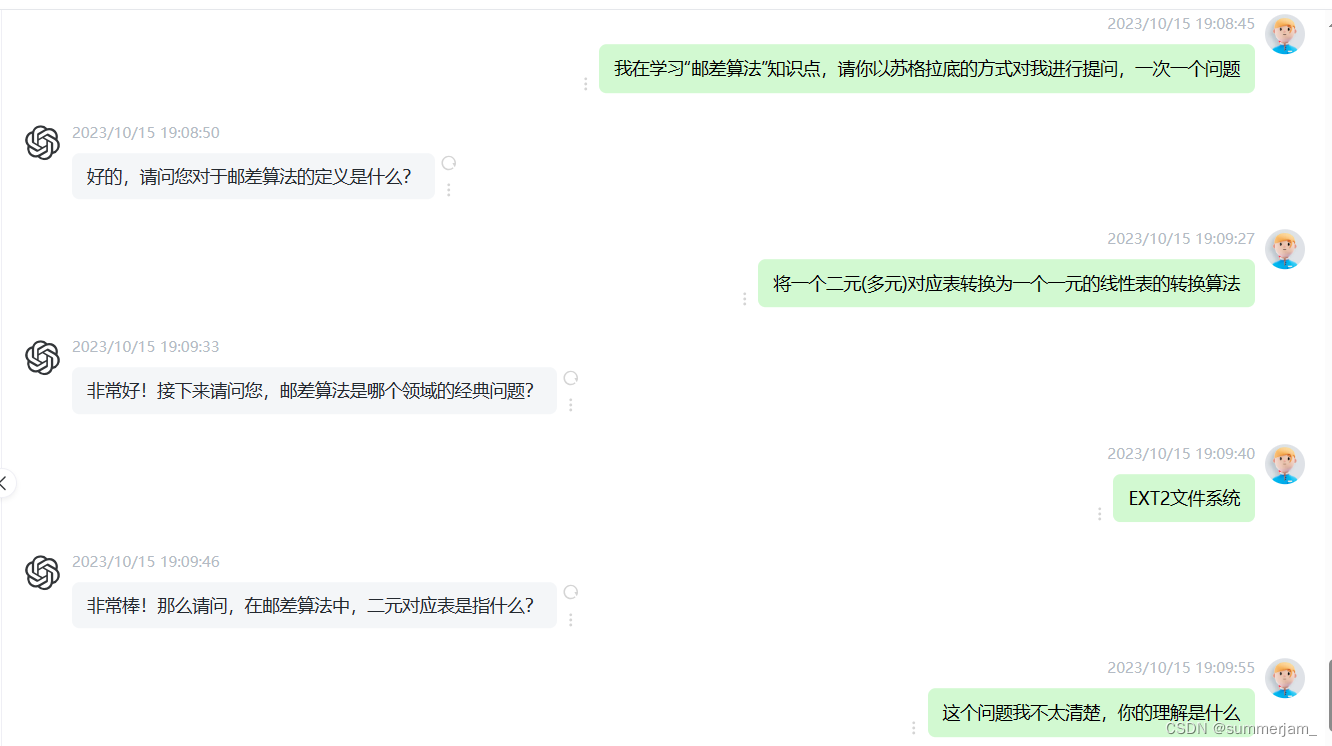


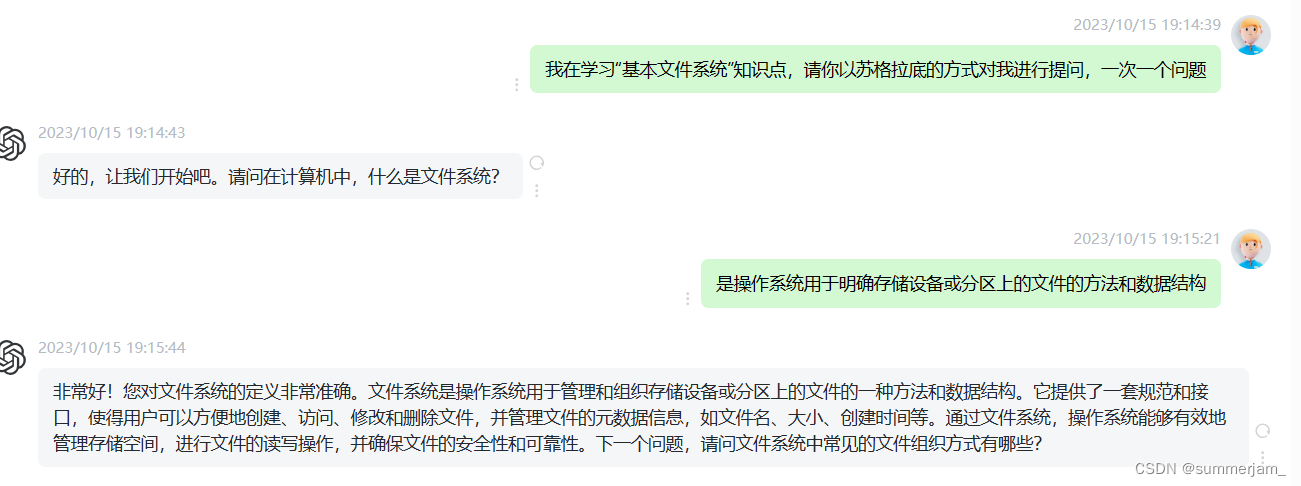
2.基本文件系统
因为GPT跑题解锁的“隐藏结局”

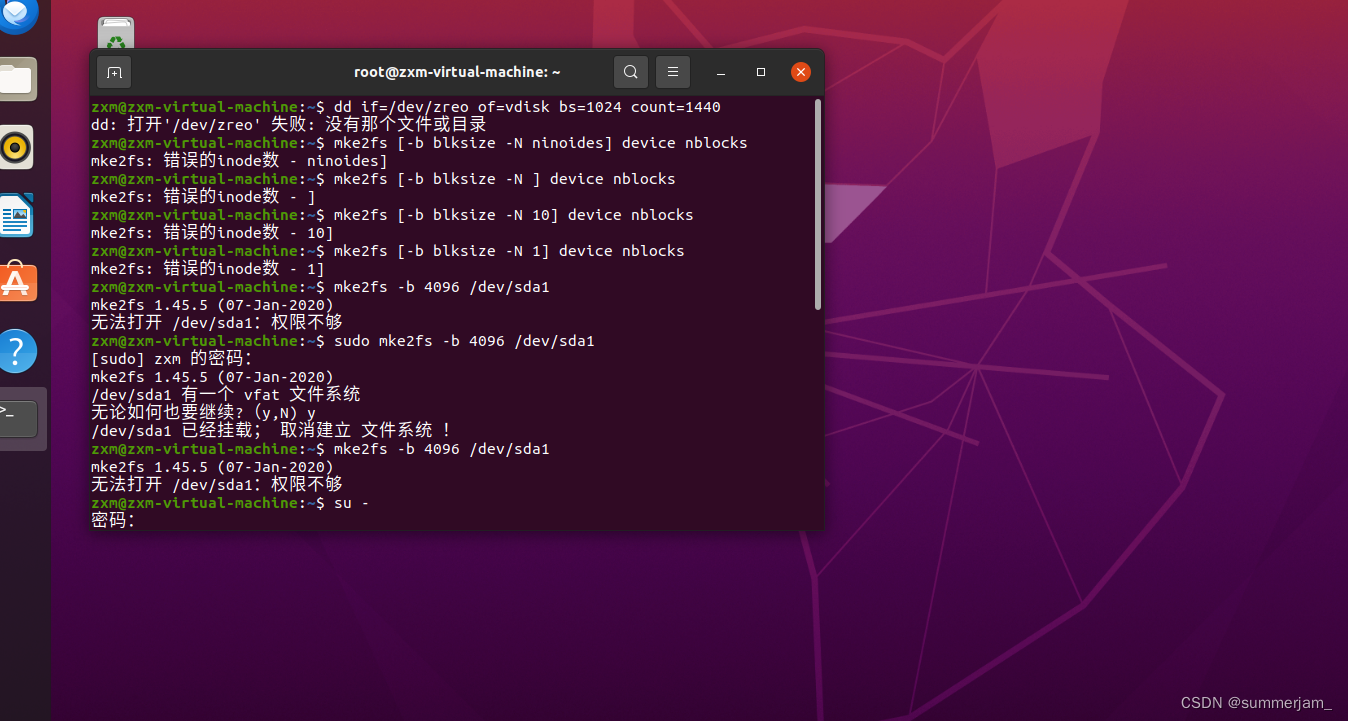
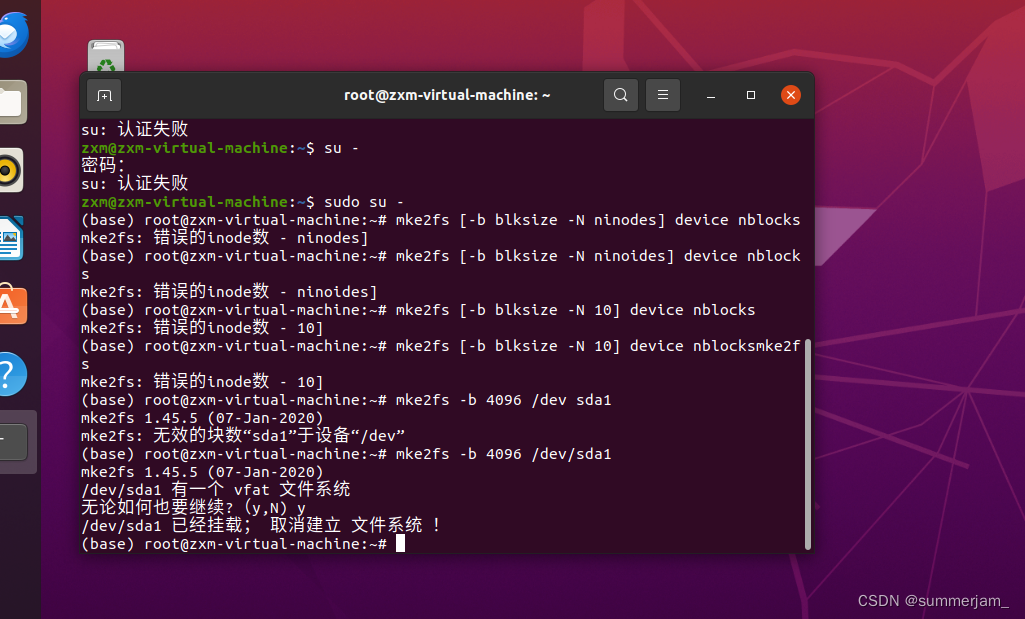
十、问题与解决
在创建虚拟磁盘过程中,我遇到了以下问题
通过对GPT的询问(中途多次修正我的promote),但是最后还是没有得到有用的解答,经过这段时间对于GPT的学习应用,我感到一些实际问题在CSDN上看博客往往比问GPT更有效,说明人工智能仍需升级,我也需要提升自己的promote能力