一、Spark RDD
1. RDD是什么
RDD,即弹性分布式数据集(Resilient Distributed Dataset),是Spark对数据的抽象,本质上是分布在多个节点上的数据集合。
弹性是指当内存不够时,数据可以持久化到磁盘,并且RDD具有高效的容错能力。
分布式数据集是指一个数据集存储在不同的节点上,每个节点存储数据集的一部分。
例如,有数据集(hello,world,scala,spark,love,spark,happy),存储在三个节点上,节点一存储(hello,World),节点二存储(scala,spark,love),节点三存储(spark,happy),将数据集分开存储,有利于并行处理
在编程时,无需关心上述概念,只需将RDD看成是数据的集合,对RDD进行操作即可。
2. 创建RDD
创建RDD,即导入数据,要处理数据,就要先导入数据到Spark,Spark支持多种数据源。
2.1 从集合创建
val sc = new SparkContext(conf)
val rdd = sc.parallelize(List(1, 2, 3, 4, 5, 6))
print(rdd)
2.2 从外部存储创建RDD
需要使用哪个数据源,搜索文档即可
3. RDD算子
3.1 转换算子
1.map
接收一个元素,对其进行处理,然后返回处理后的结果
val rdd = sc.parallelize(List(1, 2, 3, 4, 5, 6, 7))
rdd.map(_+1).collect()
2.flatMap
和map类似,但是map每次返回1个值,flatMap可返回0到多个值
val rdd = sc.parallelize((1 to 10).toList)
rdd.flatMap(value =>
if (value < 5) {
// 如果值小于5,返回两个随机值
Seq(scala.util.Random.nextInt(100), scala.util.Random.nextInt(100))
} else {
// 如果值大于等于5,返回四个随机值
Seq(scala.util.Random.nextInt(100), scala.util.Random.nextInt(100),
scala.util.Random.nextInt(100), scala.util.Random.nextInt(100))
}).collect()
3. filter
过滤,只有满足条件的值才能通过
val rdd = sc.parallelize(List(1, 2, 3, 4, 5, 6, 7))
// 小于等于3的值会被过滤
rdd.filter(_>3).collect()
4. reduceByKey
作用对象:(key, value)元组,该算子会把Key值相同的元素合并到一起处理
例:将Key值相同的元组求和
val list = List(("A", 10), ("A", 20), ("B", 5), ("B", 6))
val rdd = sc.parallelize(list)
rdd.reduceByKey((x,y)=>x+y).collect()
最终结果
(A,30), (B,11)
5. groupByKey
作用对象:(key, value)元组,
该算子会把Key值相同的元素合并为一个元素
val list = List(("A", 10), ("A", 20), ("B", 5), ("B", 6))
val rdd = sc.parallelize(list)
rdd.groupByKey().collect()
结果:
(A,Seq(10, 20)), (B,Seq(5, 6))
6.union
将两个RDD合并成一个新的RDD,主要用于对不同的数据源进行合并,两个RDD的数据类型要一致
val array1 = Array(1,2)
val array2 = Array(4,5,7)
val rdd1 = sc.parallelize(array1)
val rdd2 = sc.parallelize(array2)
rdd1.union(rdd2).collect()
7. sortBy
按照给定规则,对RDD内元素进行排序
该算子接收两个参数,第一个参数为排序函数,第二个参数是bool值,指定升序或降序排列,升序是true(默认),降序是false
val array = Array(("hadoop", 1), ("java", 3), ("scala", 2))
val rdd = sc.parallelize(array)
rdd.sortBy(_._2, false).collect()
8. sortByKey
接收(key, value)格式的元素,按照key进行排序,默认true升序,false为降序
9. join
内连接
val array1 = Array(("A", "a1"), ("B", "b2"), ("B", "b3"))
val array2 = Array(("A", "A1"), ("B", "B2"), ("B", "B3"), ("C", "C1"))
val rdd1 = sc.parallelize(array1)
val rdd2 = sc.parallelize(array2)
rdd1.join(rdd2).collect()
结果
(A,(a1,A1)), (B,(b2,B2)), (B,(b2,B3)), (B,(b3,B2)), (B,(b3,B3))
除join外,还有leftOuterJoin、rightOuterJoin、fullOuterJoin
fullOuterJoin:相当于取并集
10.intersection
取交集
val rdd1 = sc.parallelize(1 to 5)
val rdd2 = sc.parallelize(4 to 9)
rdd1.intersection(rdd2).collect()
结果
Array(4, 5)
11. distinct
去重
val array = Array(1,1,2,2,2,2,3,4,5,6,7,8,8,8,9)
val rdd = sc.parallelize(array1)
rdd.distinct().collect()
12. cogroup
3.2 行动算子
Spark是懒执行,也就是碰到转化算子只是记录下来,并不会进行运算,直到遇到行动算子才开始真正执行

1.reduce
求和
val array = Array(1,1,2,2,2,2,3,4,5,6,7,8,8,8,9)
val rdd = sc.parallelize(array)
rdd.reduce(_+_)
4. RDD的分区
RDD是数据的集合,该集合被划分为多个子集,分布在不同的节点上,每一个子集被称为分区(Partition)。因此可以说,RDD是由若干个分区组成的。RDD与分区的关系如图所示。
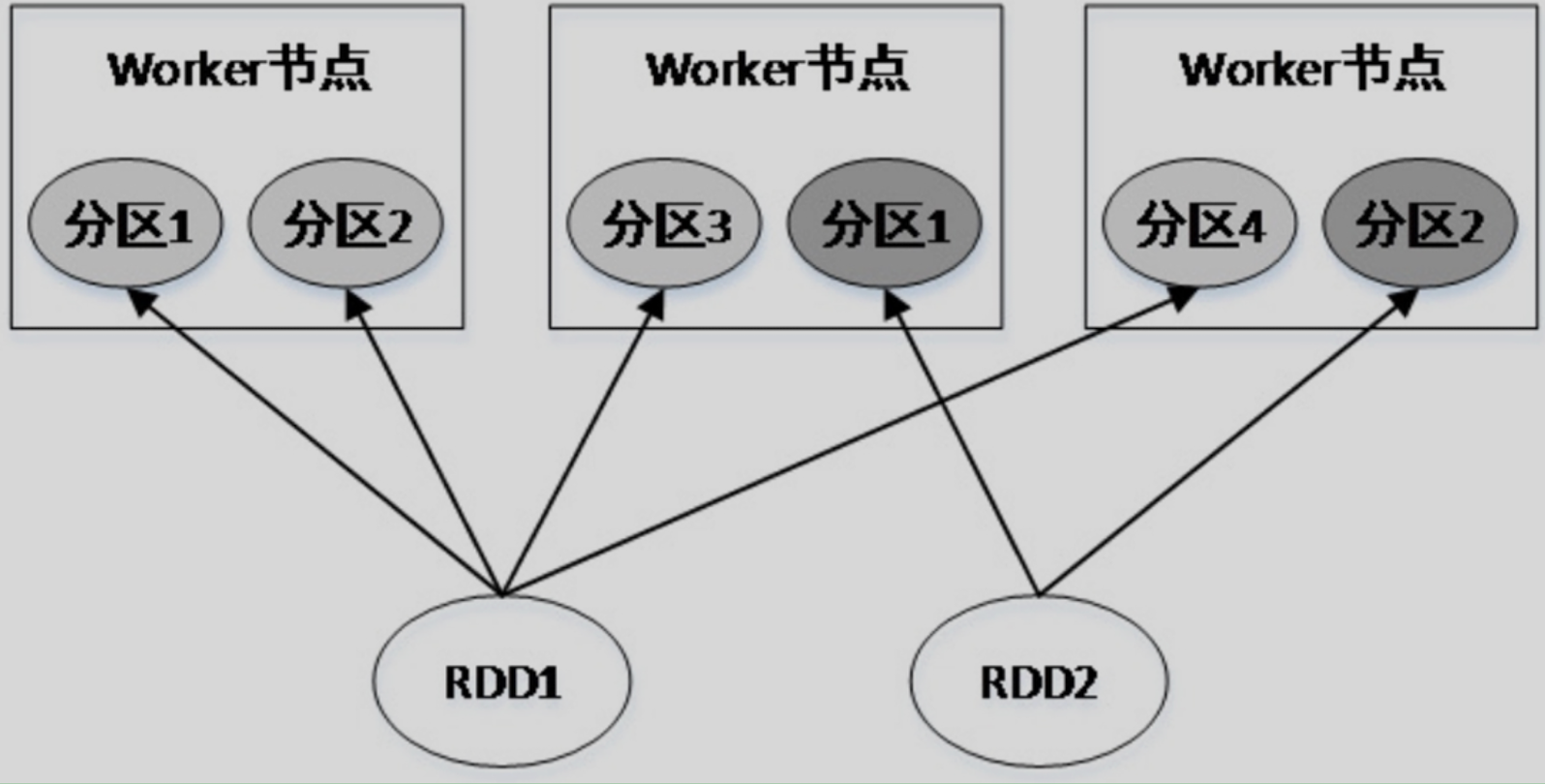
RDD不同分区的数据可以并行计算,因此分区的数量决定了并行计算的粒度。Spark会给每个分区分配一个单独的Task进行计算,因此Task的数量是由分区数量决定的。
RDD分区的原则是:分区的数量尽量等于集群CPU核心的数量。
4.1 parallelize
指定分区数量
val array = Array(1,1,2,2,2,2,3,4,5,6,7,8,8,8,9)
val rdd = sc.parallelize(array, 10)
rdd.getNumPartitions
默认分区数量
若不指定分区数量,则默认分区数量为Spark配置文件spark-defaults.conf中 spark.default.parallelism的值。
若没有配置该参数,Spark会根据集群的运行模式确定分区数量。
本地模式:分区数量 = 本机CPU核心数,这样每个核心处理一个分区,可以最大程度发挥CPU的性能。Spark Standalone或Spark On YARN模式:分区数量 =Max(集群CPU核心总数,2),即最少分区数为2。
4.2 textFile
指定最小分区数量
val rdd = sc.textFile("word.txt", 10)
rdd.getNumPartitions
5. RDD依赖
Spark中的处理类似于一条流水线,后一个处理依赖于前一个处理的结果,因此RDD存在前后依赖关系,这种关系分为两种:窄依赖和宽依赖
5.1 窄依赖
窄依赖是指父RDD的一个分区最多被子RDD的一个分区所用。也就是说,父RDD与子RDD的分区对应关系为一对一或多对一。例如,map()、filter()、union()等操作都是窄依赖。就是说执行算子前后,数据不需要调整所在分区。
5.2 宽依赖
宽依赖是指父RDD的一个分区被子RDD的多个分区所用。也就是说,父RDD与子RDD的分区的关系为多对多。例如,groupByKey()、reduceByKey()、sortByKey()等操作都是宽依
赖。
宽依赖就是执行算子后,数据需要调整位置,比如有两类数据,一类数据的Key是A,另一类Key为B,两类数据打散分布在多个分区,在执行groupByKey后,A和B的数据就需要分开,一个分区只存储A,另一个分区只存储B。
5.3 Stage划分
在Spark中,每一次对RDD进行操作都会生成一个新的RDD,Spark会按照依赖关系,将这些RDD形成一个有向无环图DAG(Directed Acyclic Graph)。
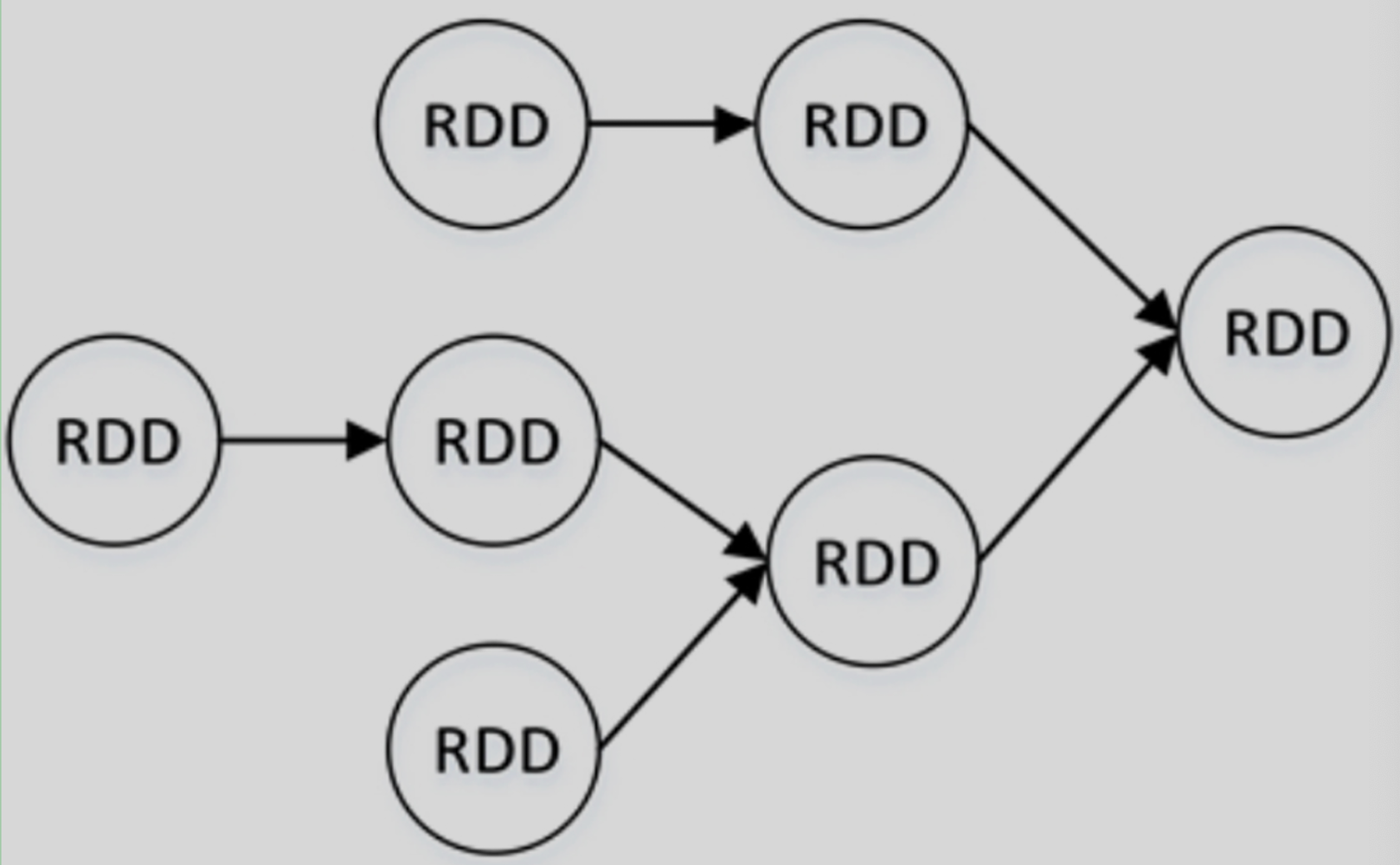
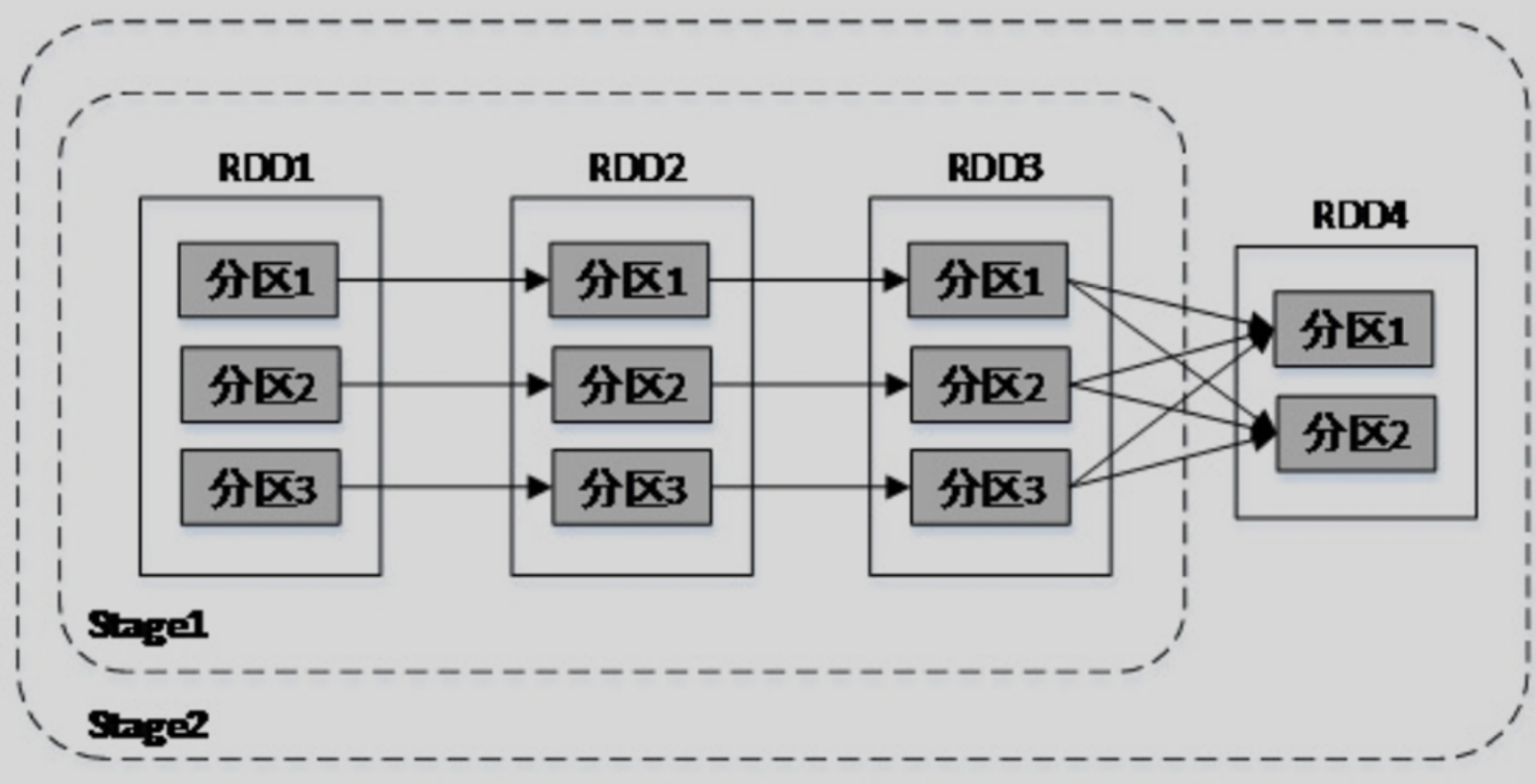
Spark会根据DAG将整个计算划分为多个阶段(Stage)。每个Stage由多个Task任务并行计算,每个Task任务作用于一个分区,Stage的Task数量由Stage最后一个RDD的分区数决定。
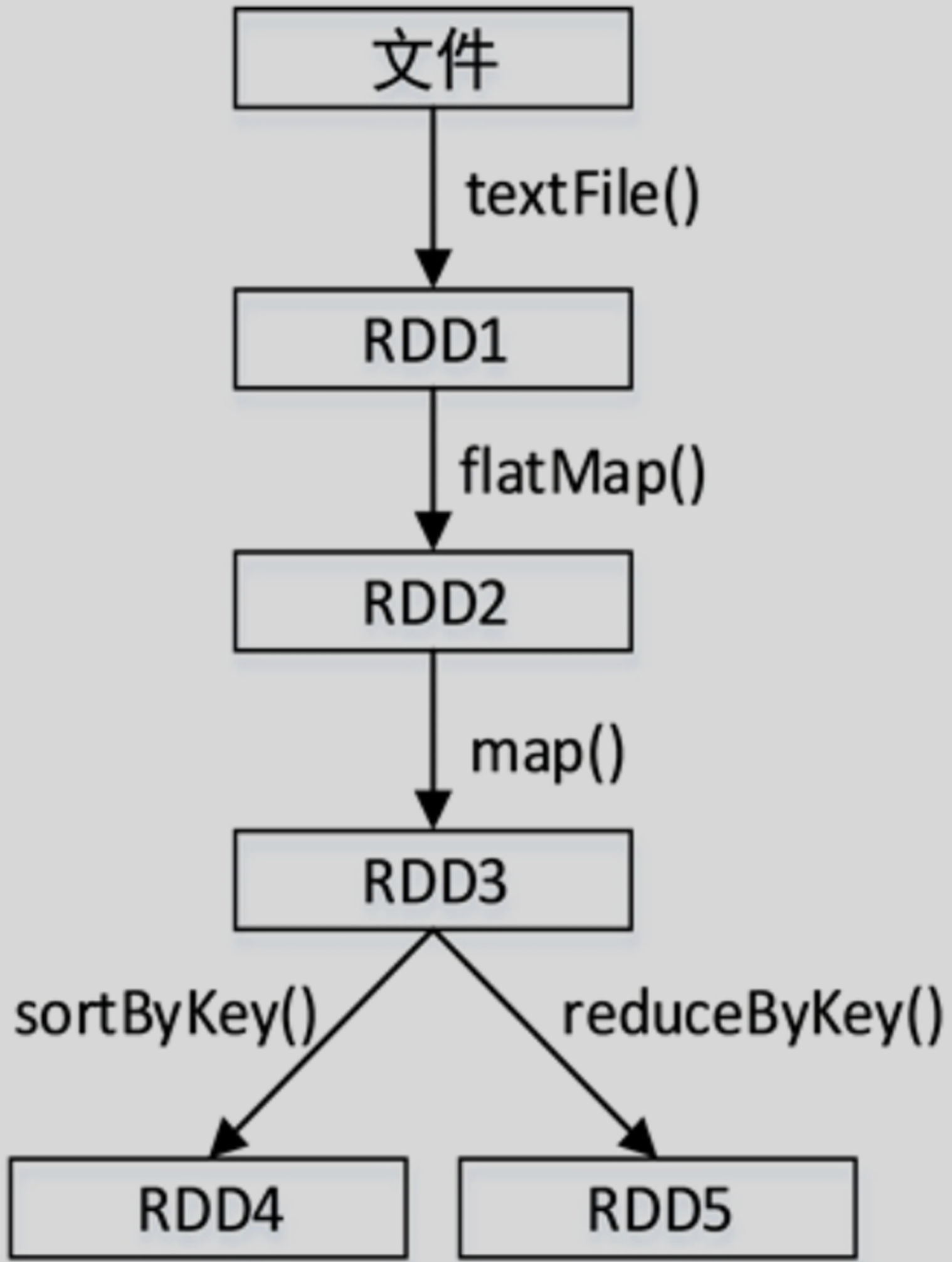
Stage的划分依据为是否有宽依赖,即是否有Shuffle。Spark调度器会从DAG图的末端向前推进,遇到Shuffle就进行划分,Shuffle之前的所有RDD组成一个Stage,整个DAG图为一个Stage。经典的单词计数Stage划分如图所示。
6. RDD Persist
RDD是懒加载的,只有遇到行动算子时才会真正开始计算,且当同一个RDD被多次使用时,需要重新计算,这样开销太大。为了避免重复计算,可以持久化RDD。
Spark中可以将某个RDD中保存到内存或者磁盘中,需要对这个RDD进行操作时,直接取出,不需要从头计算。
例如有多个RDD,依赖关系如图。在图中对RDD3进行了两次操作,分别生成了RDD4和RDD5。若RDD3没有持久化,则每次对RDD3进行操作都需要从RDD1开始计算,可以持久化RDD3,这样就可以重复使用。
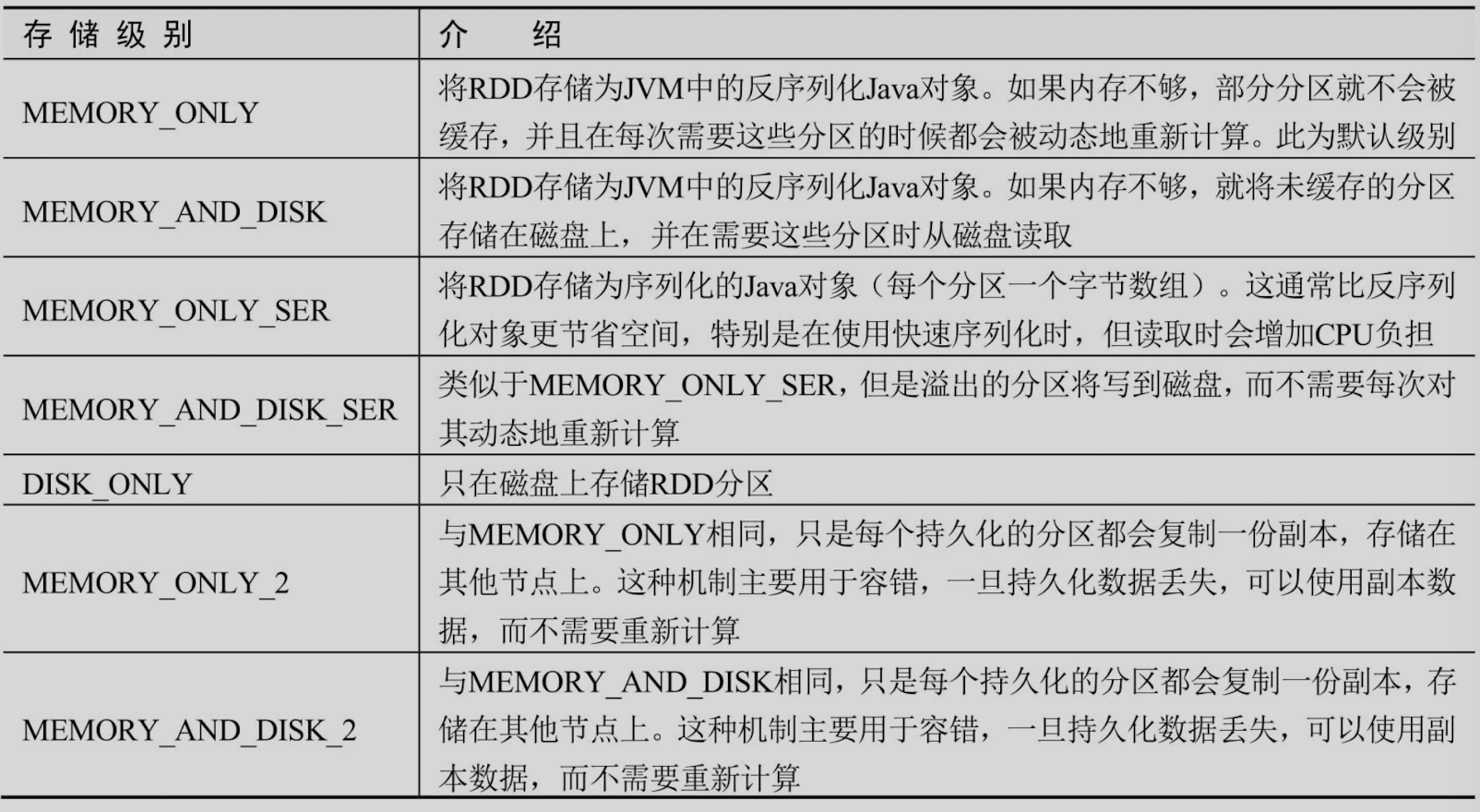
6.1 存储级别
RDD可以使用不同的存储级别进行存储,默认的存储级别是StorageLevel.MEMORY_ONLY。主要存储级别如下:
在Shuffle操作(例如reduceByKey())中,即使用户没有使用persist方法,也会自动保存一些中间数据。这样做是为了避免在Shuffle失败时重新计算整个输入。如果想多次使用某个RDD,那么强烈建议持久化该RDD。
如何选择存储级别?
- 如果内存足够大,能够放得下RDD,那么优先使用默认存储级别(MEMORY_ONLY)
- 如果RDD存储在内存中会发生溢出,那么使用MEMORY_ONLY_SER并选择一个快速序列化库将对象序列化,以节省空间,访问速度仍然相当快。
- 除非计算RDD的代价非常大,或者该RDD存储了大量数据,否则不要将溢出的数据写入磁盘,因为重新计算分区的速度可能与从磁盘读取分区一样快。
- 如果希望在服务器出故障时能够快速恢复,那么可以使用多副本存储MEMORY_ONLY_2 或MEMORY_AND_DISK_2。该存储级别在数据丢失后允许在RDD上继续运行任务,而不必等待重新计算丢失的分区。其他存储级别在发生数据丢失后,需要重新计算丢失的分区。
6.2 代码
持久化
val rdd = sc.parallelize(List(1,2,3,4,5,6,7))
rdd.persist()
持久化到磁盘
val rdd2 = rdd.map(_ * 10)
import org.apache.spark.storage.StorageLevel
rdd2.persist(StorageLevel.DISK_ONLY)
rdd2.collect()
取消持久化
rdd.unpersist()
6.3 Cache
cache就是默认存储级别,即MEMORY_ONLY的persist,而且不能修改存储级别
val rdd = sc.parallelize(List(1,2,3,4,5,6,7))
// 相当于rdd.persist()
rdd.cache()
rdd.collect()
7. Checkpoint
Checkpoint就是实时将RDD的数据存储到磁盘中,最好是存储到共享文件系统,例如HDFS,这样发生故障导致RDD数据丢失时,可以快速恢复,而不需要从头计算
7.1 与persist()的区别
persist()是将数据存储于机器本地的内存或磁盘,当机器发生故障时无法恢复,而Checkpoint是将RDD数据存储于外部的共享文件系统(例如HDFS),保证了数据的可靠性。- Spark执行结束后,
persist()的数据会被清空,而Checkpoint的数据不受影响,除非手动移除。因此,Checkpoint数据可被多个Spark程序使用,而persist()的数据只能被当前Spark程序使用。
使用
val sc = new SparkContext(conf)
sc.setCheckpointDir("hdfs://xxxxx")
val rdd = sc.parallelize(List(1,2,3,4,5,6,7))
rdd.collect()
rdd.checkpoint()
在将RDD标记为Checkpoint之前,最好先持久化到内存,因为Spark会单独启动一个任务将RDD的数据写入文件系统,如果数据已经持久化到内存,将直接从内存中读取并写入,否则需要重复计算RDD数据。
8. 共享变量
8.1 默认情况下数据的传递
val arr = Array(1, 2, 3, 4, 5)
val lines = sc.textFile("xxx")
lines.map(line => (line, arr)).collect()
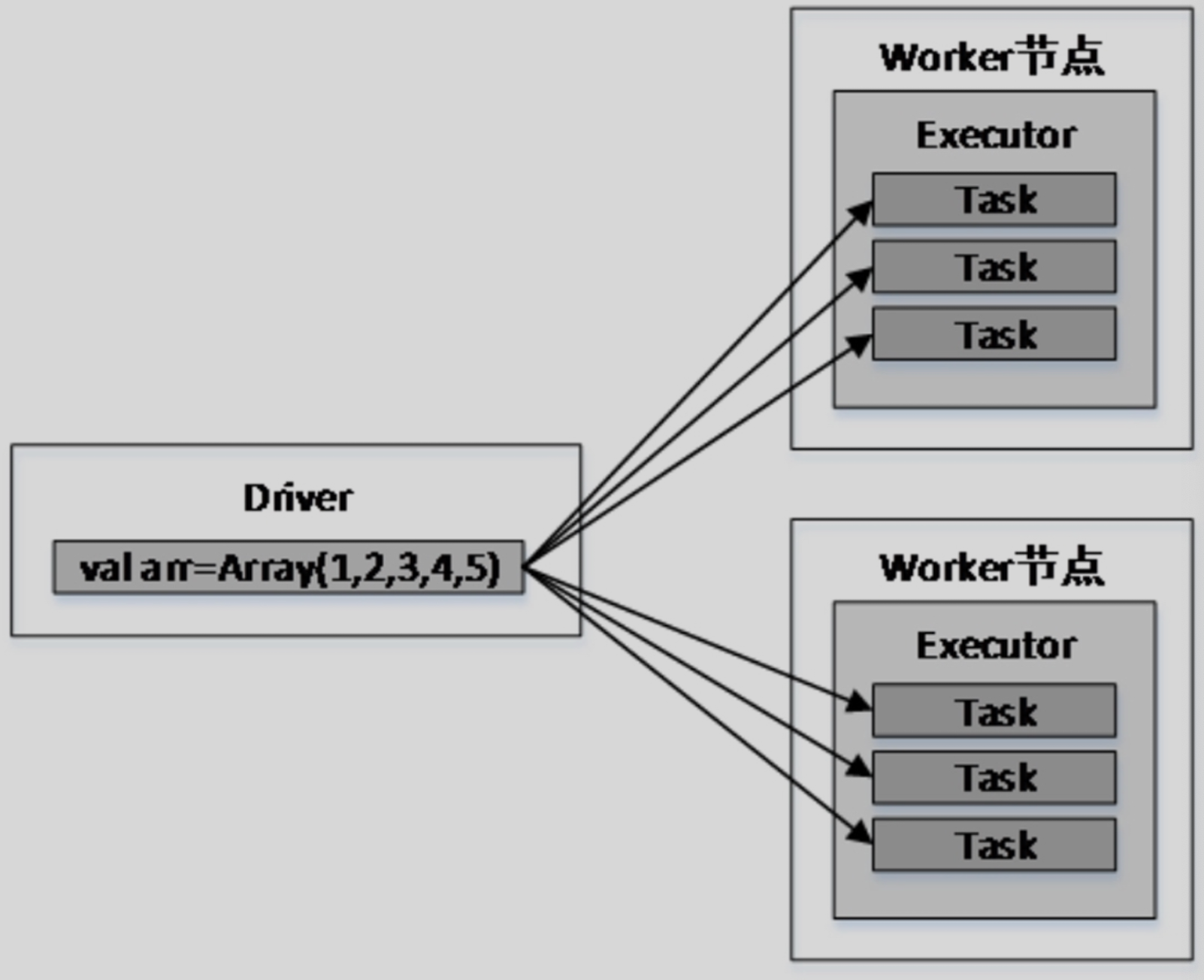
上述代码中,传递给map()算子的函数line =>(line,arr)会被发送到Executor执行,而变量arr将发送到Worker节点的所有Task中。变量arr传递的流程如图所示。
假设arr有100MB,则每一个Task都需要维护100MB的副本,若Executor中启动了3个Task,则该Executor将消耗300MB内存。
为解决上述问题,可使用广播变量
8.2 广播变量
val arr = Array(1, 2, 3, 4, 5)
val broadcastVar = sc.broadcast(arr)
val lines = sc.textFile("xxx")
lines.map(line => (line, broadcastVar)).collect()
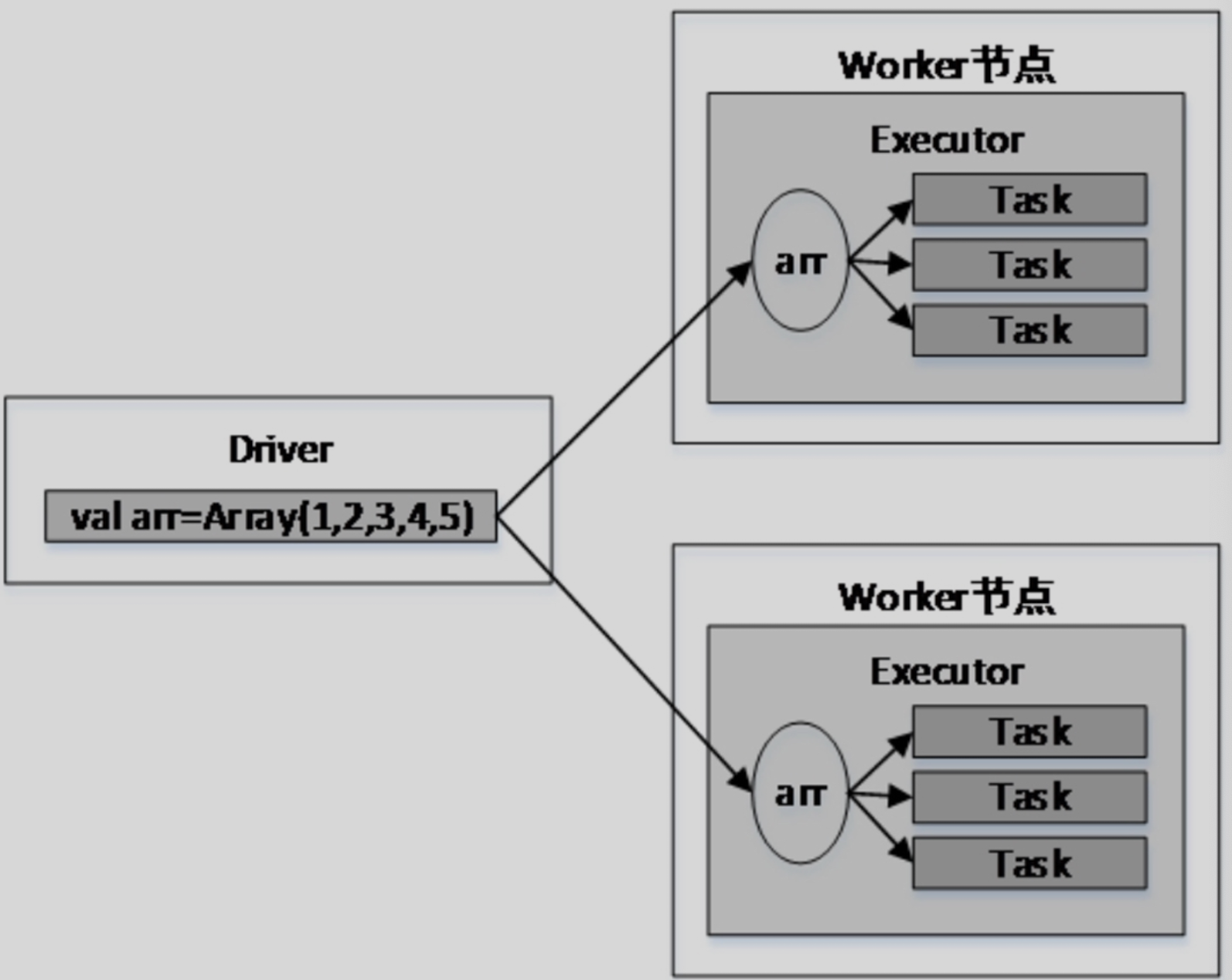
Worker的所有Task共享广播变量,大大减少了网络传输和内存开销。
8.3 累加器
查看下面这段代码
var sum = 0
val rdd = sc.makeRDD(Array(1, 2, 3, 4, 5))
rdd.foreach(item => sum +=item)
print(sum)
会发现结果是0,是因为sum在Driver中定义,而sum+=×是在Executor中执行,因此输出结
果不正确。
可使用累加器解决这个问题
val myAcc = sc.longAccumulator("My Accumulator")
val rdd = sc.makeRDD(Array(1, 2, 3, 4, 5))
rdd.foreach(item => myAcc.add(item))
print(myAcc.value)
除了longAccumulator还有doubleAccumulator
案例
1 统计单词出现个数
val sc = new SparkContext(conf)
val linesRdd = sc.textFile(args(0))
// 分割
val wordsRdd = linesRdd.flatMap(_.split(" "))
// map
val paresRdd = wordsRdd.map((_, 1))
// 统计单词出现个数
val wordCountsRdd = paresRdd.reduceByKey(_ + _)
// 对统计结果进行排序
val wordCountsSortRdd = wordCountsRdd.sortBy(_._2, false)
// 保存
wordCountsSortRdd.saveAsTextFile(args(1))
sc.stop()
2 RDD实现分组求TopN
统计并打印每个学生最高的三门成绩
val list = "Andy,98\nJack,87\nBill,99\nAndy,78\nJack,85\nBill,86\nAndy,90\nJack,88\nBill,76\nAndy,58\nJack,67\nBill,79".split("\n").toList
val scoreTxtRdd = sc.parallelize(list)
val scoreRdd = scoreTxtRdd.map(line => {
val lines = line.split(",")
val name = lines(0)
val score = lines(1)
(name, score.toInt)
})
val top3 = scoreRdd.groupByKey().map(data => {
val name = data._1
val scoreTop3 = data._2.toList.sortWith(_ > _).take(3)
(name, scoreTop3)
})
top3.collect()
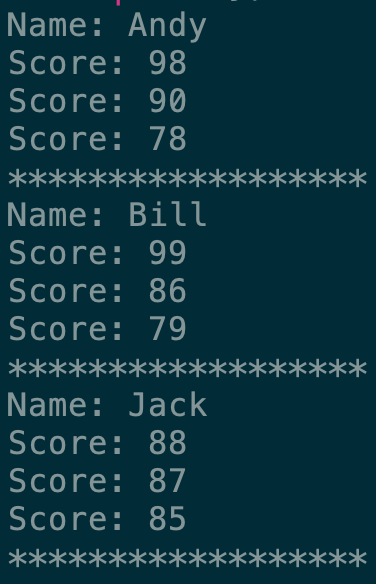
top3.foreach(data => {
println("Name: " + data._1)
data._2.foreach(data => {
println("Score: " + data)
})
println("******************")
})
3. 实现二次排序
首先按照第一个字段进行排序,若第一个字段相等,则按照第二个字段排序。
例如,文件sort.txt中有以下内容:
6 7
5 8
2 9
7 5
4 3
8 3
2 7
6 1
第一个字段升序,第二个字段降序,结果应该是
2 9
2 7
4 3
5 8
6 7
6 1
7 5
8 3
代码
// 自定义一个比较器存储KV对
class SecondSortPair(val first: Int, val second: Int)extends Ordered[SecondSortPair] with Serializable{
override def compare(that: SecondSortRule): Int = {
if(this.first != that.first){
this.first - that.first
} else {
that.second - this.second
}
}
}
def main(args: Array[String]): Unit = {
val list = "6 7\n5 8\n2 9\n7 5\n4 3\n8 3\n2 7\n6 1".split("\n").toList
val valTxtRdd = sc.parallelize(list)
val valRdd = valTxtRdd.map(line => {
val lines = line.split(" ")
val v1 = lines(0).toInt
val v2 = lines(1).toInt
(new SecondSortPair(v1, v2), line)
})
valRdd.sortByKey().collect().foreach(line=>println(line._2))
}
4. 计算平均分
四个文件输入,分别是科目和所有同学这门课的成绩,求出同学的平均分,期望输出如下
张三 80
李四 70
王五 60
赵六 67
代码
def list2Rdd(list: List[String]): org.apache.spark.rdd.RDD[(String, Int)] = {
sc.parallelize(list).map(data => {
val splits = data.split(" ")
val name = splits(0)
val score = splits(1).toInt
(name, score)
})
}
def main(args: Array[String]): Unit = {
val sc = new SparkContext()
val math = "张三 88\n李四 99\n王五 66\n赵六 77".split("\n").toList
val chinese = "张三 78\n李四 89\n王五 96\n赵六 67".split("\n").toList
val english = "张三 80\n李四 82\n王五 84\n赵六 86".split("\n").toList
val chemistry = "张三 78\n李四 23\n王五 34\n赵六 85".split("\n").toList
val mathRdd = list2Rdd(math)
val chineseRdd = list2Rdd(chinese)
val englishRdd = list2Rdd(english)
val chemistryRdd = list2Rdd(chemistry)
val joinedRdd = mathRdd.union(chineseRdd).
union(englishRdd).union(chemistryRdd)
val groupedRdd = joinedRdd.groupByKey()
groupedRdd.map(data => {
val scoreSum = data._2.sum
(data._1, scoreSum / 4)
}).collect()
}
9. 解决数据倾斜
9.1 定义
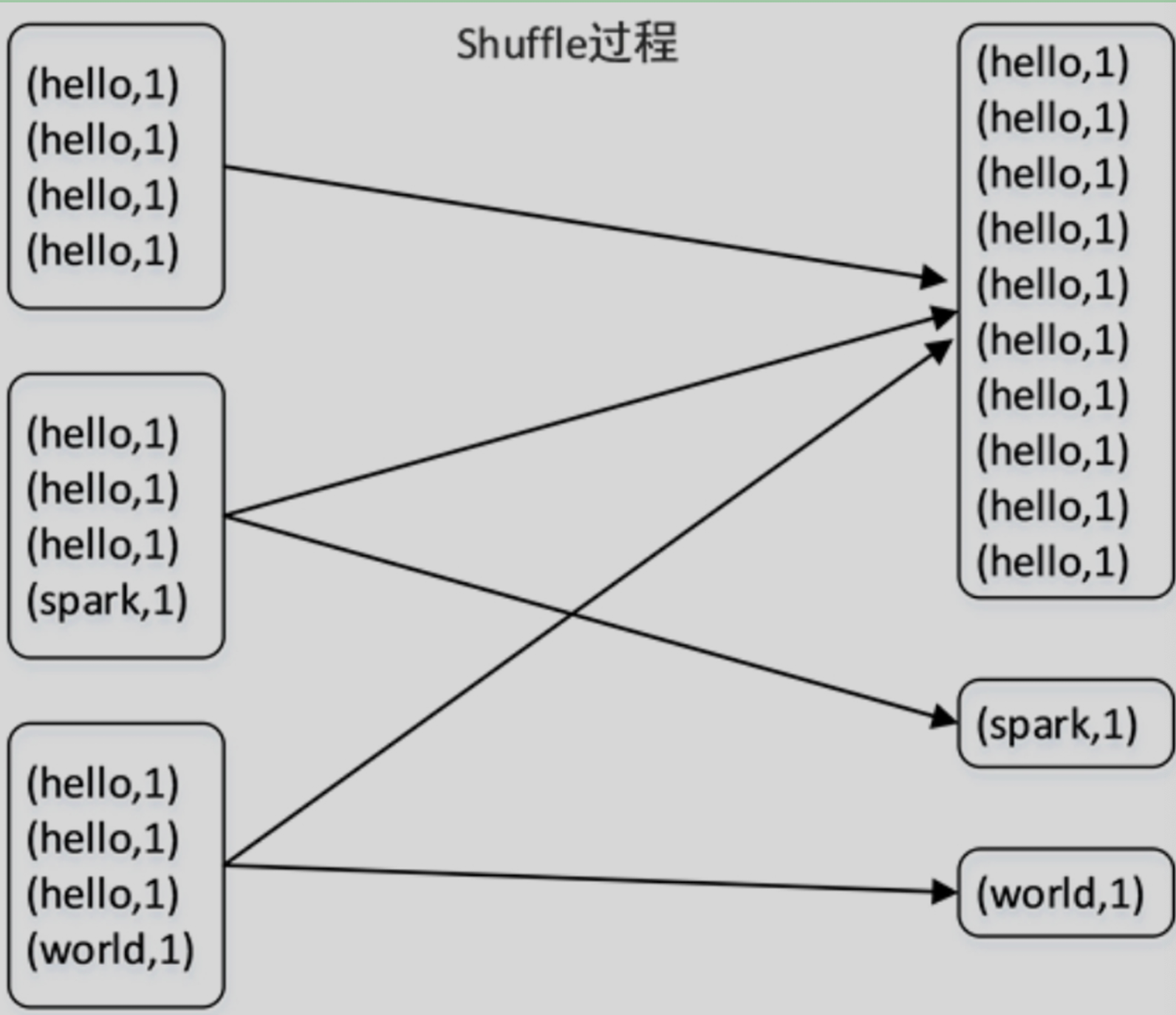
在shuffle过程中,出现了某个task要处理的数据远远多于其他task,导致出现大多数task空闲,而少数task十分繁忙的情况
如图所示,在Shuffle过程中,hello有10条数据,全部被分配到了同一个分区中,由同
一个Task来处理(一个Task处理一个分区),而剩余的两个分区中则分别只分配到了一条数据。若hello的数据量非常大,则将产生数据倾斜。
9.2 解决办法
-
数据预处理
假设数据来自于Hive,那么可以在Hive中对数据进行一次预处理,保证数据划分均匀。也可在Hive中提前对数据进行一次聚合,这样当数据传入Spark中后,不需要再次进行reduceByKey等聚合操作,没有了Shuffle阶段,就避免了数据倾斜。 -
过滤掉导致数据倾斜的key
如果产生数据倾斜的key没有意义
(比如存在很多key是_),那么可以在读取时直接用flter过滤掉,从而消除数据倾斜。 -
提高shuffle并行度
Shuffle过程涉及数据重组和重新分区。如果分区数量
(并行度)设置的不合适,就会造成大量不同的key被分配到同一个分区,导致某个Task处理的数据远多于其他Task,造成数据倾斜。可以在使用聚合算子
(例如groupByKey()、countByKey()、reduceByKey()等)时指定分区数量(并行度),让原本分配给一个Task的key分配给多个Task,减轻数据倾斜的影响。例如,在对某个RDD执行reduceByKey()算子时,可以传入一个参数,reduceByKey(20) ,指定Shuffle操作的并行度,也就是数据重组后的分区数量。
但是增加并行度,其实并不能彻底解决数据倾斜,对于一些极端情况,比如某个key的数据量有100万,那么无论Task的数量增加到多少,这个key的数据仍然会分配到一个分区,由一个Task处理,还是会发生数据倾斜。
-
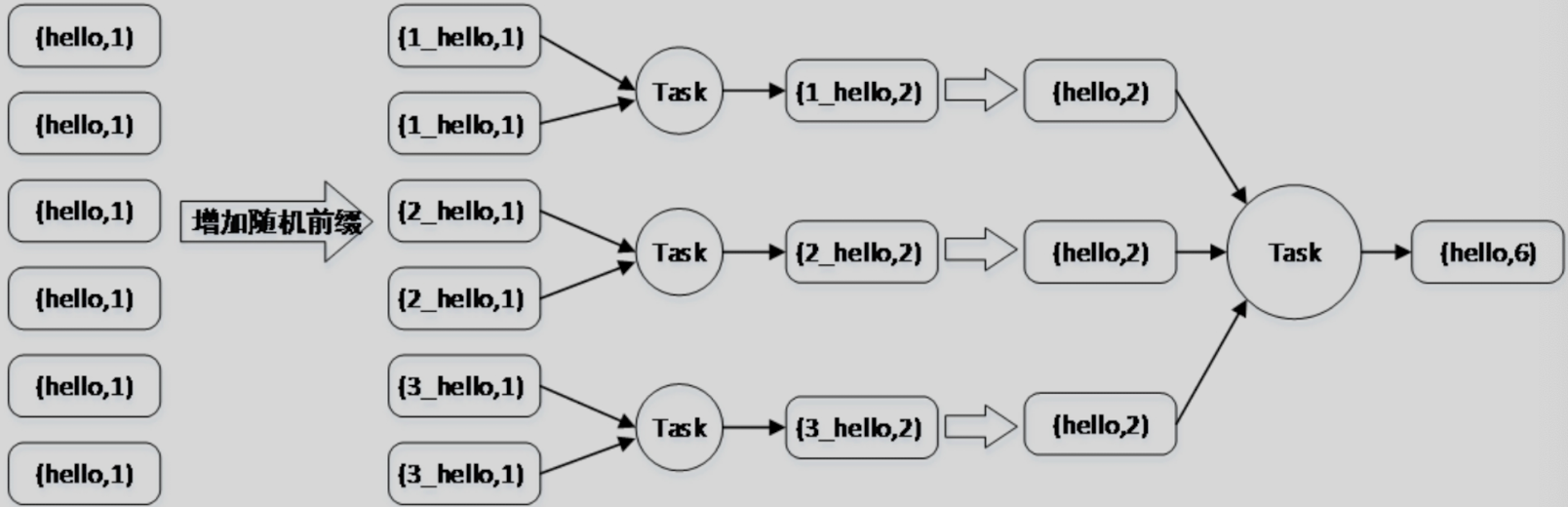
使用随机key进行双重聚合
在原本的key上追加随机数字作为前缀,将相同的key变为多个不同的key,这样可以让原本被分配到同一分区的key分散到多个分区,从而使用多个Task进行处理,解决单个Task数据量过多的问题。
之后去除掉随机前缀进行全局聚合,就可以得到最终的结果,从而避免数据倾斜。这种使用双重聚合避免数据倾斜的方式在Spark中适合
(groupByKey和reduceByKey)等聚合类算子,聚合原理如图。