Spark 使用遇到的问题
环境信息
IDEA版本:Build #IU-232.8660.185, built on July 26, 2023
系统版本:Macos 14.0
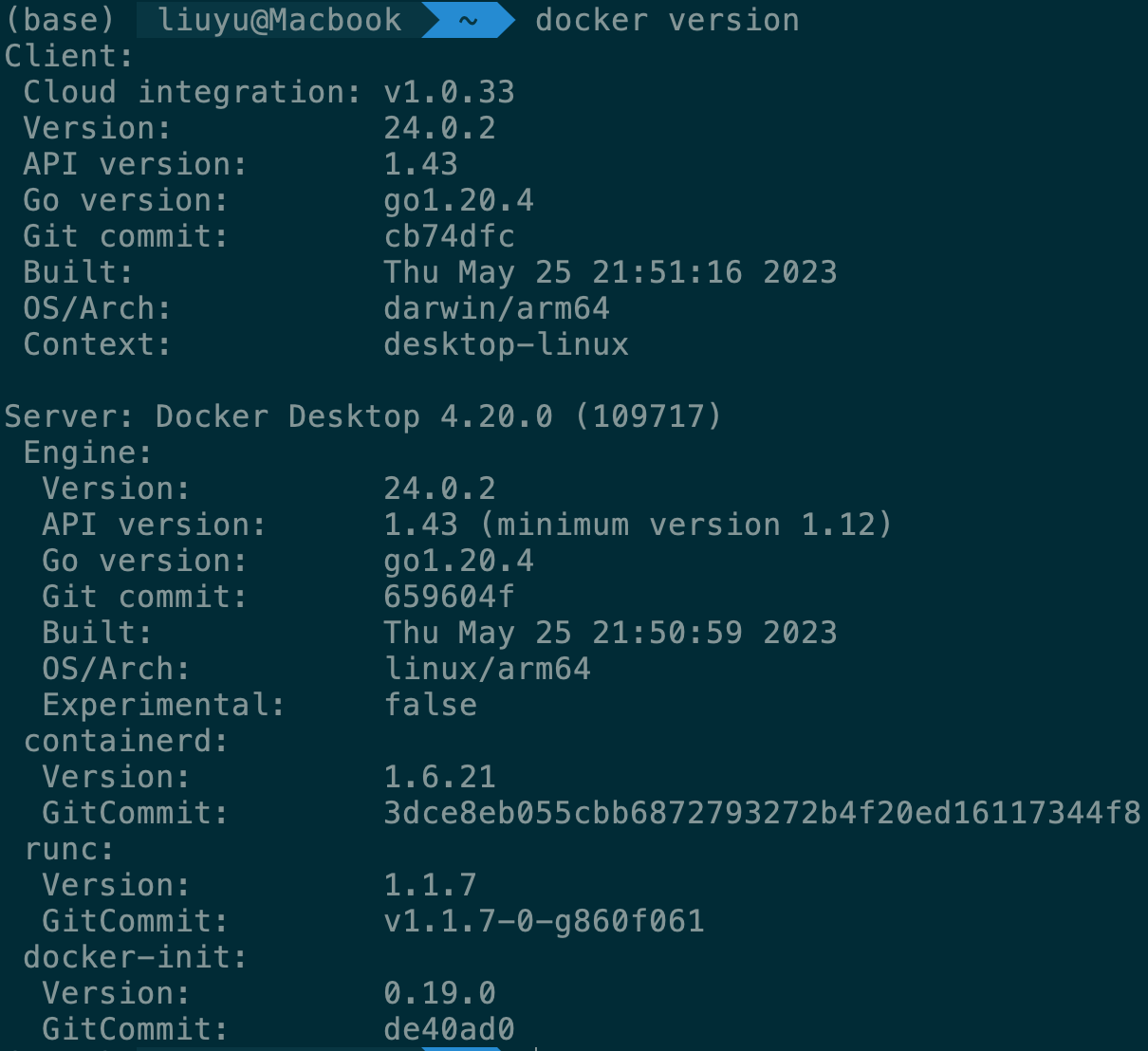
Docker版本:
一、Docker运行Spark集群
这里使用bitnami发行的spark image
github文档地址:https://github.com/bitnami/containers/tree/main/bitnami/spark#configuration
下载完成后,
-
在磁盘上随便找个地方创建一个文件夹,
-
新建一个文件,文件名必须是
docker-compose.yml -
文件内容如下
# Copyright VMware, Inc. # SPDX-License-Identifier: APACHE-2.0 version: '2' services: spark: image: docker.io/bitnami/spark:3.5 environment: - SPARK_MODE=master - SPARK_RPC_AUTHENTICATION_ENABLED=no - SPARK_RPC_ENCRYPTION_ENABLED=no - SPARK_LOCAL_STORAGE_ENCRYPTION_ENABLED=no - SPARK_SSL_ENABLED=no - SPARK_USER=spark ports: - '8080:8080' spark-worker: image: docker.io/bitnami/spark:3.5 environment: - SPARK_MODE=worker - SPARK_MASTER_URL=spark://spark:7077 - SPARK_WORKER_MEMORY=1G - SPARK_WORKER_CORES=1 - SPARK_RPC_AUTHENTICATION_ENABLED=no - SPARK_RPC_ENCRYPTION_ENABLED=no - SPARK_LOCAL_STORAGE_ENCRYPTION_ENABLED=no - SPARK_SSL_ENABLED=no - SPARK_USER=sparkimage版本必须和你的一致,比如说我的image版本是

那就修改成
image: docker.io/bitnami/spark:3.5.0-debian-11-r9 -
启动Spark
打开命令符,进入文件所在目录,单worker启动
docker-compose up启动多个worker
docker-compose up --scale spark-worker=3
二、IDEA 2023创建Scala Maven项目
-
新建一个项目,选择
IntelliJBuild System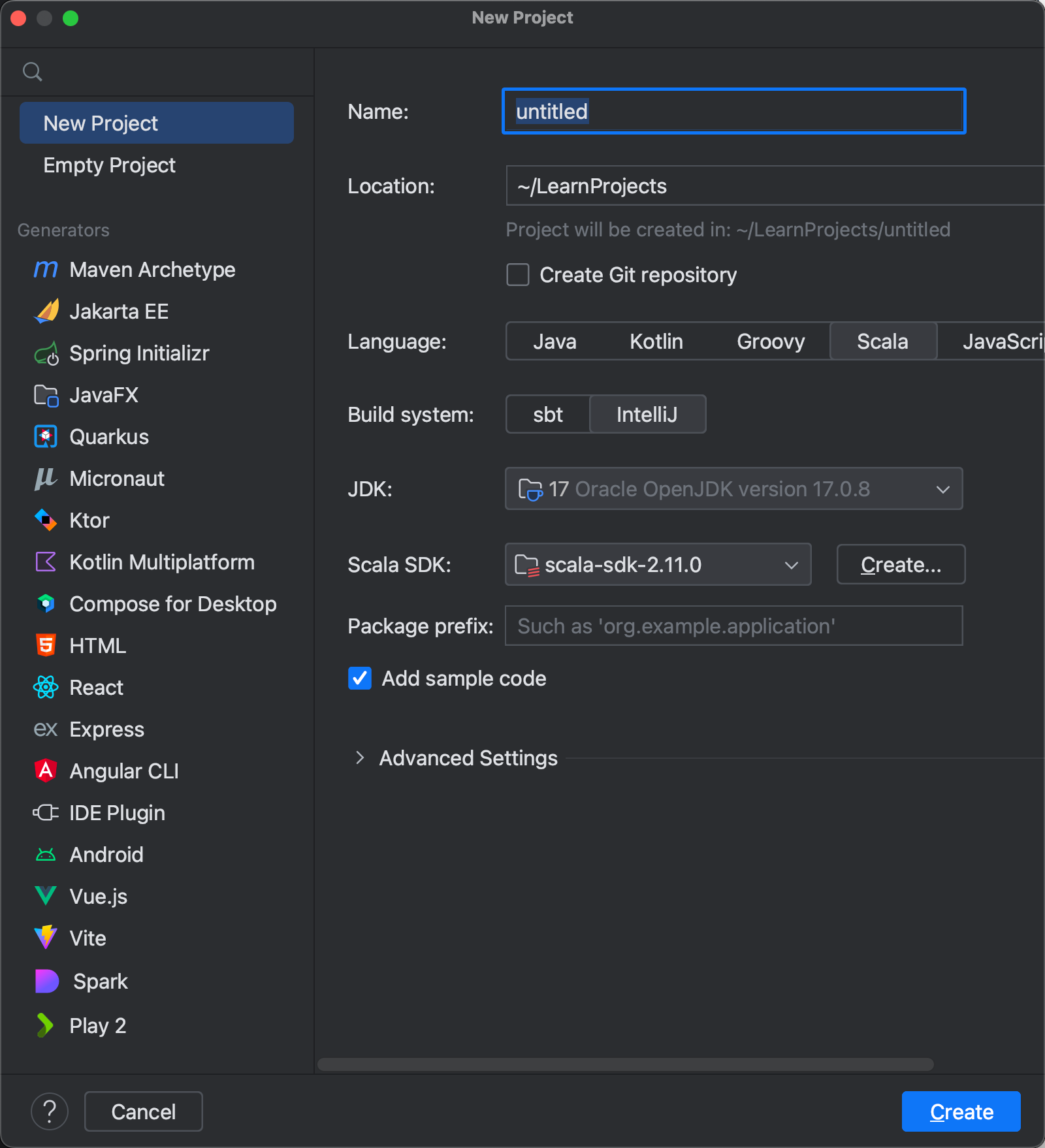
-
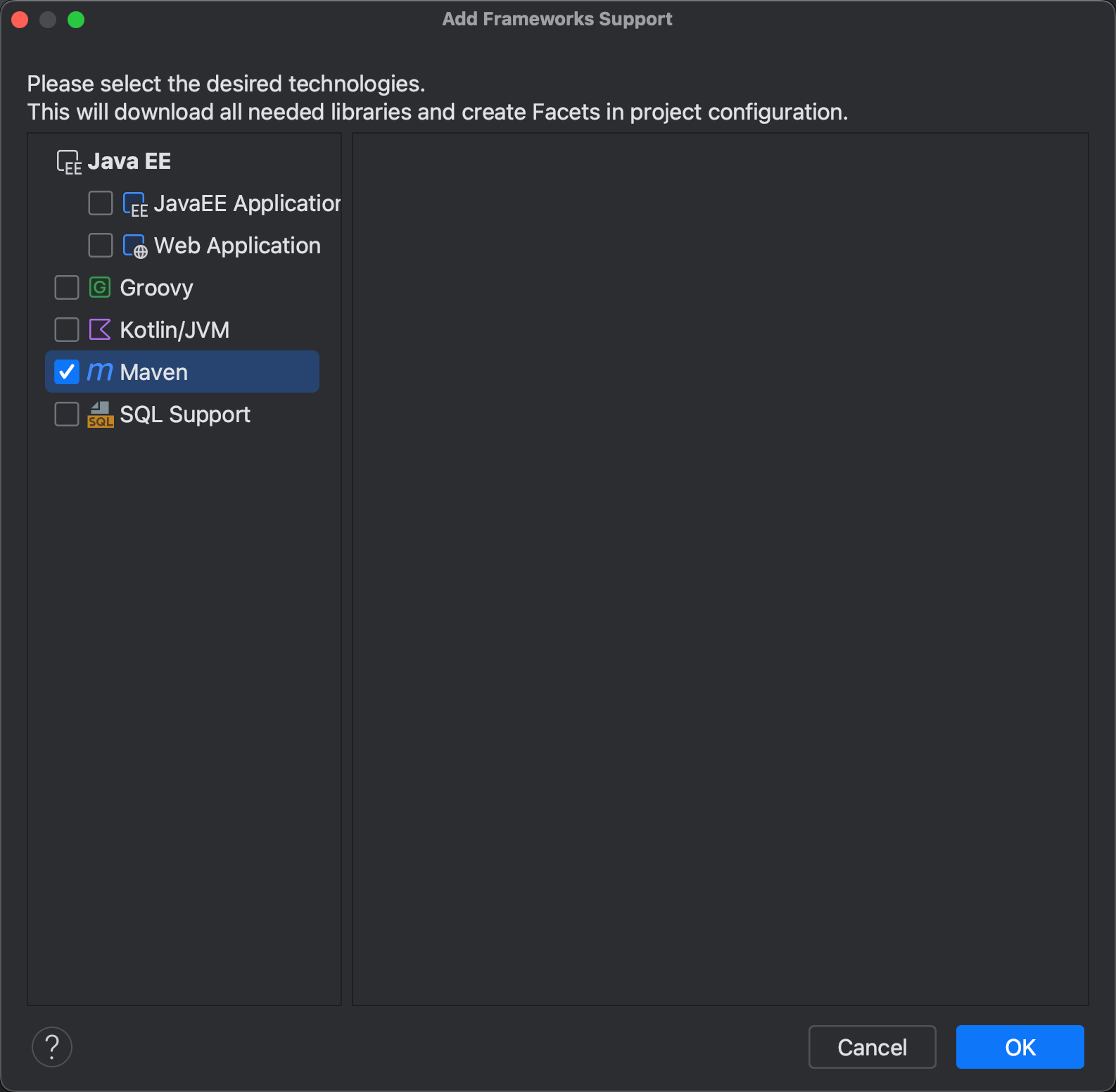
右上角搜索
Add Framework Support
-
然后添加Maven即可
三、IDEA连接Docker Spark
-
IDEA新建一个Maven Scala项目
-
添加如下依赖
<dependencies> <dependency> <groupId>org.scala-lang</groupId> <artifactId>scala3-library_3</artifactId> <version>3.3.1</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.13</artifactId> <version>3.5.0</version> </dependency> </dependencies> -
查看Spark启动日志,获取Master运行端口,我这里是7077

-
也可进入Spark WebUI地址查看,WebUI默认地址
http://localhost:8080/,URL后面的端口值即为Master运行端口
-
编写Spark代码
def main(args: Array[String]): Unit = { val conf = new SparkConf() conf.setAppName("myapp") conf.setMaster("spark://localhost:7077") val sc = new SparkContext(conf) val rdd = sc.parallelize(List(1, 2, 3, 4, 5, 6)) print(rdd) }注意Master的地址,把7077改成你的端口即可,
不要修改localhost -
运行后可能会报错
Exception in thread "main" java.lang.IllegalAccessError: class org.apache.spark.storage.StorageUtils$ (in unnamed module @0x55b0dcab) cannot access class sun.nio.ch.DirectBuffer (in module java.base) because module java.base does not export sun.nio.ch to unnamed module @0x55b0dcab at org.apache.spark.storage.StorageUtils$.<clinit>(StorageUtils.scala:213) at org.apache.spark.storage.BlockManagerMasterEndpoint.<init>(BlockManagerMasterEndpoint.scala:121) at org.apache.spark.SparkEnv$.$anonfun$create$9(SparkEnv.scala:358) at org.apache.spark.SparkEnv$.registerOrLookupEndpoint$1(SparkEnv.scala:295) at org.apache.spark.SparkEnv$.create(SparkEnv.scala:344) at org.apache.spark.SparkEnv$.createDriverEnv(SparkEnv.scala:196) at org.apache.spark.SparkContext.createSparkEnv(SparkContext.scala:284) at org.apache.spark.SparkContext.<init>(SparkContext.scala:483) at Main$.main(Main.scala:9) at Main.main(Main.scala)需要修改运行设置
Modify Options-->Add VM Options--> 添加下面语句--add-exports java.base/sun.nio.ch=ALL-UNNAMED之后运行即可