Personalized Transformer for Explainable Recommendation论文阅读笔记
摘要
自然语言生成的个性化在大量任务中都起着至关重要的作用。比如可解释的推荐,评审总结和对话系统等。在这些任务中,用户和项目ID是个性化的重要标识符。虽然Transfomer拥有强大的语言建模能力,但是没有个性化,并且难以利用这些ID。因为ID标记和文字完全不在同一个语义空间上。
为了解决这个问题,我们提出了个性化的Transformer(PETER)。设计了一个简单而有效的任务,即利用ID来预测需要被生成的解释中的单词。从而使ID具有语言学意义。并且使Transformer变得个性化。除了生成解释之外,PETER还可以做推荐,有效的统一推荐和解释两大任务。未训练的小模型在生成任务和效率方面都优于微调的BERT,突出了设计的重要性和良好的实用性。
介绍
许多程序需要一定城的的个性化比如可解释的推荐等。在这些任务中,区分一个用户/项目与其他项目的用户和项目id对个性化至关重要。
例如在推荐系统中不同的用户可能会关心不同的项目特征,而不同的项目可能会有不同的特征。
可推荐解释的目的就是向用户提供推荐项目的解释,以证明推荐如何符合用户的兴趣。也就是说,给定一对用户ID和项目ID,系统需要生成一个解释比如夹克的风格很时尚。
Transformer的语言建模能力很强大,但是目前对个性化自然语言生成的探索相对不足。id和词语是在非常不同的语义空间中,直接将它们放到一起进行注意力学习是有问题的。因为id出现的频率远低于单词。
为了解决这个问题,我们设计了一个上下文预测的任务来连接ID和单词。该任务将id映射到由解释任务生成的单词上。然后,解释生成认为对这些单词进行修饰,形成一个可读的句子。同时,我们证明了在同一模型上进行推荐任务也是可行的。所以我们提出PETER,当PETER对同一个用户-项目对生成解释时,它可以同时利用用户和项目的信息。这说明了我们上下文预测的有效性。
此外,PETER可以灵活的合并项目特性,这可以帮助指导它的生成。这些非常有用。
总结一下,这个模型主要的贡献是:
- PETER根据用户和项目id同时提出推荐和生成解释,以获得可解释的推荐。这篇文章是第一个使Transformer生成个性化自然语言。
- 不仅根据文本质量指标评估生成的解释,还特别关注评估从项目特征的角度出发的可解释性
- 解决方案揭示了更广泛的、同样需要个性化的领域。它还指出了一种可供Transformer处理异构输入的方法。例如在多模态人工智能中的文本和图像。
问题定义
我们解释任务的目标是生成一个自然语言的句子\(\hat{E_{u.i}}\),对每一对用户u和项目i
来证明为什么i会被推荐给u。模型PETER也可以通过估计评级\(\hat{r}_{u,i}\)来提出u对i偏好的预测。在测试阶段,只有u和i会被用作产生解释和推荐的输入。当项目的特性\(F_{u,i}\)可用时,我们的模型可以灵活地通过在解释开始时将它们简单地连接起来来合并它们。
方法
模型的总体框架如下:
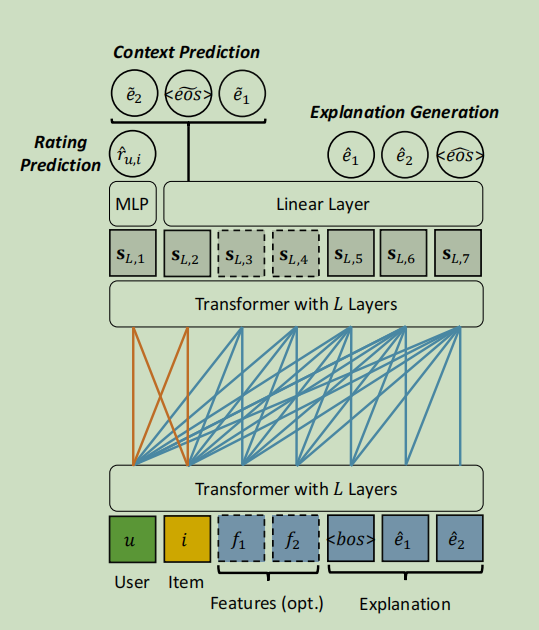
我们定义了三个任务:
- 解释生成
- 上下文预测
- 推荐
最后将其集成到一个多任务学习框架中。
1.输入表示
首先介绍将异构输入编码为向量表示的方法。输入是一个包含用户id,项目id和特征以及解释的序列。用户和项目的服务于个性化的目的。旨在使生成解释的同时反映用户的兴趣和项目的属性。特征\(F_{u,i}\)可以指导模型讨论某些主题。但是特征并不总是可用的,所以在实验中我们测试了有和没有特征的两种情况。
显然,序列S中有三种类型的标记,用户,项目和单词,包括特征。所以准备了三组随机初始化的token embedding U,I和V。此外编码序列中每个标记的位置的位置嵌入记为P。没有将用户和项目添加到词汇表V中,因为从大量的id中预测一个单词需要花费很多的时间。在执行嵌入的查找(lookup)后,我们可以得到序列的标记表示\([u,i,f_1,...,f_{|F_{u,i}|},e_1,...,e_{|E_{u,i}|}]\)。以及位置表示\([P1,...,P_{|S|}]\),其中\(|S|\)是序列的长度。输入序列的表示是相应的标记表示和位置表示的累加。记为\(S_0=[s_{0,1},...,s_{0,|S|}]\)
2.Transformer和注意力Mask
为了实现三个目标,我们展示了如何对Transformer修改注意力掩码机制。Transformer由L个相同层组成,每个层由两个子层组成,多头自注意和位置前馈网络。第l层将前一层输出的\(S_{l-1}\)编码为\(S_l\)。多头注意力机制中,每个注意头的计算也相同。在第l层的H头中,第h个头\(A_{l,h}\)的计算如下:
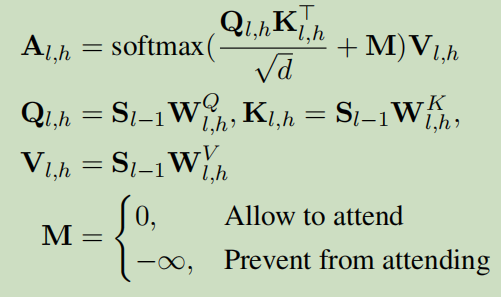
M的每个元素控制序列中的一个标记是否可以处理另一个标记。例如在单从左到右语言模型中,M的下三角部分设置为0,其余部分为\(-\infin\)允许每个token关注包括自身的过去的token。防止其关注未来的token。我们称为从左到右的mask。但是我们的模型并不局限于从左到右的解释任务。所以我们修改了掩码机制,来适应其他两个任务。序列中的前两个标记u和i可以互相关注,因为上下文预测和推荐任务都需要它们。我们称这种模型为PETER mask
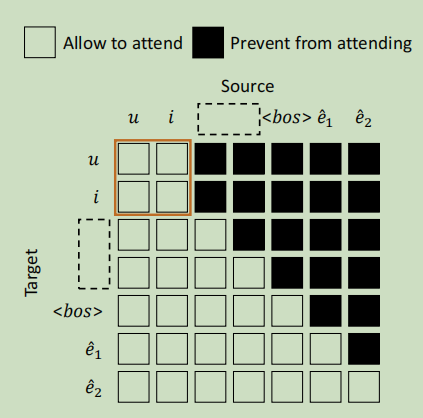
解释和推荐
得到序列的最终表示后,要执行三个任务,关键挑战在于解释生成任务的个性化。我们设计了上下文预测任务。对于这两个任务。我们将最终的标记表示应用一个线性层,将其映射到一个|V|大小的向量中,通过这一层后,\(S_{L,t}\)变成\(c_t\)
\(c_t=softmax(W^vS_{L,t}+b^v)\)
向量\(c_t\)表示词汇表V上的概率分布,可以从中采样一个单词e的概率\(c_t^e\)
下面是三个任务的具体方法
解释生成
采用负对数似然法作为解释任务的损失函数,并在训练中采用用户项目对的平均值。
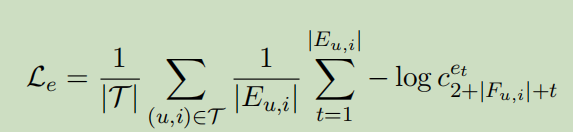
\(\tau\)表示训练集,概率\(c_t^{e_t}\)位置偏移\(2+|F_{u,i}|\)因为解释是在序列的结尾部分。当Explaination不可用时\(|F_{u,i}|=0\)
在测试阶段,我们和u,i,\(F_{u,i}\)一起,为模型提供一个特殊的开始序列标记
上下文预测
只有一个解释生成任务时,Transformer无法使用用户ID和项目ID,这样会导致相同的句子。我们设计了上下文预测的任务来将映射到解释的单词上,以便于在它们之间建立连接。由于序列的前两个位置被允许互相关注,它们的最终表示都吸收了用户和项目的信息。因此可以使用其中任何一个来执行上下文预测这个任务。
同样也采用NLL作为损失函数
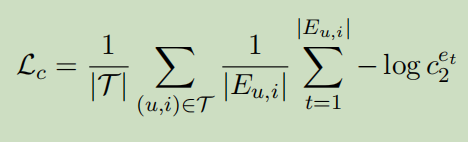
所有被预测的词都来自第二个位置
评级预测(也就是推荐了)
推荐可以被视为一个预测任务,目标是预测基于用户u和项目i的IDs的预测分数\(\hat{r_{u,i}}\)。因为u和i可以互相关注,所以它们的最终表示捕获了它们之间的相互作用。接下来将第一个表示\(S_{L,1}\)映射为一个标量,为此我们采用有一个隐藏层的多层感知机
\(\hat{r_{u,i}}=w^r\sigma(W^rs_{L,1}+\mathcal{b}^r)+b^r\)
由此可以看出,对Transformer同时进行推荐和解释都是可行的。推荐不是本文的重点,改进留到以后的工作中。对于这个任务,我们采用均方误差作为损失函数
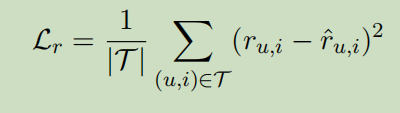
多任务学习
最后,我们将这三个任务整合到一个学习框架中,目标函数的定义为:
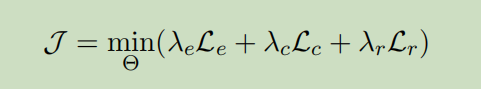
总结
这篇文章提出了一个简单和有效的解决方案来解决Transformer的个性化生成问题,释放其语言建模能力来为推荐系统生成解释。大量实验表明,该解释是有效和高效的。开辟了一种利用Transformer的新方法。
标签:解释,Transformer,用户,生成,任务,Recommendation,Personalized,ID From: https://www.cnblogs.com/anewpro-techshare/p/17751965.html