简介
学习简单、轻量级、易扩展、动态生效、调度中心HA、执行器HA、弹性扩容缩容、路由策略、故障转移、阻塞处理策略、任务超时控制、任务失败重试、任务失败告警、分片广播任务、动态分片、事件触发等很多特性。
使用
下载源码
项目源码结构如下
- xxl-job-admin:调度中心
- xxl-job-core:公共依赖
- xxl-job-executor-samples:执行器Sample示例;
- xxl-job-executor-sample-springboot:Springboot版本,通过Springboot管理执行器,推荐这种方式;
- xxl-job-executor-sample-frameless:无框架版本;
部署时,调度中心单独部署,samples中代码可集成到项目中进行使用。
初始化表结构
doc/db/tables_xxl_job.sql
- xxl_job_lock:任务调度锁表;
- xxl_job_group:执行器信息表,维护任务执行器信息;
- xxl_job_info:调度扩展信息表: 用于保存XXL-JOB调度任务的扩展信息,如任务分组、任务名、机器地址、执行器、执行入参和报警邮件等等;
- xxl_job_log:调度日志表: 用于保存XXL-JOB任务调度的历史信息,如调度结果、执行结果、调度入参、调度机器和执行器等等;
- xxl_job_log_report:调度日志报表:用户存储XXL-JOB任务调度日志的报表,调度中心报表功能页面会用到;
- xxl_job_logglue:任务GLUE日志:用于保存GLUE更新历史,用于支持GLUE的版本回溯功能;
- xxl_job_registry:执行器注册表,维护在线的执行器和调度中心机器地址信息;
- xxl_job_user:系统用户表;
linux下部署
主要是 xxl-job-admin 项目,修改 application.properties 配置文件中的
spring.datasource.url=jdbc:mysql://127.0.0.1:3306/xxl_job?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&serverTimezone=Asia/Shanghai
spring.datasource.username=root
spring.datasource.password=root_pwd
xxl.job.accessToken=default_token # 设置为空 表示客户端连接时不需要token
配置自己服务器的mysql地址及账号密码。
package之后上传到linux,具体部署过程查看 https://note.youdao.com/s/As8NwaON 的步骤创建SpringBoot项目的镜像的Dockerfile,将打包好的jar文件拷贝到容器中。
使用docker部署
docker pull xuxueli/xxl-job-admin:2.3.0
docker run -d -e PARAMS=" \
--spring.datasource.url=jdbc:mysql://42.192.20.119:3310/xxl_job?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&serverTimezone=Asia/Shanghai \
--spring.datasource.username=root \
--spring.datasource.password=abdyou000 --xxl.job.accessToken=" \
-p 8088:8080 --name xxl-job-admin xuxueli/xxl-job-admin:2.3.0
访问地址为 http://42.192.20.119:8088/xxl-job-admin 默认账号密码为 admin/123456
后台页面增加执行器和任务
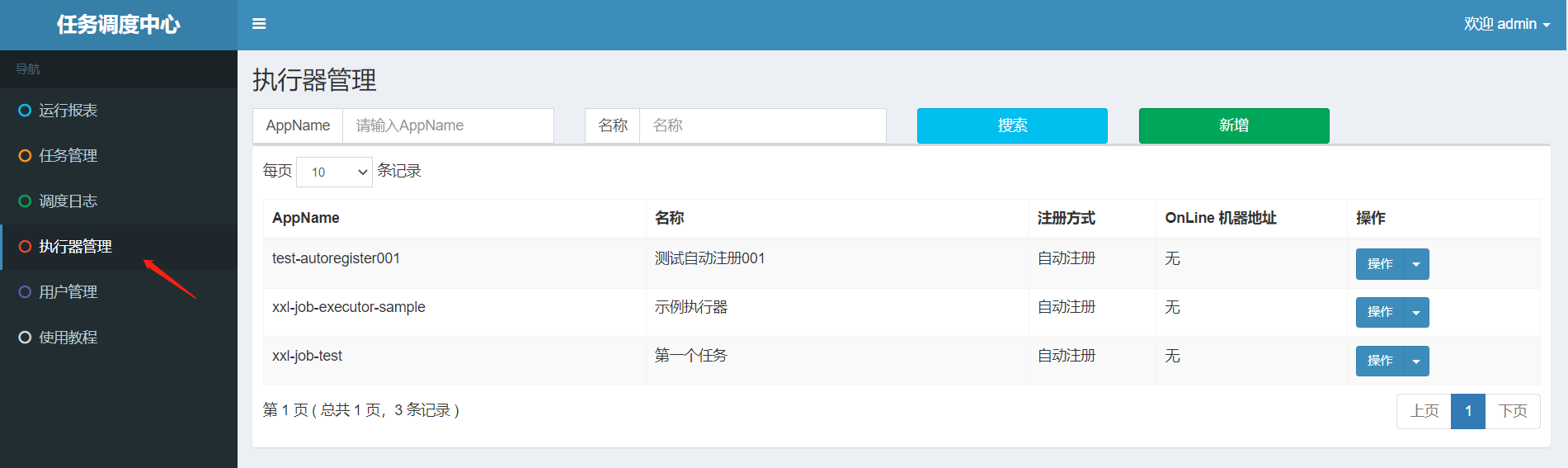
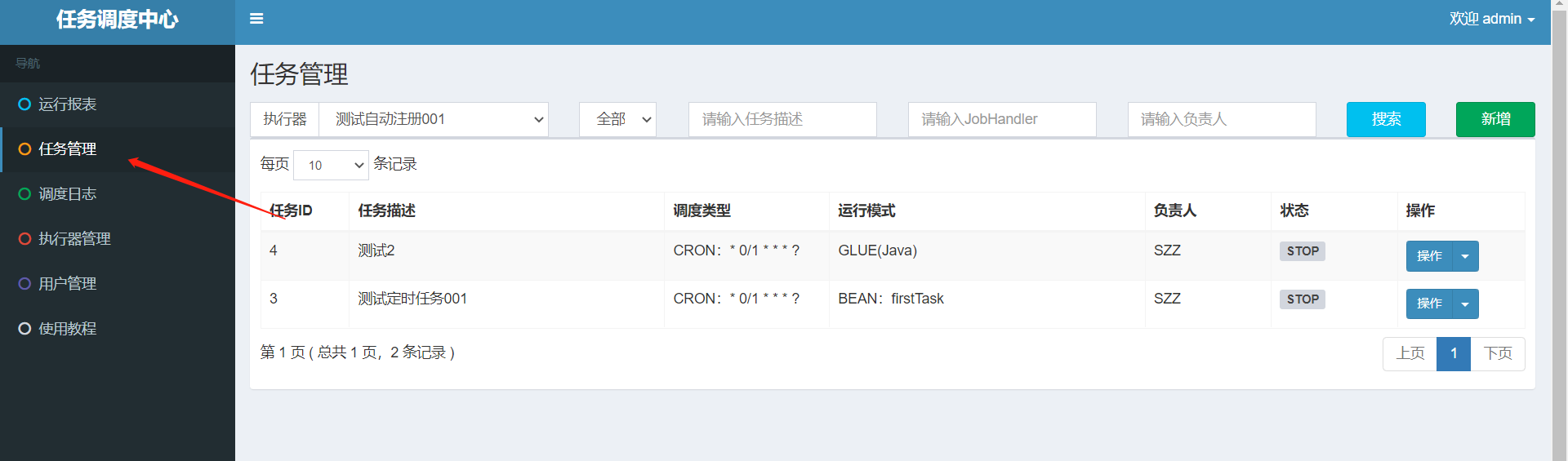
业务端增加handler
xxl:
job:
admin:
addresses: http://localhost:8080/xxl-job-admin
spring:
application:
name: cnblogs
@ConfigurationProperties(prefix = "xxl.job")
@Data
public class XxlJobProperties {
private Admin admin = new Admin();
private String accessToken = "";
private String appName;
private String address = "";
private String ip = "";
private int port = new Random().nextInt(1001) + 9000;
private String logPath = "/data/applogs/xxl-job/jobhandler";
private int logRetentionDays = 7;
@Data
public static class Admin {
private String addresses;
}
}
@Configuration
@EnableConfigurationProperties(XxlJobProperties.class)
public class XxlJobConfig {
@Value("${spring.application.name}")
private String applicationName; //对应后台的执行器名称
@Bean
public XxlJobSpringExecutor xxlJobExecutor(XxlJobProperties xxlJobProperties) {
XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor();
xxlJobSpringExecutor.setAdminAddresses(xxlJobProperties.getAdmin().getAddresses());
xxlJobSpringExecutor.setAppname(StringUtils.isEmpty(xxlJobProperties.getAppName()) ? applicationName : xxlJobProperties.getAppName());
xxlJobSpringExecutor.setAddress(xxlJobProperties.getAddress());
xxlJobSpringExecutor.setIp(xxlJobProperties.getIp());
xxlJobSpringExecutor.setPort(xxlJobProperties.getPort());
xxlJobSpringExecutor.setAccessToken(xxlJobProperties.getAccessToken());
xxlJobSpringExecutor.setLogPath(xxlJobProperties.getLogPath());
xxlJobSpringExecutor.setLogRetentionDays(xxlJobProperties.getLogRetentionDays());
return xxlJobSpringExecutor;
}
}
@Component
public class MyFirstTask {
@XxlJob("firstTask") //Bean名称对应后台任务的JobHandler
public void myFirstTaskHandler() {
String jobParam = XxlJobHelper.getJobParam();
System.out.println("jobParam=" + jobParam);
System.out.println("Hello XXL-Job");
}
}
原理
后台任务执行
- JobTriggerPoolHelper的trigger()方法
- XxlJobTrigger的runExecutor()方法
- ExecutorBizClient的run()方法
- 调用了客户端的 http://addressUrl/run 接口
- JobApiController来接收客户端的注册或其他接口
- JobRegistryHelper用来检查xxl_job_registry中在线的客户端,并更新xxl_job_group的address_list字段
<select id="findDead" parameterType="java.util.HashMap" resultType="java.lang.Integer" >
SELECT t.id
FROM xxl_job_registry AS t
WHERE t.update_time <![CDATA[ < ]]> DATE_ADD(#{nowTime},INTERVAL -#{timeout} SECOND)
</select>
上述sql用来查询已不在线的客户端,每隔30秒检查一次,90秒还未更新时间说明已不在线。
后台启动流程
- XxlJobAdminConfig开始
- XxlJobScheduler来初始化各种组件
- i18n
- JobTriggerPoolHelper,任务执行器,内部包含快慢线程池(如果一次执行超过500ms切一分钟内执行超过10次,就是用慢线程池)
- JobRegistryHelper用来更新每一个appName对应的客户端列表,且用来处理客户端发来的注册请求
- JobLogReportHelper,每分钟执行一次,查询任务执行日志并创建日志报表记录
- JobScheduleHelper用来处理定时任务,分两步,第一步查询出快到执行时间的任务,第二步执行任务。通过
select * from xxl_job_lock where lock_name = 'schedule_lock' for update;
xxl-job通过mysql悲观锁实现分布式锁,从而避免多个服务器同时调度任务。
客户端
- XxlJobSpringExecutor在Bean初始化时处理所有包含@XxlJob注解的方法的Bean
- EmbedServer的start()会使用netty开启服务端
- EmbedHttpServerHandler来接收网页后台的请求
- ExecutorBizImpl的run()方法来处理执行Bean的业务处理
- JobThread来运行真正的任务逻辑,每次执行再开启一个单独的线程
- ExecutorRegistryThread线程向后台服务注册当前客户端
时间轮
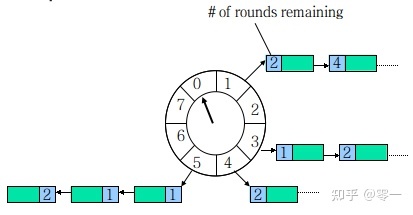
将一段时间分成相等的时间,每个相等的时间关联着任务。
总结
内部使用了很多线程和线程池来处理各种逻辑,使用SpringGlueFactory(内部使用GroovyClassLoader)来解析glue代码。
官方文档
深入xxl-Job源码分析