近来,大语言模型 (LLM) 已被证明是提高编程、内容生成、文本分析、网络搜索及远程学习等诸多领域生产力的可靠工具。
大语言模型对用户隐私的影响
尽管 LLM 很有吸引力,但如何保护好 输入给这些模型的用户查询中的隐私 这一问题仍然存在。一方面,我们想充分利用 LLM 的力量,但另一方面,存在向 LLM 服务提供商泄露敏感信息的风险。在某些领域,例如医疗保健、金融或法律,这种隐私风险甚至有一票否决权。
一种备选解决方案是本地化部署,LLM 所有者将其模型部署在客户的计算机上。然而,这不是最佳解决方案,因为构建 LLM 可能需要花费数百万美元 (GPT3 为 460 万美元),而本地部署有泄露模型知识产权 (intellectual property, IP) 的风险。
Zama 相信有两全其美之法: 我们的目标是同时保护用户的隐私和模型的 IP。通过本文,你将了解如何利用 Hugging Face transformers 库并让这些模型的某些部分在加密数据上运行。完整代码见 此处。
全同态加密 (Fully Homomorphic Encryption,FHE) 可以解决 LLM 隐私挑战
针对 LLM 部署的隐私挑战,Zama 的解决方案是使用全同态加密 (FHE),在加密数据上执行函数。这种做法可以实现两难自解,既可以保护模型所有者知识产权,同时又能维护用户的数据隐私。我们的演示表明,在 FHE 中实现的 LLM 模型保持了原始模型的预测质量。为此,我们需要调整 Hugging Face transformers 库 中的 GPT2 实现,使用 Concrete-Python 对推理部分进行改造,这样就可以将 Python 函数转换为其 FHE 等效函数。
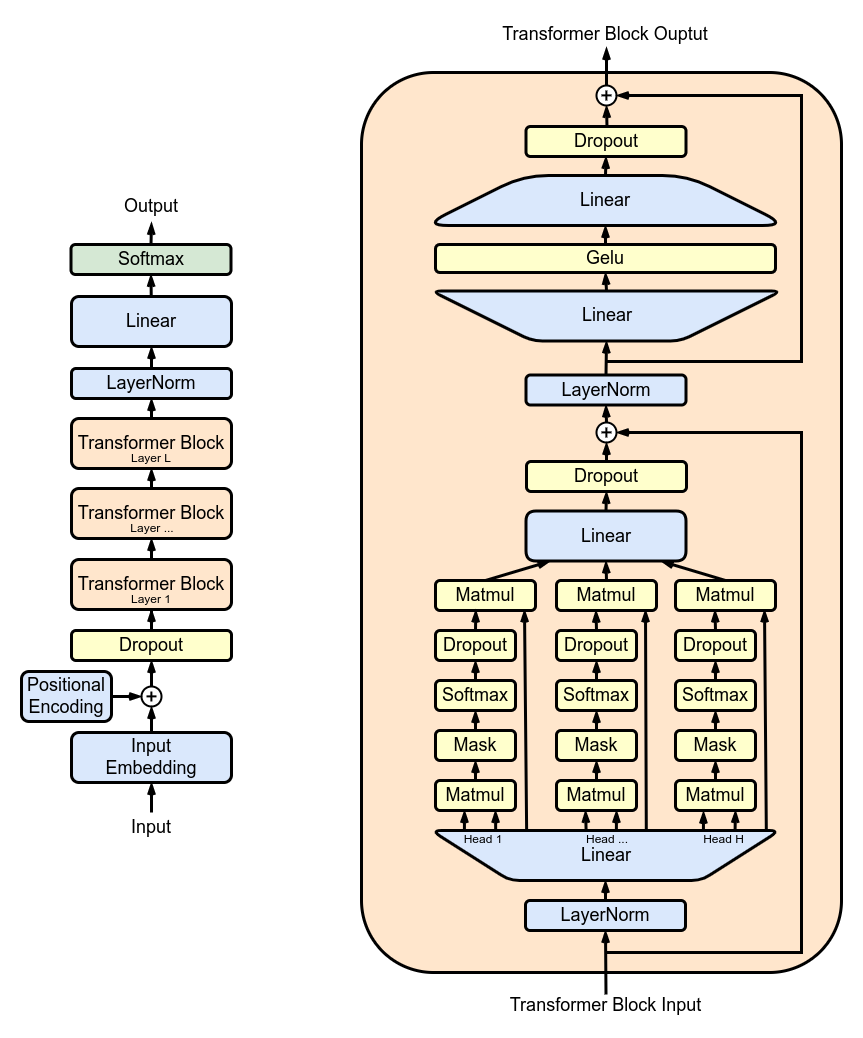
图 1 展示了由多个 transformer block 堆叠而成的 GPT2 架构: 其中最主要的是多头注意力 (multi-head attention,MHA) 层。每个 MHA 层使用模型权重来对输入进行投影,然后各自计算注意力,并将注意力的输出重新投影到新的张量中。
在 TFHE 中,模型权重和激活均用整数表示。非线性函数必须通过可编程自举 (Programmable Bootstrapping,PBS) 操作来实现。PBS 对加密数据实施查表 (table lookup,TLU) 操作,同时刷新密文以支持 任意计算。不好的一面是,此时 PBS 的计算时间在线性运算中占主导地位。利用这两种类型的运算,你可以在 FHE 中表达任何子模型的计算,甚至完整的 LLM 计算。
使用 FHE 实现 LLM 的一层
接下来,你将了解如何加密多头注意力 (MHA) 中的一个注意力头。你可以在 此处 找到完整的 MHA 实现代码。

图 2 概述了一个简化的底层实现。在这个方案中,模型权重会被分成两个部分,分别存储在客户端和服务端。首先,客户端在本地开始推理,直至遇到已第一个不在本地的层。用户将中间结果加密并发送给服务端。服务端对其执行相应的注意力机制计算,然后将结果返回给客户端,客户端对结果进行解密并继续在本地推理。
量化
首先,为了对加密值进行模型推理,模型的权重和激活必须被量化并转换为整数。理想情况是使用 训练后量化,这样就不需要重新训练模型了。这里,我们使用整数和 PBS 来实现 FHE 兼容的注意力机制,并检查其对 LLM 准确率的影响。
要评估量化的影响,我们运行完整的 GPT2 模型,并让其中的一个 LLM 头进行密态计算。然后我们基于此评估权重和激活的量化比特数对准确率的影响。
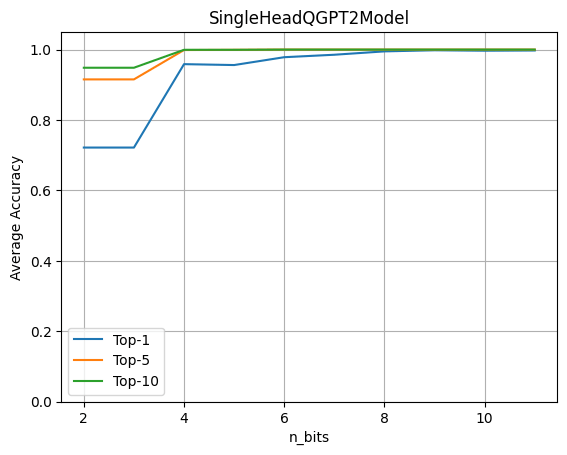
上图表明 4 比特量化保持了原始精度的 96%。该实验基于含有约 80 个句子的数据集,并通过将原始模型的 logits 预测与带有量化注意力头的模型的 logits 预测进行比较来计算最终指标。
在 Hugging Face GPT2 模型中使用 FHE
我们需要在 Hugging Face 的 transformers 库的基础上重写加密模块的前向传播,以使其包含量化算子。首先通过加载 GPT2LMHeadModel 构建一个 SingleHeadQGPT2Model 实例,然后手动使用 QGPT2SingleHeadAttention 替换第一个多头注意力模块,代码如下。你可以在 这里 找到模型的完整实现。
self.transformer.h[0].attn = QGPT2SingleHeadAttention(config, n_bits=n_bits)
至此,前向传播已被重载成用 FHE 算子去执行多头注意力的第一个头,包括构建查询、键和值矩阵的投影。以下代码中的 QGPT2 模块的代码见 此处。
class SingleHeadAttention(QGPT2):
"""Class representing a single attention head implemented with quantization methods."""
def run_numpy(self, q_hidden_states: np.ndarray):
# Convert the input to a DualArray instance
q_x = DualArray(
float_array=self.x_calib,
int_array=q_hidden_states,
quantizer=self.quantizer
)
# Extract the attention base module name
mha_weights_name = f"transformer.h.{self.layer}.attn."
# Extract the query, key and value weight and bias values using the proper indices
head_0_indices = [
list(range(i * self.n_embd, i * self.n_embd + self.head_dim))
for i in range(3)
]
q_qkv_weights = ...
q_qkv_bias = ...
# Apply the first projection in order to extract Q, K and V as a single array
q_qkv = q_x.linear(
weight=q_qkv_weights,
bias=q_qkv_bias,
key=f"attention_qkv_proj_layer_{self.layer}",
)
# Extract the queries, keys and vales
q_qkv = q_qkv.expand_dims(axis=1, key=f"unsqueeze_{self.layer}")
q_q, q_k, q_v = q_qkv.enc_split(
3,
axis=-1,
key=f"qkv_split_layer_{self.layer}"
)
# Compute attention mechanism
q_y = self.attention(q_q, q_k, q_v)
return self.finalize(q_y)
模型中的其他计算仍以浮点形式进行,未加密,并由客户端在本地执行。
将预训练的权重加载到修改后的 GPT2 模型中,然后调用 generate 方法:
qgpt2_model = SingleHeadQGPT2Model.from_pretrained(
"gpt2_model", n_bits=4, use_cache=False
)
output_ids = qgpt2_model.generate(input_ids)
举个例子,你可以要求量化模型补全短语 “Cryptography is a” 。在 FHE 中运行模型时,如果量化精度足够,生成的输出为:
“Cryptography is a very important part of the security of your computer”
当量化精度太低时,您会得到:
“Cryptography is a great way to learn about the world around you”
编译为 FHE
现在,你可以使用以下 Concrete-ML 代码编译注意力头:
circuit_head = qgpt2_model.compile(input_ids)
运行此代码,你将看到以下打印输出: “Circuit compiled with 8 bit-width”。该配置与 FHE 兼容,显示了在 FHE 中执行的操作所需的最大位宽。
复杂度
在 transformer 模型中,计算量最大的操作是注意力机制,它将查询、键和值相乘。在 FHE 中,加密域中乘法的特殊性加剧了成本。此外,随着序列长度的增加,这些乘法的数量还会呈二次方增长。
而就加密注意力头而言,长度为 6 的序列需要 11622 次 PBS 操作。我们目前的实验还很初步,尚未对性能进行优化。虽然可以在几秒钟内运行,但不可否认它需要相当多的计算能力。幸运的是,我们预期,几年后,硬件会将延迟提高 1000 倍到 10000 倍,使原来在 CPU 上需要几分钟的操作缩短到 ASIC 上的低于 100 毫秒。有关这些估算的更多信息,请参阅 此博文。
总结
大语言模型有望使能大量应用场景,但其实现引发了用户隐私的重大关切。在本文中,我们朝着密态 LLM 迈出了第一步,我们的最终愿景是让整个模型完全在云上运行,同时用户的隐私还能得到充分尊重。
当前的做法包括将 GPT2 等模型中的特定部分转换至 FHE 域。我们的实现利用了 transformers 库,用户还能评估模型的一部分在加密数据上运行时对准确率的影响。除了保护用户隐私之外,这种方法还允许模型所有者对其模型的主要部分保密。你可在 此处 找到完整代码。
Zama 库 Concrete 和 Concrete-ML (别忘了给我们的 github 代码库点个星星 ⭐️
标签:加密,FHE,模型,qkv,LLM,self From: https://www.cnblogs.com/huggingface/p/17725744.html