摘要
这篇文章主要研究的是如何将模型的预测归因到模型的输入上这个问题。
作者提出了两条归因方法应该满足的基本定理,敏感性(Sensitivity)和实现不变性(Implementation Invariance )。大多数的归因方法并没有满足这两条定理。作者基于这两条定理提出了一个新的方法名叫Integrated Gradients,直译过来就是用积分方法求梯度。这个方法不需要修改原始模型且简单易用。作者用这个方法在图像模型,文本模型,化学模型(太可怕了)上做了测试,证明了这一方法在调试模网络,提取规则,更好的了解网络方面的作用。
介绍
很多归因方法很难去评估。所以作者提出了两条定理并基于它们提出了integrated gradients
方法。对于归因问题,作者强调了基准线的概念。如果某件事情的发生是由于某个原因,那么这个原因的缺失就是基准线。在深度学习中,可以认为那些使得预测结果为中性的输入为基准线,比如在目标检测中,黑色图像就是基线,在文本分类中,全0的向量就可以作为基线。
两个基本定理
作者强调梯度和特征值的乘积是归因方法的不错的开始点。
1.Sensitivity(a)
对于任意一个输入,如果基准线在某一个特征上有所不同,并且它们的预测结果都不同,那么这一个特征应该有一个非0的归因值。这也是非常符合人类直觉的。
单纯的梯度是违反这个Sensitivity性质的。对于函数f(x) = 1 − ReLU(1−x)。对于输入x=2,基准线x=0,两个输入产生的预测结果不同,那么我们应该给x归因非0的值,但如果单纯求梯度的话,从函数图像上也可以很直观的看到,f(x)在x=2时的梯度为0.梯度对于Sensitivity性质的违反会导致梯度关注到完全不相关的特征上。如下图,看第二行fireboat,梯度并没有关注到真正重要的东西。

第二类归因方法是从最终的预测分数,通过各层神经网络进行反向传播,最终归因到输入上。比如DeepLift,Layer-wise relevance propagation (LRP), Deconvolutional networks (DeConvNets), and Guided back-propagation这些方法。
Deconvolution networks (DeConvNets)和 Guided back-propagation方法违反了Sensitivity。因为这些方法会使用到ReLU函数,所以使得行为类似于纯梯度求解,所以在之前讨论过的问题还会出现。
DeepLift 和 LRP方法通过使用基准线保持了Sensitivity,但他们也违反了第二个定理。
2.实现不变性
如果两个神经网络对于任意的输入都能有相同的输出,那么我们说这两个网络是相同的。归因方法在两个相同的神经网络上产生的值也应该是相同的,这叫做实现不变性。
对于链式求导法则
第二类归因方法是从最终的预测分数,通过各层神经网络进行反向传播,最终归因到输入上。比如DeepLift,Layer-wise relevance propagation (LRP), Deconvolutional networks (DeConvNets), and Guided back-propagation这些方法。
Deconvolution networks (DeConvNets)和 Guided back-propagation方法违反了Sensitivity。因为这些方法会使用到ReLU函数,所以使得行为类似于纯梯度求解,所以在之前讨论过的问题还会出现。
DeepLift 和 LRP方法通过使用基准线保持了Sensitivity,但他们也违反了第二个定理。
2.实现不变性
如果两个神经网络对于任意的输入都能有相同的输出,那么我们说这两个网络是相同的。归因方法在两个相同的神经网络上产生的值也应该是相同的,这叫做实现不变性。
对于链式求导法则
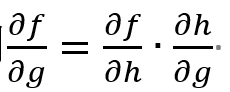
,将f看作神经网络的输出,g看作神经网络的输入,h则看作神经网络的中间部分。LRP 和 DeepLift违反了实现不变性是因为它们计算的是离散梯度。
链式法则并不能为离散值保证不变性。
,将f看作神经网络的输出,g看作神经网络的输入,h则看作神经网络的中间部分。LRP 和 DeepLift违反了实现不变性是因为它们计算的是离散梯度。
链式法则并不能为离散值保证不变性。
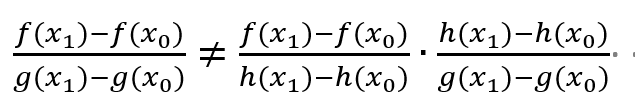
。
如果不能保持实现不变性的话,对于两个相同的网络,归因方法却会给出两个不同的值,这显然是不对的。
Integrated Gradients
用最朴素的语言来说,想象空间中有两个点,在这两个点之间,存在着一条不清楚到底是什么形状的曲线将这两点相连,将这条曲线叫做两点之间的路径。对这条路径上的每一个点求导,在求和(其实就是积分的定义了),最后再乘以两点之间的差值,最后得出来的结果就是这个方法最后的值。
用公式来描述就是下面这样,i的意思就是对第i维进行求解,x这个特征是有很多维的
。
如果不能保持实现不变性的话,对于两个相同的网络,归因方法却会给出两个不同的值,这显然是不对的。
Integrated Gradients
用最朴素的语言来说,想象空间中有两个点,在这两个点之间,存在着一条不清楚到底是什么形状的曲线将这两点相连,将这条曲线叫做两点之间的路径。对这条路径上的每一个点求导,在求和(其实就是积分的定义了),最后再乘以两点之间的差值,最后得出来的结果就是这个方法最后的值。
用公式来描述就是下面这样,i的意思就是对第i维进行求解,x这个特征是有很多维的
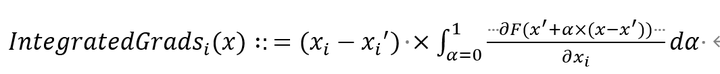 这个方法还满足一个Completeness,直译为完整性。意思可以直观的看下面这个公式
这个方法还满足一个Completeness,直译为完整性。意思可以直观的看下面这个公式
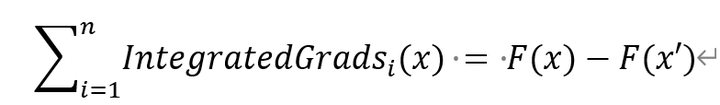
如果神经网络可以被看作一个函数F,且这个函数处处可导,那么
意思就是说我们求出来的各个特征的归因值就等于输入x和输入x'的预测值之间的差值。这一性质在很多归因方法中都有涉及。
积分梯度法的唯一性
之前的研究工作主要通过以经验为主的分析技术去评估归因方法的好坏。比如:在目标检测算法中,选取前k个归因为最重要的像素,将他们的值进行改变,观察预测分数(比如一幅图像是苹果的概率,这个概率就是预测分数)的改变。若分数有很大变动,则说明这几个像素确实很重要。但这种方法是不自然的。另一种评估方法是考虑人工在目标周围画线,然后在线内的像素应该具有较高的重要值。
接下来,作者阐述一种叫做Path Methods 的方法,并证明这个方法是唯一的一个满足前面提出的两个公理的方法。并且,作者论述了为什么采用的积分梯度的路径在不同的路径方法中是规范的。
并且,作者多次提到了Shapley方法,这一方法与Integrated Gradients方法有着千丝万缕的联系,我对这一方法了解还不多,就先不做阐述。
应用积分梯度
选择一个合适的baseline,计算机视觉选取黑色图像,自然语言处理选取全0向量。
积分梯度的计算
使用下面这个公式
如果神经网络可以被看作一个函数F,且这个函数处处可导,那么
意思就是说我们求出来的各个特征的归因值就等于输入x和输入x'的预测值之间的差值。这一性质在很多归因方法中都有涉及。
积分梯度法的唯一性
之前的研究工作主要通过以经验为主的分析技术去评估归因方法的好坏。比如:在目标检测算法中,选取前k个归因为最重要的像素,将他们的值进行改变,观察预测分数(比如一幅图像是苹果的概率,这个概率就是预测分数)的改变。若分数有很大变动,则说明这几个像素确实很重要。但这种方法是不自然的。另一种评估方法是考虑人工在目标周围画线,然后在线内的像素应该具有较高的重要值。
接下来,作者阐述一种叫做Path Methods 的方法,并证明这个方法是唯一的一个满足前面提出的两个公理的方法。并且,作者论述了为什么采用的积分梯度的路径在不同的路径方法中是规范的。
并且,作者多次提到了Shapley方法,这一方法与Integrated Gradients方法有着千丝万缕的联系,我对这一方法了解还不多,就先不做阐述。
应用积分梯度
选择一个合适的baseline,计算机视觉选取黑色图像,自然语言处理选取全0向量。
积分梯度的计算
使用下面这个公式
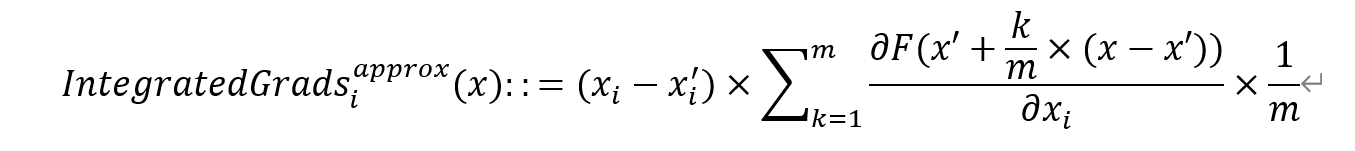
这个方法就是之前介绍的公式,只不过使用了积分的近似求法,将x到x'的路径分成m份,每一份都求一个梯度,然后求和平均,最后乘以输入和基线之间的差就是我们最后要求的值。作者这里指出m只需要取20-300左右即可。
后面就是作者在图像数据集,在文本数据集,以及在化学数据集上应用这一方法的内容。
最后,推荐这个notebook,通过一个简单的手写数字识别样例简单明了的阐述了这篇论文所讲方法的使用过程。
https://github.com/JoHof/IntegratedGradientsTutorial/blob/master/ig_example_onmnist.ipynb
这个方法就是之前介绍的公式,只不过使用了积分的近似求法,将x到x'的路径分成m份,每一份都求一个梯度,然后求和平均,最后乘以输入和基线之间的差就是我们最后要求的值。作者这里指出m只需要取20-300左右即可。
后面就是作者在图像数据集,在文本数据集,以及在化学数据集上应用这一方法的内容。
最后,推荐这个notebook,通过一个简单的手写数字识别样例简单明了的阐述了这篇论文所讲方法的使用过程。
https://github.com/JoHof/IntegratedGradientsTutorial/blob/master/ig_example_onmnist.ipynb