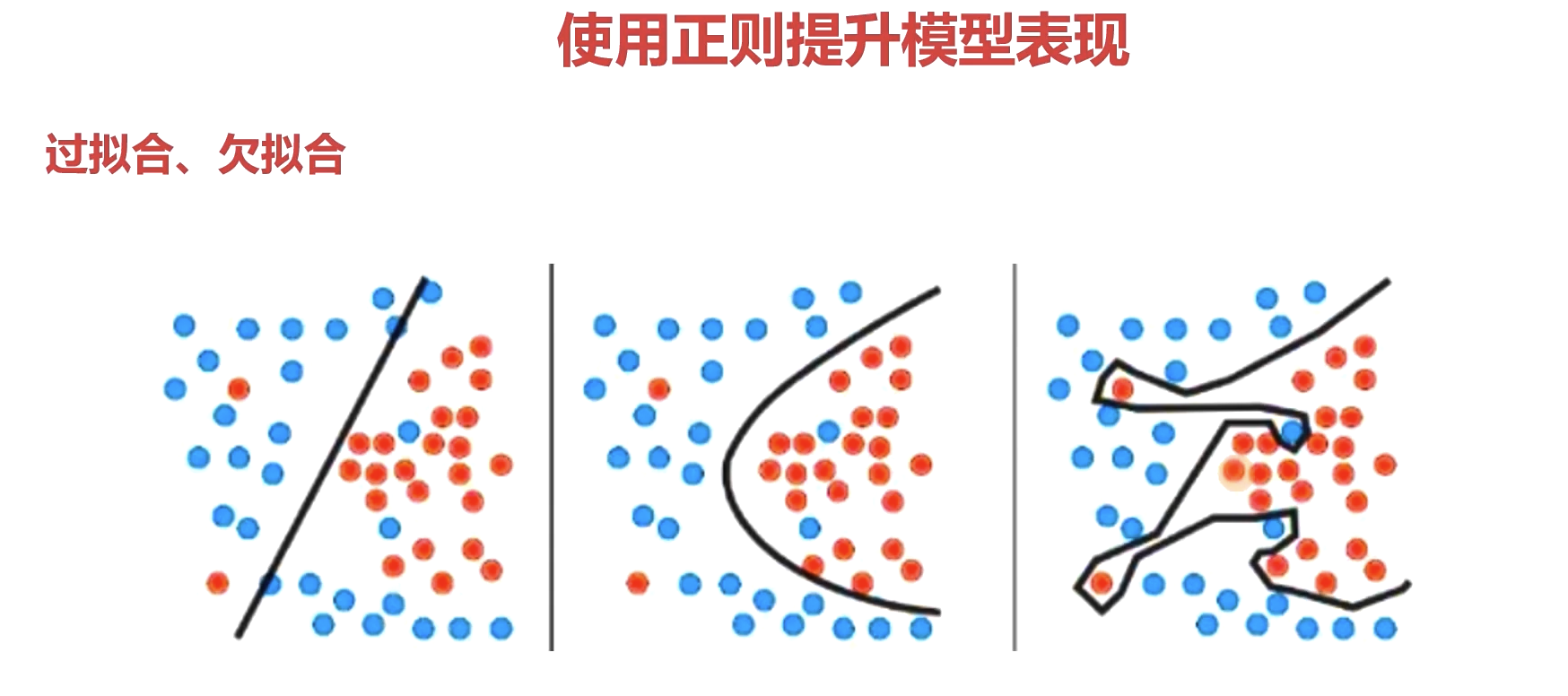
抑制过拟合:四个方法
1.添加正则项
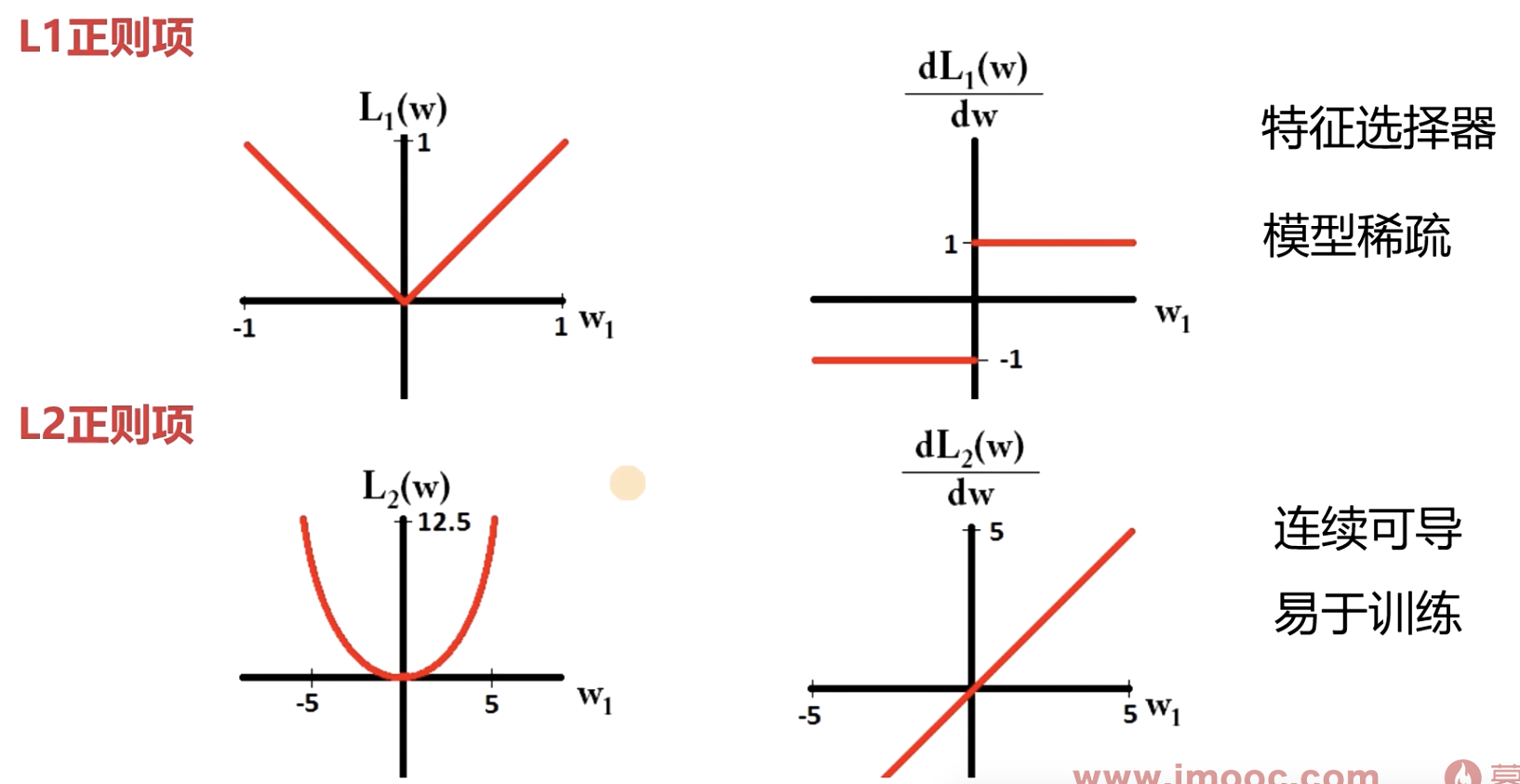
- L1正则项 (作为特征选择器,模型稀疏)
尽可能是余项(w相关项)为0 ,(说明细胞是死掉的,模型就变得稀疏,这个细胞就没用,在模型进行压缩的时候可以砍掉就可以很大倍数的压缩), w为0的时候这个细胞是没有意义的。入 自己定义的,J(w)是loss
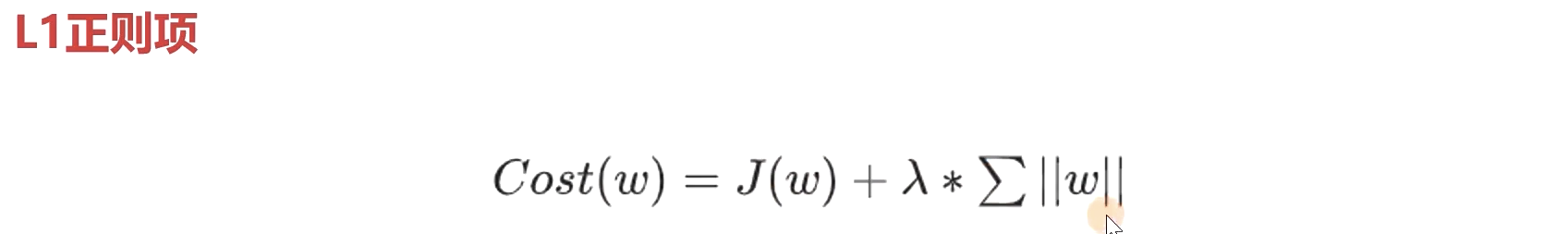
- L2正则项(连续可导,易于训练)
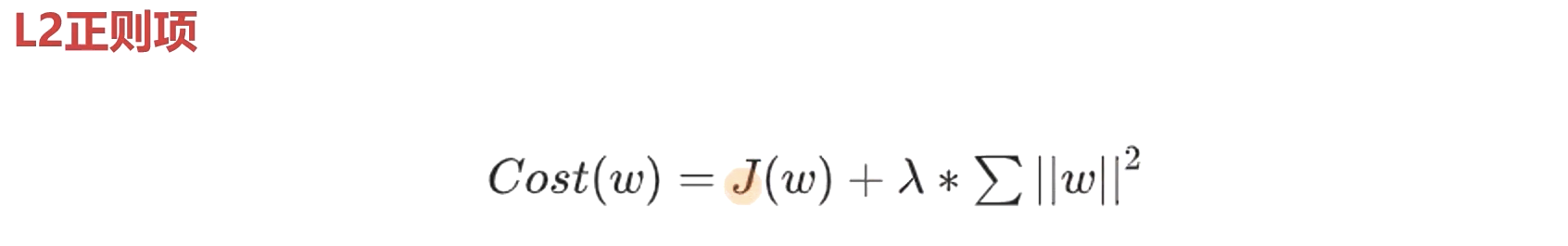
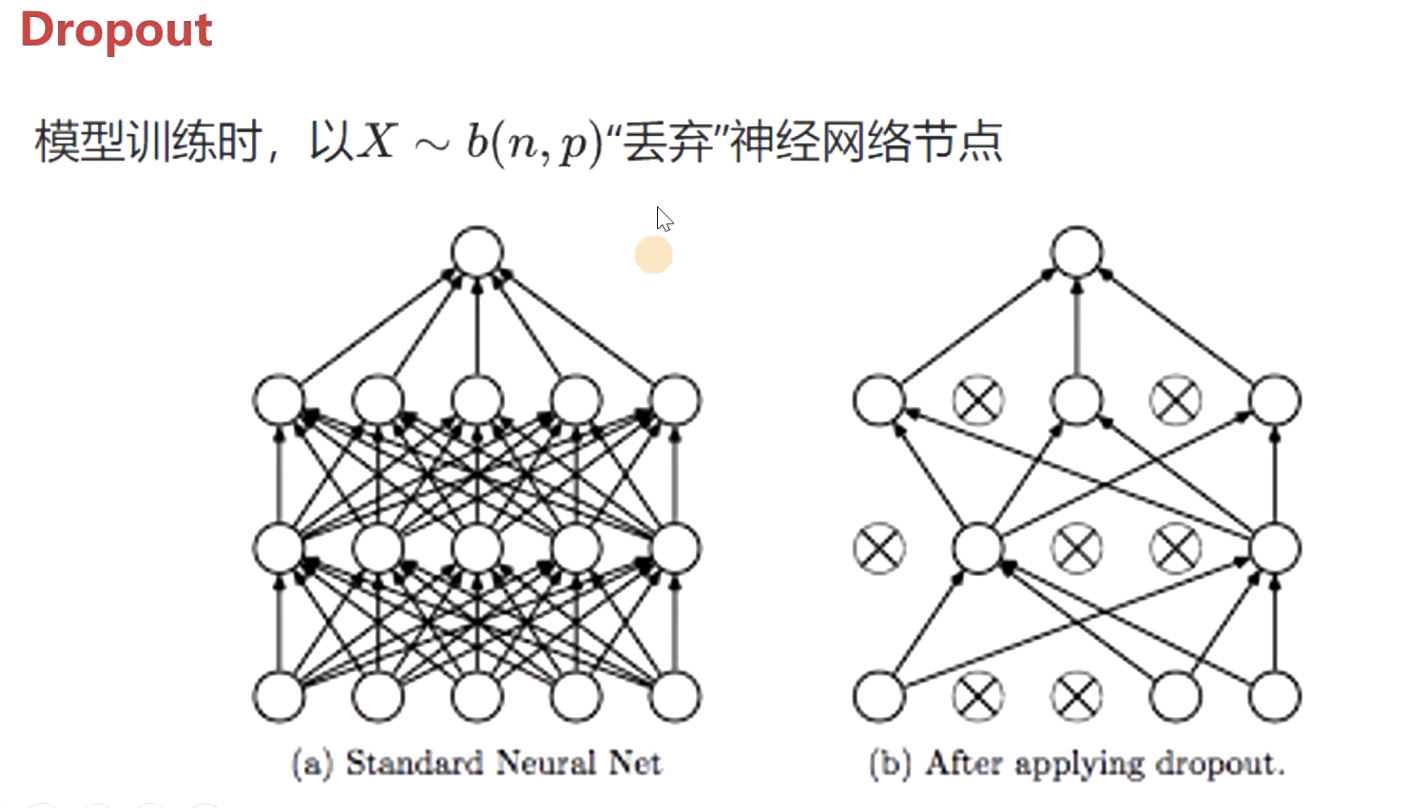
2.Dropout
$$
X \sim b(n, p)
$$
以2算式丢弃神经网络的节点。 p是丢弃的概率, 优点 使模型变得简单,抑制过拟合
3.Data Augmentation:数据增广
在数据上做文章,增广后的数据尽可能服从原数据的分布

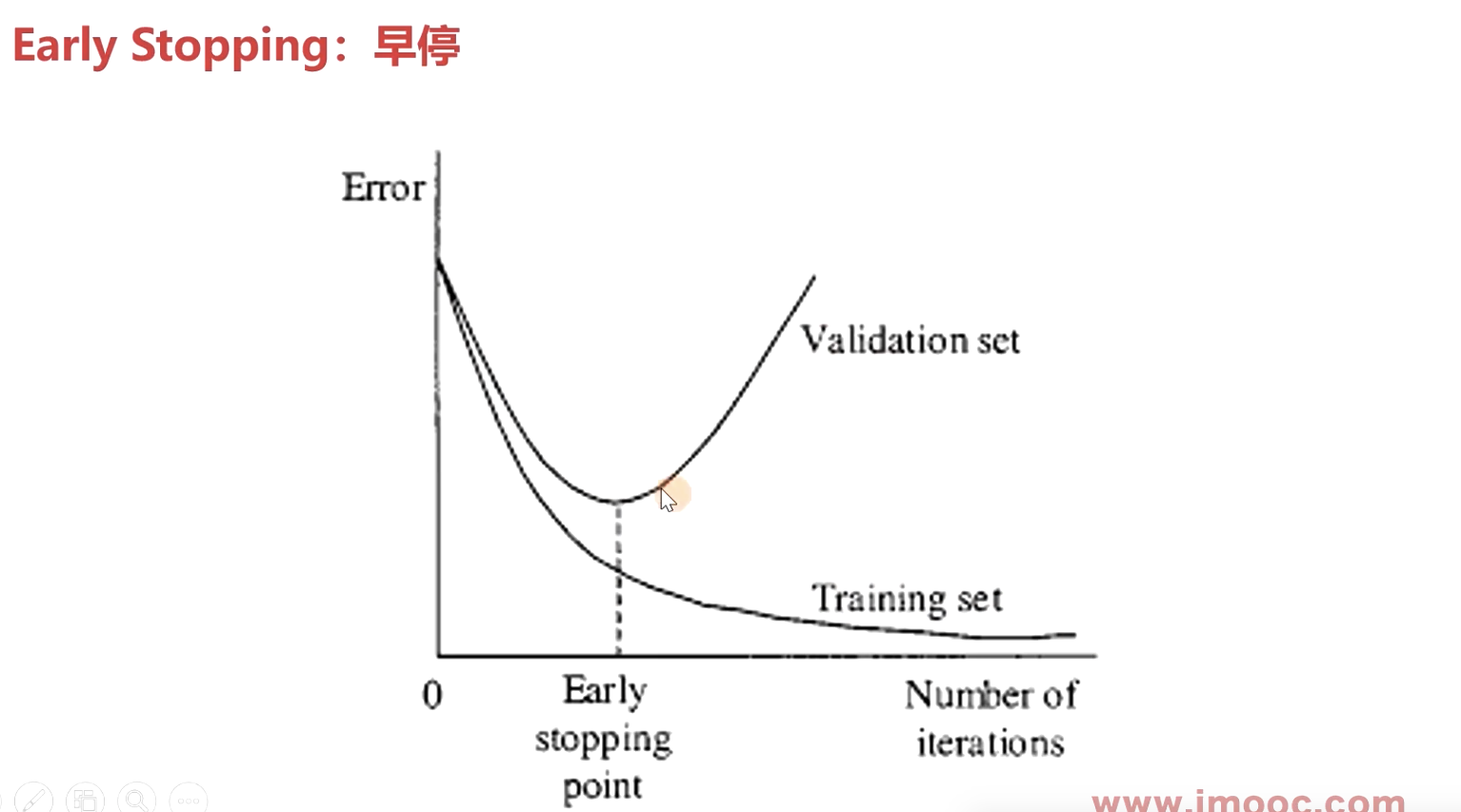
4.Early Stopping :早停

torch.randn()参数size与输出张量形状
当size是n个数时,m_1, m_2,...,m_n, 若n为奇数,则返回一个m_1行1列的张量, 其中每个元素是一个m_2行m_3列的张量,...., 又其中每个元素是一个m_n- 1行m_n列的张量,最小元素的每一行服从正态分布。
当size是n个数时,m_1,m_2,...,m_n, 若n为偶数,则返回一个m_1行m_2列的张量, 其中每个元素是一个m_3行m_4列的张量,..., 又其中每个元素是一个m_n-1行m_n列的张量, 最小元素的每一行服从正态分布。
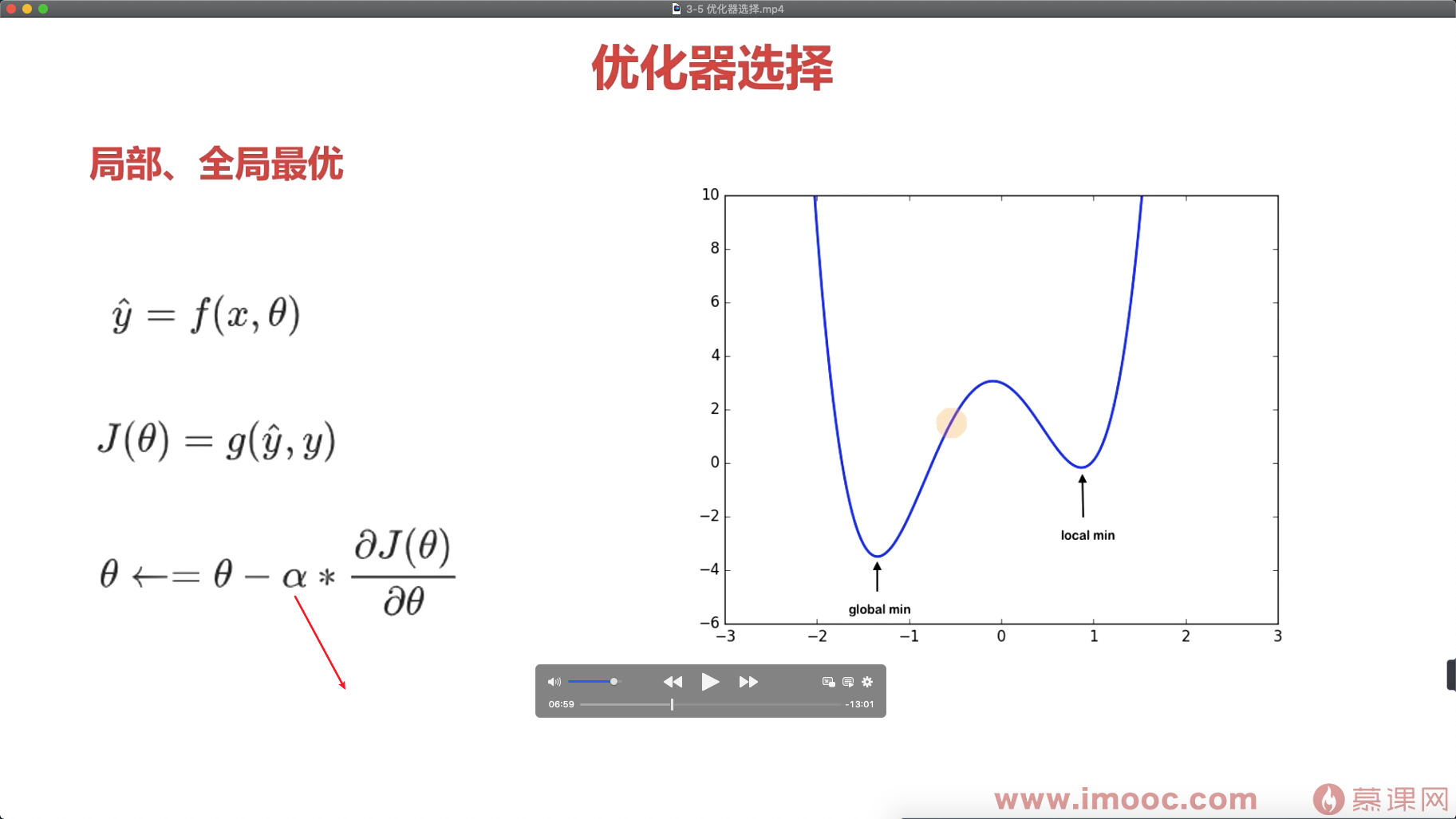
存在的问题:容易陷入局部最优解。
阿尔法 太小的话 训练时间太长成本太大,阿尔法太大 容易忽略最优解 (跨过最后解)
更改:

随机梯度下降系列 SGD:动量上做文章单向的时候vt越来越大,当从优点左面震荡到最优点右面的时候,速度就会减慢 ,直到找到最优点。
自适应学习率系列 Ada:学习率上做文章 每个 seita 单独跟踪。越从快到慢寻找最优点。
目标是:加快收敛,抑制震荡
优化器的选择:
如果数据是稀疏的,就用学习率自适应优化器
标签:...,模型,元素,张量,选择,优点,参数,size From: https://www.cnblogs.com/aohongchang/p/16744958.html