前言 对于谷歌 DeepMind 的 Soft MoE,有人表示:「即使它不是万能药,仍可以算得上一个突破」。
本文转载自机器之心
仅用于学术分享,若侵权请联系删除
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【CV技术指南】CV全栈指导班、基础入门班、论文指导班 全面上线!!
随着大模型涌现出令人惊艳的性能,模型大小已经成为影响模型性能的关键因素之一。通常,对 Transformer 模型来说,模型越大,性能就会越好,但计算成本也会增加。近期有研究表明,模型大小和训练数据必须一起扩展,才能最佳地使用给定的训练计算预算。
稀疏混合专家模型(MoE)是一种很有前途的替代方案,可以在计算成本较少的情况下,扩展模型的大小。稀疏 MoE Transformer 有一个关键的离散优化问题:决定每个输入 token 应该使用哪些模块。这些模块通常是称为专家的 MLP。
为了让 token 与专家良好匹配,人们设计了许多方法,包括线性规划、强化学习、最优传输(optimal transport)等。在许多情况下,需要启发式辅助损失(auxiliary loss)来平衡专家的利用率并最大限度地减少未分配的 token。这些挑战在分布外场景中可能会加剧。
现在,来自 Google DeepMind 的研究团队提出了一种称为「Soft MoE」的新方法 ,解决了许多问题。

论文地址:https://arxiv.org/pdf/2308.00951.pdf
Soft MoE 不采用稀疏且离散的路由器在 token 和专家之间进行硬分配(hard assignment),而是通过混合 token 来执行软分配(soft assignment)。值得注意的是,这种方法会计算所有 token 的多个加权平均值(weighted average),其中权重取决于 token 和专家,然后由相应的专家处理每个加权平均值。
常见的稀疏 MoE 算法通常会学习一些路由器参数,但这些算法的效果有时甚至不如随机固定路由。在 Soft MoE 中,由于每个路由(或混合)参数都是根据单个输入 token 直接更新的,因此可以在训练路由器期间提供稳定性。研究团队还观察到,在训练期间,大部分输入 token 可以同时改变网络中的离散路由。
此外,硬路由(hard routing)在专家模块数量较多时可能具有挑战性,因此大多数研究的训练只有几十个专家模块。相比之下,Soft MoE 可扩展至数千个专家模块,并且可以通过构建实现平衡。最后,Soft MoE 在推理时不存在批次效应(batch-effect)。
该研究进行了一系列实验来探究 Soft MoE 方法的实际效果。实验结果表明,Soft MoE L/16 在上游任务、少样本任务和微调方面击败了 ViT H/14,并且 Soft MoE L/16 仅需要一半的训练时间,推理速度还是 ViT H/14 的 2 倍。值得注意的是,尽管 Soft MoE B/16 的参数量是 ViT H/14 的 5.5 倍,但 Soft MoE B/16 的推理速度却是 ViT H/14 的 5.7 倍。
此外,该研究用实验表明通过软路由学习的表征保留了图像 - 文本对齐的优势。
Soft MoE 模型
算法描述
Soft MoE 路由算法如下图 2 所示。研究者使用 X ∈ R^m×d 来表示一个序列的输入 token,其中 m 是 token 数量,d 是维数。每个 MoE 层使用一组 n 个专家函数应用于单个 token,即 {f_i : R^d → R^d}_1:n。每个专家将处理 p 个 slot,每个 slot 有相应的 d 维参数向量。他们用

来表示这些参数。
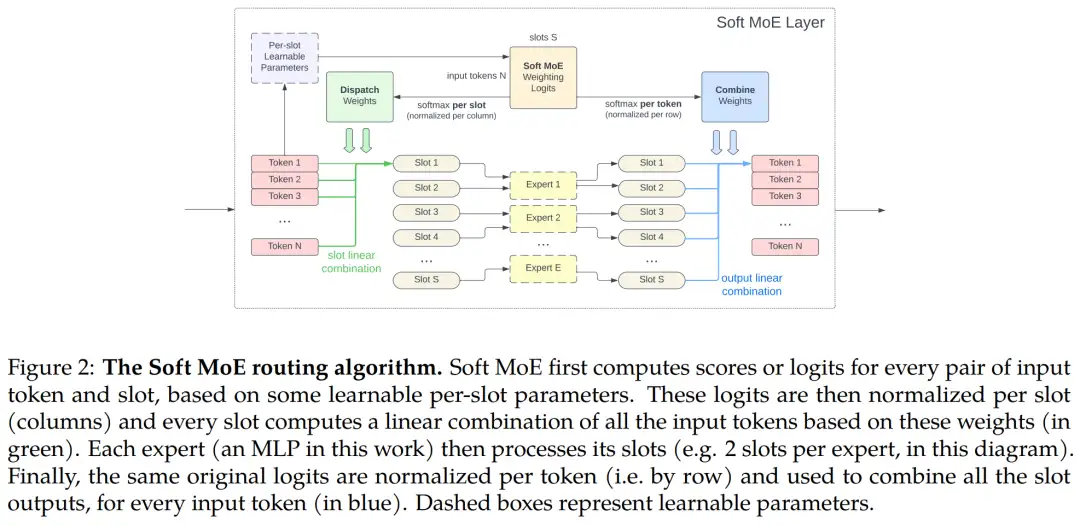
研究者遵循稀疏 MoE 的常规设计,利用 Soft MoE 块替换掉了 Transformer MLP 块的一个子集。这里通常会替换掉 MLP 块的后半部分。slot 的总数量是 Soft MoE 层的关键超参数,这是因为时间复杂度依赖于 slot 数量而不是专家数量。比如可以将 slot 数设置为与输入序列长度相等,以匹配等效密集 Transformer 的 FLOP。

Soft MoE 的特性
首先 Soft MoE 完全可微。Soft MoE 中的所有操作都是连续且完全可微的。我们可以将带有 softmax 分数的加权平均值解释为软分类,这也是 Soft MoE 算法名称的由来。作为对比,稀疏 MoE 方法通常采用的是硬分类。
其次 Soft MoE 没有 token dropping 和专家不平衡。Soft MoE 基本上不受这两点的影响,这得益于每个 slot 都填充了所有 token 的加权平均值。并且由于 softmax,所有权重都是严格正的。
再次 Soft MoE 速度快。它的主要优势是完全避免了排序或 top-k 操作,这些操作速度慢并且通常不太适合硬件加速器。因此,Soft MoE 的速度明显要快于大多数稀疏 MoE,具体如下图 6 所示。

Soft MoE 还兼具稀疏和密集的特点。稀疏 MoE 的稀疏性来自于专家参数仅应用于输入 token 的子集。然而,Soft MoE 在技术上不稀疏,这是因为每个 slot 是所有输入 token 的加权平均值。并且每个输入 token 会极少部分激活所有模型参数。同样所有输出 token 也极少部分依赖所有 slot(和专家)。还要注意一点,Soft MoE 不是密集 MoE(其中每个专家处理所有输入 token),它的每个专家仅处理 slot 的子集。
最后 Soft MoE 具有序列性。由于它组合了每个输入序列中的所有 token,因此只需将组大小设置为一个大序列。每个专家会处理每个输入的 token,这可能会在一定程度上限制高级 specialization 的数量。这也意味着 Soft MoE 呈现逐实例确定性和速度快,而稀疏 MoE 的典型实例不是这样。
实现
时间复杂度。假设单个专家函数的逐 token 成本是 O (k),则一个 Soft MoE 层的时间复杂度为 O (mnpd + npk)。通过为每个专家选择 p = O (m/n) 个 slot,也就是 token 数量除以专家数量,成本可以降低至 O (m^2d + mk)。
归一化。在 Transformer 中,MoE 层通常用来替换掉每个编码器块中的前馈层。因此当使用预归一化作为大多数现代 Transformer 架构时,MoE 层的输入是「层归一化的」。

分布式模型。研究者采用标准技术将模型分布在很多设备上。分布式模型通常会增加模型的成本开销,不过他们上文推导的基于 FLOP 的时间复杂度分析并没有捕获这一点。因此在所有实验中,研究者不仅测量了 FLOP,还测量了以 TPUv3-chip-hour 为单位的挂钟时间。
图像分类实验结果
研究者展示了图像分类的三种类型的实验:
- 训练帕累托边界
- 推理时优化模型
- 模型消融
研究者在 JFT-4B 数据集上对模型进行预训练,这是一个专有数据集,最新版本包含了超过 4B 张图像、29k 个类别。
在预训练期间,他们提供了两个指标的评估结果,即 JFT-4B 的上游验证 precision-at-1 和 ImageNet 10-shot 准确率。此外还提供了在 ImageNet-1k(1.3M 张图像)上进行微调后,ImageNet-1k 验证集上的准确率。
研究者对比了两个流行 MoE 路由算法,分别是 Tokens Choice 和 Experts Choice。
训练帕累托 - 优化模型
研究者训练了 VIT-S/8、VIT-S/16、VIT-S/32、VIT-B/16、VIT-B/32、VIT-L/16、VIT-L/32 和 VIT-H/14 模型,以及它们的稀疏对应模型。
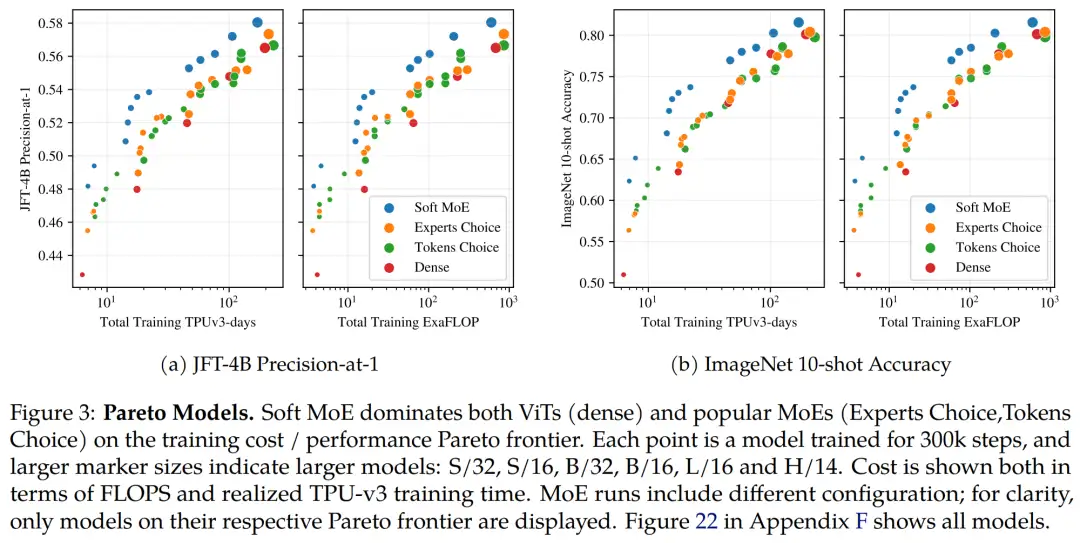
下图 3a 和 3b 显示了每个类别中模型的结果,这些模型位于各自的训练成本 / 性能帕累托边界上。在上述两个评估指标上,对于任何给定的 FLOP 或时间预算,Soft MoE 显著优于密集和其他稀疏方法。
长训练运行
除了较短的运行和消融实验之外,研究者还训练了运行更长(几百万 step)的模型,从而在更大的计算规模上测试 Soft MoE 的性能。
首先研究者训练了从 Small 到 Huge 的不同大小的 ViT 和 Soft MoE 模型,它们运行了 4 百万 step。下图 4 和表 2 展示了结果。
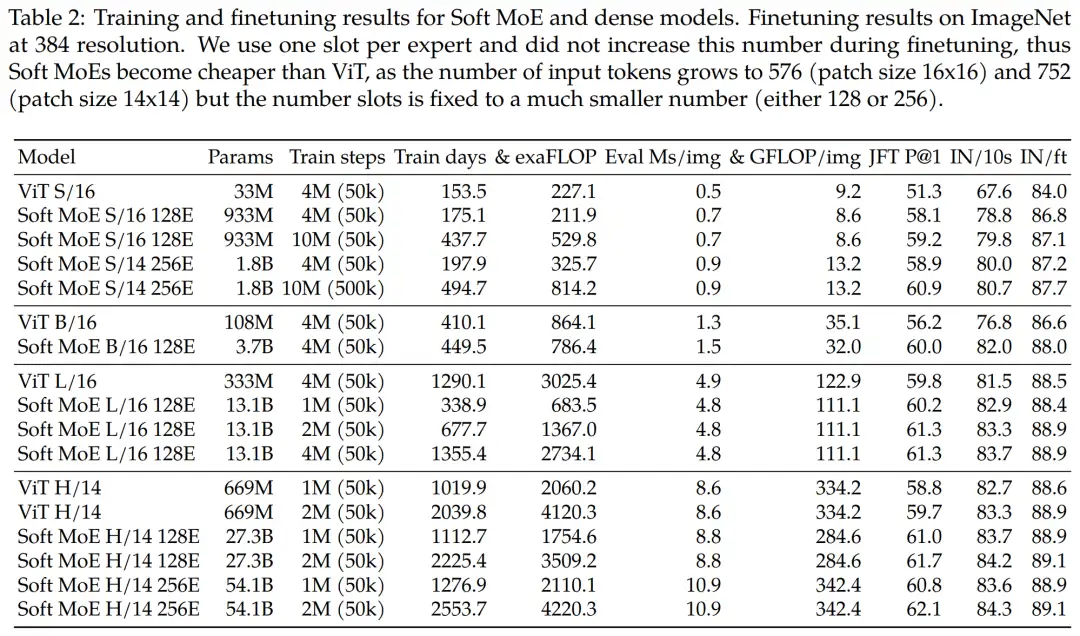
其中图 4 展示了 Soft MoE 与 ViT 的 JFT-4B 精度、ImageNet 10-shot 准确率和 ImageNet 微调准确率,以及 ExaFLOPS 的训练成本。表 2 提供了所有结果。对于给定的计算预算,Soft MoE 模型的性能远优于 ViT 模型。
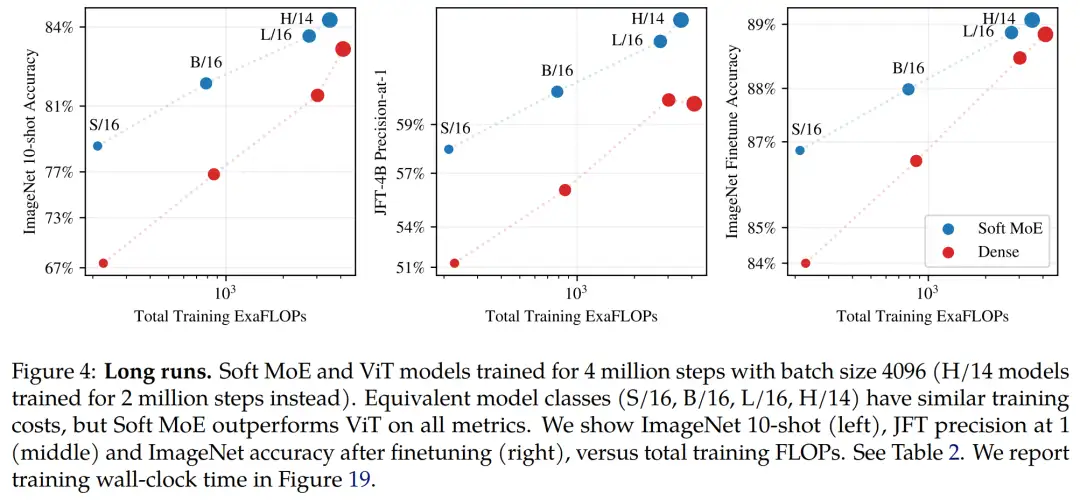
再来看针对推理进行优化的 Soft MoE。对于具有较小主干的 Soft MoE 可以与较大 ViT 模型一较高下这一事实,研究者受到了鼓舞,继续训练小的主干,以在非常低的推理成本下获得更高质量的模型。
对于更长时间的运行,研究者观察到冷却时间(学习率线性降低到 0)越长,Soft MoE 的效果很好。因此,他们将冷却时长从 50k step 增加到最多 500k。下图 5 展示了这些模型。
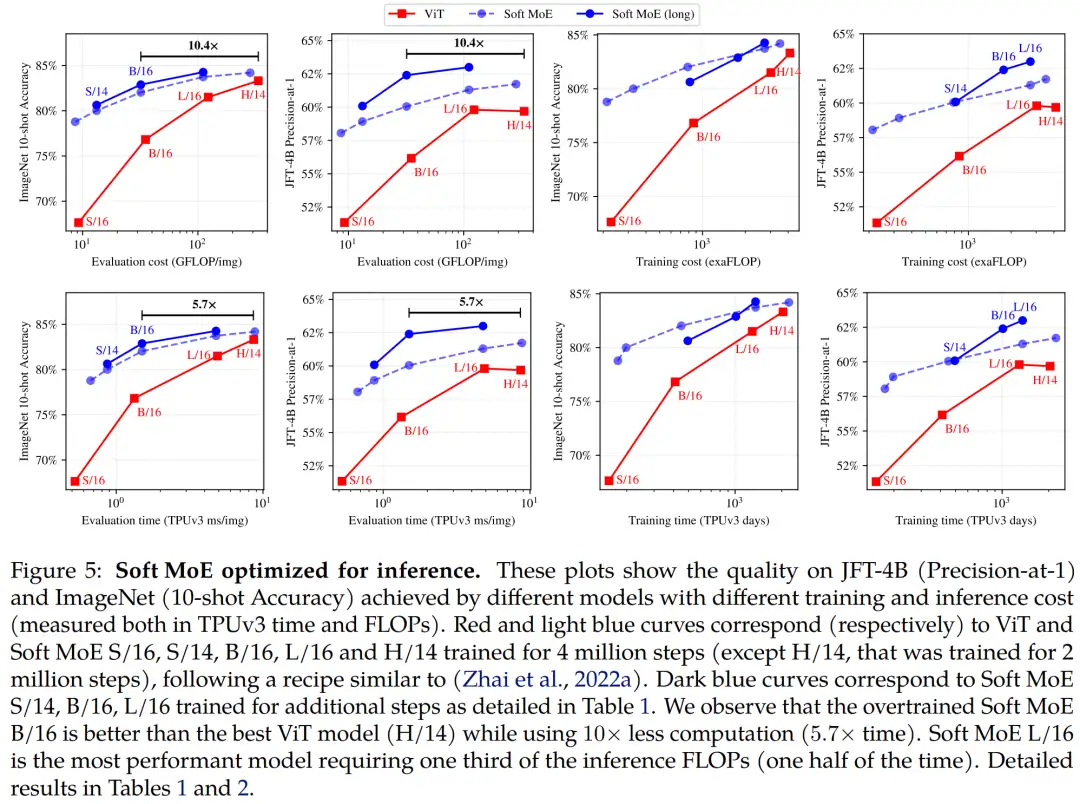
从结果来看,经过 1k TPUv3 days 训练的 Soft MoE B/16 优于在类似时间预算下训练的 ViT H/14,同时在 FLOP 推理上成本 10 倍降低,在挂钟时间上 5.7 倍减少。
即使将 ViT-H/14 的训练预算加倍(2M step 和 2039.8 train days),Soft MoE B/16(1011.4 days)也几乎与它性能相近。
此外,Soft MoE L/16 大幅地击败所有模型,同时推理速度是 ViT H/14 的近 2 倍。
更多技术细节和实验结果请参阅原论文。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:470899183。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
比Meta「分割一切AI」更全能!港科大版图像分割AI来了:实现更强粒度和语义功能
Meta Segment Anything会让CV没前途吗?
CVPR'2023年AQTC挑战赛第一名解决方案:以功能-交互为中心的时空视觉语言对齐方法
6万字!30个方向130篇 | CVPR 2023 最全 AIGC 论文汇总
ICCV2023 | 当尺度感知调制遇上Transformer,会碰撞出怎样的火花?
新加坡国立大学提出最新优化器:CAME,大模型训练成本降低近一半!
SegNetr来啦 | 超越UNeXit/U-Net/U-Net++/SegNet,精度更高模型更小的UNet家族
libtorch教程(一)开发环境搭建:VS+libtorch和Qt+libtorch
NeRF与三维重建专栏(三)nerf_pl源码部分解读与colmap、cuda算子使用
NeRF与三维重建专栏(二)NeRF原文解读与体渲染物理模型
BEV专栏(一)从BEVFormer深入探究BEV流程(上篇)
可见光遥感图像目标检测(三)文字场景检测之Arbitrary
AI最全资料汇总 | 基础入门、技术前沿、工业应用、部署框架、实战教程学习
标签:ViT,训练,一较高下,模型,token,DeepMind,Soft,MoE From: https://www.cnblogs.com/wxkang/p/17609326.html