前言 最近关于遥感物体检测的研究主要集中在改进旋转包围框的表示方法上,但忽略了遥感场景中出现的独特的先验知识。这种先验知识是非常重要的,因为微小的遥感物体可能会在没有参考足够长距离背景的情况下被错误地检测出来,而不同类型的物体所要求的长距离背景可能会有所不同。
本文将这些先验因素考虑在内,并提出了 Large Selective Kernel Network (LSKNet)。LSKNet 可以动态地调整其大空间感受野,以更好地建模遥感场景中各种物体的测距的场景。
本文转载自PaperWeekly
作者 | 李宇轩
单位 | 伦敦大学学院
仅用于学术分享,若侵权请联系删除
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【CV技术指南】CV全栈指导班、基础入门班、论文指导班 全面上线!!

论文题目:
Large Selective Kernel Network for Remote Sensing Object Detection
论文链接:https://arxiv.org/pdf/2303.09030.pdf
代码链接:
https://github.com/zcablii/LSKNet
最近关于遥感物体检测的研究主要集中在改进旋转包围框的表示方法上,但忽略了遥感场景中出现的独特的先验知识。这种先验知识是非常重要的,因为微小的遥感物体可能会在没有参考足够长距离背景的情况下被错误地检测出来,而不同类型的物体所要求的长距离背景可能会有所不同。
在本文中,我们将这些先验因素考虑在内,并提出了 Large Selective Kernel Network (LSKNet)。LSKNet 可以动态地调整其大空间感受野,以更好地建模遥感场景中各种物体的测距的场景。
据我们所知,这是首次在遥感物体检测领域探索大选择性卷积核机制的工作。在没有任何附加条件的情况下,我们 LSKNet 比主流检测器轻量的多,而且在多个数据集上刷新了 SOTA!HRSC2016(98.46% mAP)、DOTA-v1.0(81.64% mAP)和 FAIR1M-v1.0(47.87% mAP)。

Introduction
近期很少有工作考虑到遥感图像中存在的强大的先验知识。航空图像通常是以高分辨率的鸟瞰视角拍摄的。特别是,航空图像中的大多数物体可能是小尺寸的,仅凭其外观很难识别。相反,这些物体的成功识别往往依赖于它们的背景,因为周围的环境可以提供关于它们的形状、方向和其他特征的宝贵线索。根据对主流遥感数据集的分析,我们确定了两个重要的前提条件:
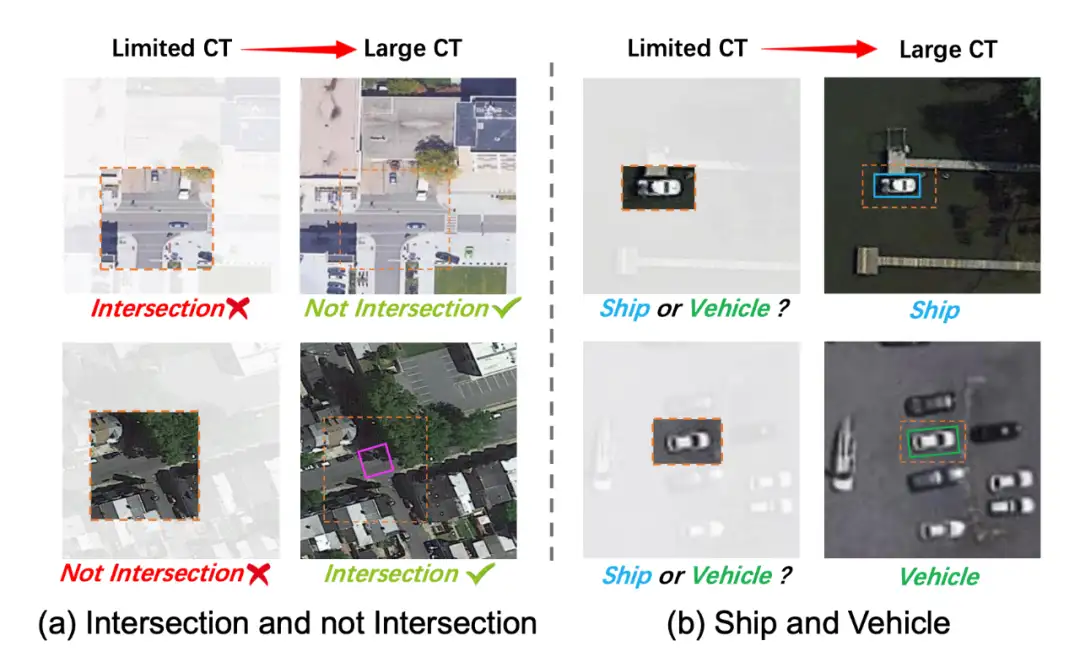 ▲ 图1. 成功地检测遥感目标需要使用广泛的背景信息。感受野有限的探测器可能很容易导致错误的探测结果。CT: Context
▲ 图1. 成功地检测遥感目标需要使用广泛的背景信息。感受野有限的探测器可能很容易导致错误的探测结果。CT: Context
1. 准确检测遥感图像中的物体往往需要广泛的背景信息
如图 1(a) 所示,遥感图像中的物体检测器所使用的有限范围的背景往往会导致错误的分类。例如,在上层图像中,由于其典型特征,检测器可能将T子路口归类为十字路口,但实际上,它不是一个十字交路口。同样,在下图中,由于大树的存在,检测器可能将十字路口归类为非路口,但这也是不正确的。这些错误的发生是因为检测器只考虑了物体附近的有限的上下文信息。在图 1(b) 中的船舶和车辆的例子中也可以看到类似的情况。
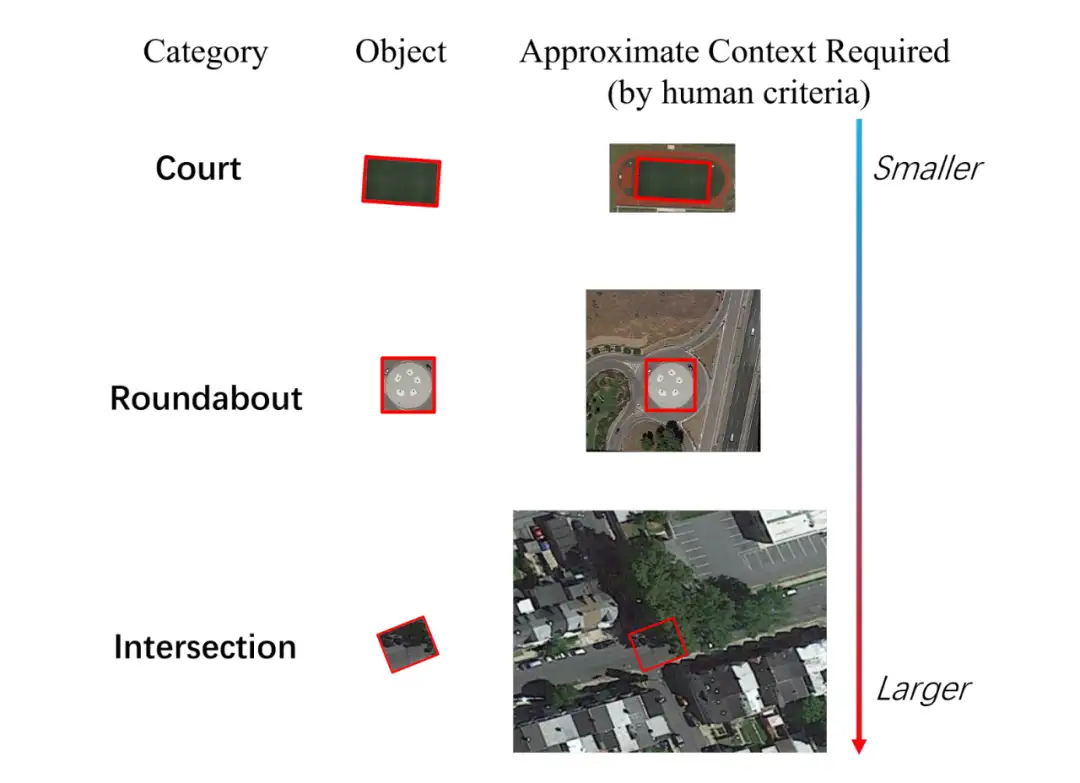 ▲ 图2. 按照人类的标准,不同的物体类型所需要的背景信息范围非常不同。红框是目标GT标注。
▲ 图2. 按照人类的标准,不同的物体类型所需要的背景信息范围非常不同。红框是目标GT标注。
2. 不同类型的物体所需的上下文信息的范围非常不同
如图 2 所示,在遥感图像中进行准确的物体检测所需的背景信息量会因被检测物体的类型而有很大不同。例如,足球场可能需要相对较少的额外环境信息,因为它有独特的可区分的球场边界线。
相比之下,环岛可能需要更大范围的上下文信息,以区分花园和环形建筑。交叉口,特别是那些部分被树木覆盖的交叉口,由于相交道路之间的长距离依赖性,往往需要一个非常大的感受野。这是因为树木和其他障碍物的存在会使人们难以仅仅根据外观来识别道路和交叉口本身。其他物体类别,如桥梁、车辆和船舶,也可能需要不同规模的感受野,以便被准确检测和分类。
因为这些图像往往需要广泛和动态的背景信息,我们提出了一种新的方法,称为 Large Selective Kernel Network (LSKNet)。我们的方法包括动态调整特征提取骨干的感受野,以便更有效地处理被检测物体的不同的广泛背景。这是通过一个空间选择机制来实现的,该机制对一连串的大 depth-wise 卷积核所处理的特征进行有效加权,然后在空间上将它们合并。这些核的权重是根据输入动态确定的,允许该模型自适应地使用不同的大核,并根据需要调整空间中每个目标的感受野。
据我们所知,我们提出的 LSKNet 是第一个研究和讨论在遥感物体探测中使用大的和有选择性的卷积核的模型。尽管我们的模型很简单,但在三个流行的数据集上实现了最先进的性能。HRSC2016(98.46% mAP)、DOTA-v1.0(81.64% mAP)和 FAIR1M-v1.0(47.87% mAP),超过了之前公布的结果。此外,我们实验证明了我们模型的行为与上述两个先验假设的一致性。

Method
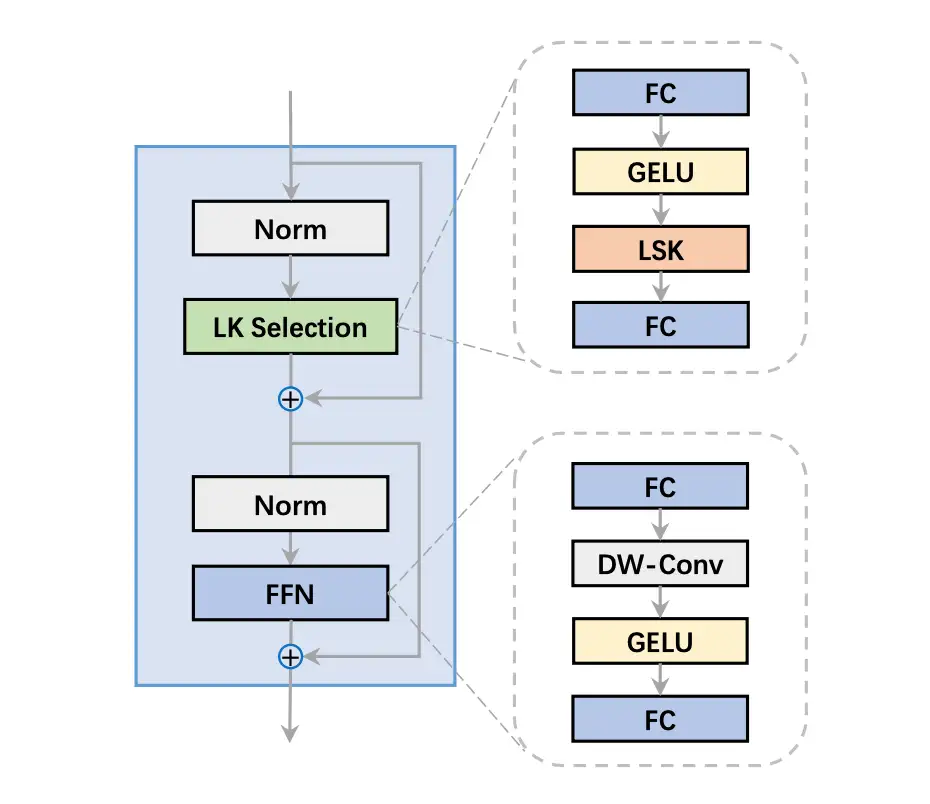 ▲ 图3. LSK Block 图示
▲ 图3. LSK Block 图示
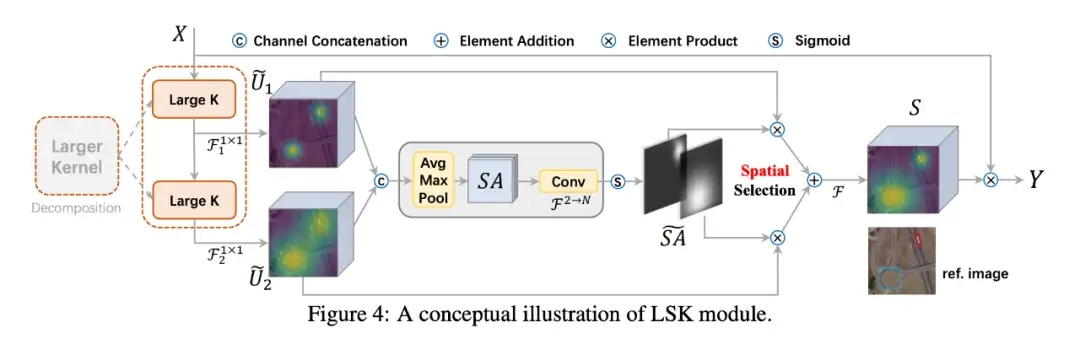 ▲ 图4. LSK Module 的概念图
▲ 图4. LSK Module 的概念图
LSKNet Architecture
图 3 展示了一个 LSKNet Bolck 的图示,是主干网中的一个重复块,其灵感来自 ConvNeXt, PVT-v2, VAN, Conv2Former 和 MetaFormer。每个 LSKNet 块由两个剩余子块组成:大核选择(LK Selection)子块和前馈网络(FFN)子块。LK 选择子块根据需要动态地调整网络的感受野。前馈网络子块用于通道混合和特征细化,由一个全连接层、一个深度卷积、一个 GELU 激活和第二个全连接层组成的序列。核心模块 LSK Module(图 4)被嵌入到 LK 选择子块中。它由一连串的大内核卷积和一个空间内核选择机制组成。
Large Kernel Convolutions & Spatial Kernel Selection
根据 Introduction 中所说的先验(2),建议对一系列的多个尺度的背景进行建模,以进行适应性选择。因此,我们建议通过明确地将其分解为一连串具有大的卷积核和不断扩张的 depth-wise 卷积来构建一个更大感受野的网络。其序列中第i个深度卷积的核大小 k、扩张率 d 和感受野 RF 的扩展定义如下:
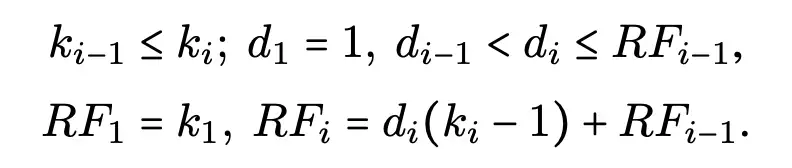
核的大小和扩张率的增加确保了感受野有足够快的扩展。我们对扩张率设定了一个上限,以保证扩张卷积不会在特征图之间引入空隙。
所提出的设计有两个优点。第一,它明确地产生了具有各种大感受野的多个特征,这使得后来的内核选择更加容易。第二,顺序分解比简单地应用一个较大的核更有效更高效。为了提高网络关注检测目标的最相关的空间背景区域的能力,我们使用了一种空间选择机制,从不同尺度的大卷积核中空间选择特征图。图 4 显示了 LSK 模块的详细概念图,在这里我们直观地展示了大选择核是如何通过自适应地收集不同物体的相应大感受野而发挥作用的。
LSK Module 的 pytorch 代码如下:
class LSKmodule(nn.Module):
def __init__(self, dim):
super().__init__()
self.conv0 = nn.Conv2d(dim, dim, 5, padding=2, groups=dim)
self.convl = nn.Conv2d(dim, dim, 7, stride=1, padding=9, groups=dim, dilation=3)
self.conv0_s = nn.Conv2d(dim, dim//2, 1)
self.conv1_s = nn.Conv2d(dim, dim//2, 1)
self.conv_squeeze = nn.Conv2d(2, 2, 7, padding=3)
self.conv_m = nn.Conv2d(dim//2, dim, 1)
def forward(self, x):
attn1 = self.conv0(x)
attn2 = self.convl(attn1)
attn1 = self.conv0_s(attn1)
attn2 = self.conv1_s(attn2)
attn = torch.cat([attn1, attn2], dim=1)
avg_attn = torch.mean(attn, dim=1, keepdim=True)
max_attn, _ = torch.max(attn, dim=1, keepdim=True)
agg = torch.cat([avg_attn, max_attn], dim=1)
sig = self.conv_squeeze(agg).sigmoid()
attn = attn1 * sig[:,0,:,:].unsqueeze(1) + attn2 * sig[:,1,:,:].unsqueeze(1)
attn = self.conv_m (attn)
return x * attn

方法
在我们的实验中,我们报告了 HRSC2016、DOTA-v1.0 和 FAIR1M-v1.0 数据集上的检测模型结果。为了保证公平性,我们遵循与其他主流方法相同的数据集处理方法和训练方式(如 -Net, Oriented RCNN, R3Det...)。
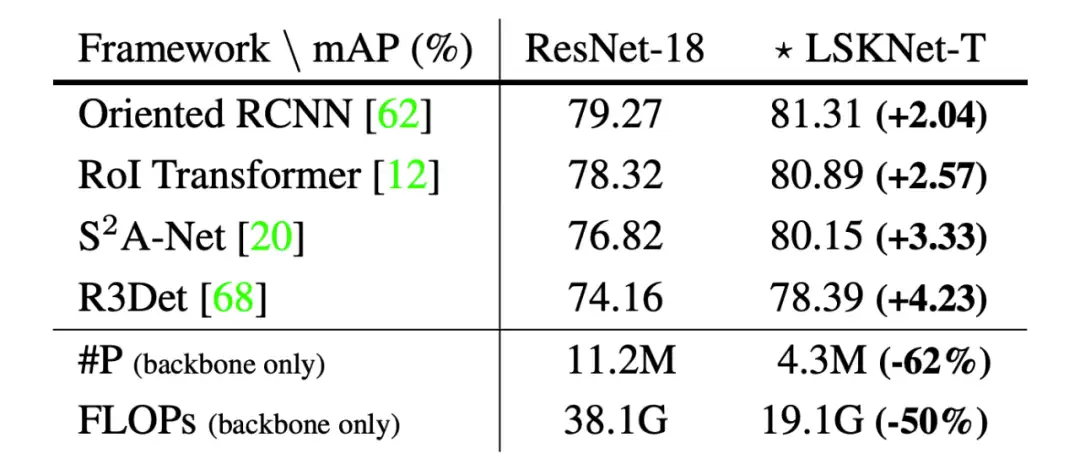 ▲ 表1. LSKNet-T和ResNet-18作为骨干网在DOTA-v1.0上的不同检测框架的比较。LSKNet-T骨干网在ImageNet上进行了100次预训练。与ResNet-18相比,轻量级的LSKNet-T在各种框架中取得了明显更高的mAP。
▲ 表1. LSKNet-T和ResNet-18作为骨干网在DOTA-v1.0上的不同检测框架的比较。LSKNet-T骨干网在ImageNet上进行了100次预训练。与ResNet-18相比,轻量级的LSKNet-T在各种框架中取得了明显更高的mAP。
在不同检测框架下,使用我们的 LSKNet 骨干,模型更轻量,对检测模型性能提升巨大!(表 1)
 ▲ 表2. 在DOTA-v1.0的O-RCNN框架下,LSKNet-S和其他(大核/选择性注意)骨干的比较,除了Prev Best是在RTMDet下。所有骨干网都在ImageNet上进行了100次预训练。我们的LSKNet在类似的复杂度预算下实现了最佳的mAP,同时超过了之前的最佳公开记录。
▲ 表2. 在DOTA-v1.0的O-RCNN框架下,LSKNet-S和其他(大核/选择性注意)骨干的比较,除了Prev Best是在RTMDet下。所有骨干网都在ImageNet上进行了100次预训练。我们的LSKNet在类似的复杂度预算下实现了最佳的mAP,同时超过了之前的最佳公开记录。
在相同检测框架的不同骨干网络(大卷积核和选择性机制的骨干网络)中,在相似模型复杂的的前提下,我们的 LSKNet 骨干 mAP 更强!(表 2)
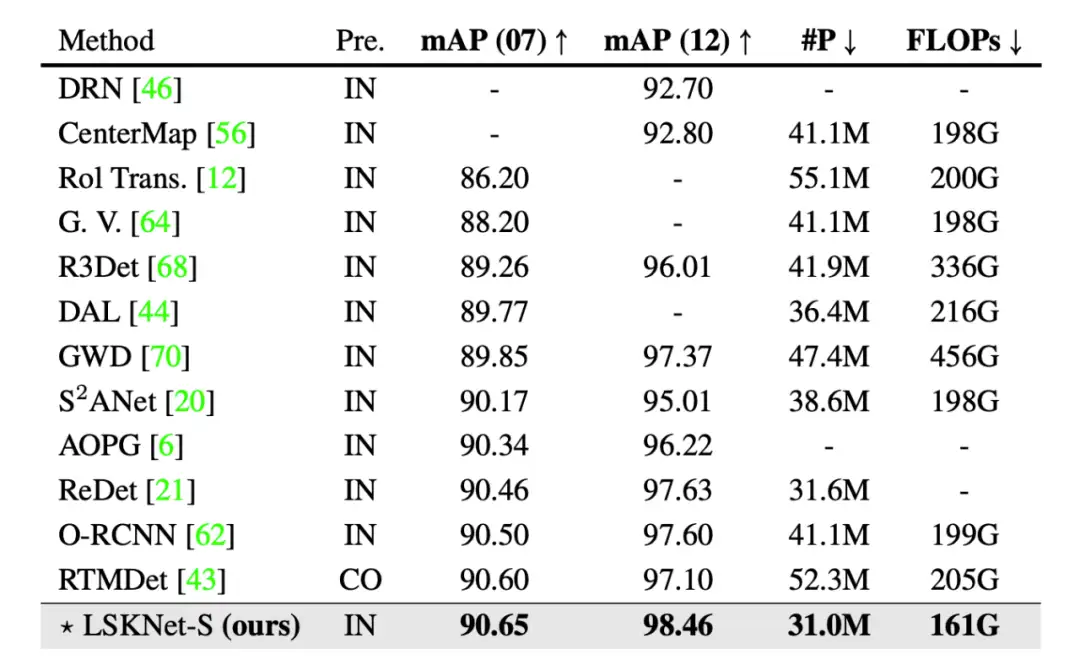 ▲ 表3. 在HRSC2016数据集上与最先进的方法比较
▲ 表3. 在HRSC2016数据集上与最先进的方法比较
在 HRSC2016 数据集上,性能超越之前所有的方法!(表 3)
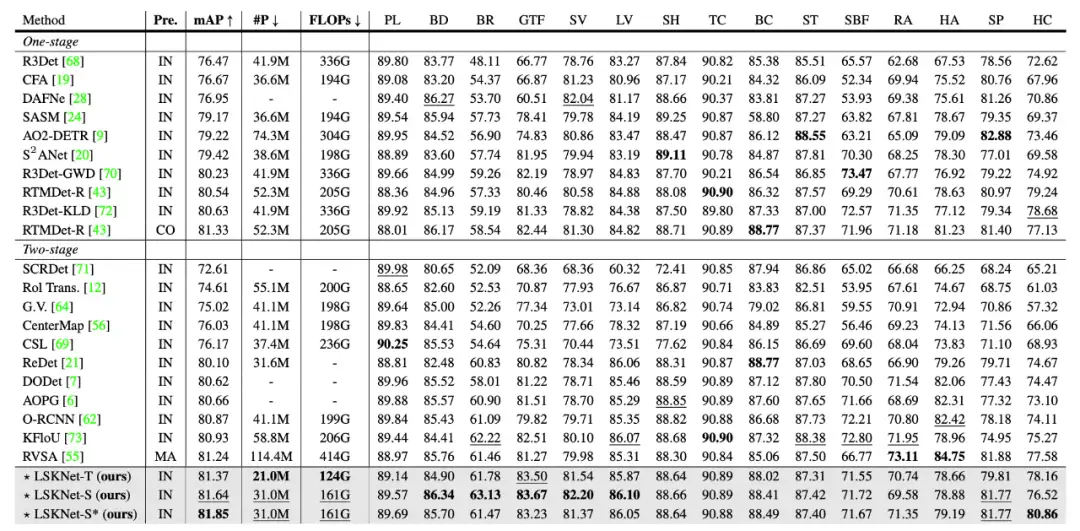 ▲ 表4. 在多尺度训练和测试的DOTA-v1.0数据集上与最先进的方法进行比较
▲ 表4. 在多尺度训练和测试的DOTA-v1.0数据集上与最先进的方法进行比较
在 DOTA-v1.0 数据集上,性能超越之前所有的方法!(表 4)在此数据集上,(近期的方法在性能上近乎饱和,最近的 SOTA 方法 RVSA 用了极为重量的模型和在庞大的数据集上做预训练才勉强突破 0.81 的 mAP,RTMDet 则是在 COCO 预训练,36epoch 加 EMA 的微调方式,而其他主流方法都是 ImageNet 预训练和 12epoch w/o EMA 微调,才达到 81.33 的性能。)我们的方法在模型参数量和计算复杂度全面小于其他方法的前提下,性能刷新了新的 SOTA!
 ▲ 表5. 在FAIR1M-v1.0数据集上与最先进的方法比较。*: 结果参考了FAIR1M论文[51]。
▲ 表5. 在FAIR1M-v1.0数据集上与最先进的方法比较。*: 结果参考了FAIR1M论文[51]。
在近期中国空天院提出的 FAIR1M-v1.0 数据集上,我们也刷新了 mAP。
Ablation Study
消融实验部分,为了提高实验效率,我们采用 LSKNet-T 骨架在 ImageNet 上做 100 个 epoch 的骨干预训练。
 ▲ 表6. 分解的大核的数量对推理的FPS和mAP的影响,给定的理论感受野是29。将大核分解成两个深度方向的核,实现了速度和精度的最佳表现。
▲ 表6. 分解的大核的数量对推理的FPS和mAP的影响,给定的理论感受野是29。将大核分解成两个深度方向的核,实现了速度和精度的最佳表现。
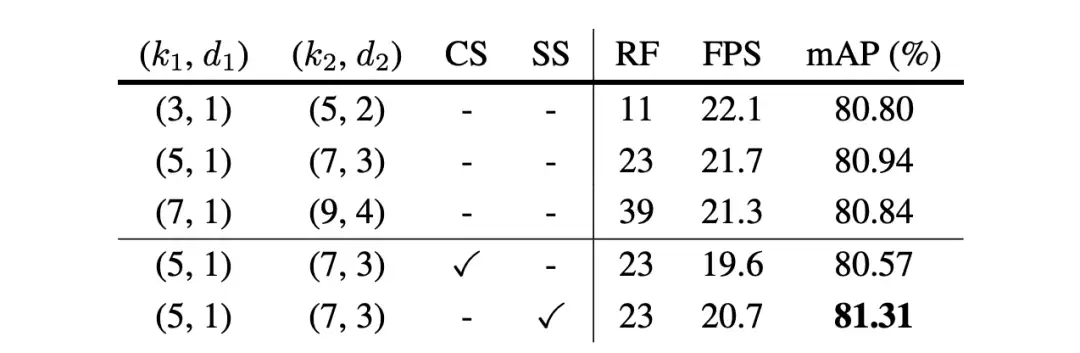 ▲ 表7. 当大卷积被分解成两个连续的depth-wise卷积时,LSKNet的关键设计组件的有效性。CS:通道选择(类似于SKNet);SS:空间选择(我们的)。LSKNet在使用一个合理的大的感受野和空间选择时取得了最佳性能。
▲ 表7. 当大卷积被分解成两个连续的depth-wise卷积时,LSKNet的关键设计组件的有效性。CS:通道选择(类似于SKNet);SS:空间选择(我们的)。LSKNet在使用一个合理的大的感受野和空间选择时取得了最佳性能。
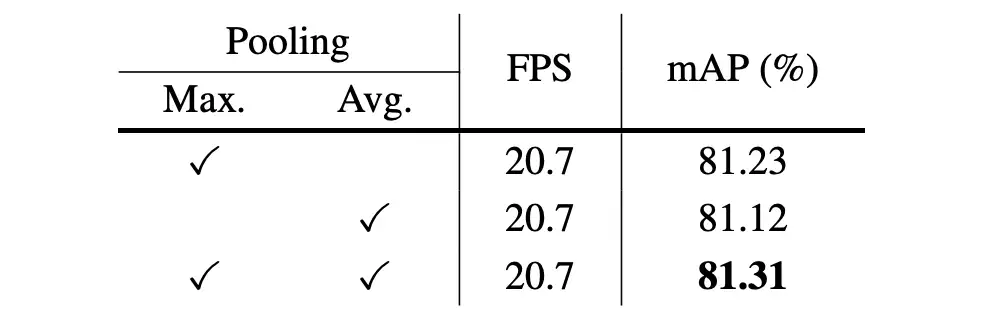 ▲ 表8. 对我们提出的LSK模块的空间选择中的最大和平均池化的有效性进行消融实验。在同时使用最大和平均池化时,获得了最好的结果。
▲ 表8. 对我们提出的LSK模块的空间选择中的最大和平均池化的有效性进行消融实验。在同时使用最大和平均池化时,获得了最好的结果。
Analysis
 ▲ 图5. 使用ResNet-50和LSKNet-S的O-RCNN检测框架的Eigen-CAM可视化。我们提出的LSKNet可以对长范围的上下文信息进行建模,从而在各种困难的情况下获得更好的性能。
▲ 图5. 使用ResNet-50和LSKNet-S的O-RCNN检测框架的Eigen-CAM可视化。我们提出的LSKNet可以对长范围的上下文信息进行建模,从而在各种困难的情况下获得更好的性能。
图 5 所示,LSKNet-S 可以捕捉到更多与检测到的目标相关的背景信息,从而在各种困难情况下有更好的表现,这证明了我们的先验(1)。
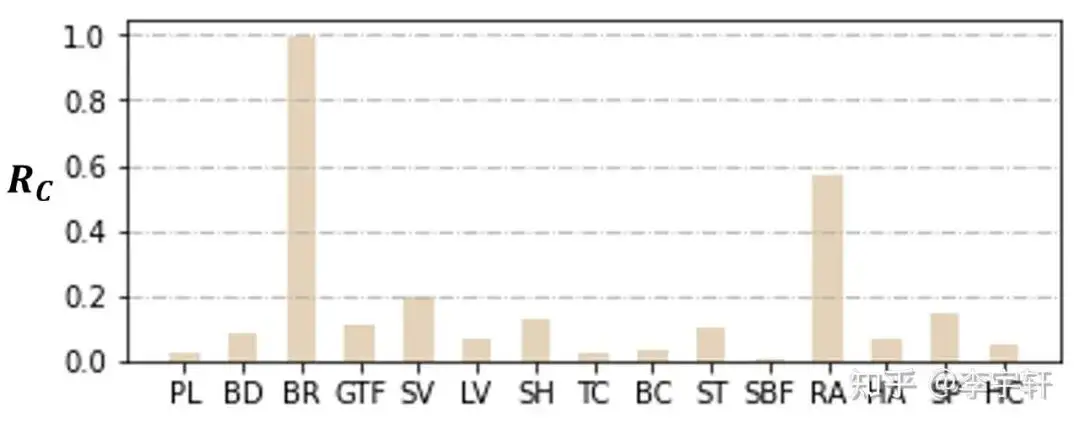 ▲ 图6. DOTA-v1.0中物体类别的预期感受野和GT框面积的比率:Rc。不同物体类别所需的相对范围有很大的不同。
▲ 图6. DOTA-v1.0中物体类别的预期感受野和GT框面积的比率:Rc。不同物体类别所需的相对范围有很大的不同。
为了研究每个物体类别的感受野范围,我们定义物体类别预期感受野和 GT 框面积的比率:Rc。此数值越大,说明目标需要的额外感受野越大。图 6 中结果表明,与其他类别相比,桥梁类别需要更多的额外上下文信息,这主要是由于它与道路的特征相似,并且需要语境线索来确定它是否被水所包围。
相反,球场类别,如足球场,由于其独特的纹理属性,特别是球场边界线,需要最少的上下文信息。这与我们的常识相吻合,并进一步支持先前的观点(2),即不同的物体类别所需的上下文信息的相对范围有很大不同。
 ▲ 图7. DOTA-v1.0中物体类别的感受野激活,其中激活图来自我们训好的LSKNet模型根据主论文公式(8)(即空间激活)得出。物体类别按照从左上到右下的顺序,据预期感受野面积和GT框面积之比递减排列(及图6中的数值顺序)
▲ 图7. DOTA-v1.0中物体类别的感受野激活,其中激活图来自我们训好的LSKNet模型根据主论文公式(8)(即空间激活)得出。物体类别按照从左上到右下的顺序,据预期感受野面积和GT框面积之比递减排列(及图6中的数值顺序)
我们进一步研究我们的 LSKNet 中的大核选择倾向性行为。我们定义了 Kernel Selection Difference(较大的感受野卷积核特征图激活值 - 较小的感受野卷积核特征图激活值)。
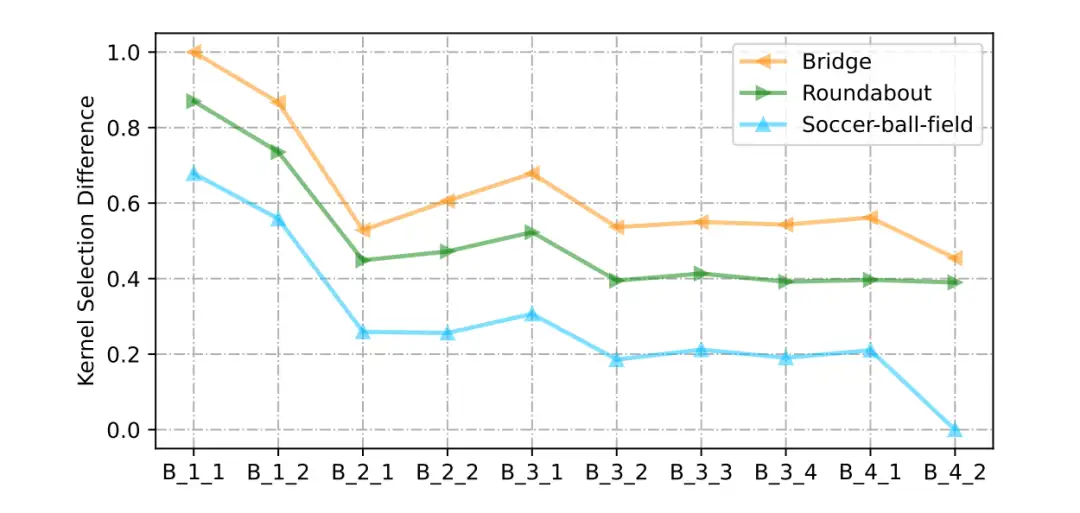 ▲ 图8. 桥梁、环岛和足球场的LSKNet-T块中的大卷积核选择差异。B i j代表第i阶段的第j个LSK Block,数值越大,表明检测时更倾向于选择有更大感受野的卷积核,对更大范围的背景的依赖性也越大。
▲ 图8. 桥梁、环岛和足球场的LSKNet-T块中的大卷积核选择差异。B i j代表第i阶段的第j个LSK Block,数值越大,表明检测时更倾向于选择有更大感受野的卷积核,对更大范围的背景的依赖性也越大。
在图 8 中,我们展示了三个典型类别的所有图像的归一化 Kernel Selection Difference:桥梁、环形路和足球场,以及每个 LSKNet-T 块的情况。正如预期的那样,Bridge 的所有块的大核的参与度高于 Roundabout,而 Roundabout 则高于 Soccer-ball-field。这与常识一致,即 Soccer-ball-field 确实不需要大量的上下文,因为它本身的纹理特征已经足够明显和具有鉴别性。
我们还出人意料地发现了 LSKNet 在网络深度上的另一种选择模式。LSKNet 通常在其浅层利用较大感受野的卷积核,而在较高的层次利用较小的。这表明,网络倾向于在网络浅层迅速扩大感受野捕捉信息,以便高层次的语义学能够包含足够的感受野,从而获得更好的辨别力。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:470899183。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
比Meta「分割一切AI」更全能!港科大版图像分割AI来了:实现更强粒度和语义功能
Meta Segment Anything会让CV没前途吗?
CVPR'2023年AQTC挑战赛第一名解决方案:以功能-交互为中心的时空视觉语言对齐方法
6万字!30个方向130篇 | CVPR 2023 最全 AIGC 论文汇总
ICCV2023 | 当尺度感知调制遇上Transformer,会碰撞出怎样的火花?
新加坡国立大学提出最新优化器:CAME,大模型训练成本降低近一半!
SegNetr来啦 | 超越UNeXit/U-Net/U-Net++/SegNet,精度更高模型更小的UNet家族
libtorch教程(一)开发环境搭建:VS+libtorch和Qt+libtorch
NeRF与三维重建专栏(三)nerf_pl源码部分解读与colmap、cuda算子使用
NeRF与三维重建专栏(二)NeRF原文解读与体渲染物理模型
BEV专栏(一)从BEVFormer深入探究BEV流程(上篇)
可见光遥感图像目标检测(三)文字场景检测之Arbitrary
AI最全资料汇总 | 基础入门、技术前沿、工业应用、部署框架、实战教程学习
标签:dim,SOTA,卷积,LSKNet,物体,遥感,ICCV,检测 From: https://www.cnblogs.com/wxkang/p/17574137.html