摘要:基于盘古大模型能力,华为云MetaStudio数字内容生产线全新升级,推出数字人模型生成服务和模型驱动服务。
近日,华为开发者大会2023 ( Cloud ) 在东莞拉开帷幕。基于盘古大模型能力,华为云MetaStudio数字内容生产线全新升级,推出数字人模型生成服务和模型驱动服务,旨在通过数字人服务和技术赋能,赋能千行百业提升数字内容创作体验和效率。
AIGC正在重构数字内容生产模式,重新定义内容力
当前,数字人逐渐成为3D互联网时代各类应用的核心入口,进入千行百业。大家常见的数字人抖音直播,营业厅的数字人客服,还有各类综艺节目如湖南台《你好星期六》节目的综艺虚拟主持人小漾等等,多种场景应用层出不穷,新形象不断呈现。
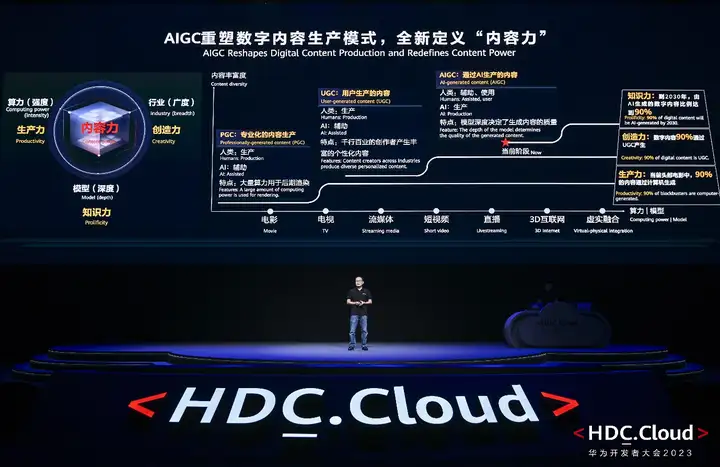
在数字内容产业,内容力决定了企业的竞争力,它由生产力、创造力和知识力逐步叠加和演进而成。PGC时代,头部电影中有90%的内容是通过计算机来生成的。生产力,也就是算力的强度决定了内容力;UGC时代,超过90%的数字内容由个人用户产生,创作者来自于千行百业。在生产力基础上,增加了创造力,也就是行业的广度,共同决定内容力;当前,我们已经进入AI时代,AIGC正在重构数字内容生产模式。到2030年,90%的内容将通过AI产生。在生产力和创造力的基础上,进一步增加了知识力,也就是模型的深度,共同决定内容力。
人人都需要自己独一无二的个性化的数字人
华为云MetaStudio数字内容生产线,基于华为云盘古基础大模型能力、渲染引擎和实时音视频能力,使用PB级的音视频数据进行训练,构建了数字人通用大模型,包括数字人形象、动作、表情、口型、声音等;每个用户还可以结合个人数据进行训练,构建自己的数字人个性化大模型。数字人生成后,用户通过文字、语音、视频等方式生产驱动向量信息,从而驱动数字人生成高清视频。
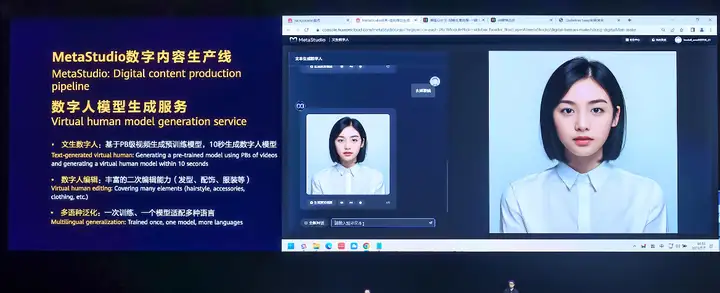
通过发布现场的演示我们可以看到,用户可通过多种方式生成数字人模型:
- 输入文字生成数字人:输入文本,描述希望生成的数字人样子,10秒生成模型。比如通过Prompt文本输入,目前支持可选50多项参数来生成数字人形象,生成时间仅需10秒,而行业的一些大模型需要30秒或者更长的时间。
- 也可以上传图片生成数字人:只需要上传一张照片,根据照片中的个人特征,生成不同类型的数字人,比如风格化和美型数字人,这个时间仅需30秒。
- 或者用户只需要拍摄一段5分钟的视频,也能生成个性化数字人模型,包含用户自己的表情、口型、动作特征,整个模型训练过程只需要1个小时。而业界一般需要训练12个小时以上。基于个性化模型生成的数字人,将保留用户的个性化形象、表情、动作、声音和口型信息。生成数字人后,可以通过对话完成对数字人的二次编辑和背景融合,比如发型、配饰、服装等,真正做到每个人的数字人都独一无二。
多模态数字人模型驱动,数字人在各行业多场景中应用
数字人生成后,预训练模型对输入的驱动方式进行分析,从多模态信息中通过深度编码器提取特征向量信息,驱动生成数字人的表情、口型、肢体动作参数,并最终生成高清视频。

驱动的方式也有多种,文字驱动可基于识别文字的语义和情感,实现数字人动作和文字的精准匹配。通过多语言泛化技术,一种语言、一次训练,即可使用多种语言驱动数字人。除此之外,现在业界大部分数字人都是站在固定点讲解,无法支持移动,华为云通过2D视频,以及2D/3D数据的联合训练,实现数字人走动、侧身、手势的精确驱动。
多模态的数字人实时驱动服务,可以广泛应用到各种各样的行业场景,比如直播、在线教育、在线客服、线上会议等。例如会议场景,通常我们默认都是关闭视频入会,一是大多数人长时间面对镜头感觉不自然、二是在办公室公共环境、酒店、家里等场合涉及隐私,不愿意打开摄像头,三是在运动的时候不方便打开摄像头。这种情况下,可以通过自己的数字人加入会议,展现形象的同时又保护了隐私,不再只显示简单的姓名信息,实现有温度的交互体验。会议过程会通过摄像头进行验证,确保是本人参会。实时驱动的时延在100ms以内,就跟我们现在开视频会议一样,没有明显延迟感觉。可以说,华为云MetaStudio数字人服务重塑了云会议的体验。
同样的,数字人在其他行业应用也可以一样简单、快速的集成数字人实时通信与互动能力,实现有温度的交互体验。华为云MetaStudio数字内容生产线全新升级,通过盘古大模型的赋能,让数字人具备个性化外形和灵魂,每个人都拥有个性化的数字人。
标签:数字,模型,生成,华为,驱动,MetaStudio From: https://www.cnblogs.com/huaweiyun/p/17550502.html