目录
一、概述
Apache DolphinScheduler(简称DolphinScheduler)是一种开源的、分布式的、易于使用的大数据工作流调度系统。它旨在为大数据处理提供一个可靠、高效和可扩展的调度解决方案。
DolphinScheduler具有以下特点和功能:
-
分布式架构:DolphinScheduler采用了分布式架构,可以在大规模集群上运行,实现高并发的任务调度和执行。
-
多种任务类型:支持多种类型的任务,包括Shell任务、Spark任务、Hadoop任务、SQL任务等,可以满足各种大数据处理需求。
-
可视化工作流编辑器:提供了直观易用的工作流编辑器,可以通过图形界面进行工作流的创建、编辑和调度管理,无需编写复杂的代码。
-
丰富的调度策略:支持灵活的调度策略,可以根据任务依赖关系、优先级、资源需求等进行调度和管理。
-
任务监控和告警:提供了实时的任务监控和告警功能,可以及时了解任务的执行情况和异常情况,并采取相应的措施进行处理。
-
安全和权限管理:支持用户认证和授权,可以对任务和资源进行细粒度的权限管理,保证系统的安全性和数据的隐私性。
-
扩展性和集成性:DolphinScheduler提供了丰富的扩展接口和插件机制,可以方便地集成到现有的大数据生态系统中,并支持自定义插件开发。
总之,Apache DolphinScheduler是一个功能强大的大数据工作流调度系统,可以帮助用户实现高效、可靠的大数据处理任务调度和管理。它是开源社区的项目,用户可以根据自己的需求进行定制和扩展,并参与社区共同贡献和发展。
二、Apache DolphinScheduler 与 Azkaban 对比
Apache DolphinScheduler 和 Azkaban 都是开源的大数据工作流调度系统,用于管理和调度大数据处理任务。它们具有一些相似的特点,但也有一些区别。
相似之处:
-
工作流调度:两者都提供了工作流调度功能,可以定义任务之间的依赖关系,按照指定的调度策略和优先级来执行任务。
-
可视化编辑器:两者都提供了可视化的工作流编辑器,可以通过图形界面创建、编辑和管理工作流,减少了对复杂的脚本编写的依赖。
-
多任务类型支持:两者都支持多种类型的任务,如Shell任务、Hadoop任务、Spark任务等,可以满足各种大数据处理需求。
-
调度监控和告警:两者都提供了任务的监控和告警功能,可以实时查看任务的执行状态,并及时通知用户执行结果或异常情况。
区别之处:
-
架构设计:
DolphinScheduler采用分布式架构,可以在大规模集群上运行,支持高并发的任务调度和执行。而Azkaban采用集中式架构,适用于中小规模的集群。 -
扩展性和集成性:
DolphinScheduler提供了丰富的扩展接口和插件机制,可以方便地与其他大数据生态系统进行集成,并支持自定义插件开发。Azkaban在扩展性和集成性方面相对较弱。 -
权限管理:
DolphinScheduler支持用户认证和授权,可以对任务和资源进行细粒度的权限管理。Azkaban也支持权限管理,但在细粒度控制方面较弱。 -
社区发展和支持:DolphinScheduler是一个新兴的开源项目,社区活跃度逐渐增加,但相对于Azkaban来说,社区支持和文档资源相对较少。
选择使用 Apache DolphinScheduler 还是 Azkaban 取决于具体的需求和情况。如果您需要一个高可扩展性和灵活性的调度系统,并且希望与其他大数据生态系统进行深度集成,DolphinScheduler 可能是一个不错的选择。如果您的集群规模较小,并且对权限管理的要求不是很高,同时希望使用一个经过长期发展和广泛使用的调度系统,Azkaban 可能更适合您的需求。
三、DolphinScheduler 架构设计
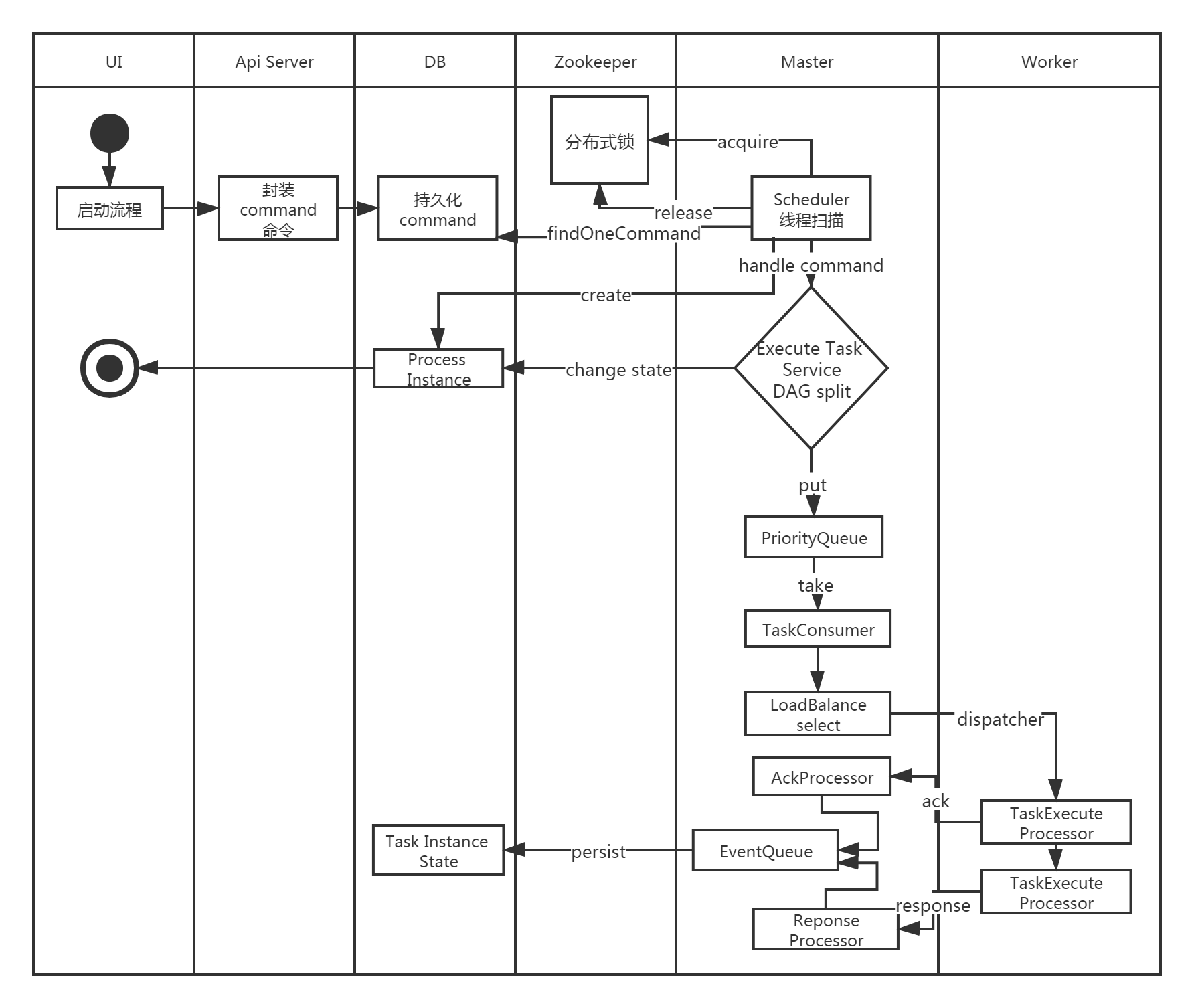
启动流程活动图
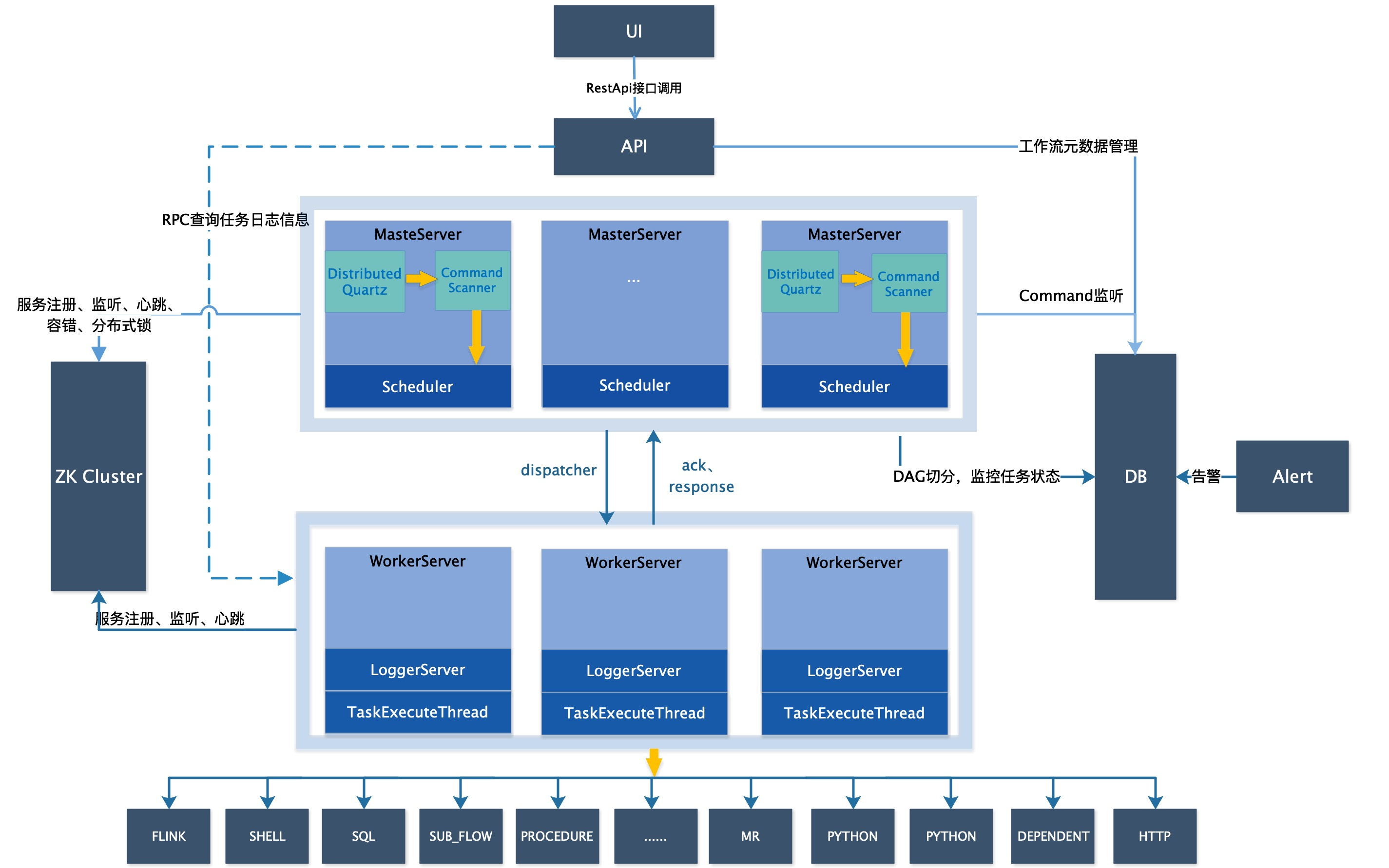
架构说明
-
MasterServer:MasterServer采用分布式无中心设计理念,MasterServer主要负责DAG任务切分、任务提交监控,并同时监听其它MasterServer和WorkerServer的健康状态。MasterServer服务启动时向Zookeeper注册临时节点,通过监听Zookeeper临时节点变化来进行容错处理。MasterServer基于netty提供监听服务。该服务内主要包含:
-
DistributedQuartz分布式调度组件,主要负责定时任务的启停操作,当quartz调起任务后,Master内部会有线程池具体负责处理任务的后续操作; -
MasterSchedulerService是一个扫描线程,定时扫描数据库中的t_ds_command表,根据不同的命令类型进行不同的业务操作; -
WorkflowExecuteRunnable主要是负责DAG任务切分、任务提交监控、各种不同事件类型的逻辑处理; -
TaskExecuteRunnable主要负责任务的处理和持久化,并生成任务事件提交到工作流的事件队列; -
EventExecuteService主要负责工作流实例的事件队列的轮询; -
StateWheelExecuteThread主要负责工作流和任务超时、任务重试、任务依赖的轮询,并生成对应的工作流或任务事件提交到工作流的事件队列; -
FailoverExecuteThread主要负责Master容错和Worker容错的相关逻辑;
-
-
WorkerServer:WorkerServer也采用分布式无中心设计理念,WorkerServer主要负责任务的执行和提供日志服务。WorkerServer服务启动时向Zookeeper注册临时节点,并维持心跳。WorkerServer基于netty提供监听服务。该服务包含:
-
WorkerManagerThread主要负责任务队列的提交,不断从任务队列中领取任务,提交到线程池处理; -
TaskExecuteThread主要负责任务执行的流程,根据不同的任务类型进行任务的实际处理; -
RetryReportTaskStatusThread主要负责定时轮询向Master汇报任务的状态,直到Master回复状态的ack,避免任务状态丢失;
-
-
ZooKeeper:ZooKeeper服务,系统中的MasterServer和WorkerServer节点都通过ZooKeeper来进行集群管理和容错。另外系统还基于ZooKeeper进行事件监听和分布式锁。 我们也曾经基于Redis实现过队列,不过我们希望DolphinScheduler依赖到的组件尽量地少,所以最后还是去掉了Redis实现。 -
AlertServer:提供告警服务,通过告警插件的方式实现丰富的告警手段。 -
ApiServer:API接口层,主要负责处理前端UI层的请求。该服务统一提供RESTful api向外部提供请求服务。 -
UI:系统的前端页面,提供系统的各种可视化操作界面。
这里只是摘录了官方文档部分内容,更多内容可以参考官方文档:https://dolphinscheduler.apache.org/zh-cn/docs/3.1.7/architecture/design
四、环境部署
1)环境信息
| IP | 主机名 | 角色 |
|---|---|---|
| 192.168.182.110 | local-168-182-110 | master-server、api-server、alert-server、ZK、MySQL |
| 192.168.182.111 | local-168-182-111 | master-server、worker-server |
| 192.168.182.112 | local-168-182-112 | worker-server |
2)安装 JDK
官网下载:https://www.oracle.com/java/technologies/downloads/
百度云下载
链接:https://pan.baidu.com/s/1-rgW-Z-syv24vU15bmMg1w
提取码:8888
# 编辑/etc/profile,文末插入以下内容:
# set java
export JAVA_HOME=/opt/apache/jdk1.8.0_212
export PATH=$JAVA_HOME/bin:$PATH
3)安装 MySQL 数据库
这里选择docker快速部署的方式:通过 docker-compose 快速部署 MySQL保姆级教程
1、部署 docker
# 安装yum-config-manager配置工具
yum -y install yum-utils
# 建议使用阿里云yum源:(推荐)
#yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
# 安装docker-ce版本
yum install -y docker-ce
# 启动并开机启动
systemctl enable --now docker
docker --version
2、部署 docker-compose
curl -SL https://github.com/docker/compose/releases/download/v2.16.0/docker-compose-linux-x86_64 -o /usr/local/bin/docker-compose
chmod +x /usr/local/bin/docker-compose
docker-compose --version
3、安装 git
yum -y install git
3、开始部署
git clone https://gitee.com/hadoop-bigdata/docker-compose-mysql.git
cd docker-compose-mysql
# create network
docker network create hadoop-network
# 部署
docker-compose -f docker-compose.yaml up -d
# 查看
docker-compose -f docker-compose.yaml ps
# 登录mysql
mysql -uroot -p
# 输入密码:123456
# 创建数据库
create database dolphinscheduler character set utf8 ;
CREATE USER 'dolphinscheduler'@'%'IDENTIFIED BY 'dolphinscheduler@123';
GRANT ALL PRIVILEGES ON dolphinscheduler.* TO 'dolphinscheduler'@'%';
FLUSH PRIVILEGES;
4)安装注册中心 Zookeeper
这里选择docker快速部署的方式:【中间件】通过 docker-compose 快速部署 Zookeeper 保姆级教程
git clone https://gitee.com/hadoop-bigdata/docker-compose-zookeeper.git
cd docker-compose-zookeeper
# 部署
docker-compose -f docker-compose.yaml up -d
# 查看
docker-compose -f docker-compose.yaml ps
5)下载 dolphinscheduler 安装包
wget https://dlcdn.apache.org/dolphinscheduler/3.1.7/apache-dolphinscheduler-3.1.7-bin.tar.gz --no-check-certificate
# 解压
tar -xvzf apache-dolphinscheduler-*-bin.tar.gz
注意:
DolphinScheduler本身不依赖 Hadoop、Hive、Spark,但如果你运行的任务需要依赖他们,就需要有对应的环境支持。
6)修改配置
1、修改 install_env.sh 文件
文件 install_env.sh 描述了哪些机器将被安装 DolphinScheduler 以及每台机器对应安装哪些服务。
bin/env/install_env.sh
配置
# ---------------------------------------------------------
# INSTALL MACHINE
# ---------------------------------------------------------
# 需要配置master、worker、API server,所在服务器的IP均为机器IP或者localhost
# 如果是配置hostname的话,需要保证机器间可以通过hostname相互链接
# 如下图所示,部署 DolphinScheduler 机器的 hostname 为 ds1,ds2,ds3,ds4,ds5,其中 ds1,ds2 安装 master 服务,ds3,ds4,ds5安装 worker 服务,alert server安装在ds4中,api server 安装在ds5中
# ips="ds1,ds2,ds3,ds4,ds5"
ips="192.168.182.110,192.168.182.111,192.168.182.112"
# masters="ds1,ds2"
masters="192.168.182.110,192.168.182.111"
# workers="ds3:default,ds4:default,ds5:default"
workers="192.168.182.111:default,192.168.182.112:default"
# alertServer="ds4"
alertServer="192.168.182.110"
# apiServers="ds5"
apiServers="192.168.182.110"
2、修改 dolphinscheduler_env.sh 文件
文件 ./bin/env/dolphinscheduler_env.sh 描述了下列配置:
DolphinScheduler的数据库配置,详细配置方法见初始化数据库- 一些任务类型外部依赖路径或库文件,如
JAVA_HOME和SPARK_HOME都是在这里定义的 - 注册中心
zookeeper - 服务端相关配置,比如缓存,时区设置等。
如果您不使用某些任务类型,您可以忽略任务外部依赖项,但您必须根据您的环境更改 JAVA_HOME、注册中心和数据库相关配置。
# JAVA_HOME, will use it to start DolphinScheduler server
# export JAVA_HOME=${JAVA_HOME:-/opt/soft/java}
export JAVA_HOME=/opt/apache/jdk1.8.0_212
# Database related configuration, set database type, username and password
# export DATABASE=${DATABASE:-postgresql}
export DATABASE=${DATABASE:-mysql}
export SPRING_PROFILES_ACTIVE=${DATABASE}
# export SPRING_DATASOURCE_URL="jdbc:postgresql://127.0.0.1:5432/dolphinscheduler"
export SPRING_DATASOURCE_URL="jdbc:mysql://192.168.182.110:3306/dolphinscheduler?useUnicode=true&characterEncoding=UTF-8&useSSL=false"
# export SPRING_DATASOURCE_USERNAME={user}
export SPRING_DATASOURCE_USERNAME=dolphinscheduler
# export SPRING_DATASOURCE_PASSWORD={password}
export SPRING_DATASOURCE_PASSWORD=dolphinscheduler@123
# DolphinScheduler server related configuration
export SPRING_CACHE_TYPE=${SPRING_CACHE_TYPE:-none}
export SPRING_JACKSON_TIME_ZONE=${SPRING_JACKSON_TIME_ZONE:-UTC}
export MASTER_FETCH_COMMAND_NUM=${MASTER_FETCH_COMMAND_NUM:-10}
# Registry center configuration, determines the type and link of the registry center
export REGISTRY_TYPE=${REGISTRY_TYPE:-zookeeper}
# export REGISTRY_ZOOKEEPER_CONNECT_STRING=${REGISTRY_ZOOKEEPER_CONNECT_STRING:-localhost:2181}
export REGISTRY_ZOOKEEPER_CONNECT_STRING="192.168.182.110:31181,192.168.182.110:32181,192.168.182.110:33181"
# Tasks related configurations, need to change the configuration if you use the related tasks.
export HADOOP_HOME=${HADOOP_HOME:-/opt/soft/hadoop}
export HADOOP_CONF_DIR=${HADOOP_CONF_DIR:-/opt/soft/hadoop/etc/hadoop}
export SPARK_HOME1=${SPARK_HOME1:-/opt/soft/spark1}
export SPARK_HOME2=${SPARK_HOME2:-/opt/soft/spark2}
export PYTHON_HOME=${PYTHON_HOME:-/opt/soft/python}
export HIVE_HOME=${HIVE_HOME:-/opt/soft/hive}
export FLINK_HOME=${FLINK_HOME:-/opt/soft/flink}
export DATAX_HOME=${DATAX_HOME:-/opt/soft/datax}
export PATH=$HADOOP_HOME/bin:$SPARK_HOME1/bin:$SPARK_HOME2/bin:$PYTHON_HOME/bin:$JAVA_HOME/bin:$HIVE_HOME/bin:$FLINK_HOME/bin:$DATAX_HOME/bin:$PATH
3、下载MySQL驱动包
wget https://repo1.maven.org/maven2/mysql/mysql-connector-java/8.0.16/mysql-connector-java-8.0.16.jar
mv mysql-connector-java-8.0.16.jar tools/libs/
cp tools/libs/mysql-connector-java-8.0.16.jar master-server/libs/
cp tools/libs/mysql-connector-java-8.0.16.jar worker-server/libs/
cp tools/libs/mysql-connector-java-8.0.16.jar alert-server/libs/
cp tools/libs/mysql-connector-java-8.0.16.jar api-server/libs/
【注意】除了将
mysql-connector-java-8.0.16.jar驱动放到以上的libs文件夹后,还需要将mysql-connector-java-8.0.16.jar驱动放到tools目录下的libs目录一份。
7)将配置copy其它节点
scp -r /opt/apache/dolphinscheduler local-168-182-111:/opt/apache/
scp -r /opt/apache/dolphinscheduler local-168-182-112:/opt/apache/
8)初始化数据库
bash tools/bin/upgrade-schema.sh
9)启动服务
因为机器资源有限,这里调整一下jvm内存
# master-server/bin/start.sh
# api-server/bin/start.sh
# alert-server/bin/start.sh
# ./worker-server/bin/start.sh
根据规划,分别在不同机器上启动对应的服务
| IP | 主机名 | 角色 |
|---|---|---|
| 192.168.182.110 | local-168-182-110 | master-server、api-server、alert-server、ZK、MySQL |
| 192.168.182.111 | local-168-182-111 | master-server、worker-server |
| 192.168.182.112 | local-168-182-112 | worker-server |
# 启停 Master
bash ./bin/dolphinscheduler-daemon.sh start master-server
# 查看日志
tail -f master-server/logs/dolphinscheduler-master.log
# bash ./bin/dolphinscheduler-daemon.sh stop master-server
# 启停 Api
bash ./bin/dolphinscheduler-daemon.sh start api-server
# 查看日志
tail -f api-server/logs/dolphinscheduler-api.log
# bash ./bin/dolphinscheduler-daemon.sh stop api-server
# 启停 Alert
bash ./bin/dolphinscheduler-daemon.sh start alert-server
# 查看日志
tail -f alert-server/logs/dolphinscheduler-alert.log
# bash ./bin/dolphinscheduler-daemon.sh stop alert-server
# 启停 Worker
bash ./bin/dolphinscheduler-daemon.sh start worker-server
# 查看日志
tail -f worker-server/logs/dolphinscheduler-worker.log
# bash ./bin/dolphinscheduler-daemon.sh stop worker-server
10)web 地址访问
# http://<your_ip>:12345/dolphinscheduler/ui/login
http://192.168.182.110:12345/dolphinscheduler/ui/login
默认账户密码:admin/dolphinscheduler123
Apache DolphinScheduler(海豚调度系统)介绍与环境部署 就到这里了,有任何疑问环境给我留言或私信,可关注我公众号:大数据与云原生技术分享,加群交流或私信沟通~
