10.WordCount示例编写(一)
任务目的
- 理解 WordCount 示例的业务逻辑
- 掌握 MapReduce Map 端编程规范
- 理解 WordCount 示例 Map 端的自定义业务逻辑的编写
任务清单
- 任务1:WordCount 的业务逻辑
- 任务2:WordCount Map 端程序编写
详细任务步骤
任务1:WordCount 的业务逻辑
MapTask 阶段处理每个数据分块的单词统计分析,思路是将每一行文本拆分成一个个的单词,每遇到一个单词则把其转换成一个 key-value 对,比如单词 Car,就转换成<’Car’,1>发送给 ReduceTask 去汇总。
ReduceTask 阶段将接收 MapTask 的结果,按照 key 对 value 做汇总计数。
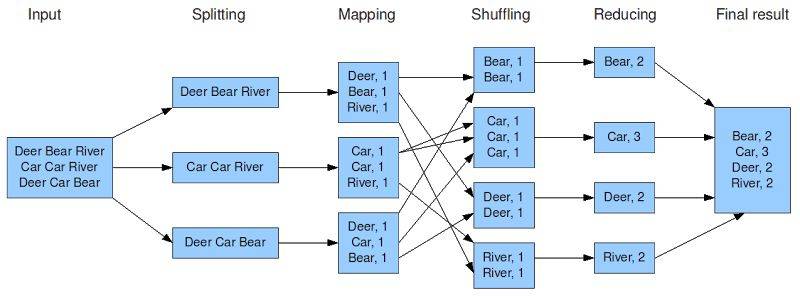
图1
任务2:WordCount Map 端程序编写
回顾 MapReduce Map 端编码规范:
1. 用户自定义的 Mapper 需要继承父类 Mapper
2. Mapper 的输入数据是 KV 对的形式(KV 的类型可自定义)
3. Mapper 的输出数据是 KV 对的形式(KV 的类型可自定义)
4. Mapper 中的业务逻辑写在 map() 方法 中
5. MapTask 进程对每一个<K,V>调用一次map()方法
接下来进入 WordCount Map 端程序的编写,eclipse 成功连接到 Hadoop 集群后,选择“File”->“New”->“Project”->“Map/Reduce Project”创建名为 MyMR 的项目名,在此项目下创建名为com.hongyaa.mr的包名,在此包下创建名为 WordCountMapper.java 的类,如下图所示:

图2
首先编写 Map 端编程框架,自定义的 WordCountMapper 需要继承父类 Mapper,输入数据和输出数据都是KV 对的形式。具体框架代码如下:
public class WordCountMapper extends Mapper<KEYIN,VALUEIN,KEYOUT,VALUEOUT> {
}
- KEYIN:是指框架读取到的数据的key的类型,在默认的InputFormat下,读到的key是一行文本的起始偏移量,所以key的类型是Long,对应 Hadoop 中的 LongWritable
- VALUEIN:是指框架读取到的数据的value的类型,在默认的InputFormat下,读到的value是一行文本的内容,所以value的类型是String,对应 Hadoop 中的 Text
- KEYOUT:用户自定义逻辑方法返回数据中key的类型,由用户业务逻辑决定,在此WordCount程序中,我们输出的key是单词,所以是String,对应 Hadoop 中的 Text
- VALUEOUT:用户自定义逻辑方法返回数据中value的类型,由用户业务逻辑决定,在此WordCount程序中,我们输出的value是单词的数量,所以是Integer,对应 Hadoop 中的 IntWritable
将框架中的KV对对应的类型修改完成后的代码如下所示:
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
}
已知 Mapper 中的业务逻辑写在 map() 方法中,在此 map()方法中我们需要实现的是将读取到的每一行文本拆分成一个个的单词,每遇到一个单词则把其转换成一个 key-value 对,比如单词 Car,就转换成<’Car’,1>发送给 ReduceTask 去汇总。具体代码如下所示:
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//(1)将MapTask传给我们的文本内容先转换成String
String line = value.toString();
//(2)根据空格将这一行切分成单词
String[] words = line.split(" ");
//(3)将单词输出为<单词,1>
for (String word : words) {
//将单词作为key,将次数1作为value,以便后续的数据分发,可以根据单词分发,将相同单词分发到同一个ReduceTask中
context.write(new Text(word), new IntWritable(1));
}
}
WordCountMapper.java 的完整代码如下所示:
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
/**
* Map阶段的业务逻辑需写在自定义的map()方法中
* MapTask会对每一行输入数据调用一次我们自定义的map()方法
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//(1)将MapTask传给我们的文本内容先转换成String
String line = value.toString();
//(2)根据空格将这一行切分成单词
String[] words = line.split(" ");
//(3)将单词输出为<单词,1>
for (String word : words) {
// 将单词作为key,将次数1作为value,以便后续的数据分发,可以根据单词分发,将相同单词分发到同一个ReduceTask中
context.write(new Text(word), new IntWritable(1));
}
}
}