大多数大型语言模型(LLM)都无法在消费者硬件上进行微调。例如,650亿个参数模型需要超过780 Gb的GPU内存。这相当于10个A100 80gb的gpu。就算我们使用云服务器,花费的开销也不是所有人都能够承担的。
而QLoRa (Dettmers et al., 2023),只需使用一个A100即可完成此操作。
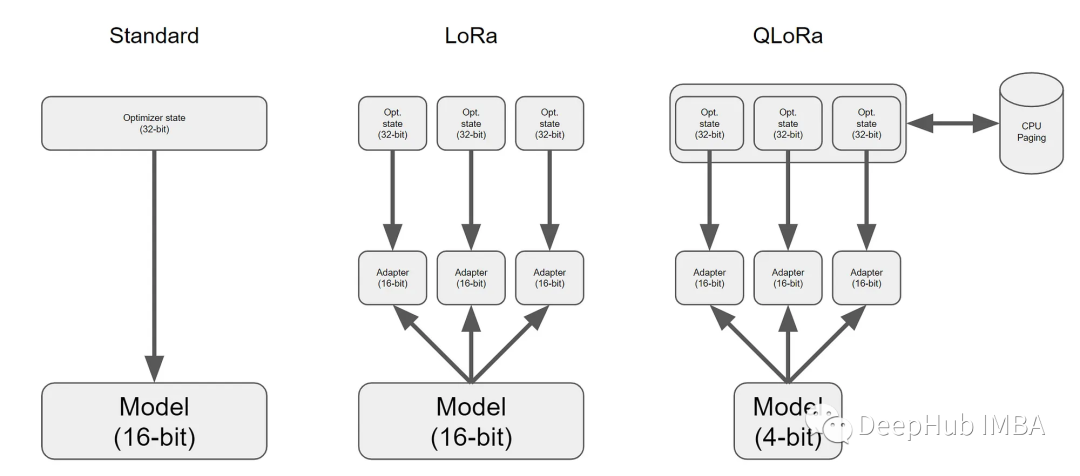
在这篇文章中将介绍QLoRa。包括描述它是如何工作的,以及如何使用它在GPU上微调具有200亿个参数的GPT模型。
为了进行演示,本文使用nVidia RTX 3060 12 GB来运行本文中的所有命令。这样可以保证小显存的要求,并且也保证可以使用免费的Google Colab实例来实现相同的结果。但是,如果你只有较小内存的GPU,则必须使用较小的LLM。
完整文章:
https://avoid.overfit.cn/post/4c4c86e3f7974157a7a8e81c57a0f8a4
标签:A100,QLoRa,模型,微调,使用,GPU From: https://www.cnblogs.com/deephub/p/17450875.html