摘要:在并发场景中,Java SDK中提供了ReadWriteLock来满足读多写少的场景。
本文分享自华为云社区《【高并发】基于ReadWriteLock开了个一款高性能缓存》,作者:冰 河。
写在前面
在实际工作中,有一种非常普遍的并发场景:那就是读多写少的场景。在这种场景下,为了优化程序的性能,我们经常使用缓存来提高应用的访问性能。因为缓存非常适合使用在读多写少的场景中。而在并发场景中,Java SDK中提供了ReadWriteLock来满足读多写少的场景。本文我们就来说说使用ReadWriteLock如何实现一个通用的缓存中心。
本文涉及的知识点有:

读写锁
说起读写锁,相信小伙伴们并不陌生。总体来说,读写锁需要遵循以下原则:
- 一个共享变量允许同时被多个读线程读取到。
- 一个共享变量在同一时刻只能被一个写线程进行写操作。
- 一个共享变量在被写线程执行写操作时,此时这个共享变量不能被读线程执行读操作。
这里,需要小伙伴们注意的是:读写锁和互斥锁的一个重要的区别就是:读写锁允许多个线程同时读共享变量,而互斥锁不允许。所以,在高并发场景下,读写锁的性能要高于互斥锁。但是,读写锁的写操作是互斥的,也就是说,使用读写锁时,一个共享变量在被写线程执行写操作时,此时这个共享变量不能被读线程执行读操作。
读写锁支持公平模式和非公平模式,具体是在ReentrantReadWriteLock的构造方法中传递一个boolean类型的变量来控制。
public ReentrantReadWriteLock(boolean fair) {
sync = fair ? new FairSync() : new NonfairSync();
readerLock = new ReadLock(this);
writerLock = new WriteLock(this);
}
另外,需要注意的一点是:在读写锁中,读锁调用newCondition()会抛出UnsupportedOperationException异常,也就是说:读锁不支持条件变量。
缓存实现
这里,我们使用ReadWriteLock快速实现一个缓存的通用工具类,总体代码如下所示。
public class ReadWriteLockCache<K,V> {
private final Map<K, V> m = new HashMap<>();
private final ReadWriteLock rwl = new ReentrantReadWriteLock();
// 读锁
private final Lock r = rwl.readLock();
// 写锁
private final Lock w = rwl.writeLock();
// 读缓存
public V get(K key) {
r.lock();
try { return m.get(key); }
finally { r.unlock(); }
}
// 写缓存
public V put(K key, V value) {
w.lock();
try { return m.put(key, value); }
finally { w.unlock(); }
}
}
可以看到,在ReadWriteLockCache中,我们定义了两个泛型类型,K代表缓存的Key,V代表缓存的value。在ReadWriteLockCache类的内部,我们使用Map来缓存相应的数据,小伙伴都都知道HashMap并不是线程安全的类,所以,这里使用了读写锁来保证线程的安全性,例如,我们在get()方法中使用了读锁,get()方法可以被多个线程同时执行读操作;put()方法内部使用写锁,也就是说,put()方法在同一时刻只能有一个线程对缓存进行写操作。
这里需要注意的是:无论是读锁还是写锁,锁的释放操作都需要放到finally{}代码块中。
在以往的经验中,有两种向缓存中加载数据的方式,一种是:项目启动时,将数据全量加载到缓存中,一种是在项目运行期间,按需加载所需要的缓存数据。
接下来,我们就分别来看看全量加载缓存和按需加载缓存的方式。
全量加载缓存
全量加载缓存相对来说比较简单,就是在项目启动的时候,将数据一次性加载到缓存中,这种情况适用于缓存数据量不大,数据变动不频繁的场景,例如:可以缓存一些系统中的数据字典等信息。整个缓存加载的大体流程如下所示。
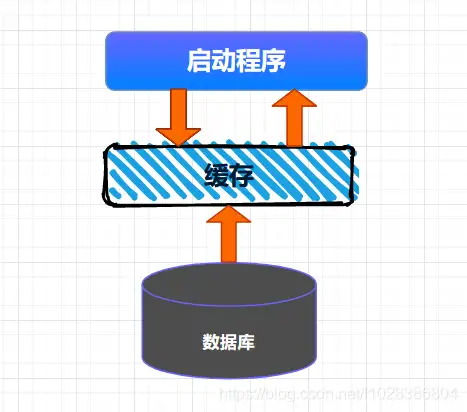
将数据全量加载到缓存后,后续就可以直接从缓存中读取相应的数据了。
全量加载缓存的代码实现比较简单,这里,我就直接使用如下代码进行演示。
public class ReadWriteLockCache<K,V> {
private final Map<K, V> m = new HashMap<>();
private final ReadWriteLock rwl = new ReentrantReadWriteLock();
// 读锁
private final Lock r = rwl.readLock();
// 写锁
private final Lock w = rwl.writeLock();
public ReadWriteLockCache(){
//查询数据库
List<Field<K, V>> list = .....;
if(!CollectionUtils.isEmpty(list)){
list.parallelStream().forEach((f) ->{
m.put(f.getK(), f.getV);
});
}
}
// 读缓存
public V get(K key) {
r.lock();
try { return m.get(key); }
finally { r.unlock(); }
}
// 写缓存
public V put(K key, V value) {
w.lock();
try { return m.put(key, value); }
finally { w.unlock(); }
}
}
按需加载缓存
按需加载缓存也可以叫作懒加载,就是说:需要加载的时候才会将数据加载到缓存。具体来说:就是程序启动的时候,不会将数据加载到缓存,当运行时,需要查询某些数据,首先检测缓存中是否存在需要的数据,如果存在,则直接读取缓存中的数据,如果不存在,则到数据库中查询数据,并将数据写入缓存。后续的读取操作,因为缓存中已经存在了相应的数据,直接返回缓存的数据即可。
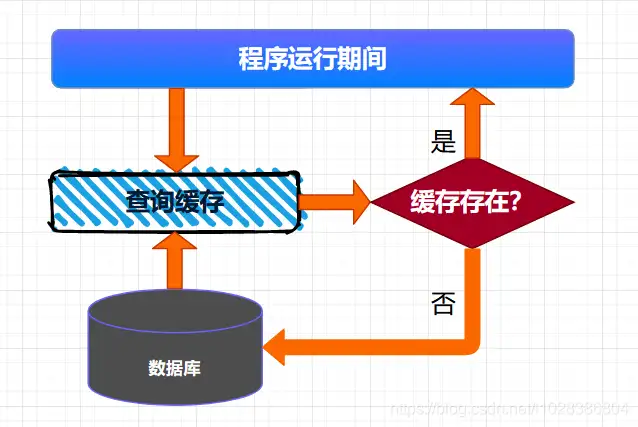
这种查询缓存的方式适用于大多数缓存数据的场景。
我们可以使用如下代码来表示按需查询缓存的业务。
class ReadWriteLockCache<K,V> {
private final Map<K, V> m = new HashMap<>();
private final ReadWriteLock rwl = new ReentrantReadWriteLock();
private final Lock r = rwl.readLock();
private final Lock w = rwl.writeLock();
V get(K key) {
V v = null;
//读缓存
r.lock();
try {
v = m.get(key);
} finally{
r.unlock();
}
//缓存中存在,返回
if(v != null) {
return v;
}
//缓存中不存在,查询数据库
w.lock();
try {
//再次验证缓存中是否存在数据
v = m.get(key);
if(v == null){
//查询数据库
v=从数据库中查询出来的数据
m.put(key, v);
}
} finally{
w.unlock();
}
return v;
}
}
这里,在get()方法中,首先从缓存中读取数据,此时,我们对查询缓存的操作添加了读锁,查询返回后,进行解锁操作。判断缓存中返回的数据是否为空,不为空,则直接返回数据;如果为空,则获取写锁,之后再次从缓存中读取数据,如果缓存中不存在数据,则查询数据库,将结果数据写入缓存,释放写锁。最终返回结果数据。
这里,有小伙伴可能会问:为啥程序都已经添加写锁了,在写锁内部为啥还要查询一次缓存呢?
这是因为在高并发的场景下,可能会存在多个线程来竞争写锁的现象。例如:第一次执行get()方法时,缓存中的数据为空。如果此时有三个线程同时调用get()方法,同时运行到 w.lock()代码处,由于写锁的排他性。此时只有一个线程会获取到写锁,其他两个线程则阻塞在w.lock()处。获取到写锁的线程继续往下执行查询数据库,将数据写入缓存,之后释放写锁。
此时,另外两个线程竞争写锁,某个线程会获取到锁,继续往下执行,如果在w.lock()后没有v = m.get(key); 再次查询缓存的数据,则这个线程会直接查询数据库,将数据写入缓存后释放写锁。最后一个线程同样会按照这个流程执行。
这里,实际上第一个线程已经查询过数据库,并且将数据写入缓存了,其他两个线程就没必要再次查询数据库了,直接从缓存中查询出相应的数据即可。所以,在w.lock()后添加v = m.get(key); 再次查询缓存的数据,能够有效的减少高并发场景下重复查询数据库的问题,提升系统的性能。
读写锁的升降级
关于锁的升降级,小伙伴们需要注意的是:在ReadWriteLock中,锁是不支持升级的,因为读锁还未释放时,此时获取写锁,就会导致写锁永久等待,相应的线程也会被阻塞而无法唤醒。
虽然不支持锁升级,但是ReadWriteLock支持锁降级,例如,我们来看看官方的ReentrantReadWriteLock示例,如下所示。
class CachedData {
Object data;
volatile boolean cacheValid;
final ReentrantReadWriteLock rwl = new ReentrantReadWriteLock();
void processCachedData() {
rwl.readLock().lock();
if (!cacheValid) {
// Must release read lock before acquiring write lock
rwl.readLock().unlock();
rwl.writeLock().lock();
try {
// Recheck state because another thread might have
// acquired write lock and changed state before we did.
if (!cacheValid) {
data = ...
cacheValid = true;
}
// Downgrade by acquiring read lock before releasing write lock
rwl.readLock().lock();
} finally {
rwl.writeLock().unlock(); // Unlock write, still hold read
}
}
try {
use(data);
} finally {
rwl.readLock().unlock();
}
}
}}
数据同步问题
首先,这里说的数据同步指的是数据源和数据缓存之间的数据同步,说的再直接一点,就是数据库和缓存之间的数据同步。
这里,我们可以采取三种方案来解决数据同步的问题,如下图所示
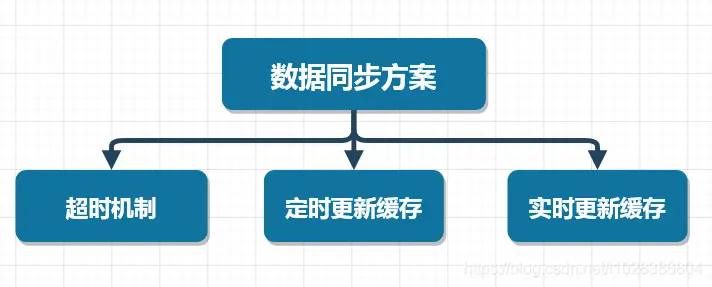
超时机制
这个比较好理解,就是在向缓存写入数据的时候,给一个超时时间,当缓存超时后,缓存的数据会自动从缓存中移除,此时程序再次访问缓存时,由于缓存中不存在相应的数据,查询数据库得到数据后,再将数据写入缓存。
定时更新缓存
这种方案是超时机制的增强版,在向缓存中写入数据的时候,同样给一个超时时间。与超时机制不同的是,在程序后台单独启动一个线程,定时查询数据库中的数据,然后将数据写入缓存中,这样能够在一定程度上避免缓存的穿透问题。
标签:缓存,通用,ReadWriteLock,rwl,线程,lock,数据,加载 From: https://www.cnblogs.com/huaweiyun/p/17442837.html