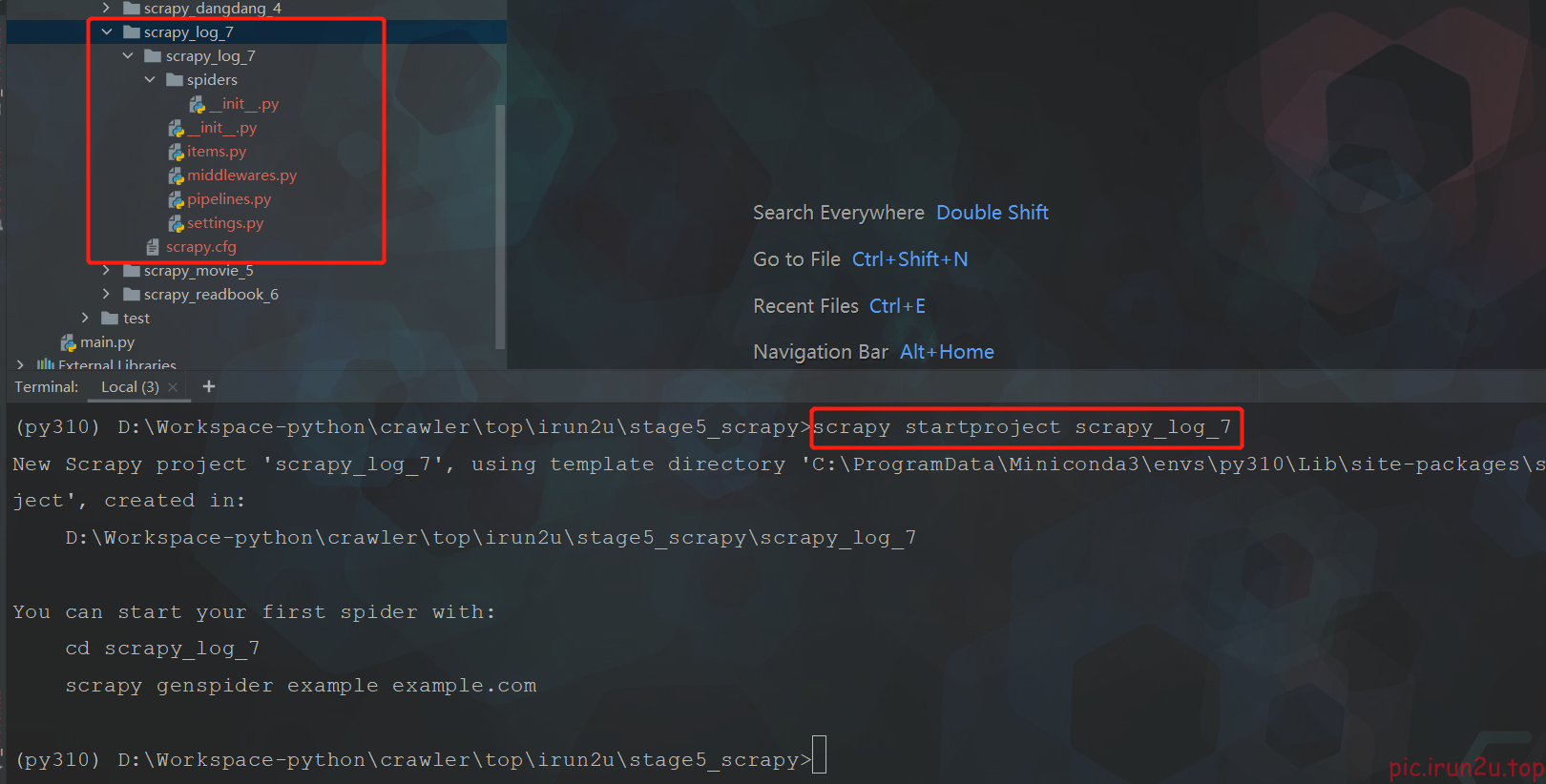
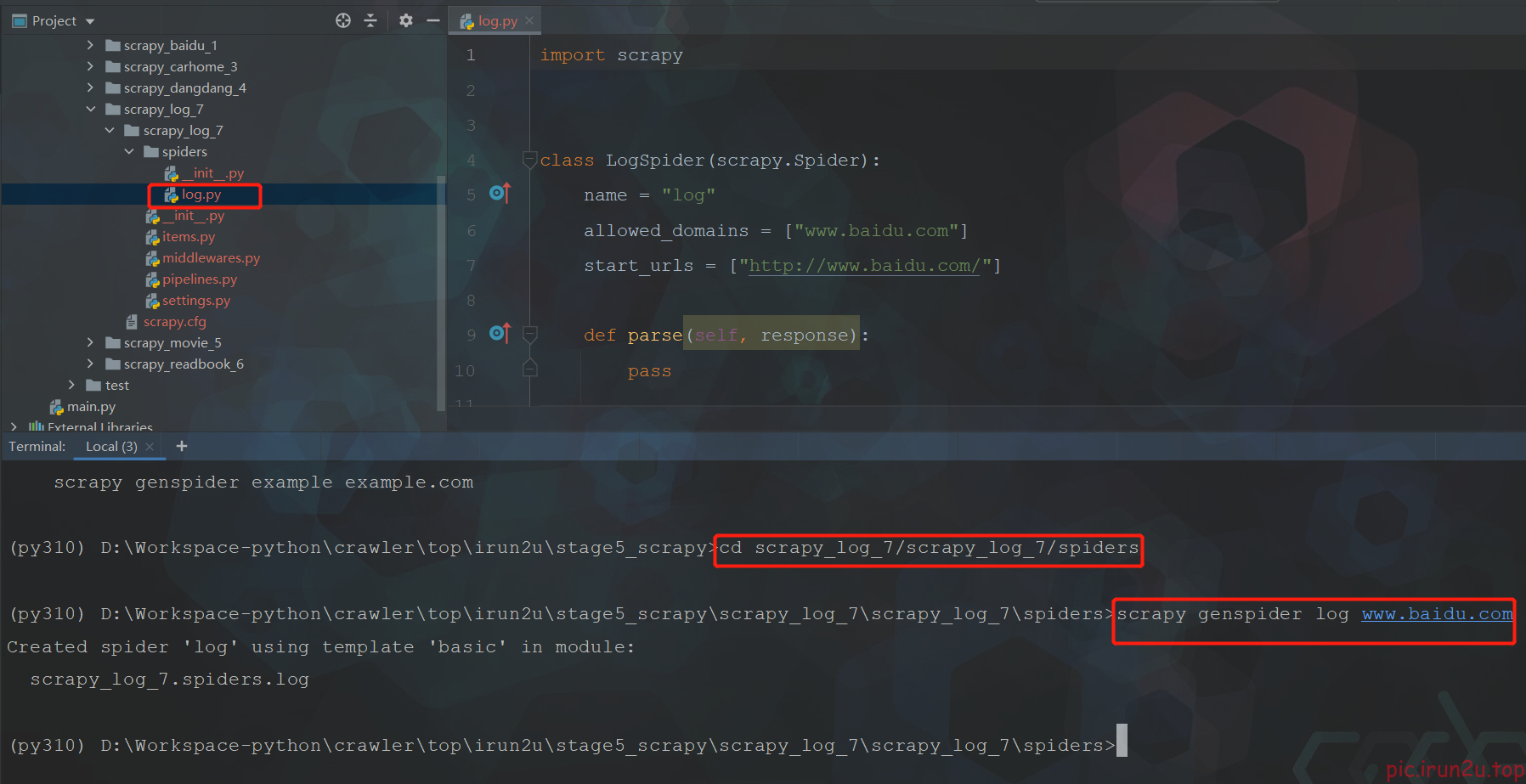
1. scrapy的日志信息设置

配置文件settings.py设置:
默认的级别为DEBUG,会显示上面所有的信息
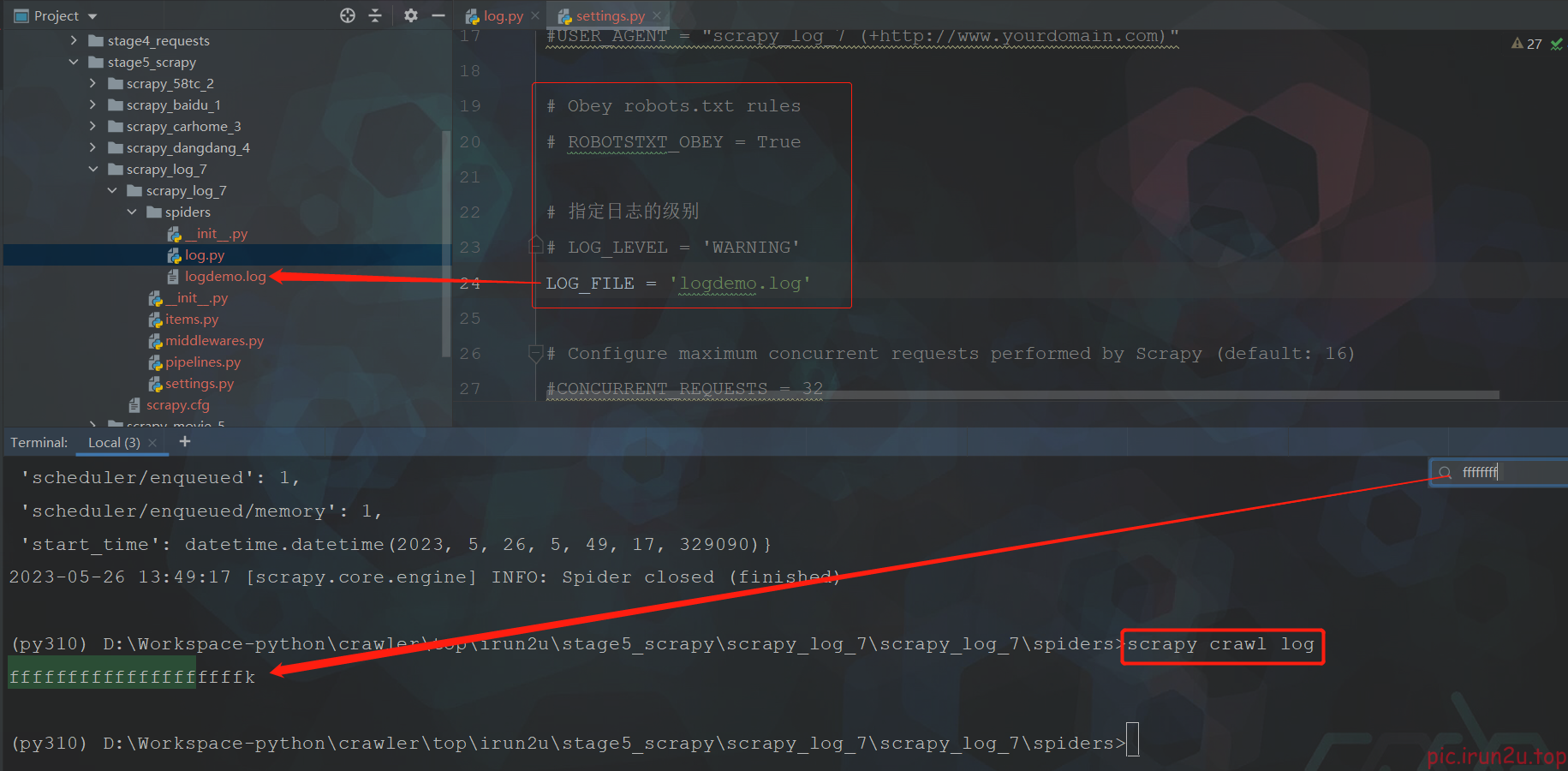
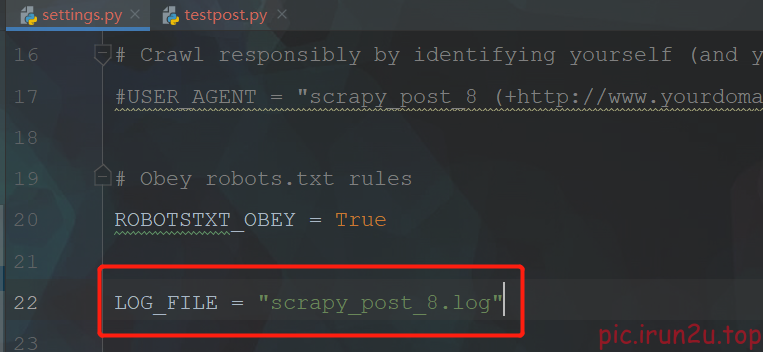
LOG_FILE : 将屏幕显示的信息全部记录到文件中,屏幕不再显示,注意文件后缀一定是.log
LOG_LEVEL : 设置日志显示的等级,就是显示哪些,不显示哪些
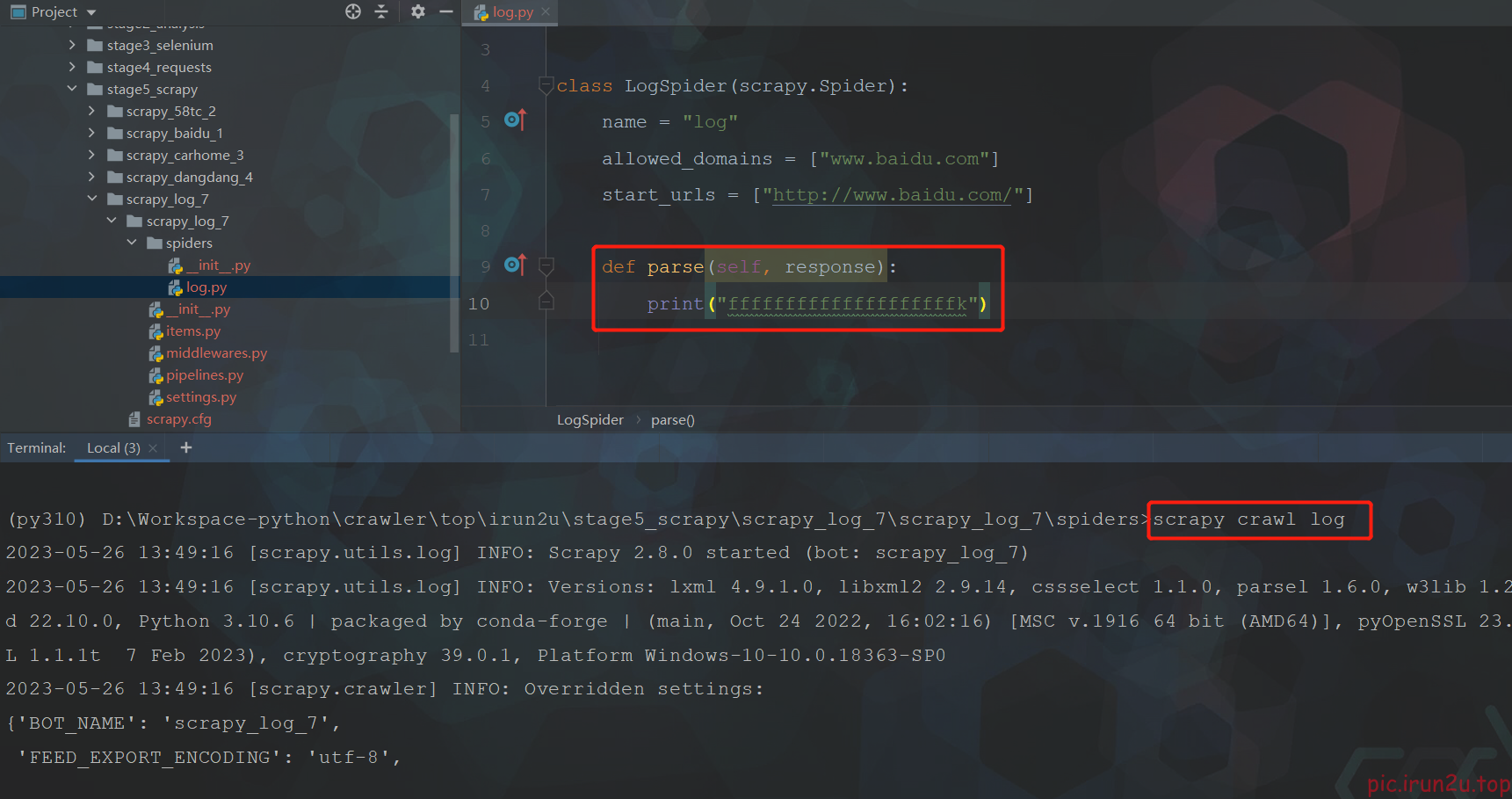
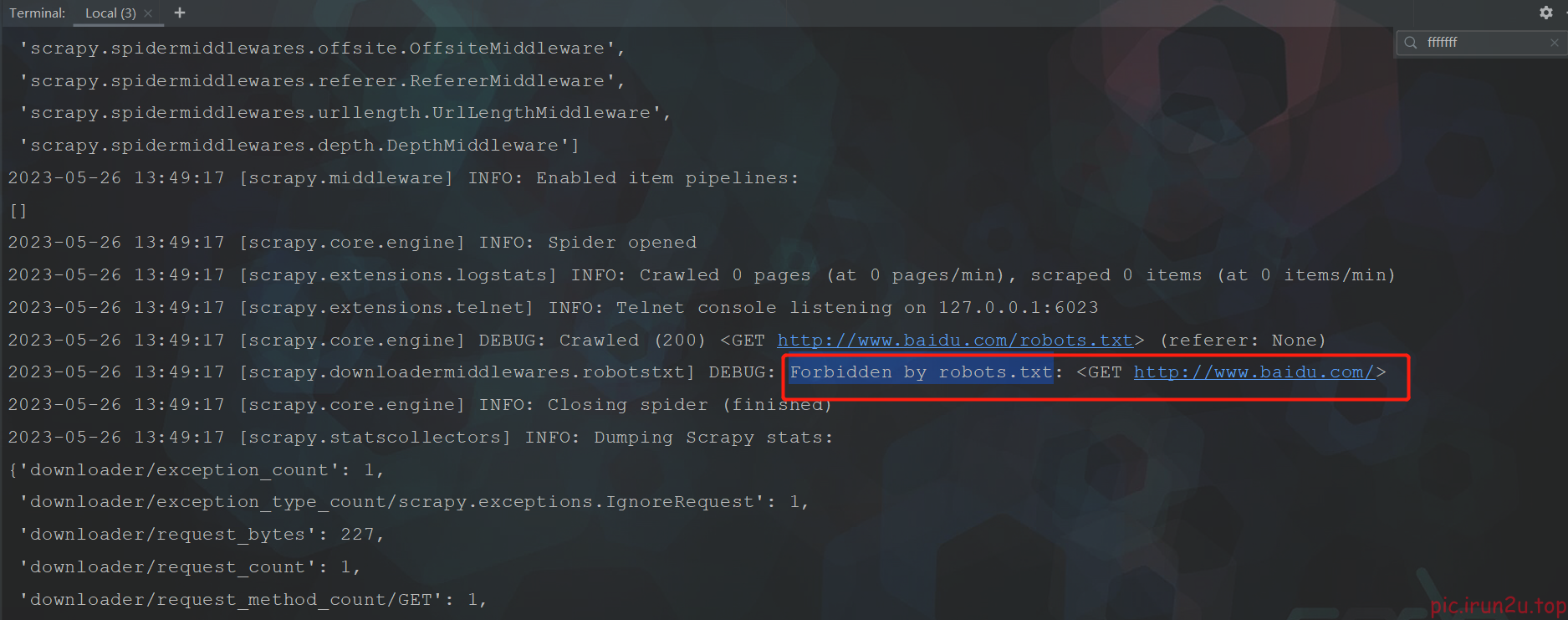
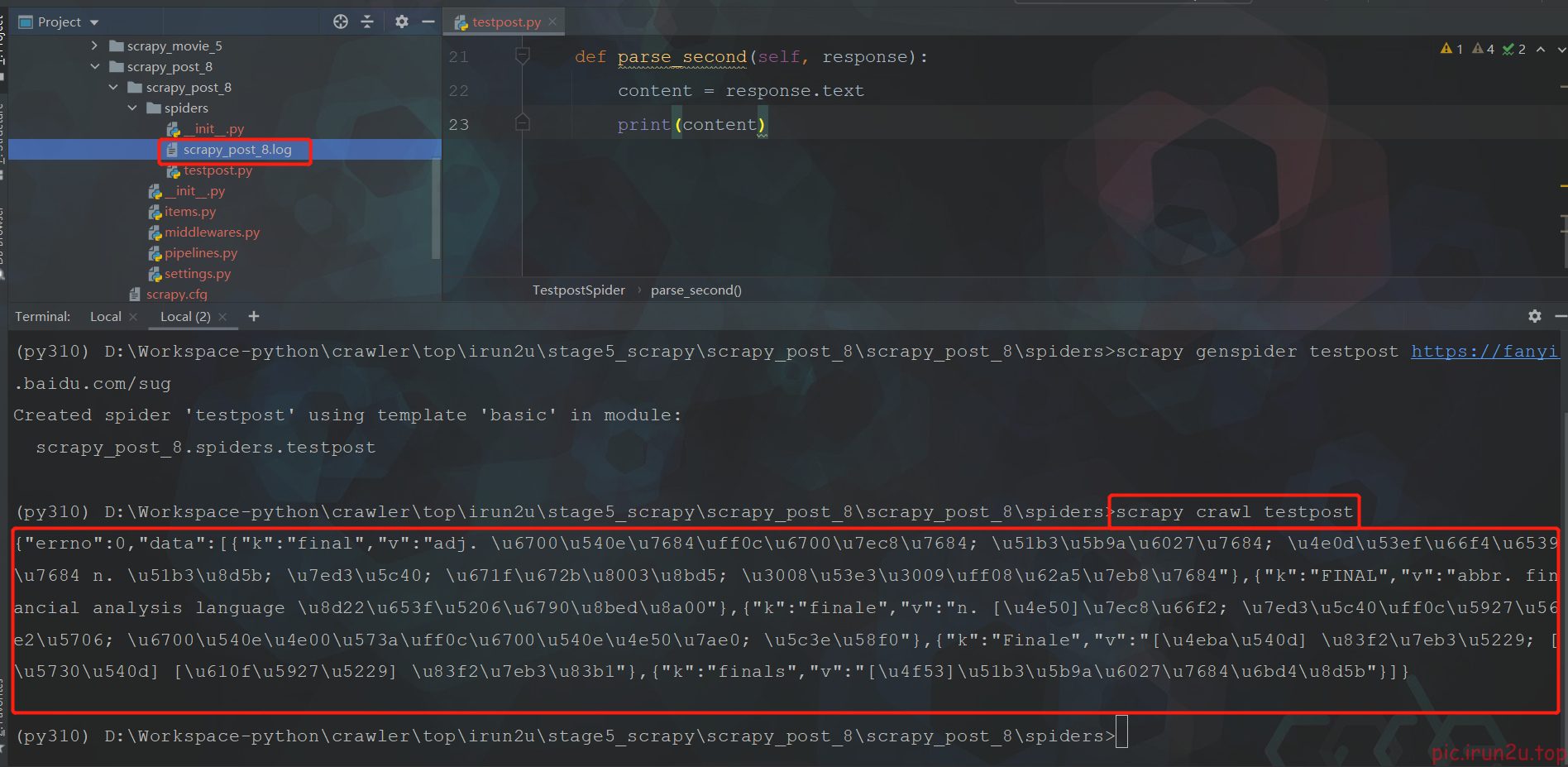
并没有正常打印,并且提示被百度反爬了,需要设置一下(settings.py)
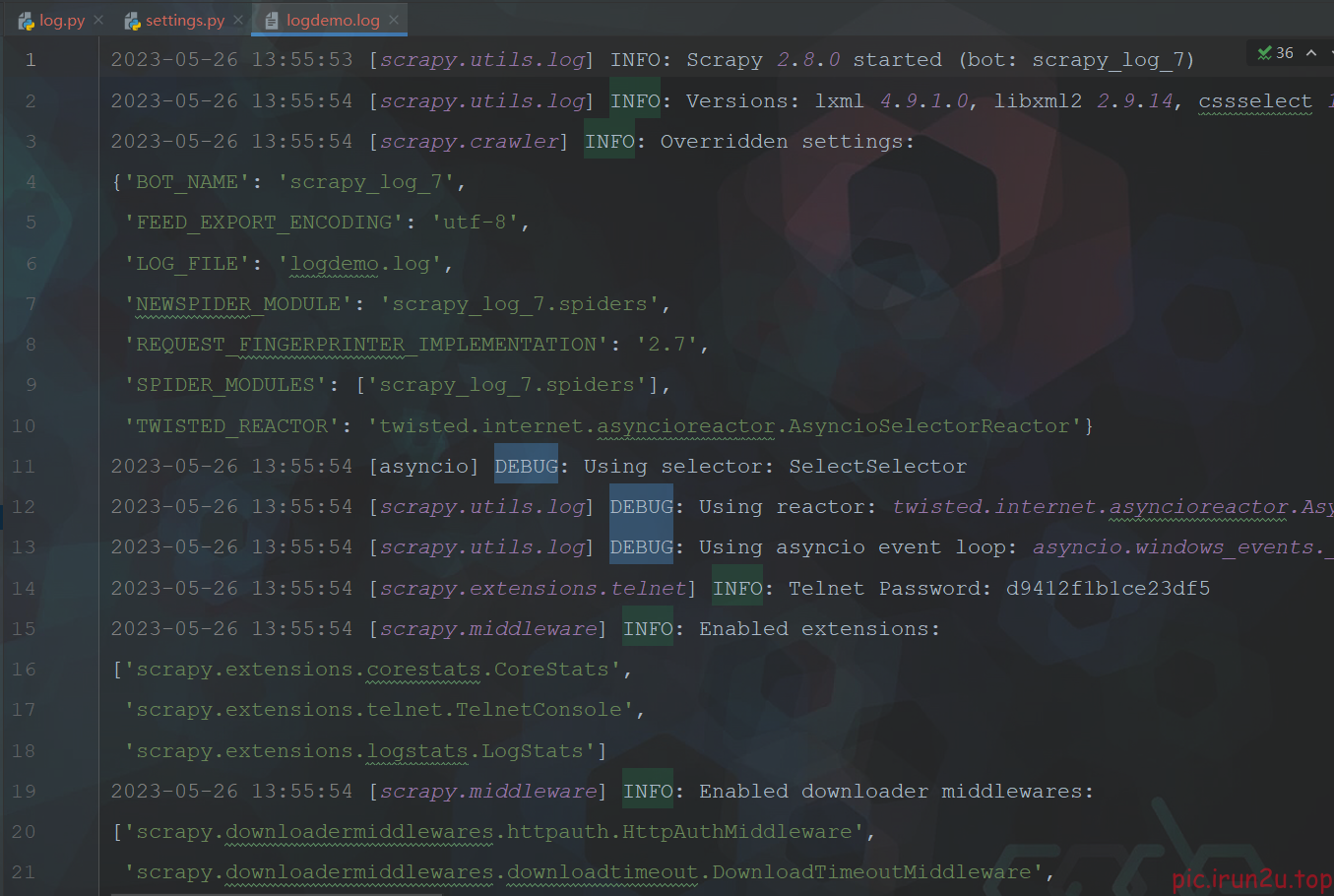
可以看到正常情况下日志比较多,顺便设置一下
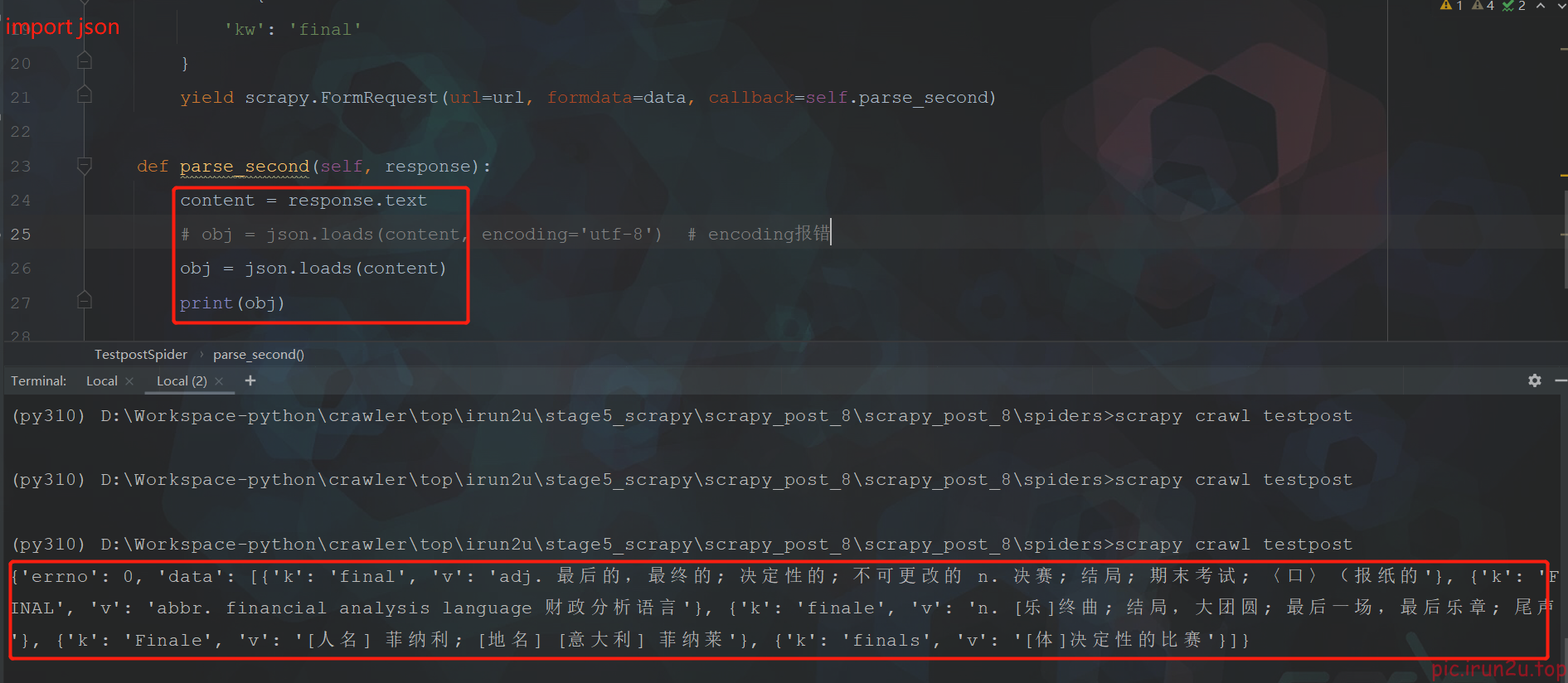
2. scrapy的post请求

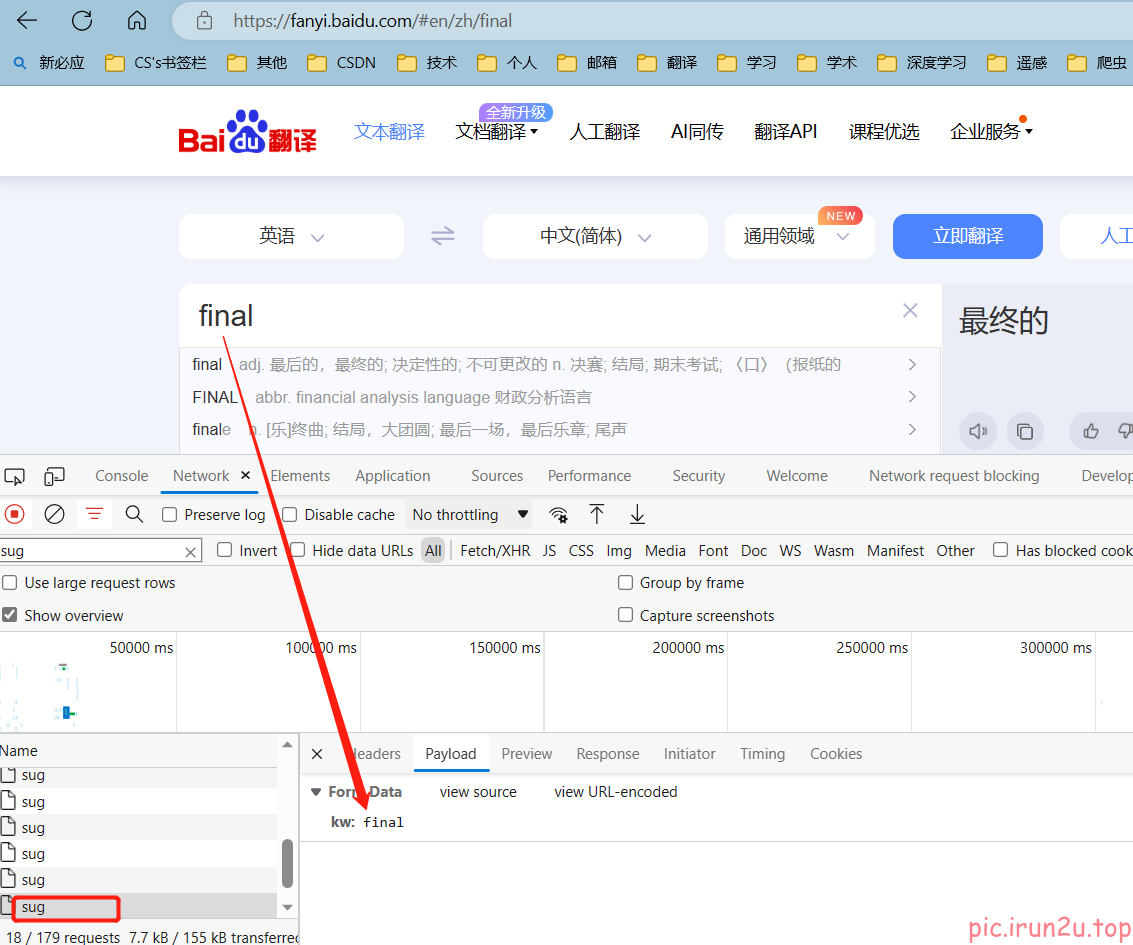
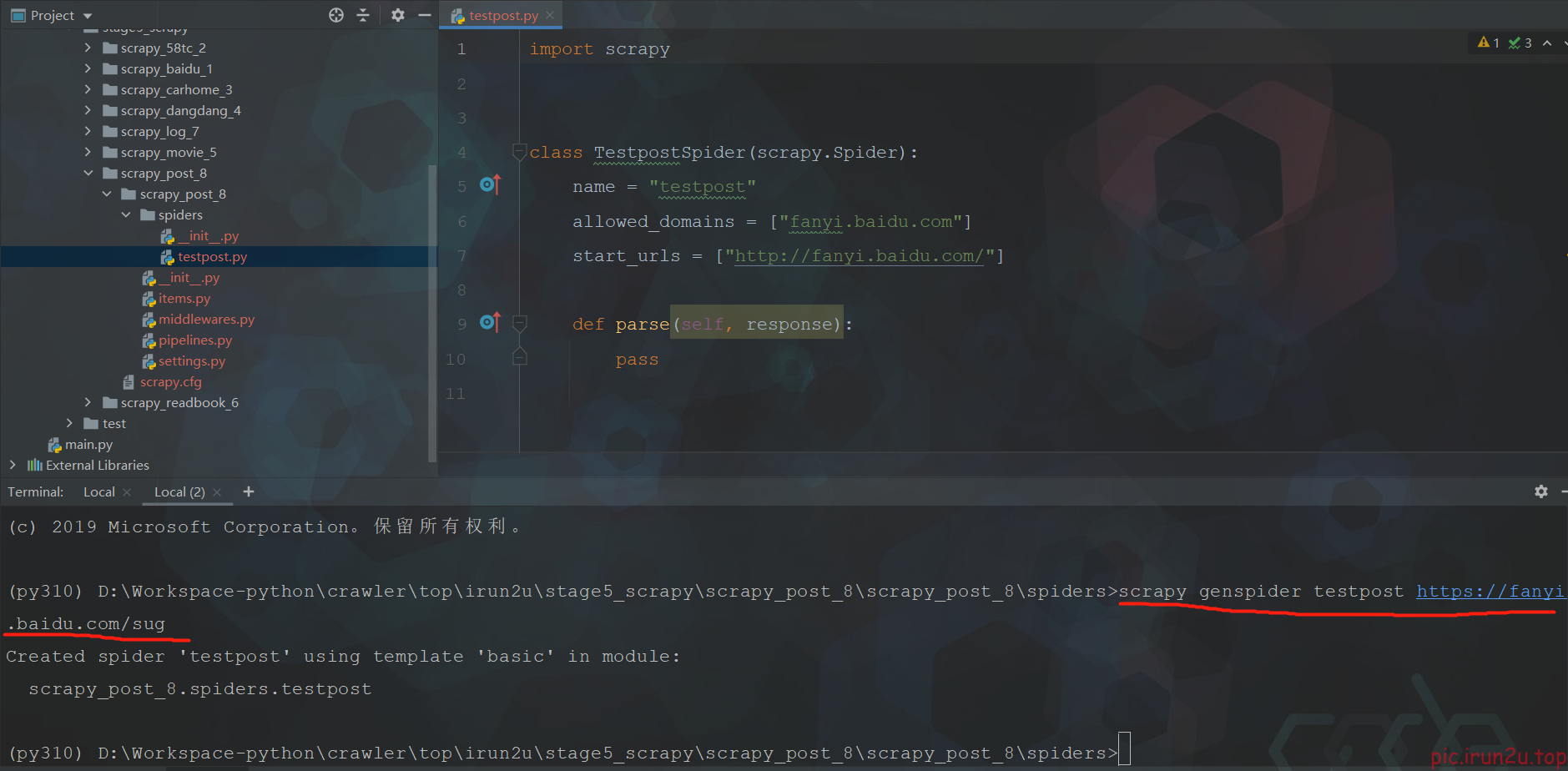
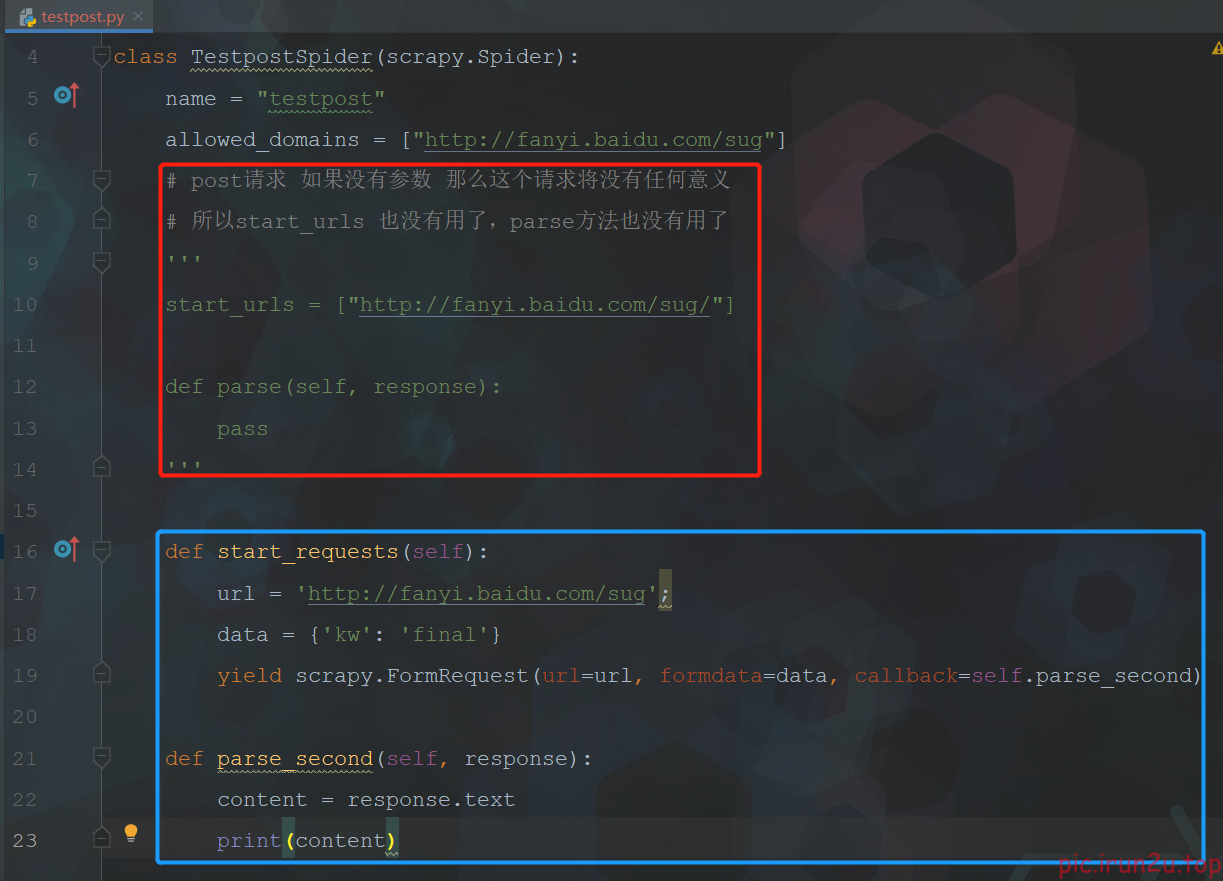
3. scrapy的代理

配置文件settings.py设置:
默认的级别为DEBUG,会显示上面所有的信息
LOG_FILE : 将屏幕显示的信息全部记录到文件中,屏幕不再显示,注意文件后缀一定是.log
LOG_LEVEL : 设置日志显示的等级,就是显示哪些,不显示哪些
并没有正常打印,并且提示被百度反爬了,需要设置一下(settings.py)
可以看到正常情况下日志比较多,顺便设置一下