摘要
作者提出了CLIP-S4,借助自监督像素表示学习和V-L模型实现各种语义分割任务,不需要使用任何像素级别标注以及未知类的信息。作者首先通过对图像的不同增强视角进行像素-分割对比学习来学习像素嵌入。之后,为进一步改善像素嵌入并实现基于自然语言的语义分割,作者设计了由V-L模型指导的嵌入一致性以及语义一致性。与SOTA的无监督/基于语言的语义分割方法相比,作者的方法在四个benchmarks上取得了突出的表现,且在未知类别识别方面显示出了大幅度的优越性。
方法
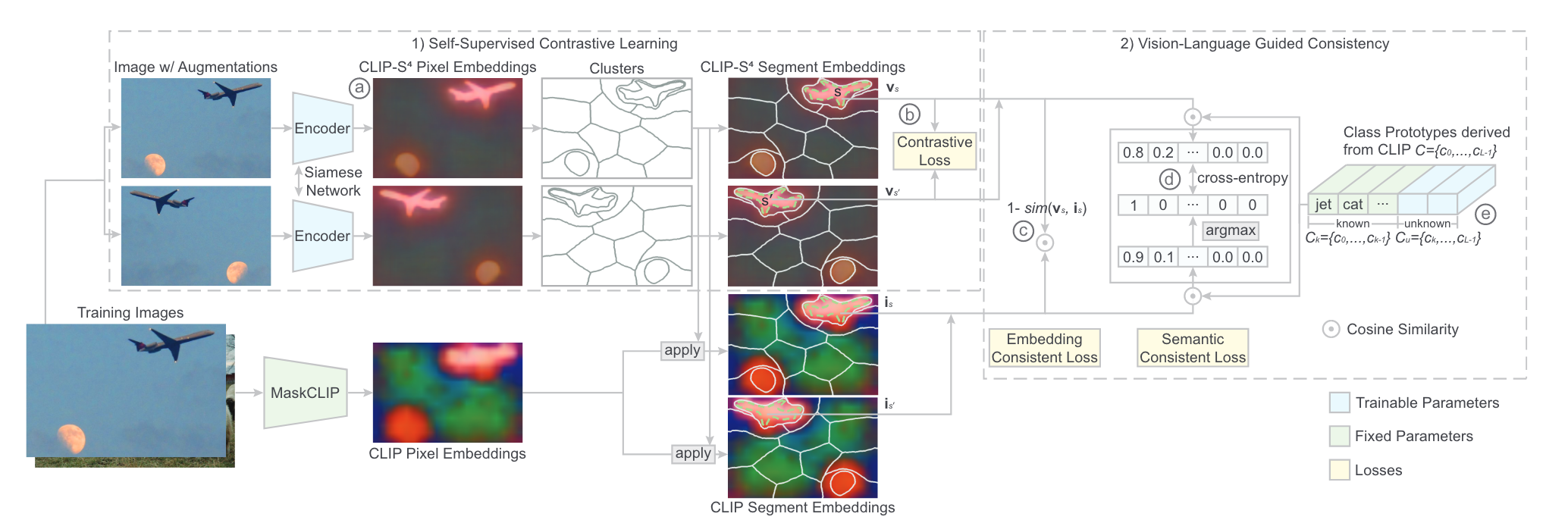
文章的主要方法实际上就是借助自监督对比学习以及CLIP的指导来训练一个输出为pixel embedding的函数。
Pixel-Segment Contrastive Learning
embedding function将每个像素\(p\)投影为d维空间的一个向量\(z_p\),之后对向量进行聚类得到\(|S|\)个区域,区域的embedding \(v_s\)表示为该区域所有向量的平均,同时进行归一化处理。对于每个像素\(p\),所有的segment分为两个集合\(S^+\)以及\(S^-\),其中\(S^+\)包含所有和\(p\)在同一视觉连贯区域内的segment,这里的视觉连贯区域可以由超像素等方法得到。作者这里还使用了数据增强,使模型根据不同的增强图像生成一致的pixel embedding。因此,不同增强图像中和像素在同一个区域的segment也都属于\(S^+\),其它所有segment属于\(S^-\)。对比损失如下:
\[\mathcal{L}_t(p)=-log\frac{\sum_{S\in\mathcal{S^+}}exp(sim(z_p,v_s)κ)}{\sum_{S\in\mathcal{S^+}∪\mathcal{S^-}}exp(sim(z_p,v_s)κ)} \]Vision-Language Model Guided Consistency
为了得到语言驱动的分割模型,同时改善pixel embedding的质量,作者使用CLIP指导embedding function的训练,使其output space与CLIP的embedding space尽可能接近,考虑的一致性分为如下两种:
Embedding Consistency
作者首先通过MaskCLIP的方式对CLIP的image encoder进行修改得到clip-i(·),直接使用CLIP的text encoder作为clip-t(·),之后获取不同增强图像的pixel embedding(具体实现是先获取pixel embedding,然后对pixel embedding施加增强效果),最后最小化CLIP embedding space与segment embedding space的距离,目的是缓解CLIP的pixel embedding的噪声带来的影响。最终,通过最大化每个segment对应的segment embedding(\(v_s\))与CLIP embedding(\(i_s=\sum_{p\in s}clip-i(s)/|s|\))从而使两个空间相一致。
Semantic Consistency
semantic consistency的作用是让模型给出与CLIP相同的语义类别预测结果(根据语义类别进行聚类可以生成更好的pixel embedding),整体思想与伪标签类似,对于每个segment使用CLIP生成目标类别的伪标签(包括已知类和未知类),伪标签通过比较segment embedding与类别在CLIP embedding space的原型的相似度得到,即\(y_s=argmax_{l\in L}(sim(i_s,c_l))\),损失使用CE计算:\(\mathcal{L}_s(s)=H(y_s,\psi(v_s))\),其中\(\psi(v_s)=softmax(sim(v_s,C))\)
Target Class Prototypes
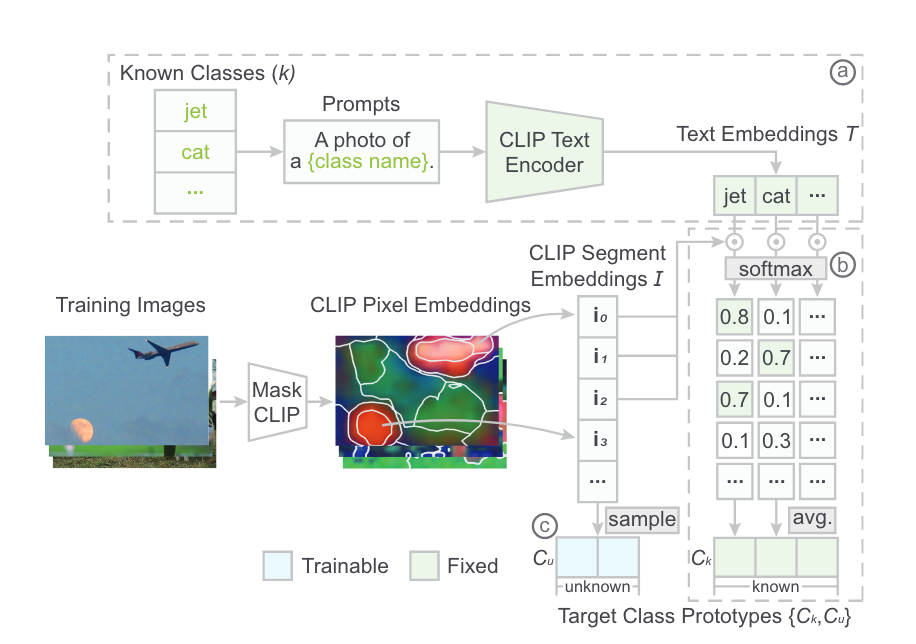
类别原型是类别在embedding space的表示,由已知类\(C_k=\{c_0,...c_{k-1}\}\)和未知类\(C_u=\{c_{k},...c_{k+u-1}\}\)(论文原文这里的表示有点问题)。
对于已知类,一个自然的想法是使用text embedding,然而CLIP的text embedding和对应的image/pixel embedding在整个embedding space中仍然有很大的差距。因此,作者使用CLIP pixel embedding的原型来表示每个已知类,首先得到一系列的text embedding,之后通过修改后的encoder得到CLIP pixel embedding,将pixel embedding聚类为segment再取平均,得到每个segment的embedding \(i_{\hat{s}}\),之后对于每个类别,计算该类的text embedding与所有segment embedding的相似度,取相似度最大的m个作为该类的原型。
对于未知类,作者通过采样所有segment embedding来随机初始化未知类的原型。在训练期间,通过最小化分配到该类的segment与原型的距离来对原型进行更新。
训练与推理
训练期间通过三个损失来更新模型的参数。推理时使用训练好的模型生成pixel embedding,用于各种下游任务。
实验
实验主要进行了三部分:Language-Driven Semantic Segmentation、Unsupervised Semantic Segmentation以及Instance Mask Tracking。
以Language-Driven Semantic Segmentation为例:
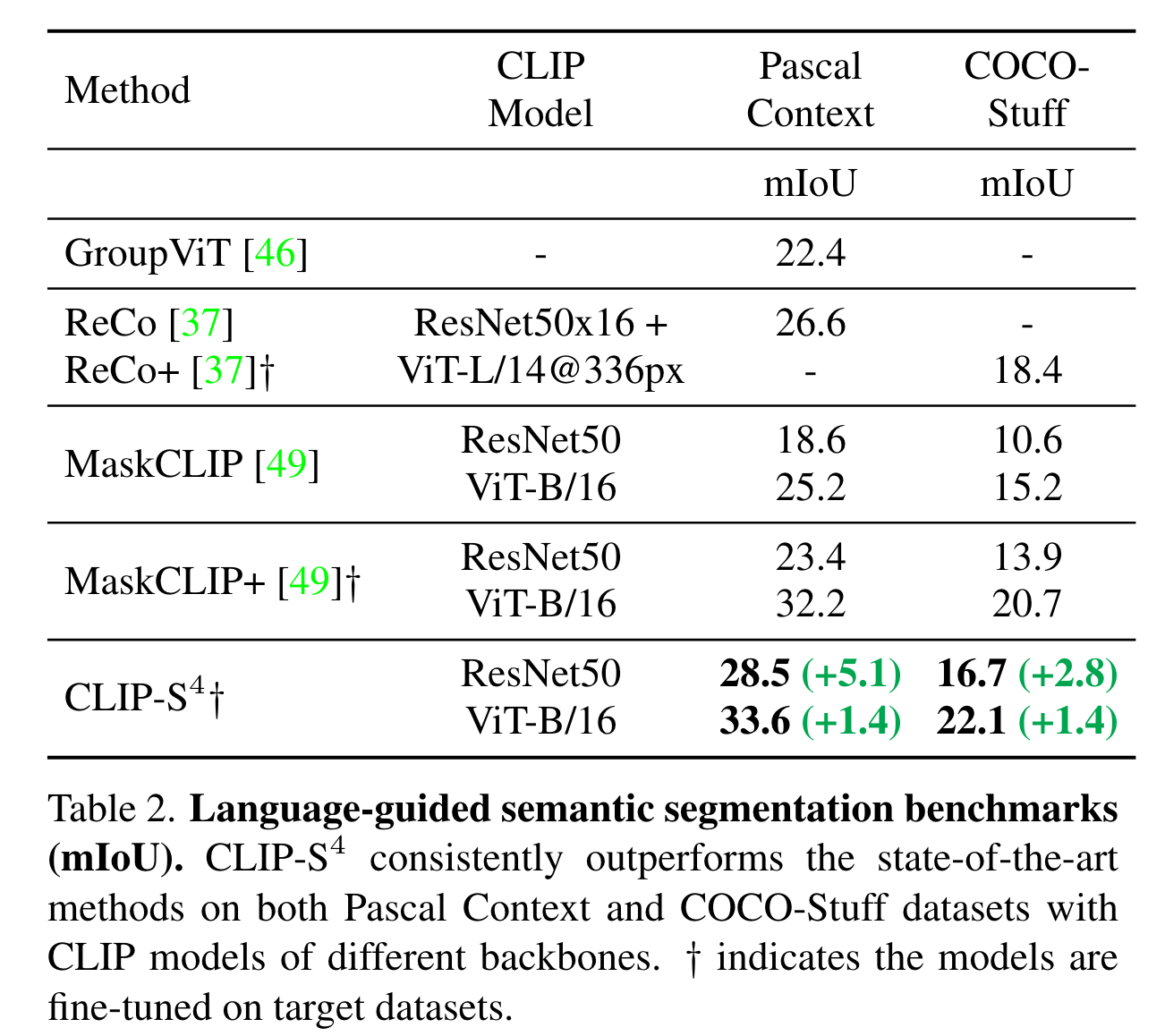
需要注意的是这里对比的GroupViT等方法的训练策略与文章方法有所不同,作者直接选取了这些方法最好的结果进行对比。同时,作者将Pascal Context的数据按照类别划分为四个fold来模拟unknown class的情景:

embedding的分布:

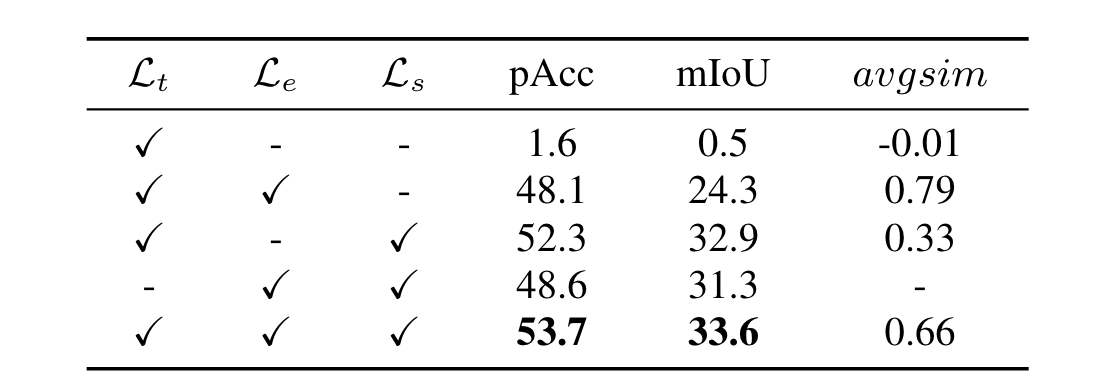
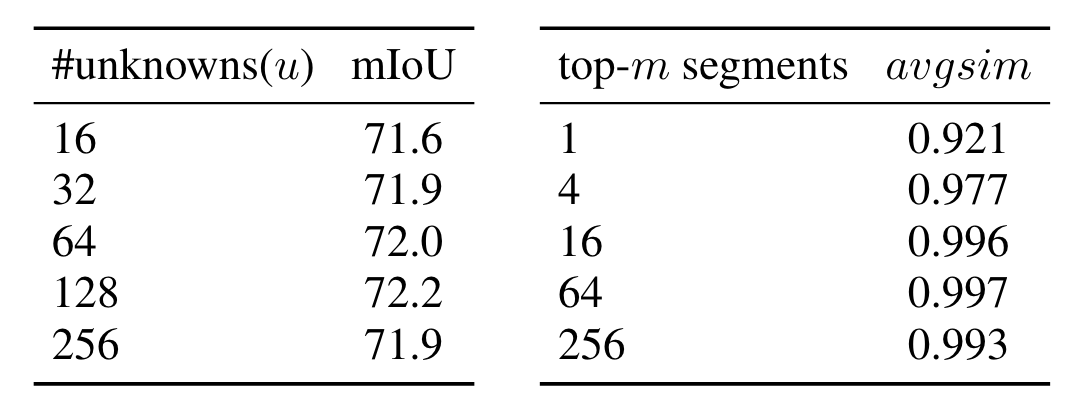
消融实验: