@
目录环境准备
基于已经搭建好的hadoop3.3.0集群
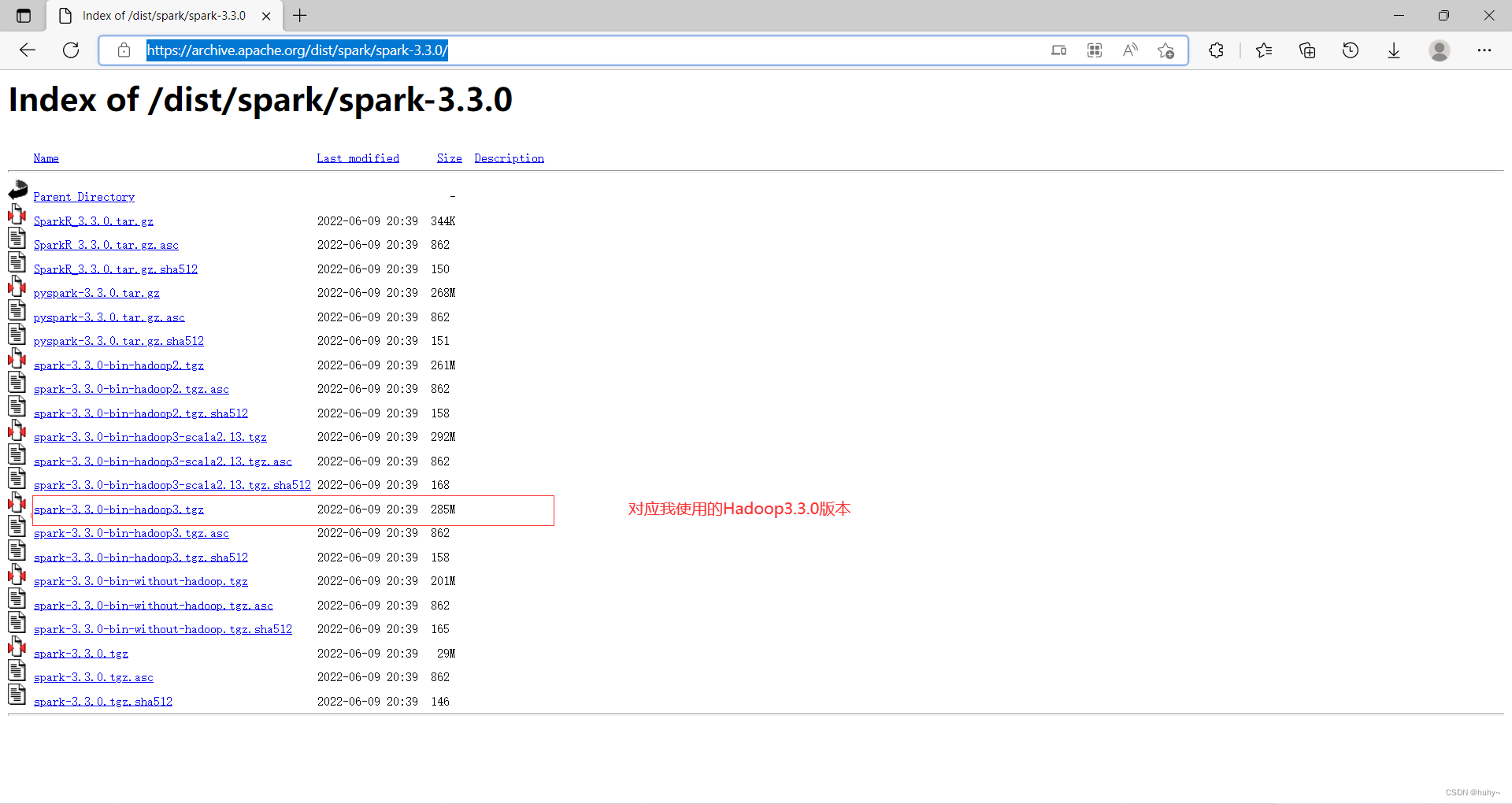
使用spark3.3.0,注意hadoop要和spark版本要对应(去官网查看)
官网地址:https://archive.apache.org/dist/spark/spark-3.3.0/
配置spark
确保HADOOP_CONF_DIRorYARN_CONF_DIR指向包含 Hadoop 集群的(客户端)配置文件的目录。这些配置用于写入 HDFS 并连接到 YARN ResourceManager。此目录中包含的配置将分发到 YARN 集群,以便应用程序使用的所有容器使用相同的配置。如果配置引用了不受 YARN 管理的 Java 系统属性或环境变量,它们也应该在 Spark 应用程序的配置(驱动程序、执行程序和以客户端模式运行时的 AM)中进行设置。
有两种部署模式可用于在 YARN 上启动 Spark 应用程序。在clustermode 下,Spark 驱动程序运行在集群上由 YARN 管理的应用程序主进程中,客户端可以在启动应用程序后离开。在clientmode 下,驱动程序运行在客户端进程中,应用程序主控仅用于向 YARN 请求资源。
与 Spark 支持的其他集群管理器不同,在参数中指定了 master 的地址--master ,在 YARN 模式下,ResourceManager 的地址是从 Hadoop 配置中获取的。因此,--master参数为yarn。
root@master:/usr/local# ll
total 52
drwxr-xr-x 13 root root 4096 Sep 18 04:28 ./
drwxr-xr-x 14 root root 4096 Apr 21 00:57 ../
drwxr-xr-x 2 root root 4096 Apr 21 00:57 bin/
drwxr-xr-x 2 root root 4096 Apr 21 00:57 etc/
drwxr-xr-x 2 root root 4096 Apr 21 00:57 games/
drwxrwxrwx 12 root root 4096 Sep 18 04:56 hadoop-3.3.0/
drwxr-xr-x 2 root root 4096 Apr 21 00:57 include/
drwxr-xr-x 7 10143 10143 4096 Dec 11 2019 jdk1.8.0/
drwxr-xr-x 3 root root 4096 Apr 21 01:00 lib/
lrwxrwxrwx 1 root root 9 Apr 21 00:57 man -> share/man/
drwxr-xr-x 2 root root 4096 Apr 21 01:00 sbin/
drwxr-xr-x 4 root root 4096 Apr 21 01:01 share/
drwxr-xr-x 13 huhy huhy 4096 Jun 9 20:37 spark-3.3.0-bin-hadoop3/
drwxr-xr-x 2 root root 4096 Apr 21 00:57 src/
root@master:/usr/local#
环境变量配置
root@master:/usr/local/spark-3.3.0-bin-hadoop3# cat /etc/profile.d/my_env.sh
#JAVA_HOME
export JAVA_HOME=/usr/local/jdk1.8.0
export PATH=$PATH:$JAVA_HOME/bin
#HADOOP_HOME
export HADOOP_HOME=/usr/local/hadoop-3.3.0
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
#解决后面启动集群的权限问题
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
export HADOOP_CONF_DIR=/usr/local/hadoop-3.3.0/etc/hadoop
export YARN_CONF_DIR=/usr/local/hadoop-3.3.0/etc/hadoop
配置spark-env.sh
root@master:/usr/local/spark-3.3.0-bin-hadoop3/conf# ls
fairscheduler.xml.template metrics.properties.template spark-env.sh.template
log4j2.properties.template spark-defaults.conf.template workers.template
root@master:/usr/local/spark-3.3.0-bin-hadoop3/conf# mv spark-env.sh.template spark-env.sh
root@master:/usr/local/spark-3.3.0-bin-hadoop3/conf# vim spark-env.sh
#配置在首行即可,配置完这个spark就能知道rm,nm,以及hdfs等节点的地址
export JAVA_HOME=/usr/local/jdk1.8.0
export HADOOP_CONF_DIR=/usr/local/hadoop-3.3.0/etc/hadoop/
export YARN_CONF_DIR=/usr/local/hadoop-3.3.0/etc/hadoop/
#配置历史服务器,切记端口是内部端口
export SPARK_HISTORY_OPTS="
-Dspark.history.ui.port=18080
-Dspark.history.fs.logDirectory=hdfs://master:8020/spark-logs
-Dspark.history.retainedApplications=30"
参数 1 含义:WEB UI 访问的端口号为 18080
参数 2 含义:指定历史服务器日志存储路径
参数 3 含义:指定保存 Application 历史记录的个数,如果超过这个值,旧的应用程序信息将被删除,这个是内存中的应用数,而不是页面上显示的应用数。
配置spark-defaults.conf
root@master:/usr/local/spark-3.3.0-bin-hadoop3/conf# mv spark-defaults.conf.template spark-defaults.conf
root@master:/usr/local/spark-3.3.0-bin-hadoop3/conf# vim spark-defaults.conf
# 开启spark的日期记录功能
spark.eventLog.enabled true
#创建spark日志路径,待会儿要创建
spark.eventLog.dir hdfs://master:8020/spark-logs
spark.yarn.historyServer.address=master:18080
spark.history.ui.port=18080
分发集群
把master上配置好的spark文件和环境变量传输到其他节点
root@master:~# scp -r /usr/local/spark-3.3.0-bin-hadoop3/conf slave1:/usr/local/spark-3.3.0-bin-hadoop3
root@master:~# scp -r /usr/local/spark-3.3.0-bin-hadoop3/conf slave2:/usr/local/spark-3.3.0-bin-hadoop3
在此之前是启动了hadoop集群的
先创建spark-logs目录
root@master:~# hadoop fs -mkdir /spark-logs
root@master:~# hadoop fs -chmod 777 /spark-logs
启动历史服务器
master上启动历史服务器进程
root@master:/usr/local/spark-3.3.0-bin-hadoop3# sbin/start-history-server.sh
starting org.apache.spark.deploy.history.HistoryServer, logging to /usr/local/spark-3.3.0-bin-hadoop3/logs/spark-root-org.apache.spark.deploy.history.HistoryServer-1-master.out
root@master:/usr/local/spark-3.3.0-bin-hadoop3# jps
1504 NameNode
1652 DataNode
2473 HistoryServer
2153 JobHistoryServer
1995 NodeManager
2669 Jps
root@master:/usr/local/spark-3.3.0-bin-hadoop3#
运行实例和shell
Spark 附带了几个示例程序。Scala、Java、Python 和 R 示例都在 examples/src/main目录中。要运行 Java 或 Scala 示例程序之一, bin/run-example
注:pyspark和spark-shell无法在交互式环境运行cluster模式
在cluster模式下启动 Spark 应用程序:
#zaispark目录下
bin/pyspark --master yarn --deploy-mode cluster/client
#表示指定为yarn模式后面具体使用哪种模式
bin/spark-shell --master yarn --deploy-mode cluster/client
#表示指定为yarn模式,后面具体使用那种模式
root@master:/usr/local/spark-3.3.0-bin-hadoop3# ls
bin data jars LICENSE NOTICE R RELEASE yarn
conf examples kubernetes licenses python README.md sbin
root@master:/usr/local/spark-3.3.0-bin-hadoop3# bin/pyspark --master yarn
Python 3.10.4 (main, Jun 29 2022, 12:14:53) [GCC 11.2.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
22/09/23 09:05:43 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
22/09/23 09:05:46 WARN Client: Neither spark.yarn.jars nor spark.yarn.archive is set, falling back to uploading libraries under SPARK_HOME.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 3.3.0
/_/
Using Python version 3.10.4 (main, Jun 29 2022 12:14:53)
Spark context Web UI available at http://master:4040
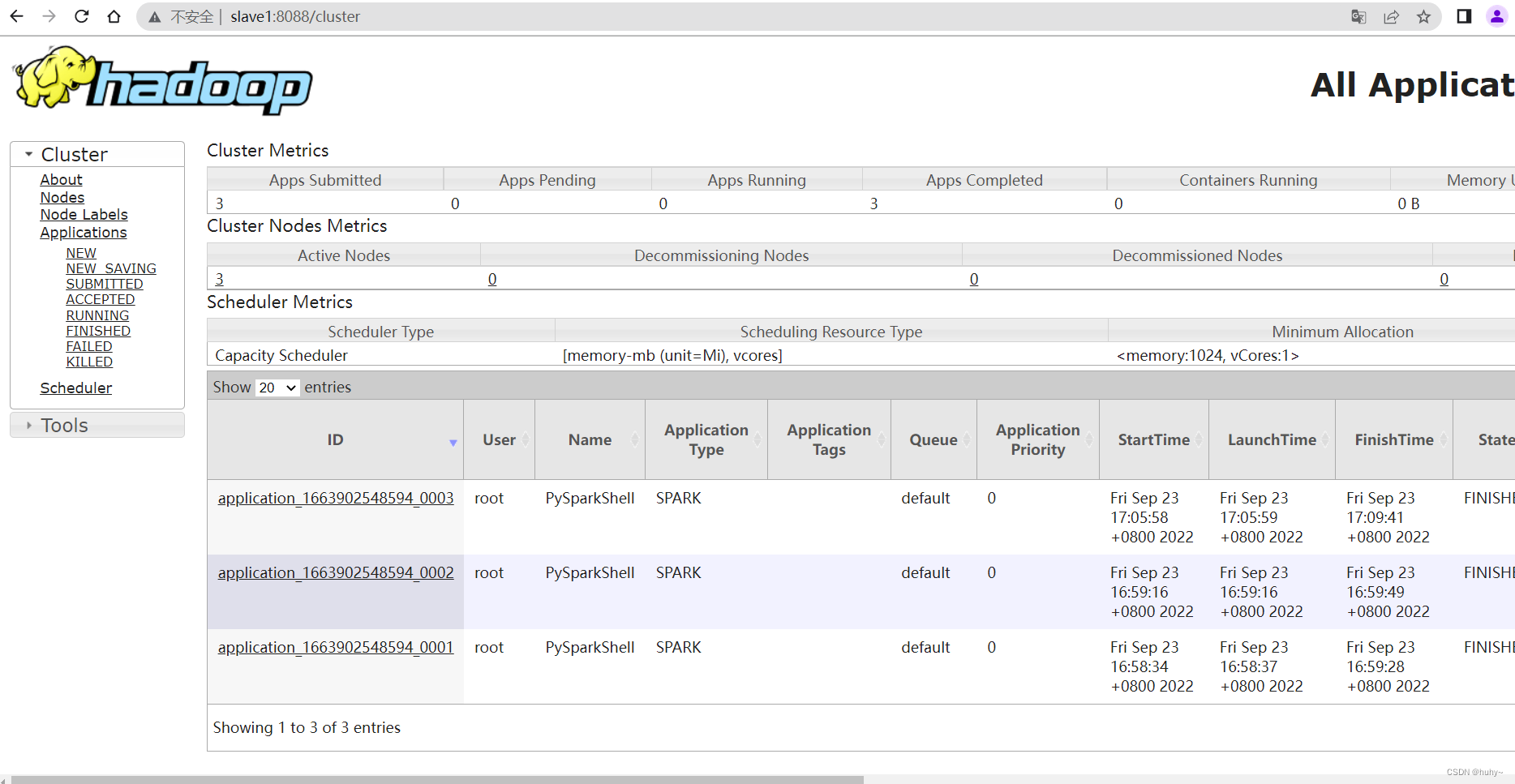
Spark context available as 'sc' (master = yarn, app id = application_1663902548594_0003).
SparkSession available as 'spark'.
>>>
访问地址查看https:192.168.200.101:8080
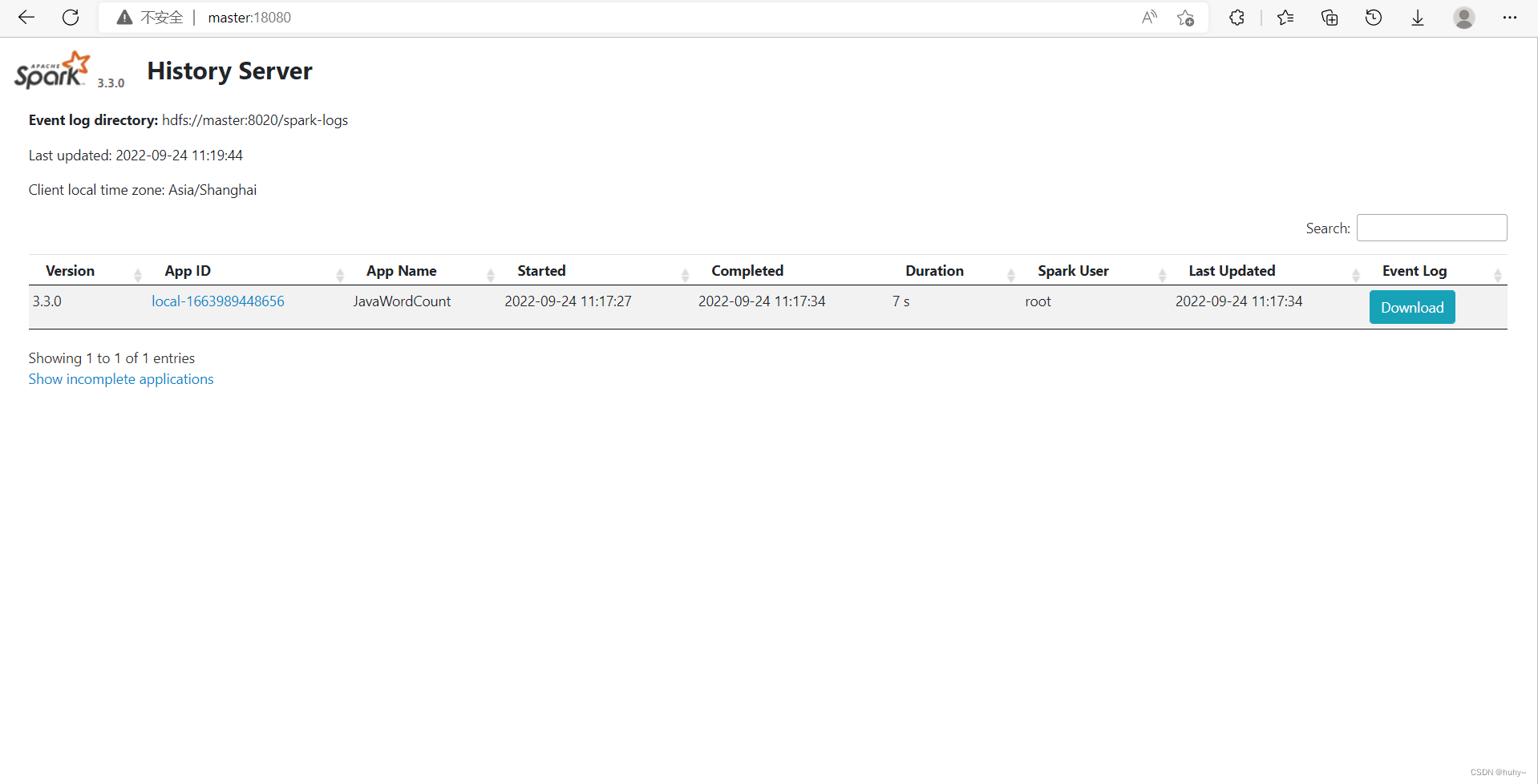
在提交一个job查看历史服务器
root@master:/usr/local/spark-3.3.0-bin-hadoop3# bin/spark-submit --class org.apache.spark.examples.JavaWordCount examples/jars/spark-examples_2.12-3.3.0.jar /usr/root/NOTICE.txt