【CVPR2022】AdaViT: Adaptive Vision Transformers for Efficient Image
链接:Recognitionhttps://openaccess.thecvf.com/content/CVPR2022/papers/Meng_AdaViT_Adaptive_Vision_Transformers_for_Efficient_Image_Recognition_CVPR_2022_paper.pdf

这篇论文核心思想是实现动态的 VIT,只选择 informative 的特征进行计算,目标是:improve the inference efficiency of VIT with a minimal drop of accuracy for image recognition.

上图能够很好的说明作者的思路,对于鸟的图片,只有部分 patch 是 informative 的,因此6个 head里面只选择2个参与计算即可,另外 4个直接断开;下面图片中, informative 的 patch 数量比较多,因此需要多投入 head 进行计算。
类似的论文从去年起有很多,比如【ICLR2022】Expediting vision transformers via token reorganization,【AAAI2022】EVO-vit,【NeurIPS2021】DynamicVIT,【ARXIV2106】IA-RED2,【NeurIPS2021】Dynamic Grained Encoder for VIT 等等,都是在丢弃一些 token 来加速VIT的计算。
之前是论文大多是在 token 级别选择丢弃,这论文的特点是从三个层次来丢弃特征加速计算:patch, head, 和 block。
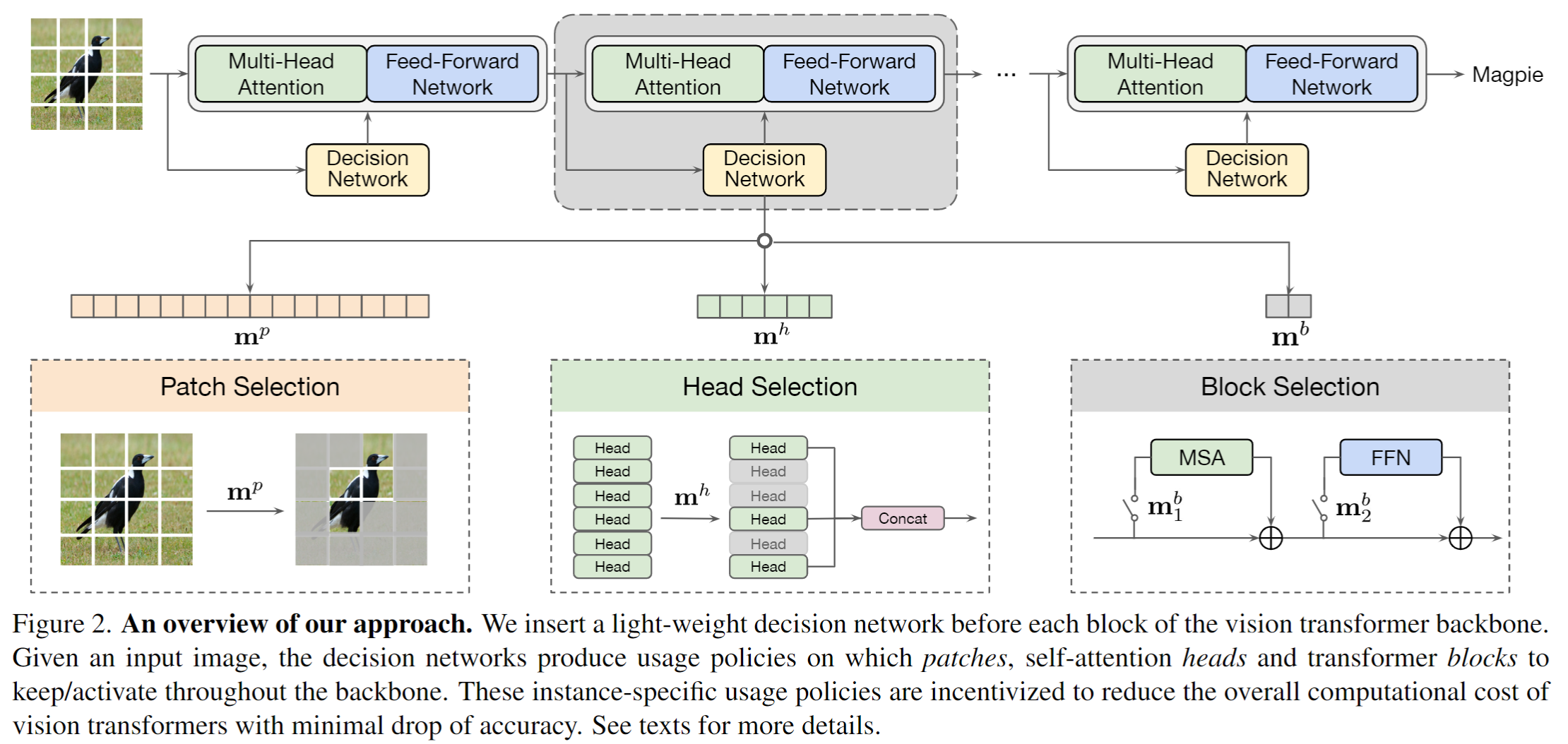
作者在每个transformer block之前加入一个轻量的决策网络,负责预测当前block中的patch、 self-attention head和block的是否使用。
因这里使有和了 hard gate,自然会面临训练时无法反向传播的问题。这里和大多数方法思路一致,使用神器 gumbel softmax 来解决。
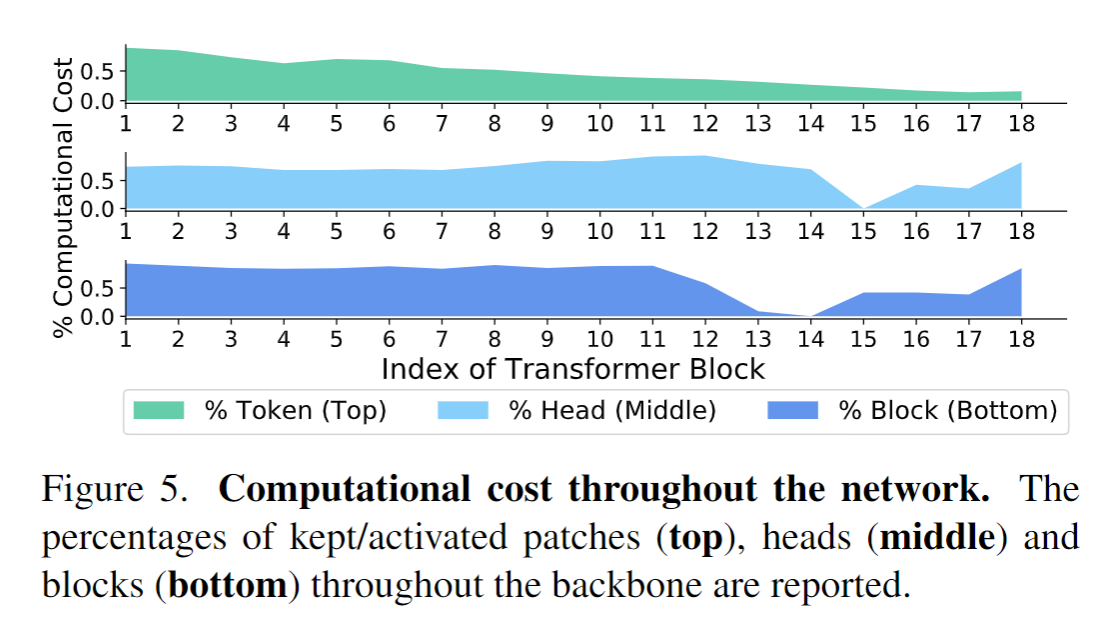
实验里有一个有趣的地方是下面这个图,可以看出一开始会有很多的 token 参与计算,但是到网络后期就非常少了。作者的解释是:The patches keep aggregating information from all other patches in the stacked self-attention layers, and a few informative patches near the output layer would suffice to represent the whole input image for correct classification. 不太一样的是 heads 和 blocks 慢慢减少,但是到某一个阶段,需求量又突然上升了。作者的解释是:the last few layers in the backbone are more responsible for the final prediction and thus are kept more often.