【ARXIV2207】HorNet: Efficient High-Order Spatial Interactions with Recursive Gated Convolutions
这篇论文来自清华大学和 Meta AI,想法非常有趣。作者认为当前的 Transformer 取得成功主要是因为 dot-product self-attention 可以实现高阶特征交互(high-order spatial interactions),如下图左侧所示。因此,作者提出了 Recursive gated convolution (gnConv),通过 门控 和 循环 实现了基于卷积的高阶空间交互建模,其结构如下图右侧所示。(论文中 n 为上标,为了写博客方便,博文中用 gnConv 表示)
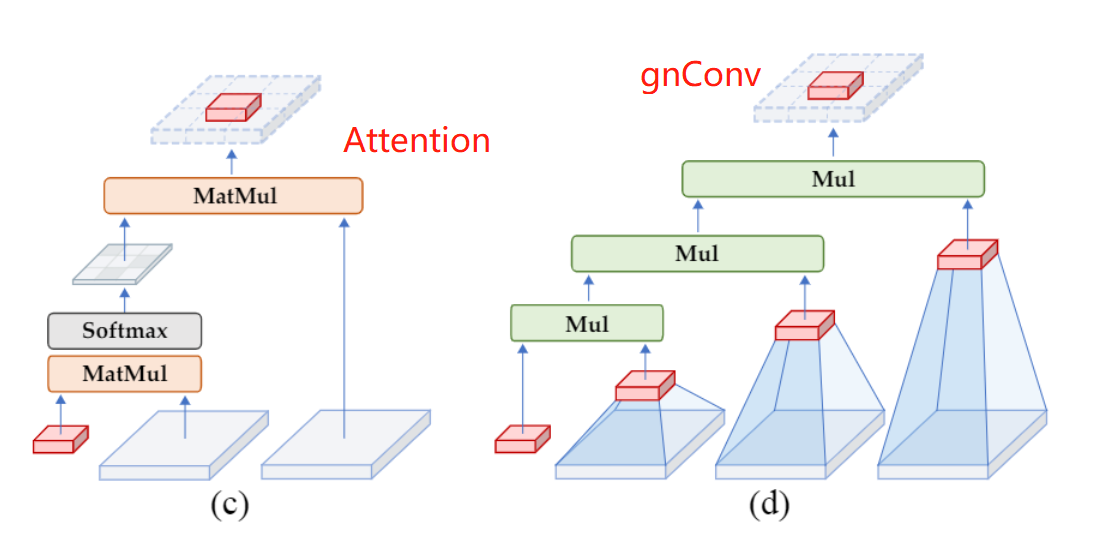
1、gnConv
作者提出的gnConv包括两个核心概念:(1)门控卷积;(2)把多个门控卷积递归循环起来(recursive)。同时,为了获取大的感受野,卷积上使用了大卷积核。下面分别介绍这三个部分。
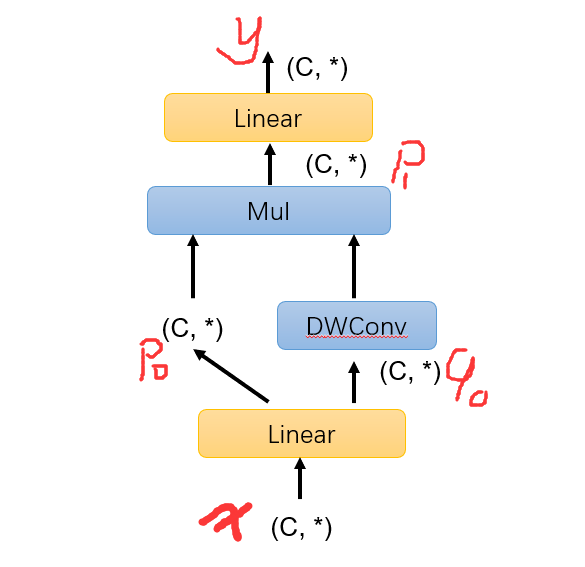
(1)门控卷积(gated convolution)。输入特征 x 使用 Linear 层变成 \(p_0\) 和 \(q_0\) ,然后 \(q_0\) 使用 depth-wise conv 处理,然后再和 \(p_0\) 做点积,得到 \(p_1\)。最后, \(p_1\) 经过 linear 层处理得到输出 \(y\) 。这个过程提取的是特征一阶交互。(这个步骤作者没有在论文中配图,我自己画了一个,大家忍忍)
(2)循环门控实现高阶交互。 循环的进行门控卷积,可以实现更高阶的特征交互。这里直接晒论文里的图和伪代码,非常容易理解。作者只进行了一次卷积,降低了计算量。从图中可以看出,各阶交互特征通道数依次是 C/4, C/2, C,这样就实现了精 粗到精的特征提取,低阶使用较少的通道。作者还有一个计算量的分析,表明gnConv可以在相近计算量的情况下实现高阶空间交互建模,感兴趣可以看论文。

(3)DWConv 中使用大卷积核。 VIT中因为具有较大的感受野,容易捕捉长距离依赖关系。受此启发,作者对于 DWConv 进行了如下改进:(1)使用 7x7 的卷积核;(2)对于一半的 channel 使用 global filter,另一半使用 3X3 的 DWConv,并且只在后面的 stage 使用。global filter 是 NeurIPS 2021 论文 Global Filter Networks for Image Classification 里提出的方法,之前还没有看过,这两天会抽空看一下。
2、HorNet 整体架构及实验结果
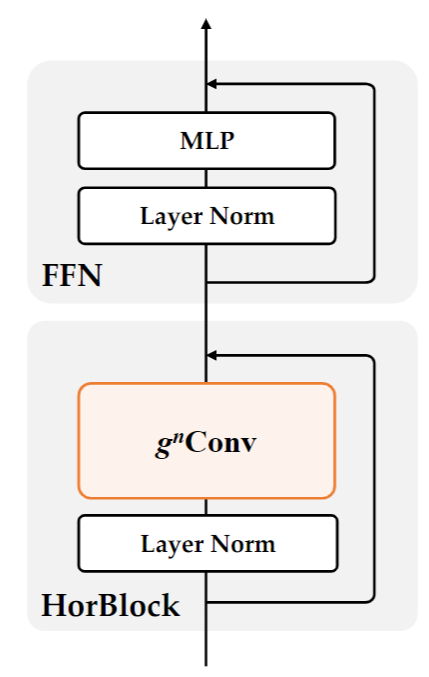
作者使用了典型 Transformer 网络的四阶段架构,如下图所示,把 attention 替换为 gnConv。作者直接沿用了 SWIN 各个阶段 block 的数量,并额外在 stage2 加了一个 block 使整体复杂度接近。各个stage的block数是[2, 3, 18, 2]。每个 stage中,gnConv空间阶数分别为[2,3,4,5]。四个 stage 的通道数依次为[C, 2C, 4C, 8C]。
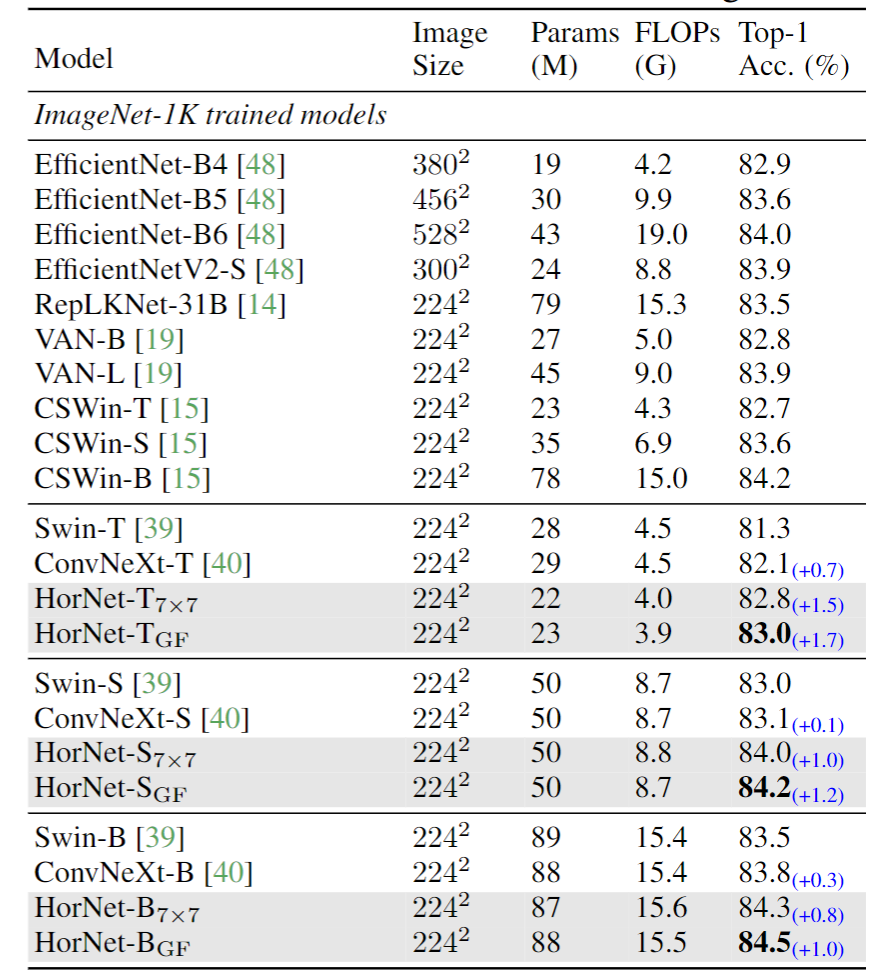
在ImageNet 上的分类结果如下表所示,HorNet大幅超过了Swin Transformer和ConvNeXt。虽然一些近期的新模型比HorNet精度高,但作者相信,在这些新模型中使用gnConv同样能够对其带来提升。
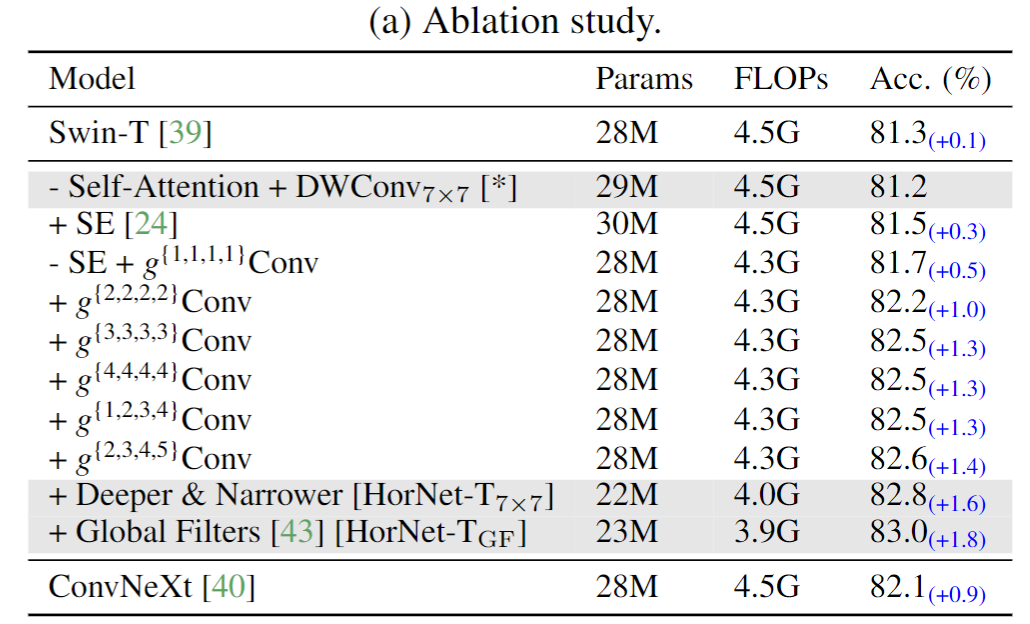
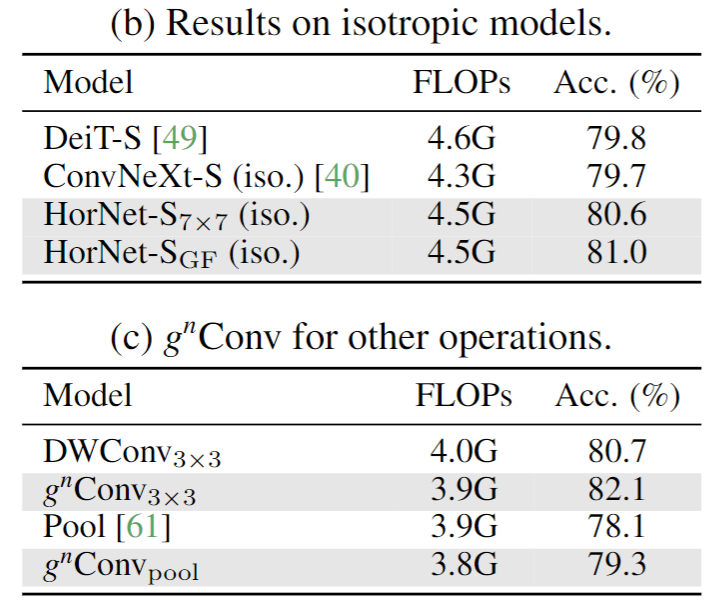
消融实验如下表(a)所示,作者验证了gnConv可以提高模型精度。精度会随着空间阶数的增大而升高。下表(b)显示了gnConv在同质架构的模型中的实验结果,表明gnConv相比普通卷积能够更有效地替代self-attention,并且对于复杂空间交互的建模能力更好。下表(c)显示了将gnConv应用于3x3的depth-wise convolution和3x3的pooling的实验结果,表明用gnConv可以提高这两种操作的有效性,从而验证了gnConv的通用性。
作者还做了在语义分割、目标检测上的实验,可以参考作者论文,这里不再多说。
标签:ARXIV2207,Recursive,Interactions,卷积,作者,交互,门控,HorNet,gnConv From: https://www.cnblogs.com/gaopursuit/p/16659273.html