摘要:最近看到K8s启动stable-diffusion的文章,想着在自己开发环境复现一下。没想到在内网环境还遇到这么多问题,记录一下。
本文分享自华为云社区《内网Docker启动Stable-Diffusion(AI作画)》,作者:tsjsdbd 。
最近看到K8s启动stable-diffusion的文章,想着在自己开发环境复现一下。没想到在内网环境还遇到这么多问题,记录一下。
1. 背景介绍
“AI作画”就是你给一段文字,AI自动生成图像;或者你给一张图像,AI自动生成另一种风格(比如自拍照=>漫画风)。这个方向的AI框架以开源的stable-diffusion为代表,著名的Midjourney则是商业版的“AI作画”。
2. 环境准备
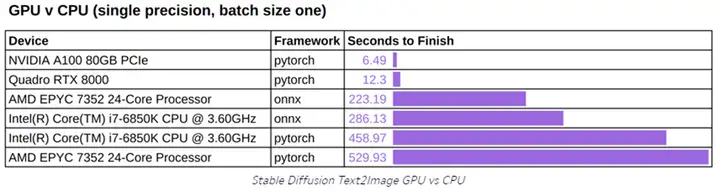
由于“AI作画”一般是GPU为主,虽然CPU也可以,但是速度相较GPU会慢很多(见下图)。所以这里我们准备一个带GPU的Docker环境。
3. 下载镜像
根据文章里面提到的gpu版镜像地址(注:它这个镜像其实来自于开源社区:stable-diffusion-webui),直接:
docker pull zibai-registry.cn-hangzhou.cr.aliyuncs.com/gpt/stable-diffusion:v1.gpu
这里要连外网+非官方仓库,所以有2个配置需要为docker设置
- 为docker设置代理。
vi /etc/systemd/system/docker.service.d/http-proxy.conf [Service] Environment="HTTPS_PROXY=http://ip:3128"
类似这样,然后重启docker
- 将目标仓库地址设置为docker的信任仓库。
vi /etc/docker/daemon.json "insecure-registries": ["zibai-registry.cn-hangzhou.cr.aliyuncs.com"],
类似这样。
4. 启动Docker容器
由于需要打开Web页面,所以我们的docker需要设置端口映射,否则无法通过浏览器访问。
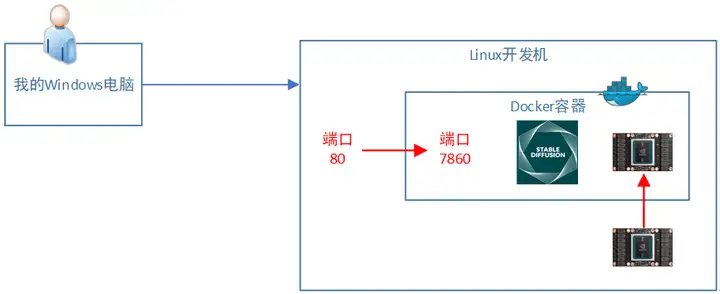
所以docker启动会带2个额外的参数:(1)挂载GPU卡。(2)设置端口映射
docker run -it -p 80:7860 --gpus "device=1" zibai-registry.cn-hangzhou.cr.aliyuncs.com/gpt/stable-diffusion:v1.gpu /bin/bash
5. 启动Stable-diffusion程序
在Docker容器中,按照启动命令执行:
python3 launch.py --listen
但是会报错:

这是因为这个镜像会联网下载“模型”。而我的容器无法联网。所以这里在容器里面设置代理:
export proxy=http://10.155.96.xx:3128
export http_proxy=$proxy
export https_proxy=${http_proxy}
类似这样。但是还是下载失败,报“证书不合法”

关于这个 “huggingface.co”证书不合法的问题。找了一圈解决方案,都无效。
比如,导出证书,
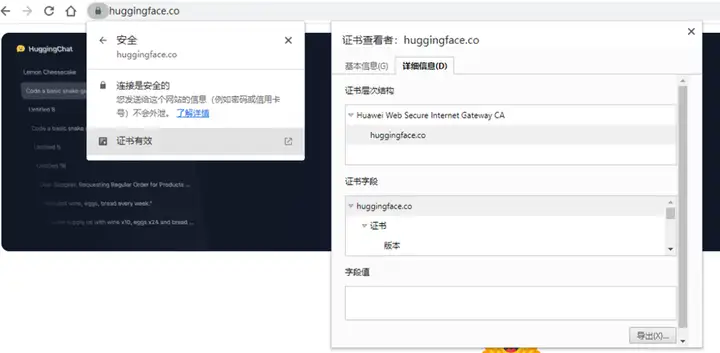
然后拷贝到容器中,更新证书列表(2个证书都拷贝了,1个huggingface.co, 1个Huawei Web Secure):
update-ca-certificates
依然报证书不合法。
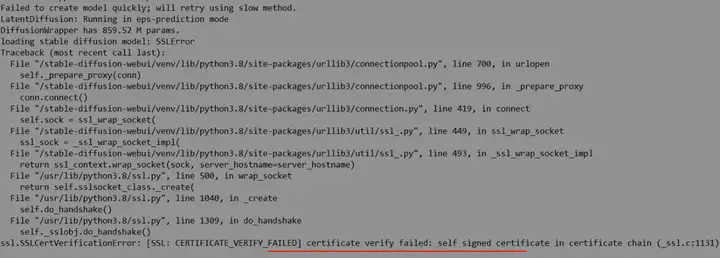
即使,我直接访问 huggingface.co 是OK的
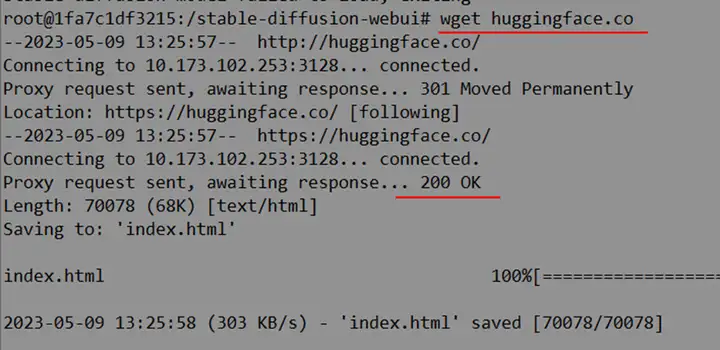
也搜了类似的问题:https://github.com/huggingface/hub-docs/issues/54,但是仍然不行。
Ps:这里证书问题不知道怎么解,有思路的同学,给点建议。
6. 修改代码,忽略证书校验
实在没办法,搜到的资料说可以在Python请求HTTP的函数里面关闭“证书校验”。
于是找到错误调用栈
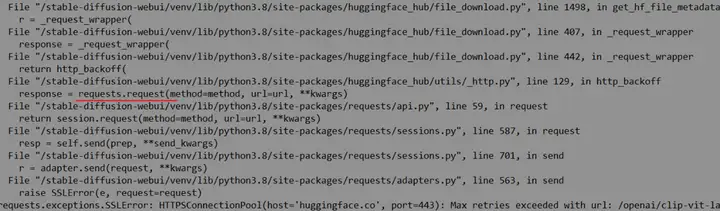
这个request发送的函数,有个“忽略证书校验”的参数。
cat /stable-diffusion-webui/venv/lib/python3.8/site-packages/huggingface_hub/utils/_http.py
(ps:容器里面没有vi命令,所以我是在主机上改的。因为任意容器里面的文件,都可以在主机Host上看到)
于是我将其改为:
response = requests.request(method=method, url=url, **kwargs)
=》
response = requests.request(method=method, url=url, verify=False, **kwargs)
然后终于,可以顺利下载“模型”了
模型下载完后,依然报了个错:
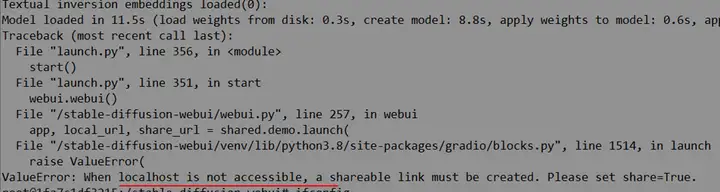
什么? localhost 不能访问,怎么可能~ 搜到一个类似的问题:https://github.com/microsoft/TaskMatrix/issues/250
说是代理原因,导致访问本地失败。
于是加上:
export no_proxy="localhost, 127.0.0.1, ::1"
报错,看来 ipv6 这个格式不认识。

最终改为:
export no_proxy="localhost, 127.0.0.1"
一切OK。
7. 打开Stable-diffusion的WEB界面
浏览器输入开发机的地址,即可打开Web界面(因为我们设置了 80 端口映射)。
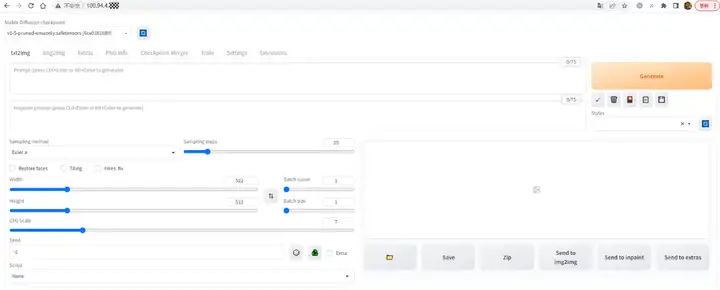
试了下效果,一般般,可能是我魔法咒语(Prompt)念的不太行。
(ps:有个“咒语”参考网站:https://civitai.com 从这里面下载的模型,生成效果不错)。
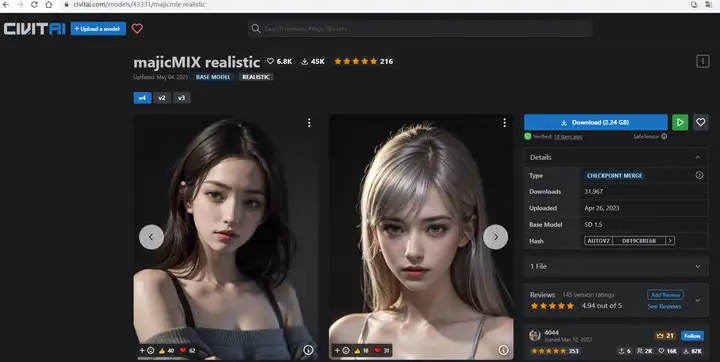
下载后,拷贝至对应目录:
docker cp ./majicmixRealistic_v4.safetensors 容器id:/stable-diffusion-webui/models/Stable-diffusion/
然后Web界面选择新下载的模型就行:
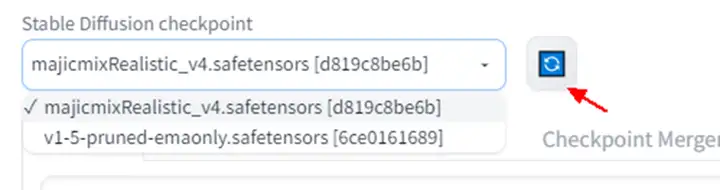
仅供参考~
参考:
《基于容器平台 ACK 快速搭建 Stable Diffusion》
其中Docker镜像对应dockerfile(万一镜像无法下载):
FROM nvidia/cuda:11.3.0-cudnn8-runtime-ubuntu20.04
ENV DEBIAN_FRONTEND noninteractive
RUN apt-get update && apt-get install -y --no-install-recommends \
libgl1 libglib2.0-0 git wget python3 python3-venv && \
apt-get clean && \
rm -rf /var/lib/apt/lists/*
ADD . /stable-diffusion-webui
WORKDIR /stable-diffusion-webui/
RUN ./webui.sh -f can_run_as_root --exit --skip-torch-cuda-test
ENV VIRTUAL_ENV=/stable-diffusion-webui/venv
ENV PATH="$VIRTUAL_ENV/bin:$PATH"
VOLUME /stable-diffusion-webui/models
VOLUME /root/.cache
CMD ["python3", "launch.py", "--listen"]
标签:Diffusion,diffusion,证书,Stable,proxy,stable,docker,内网,webui From: https://www.cnblogs.com/huaweiyun/p/17407885.html