大家好,这里是专注表观组学十余年,领跑多组学科研服务的易基因。
生物过程具有复杂性和整体性,单组学数据难以系统全面解析复杂生理过程的分子调控机制。而多组学(Multi-omics)联合分析可同时实现从“因”和“果”两个层面研究生物学问题,并对其相关性进行验证。高通量技术的发展,通过对多组学数据整合分析,已成为科学家探索生命机制的新方向。
多组学研究是探究生物系统中多种物质之间互作的方法,包括基因组学、表观基因组学、转录组学、蛋白质组学、代谢组学、微生物组学等,这些物质共同影响生命系统的表型、性状等。
什么是多组学关联分析?
关联分析是一种实用的分析技术,就是发现存在于大量数据集中的关联性或相关性,从而描述一个事物中某些属性同时变化的规律和模式。
需要特别注意的是:相关 ≠ 因果;相关 ≠ 必然
因果关系的论证一般需要严密的分子实验。

图示:分子的相互作用,产生关联
组学技术及其关联性
不同组学
① 表观组(差异表观分子特征):甲基化、组蛋白修饰、开放染色质区、lncRNA、circleRNA、miRNA... ...
② 转录组(差异基因表达):mRNA
③ 蛋白组(差异蛋白):蛋白质
④ 代谢组(差异代谢物):代谢物
⑤ 微生物组(差异菌群):菌群结构
多组学关联的意义:串联证据,互相验证,从不同的角度合力探索和解释生物学问题
判断组学之间是否可以进行关联:是否有关联的生物学理论基础。
如:
• 启动子区甲基化会抑制基因的表达。
• 基因主体甲基化与基因表达正相关。
• 开放染色质状态与基因表达有关。
• 蛋白质是mRNA翻译的产物。
• miRNA可与mRNA相互作用影响其表达和翻译
关联分析的主要套路
基于参考文献和数据库:项目异质性强,Case by Case 模式
基于代谢通路等已知数据库:高度依赖已知代谢网络解读深度,无法探索未知
基于统计学:数据最朴质的结构特征解析,可以获取未知信息,甚至可以为拓展新的知识体系提供帮助

图示:实际应用中往往三管齐下
易基因主要表观组学技术分类
- DNA甲基化/羟甲基化位点/区域
- RNA甲基化位点/区域
- 转录因子结合区、组蛋白结合区
- DNase超敏位点、开放染色质区

图示:易基因组学技术研究内容
多组学关联分析方法
(1) 直接关联
一个基因的功能元件甲基化情况影响该基因的表达。
• 重叠分析
• Pearson/Spearman 相关性分析
(2)模型关联
基于基因转录、蛋白质、代谢物等之间的上下游相互作用联系。
• 多元线性模型(multiple linear model)
(3)网络关联
基于分子功能和通路的富集性。
• WGCNA module correlation
• EMDN algorithm
• SNF algorithm
多组学关联分析方法图例
(1)直接关联
① 重叠分析
特点:简单粗暴,也适用于样本量少的情况。
分析结果:韦恩图。

图例:WGBS + total RNA-seq,含DMR的差异表达基因、差异miRNA靶向的差异表达基因、差异siRNA靶向的差异表达基因三者之间的重叠关系分析
关联理论基础:DNA甲基化、miRNA和siRNA协同作用调控基因表达。
② 皮尔森/斯皮尔曼相关性分析
特点:准确计算相关性程度(R值),及其显著性(p值)。
分析结果:散点图(+拟合线)、相关性热图
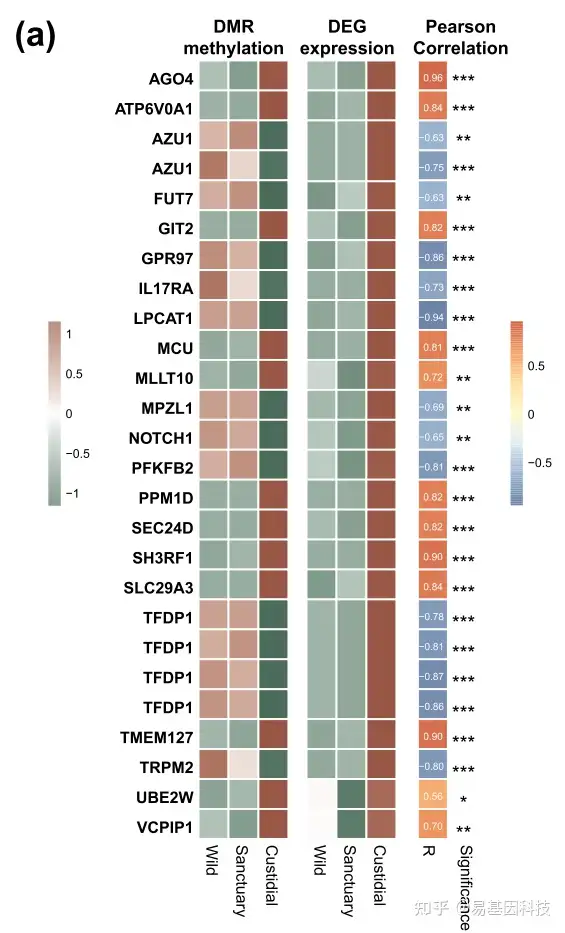
图例:血液组织RRBS+RNA-seq,DMR的甲基化水平与差异表达的表达水平之间的皮尔森关联分析。
关联理论基础:DNA甲基化可直接调控基因表达。

图例:肠道宏基因组+宏病毒组,健康与炎症性肠病(UC)组分别计算噬菌体与细菌丰度之间的皮尔森相关性并发现差异。
关联理论基础:噬菌体可侵染细菌进而影响肠道菌群的结构。

图例:胚胎scRNA-seq+蛋白质组,两连续发育阶段之间的RNA和表蛋白质表达的相关性分析。
关联理论基础:RNA转录和蛋白质翻译具有上下游关系。

图例:肠道宏基因组+代谢组,不同管理状态下川金丝猴肠道中短链脂肪酸与肠道菌群的皮尔森相关性分析。
关联理论基础:肠道中有多类菌群可直接产生短链脂肪酸这类益生物质。
(2)模型关联
回归分析(regression analysis)是确定两组或两组以上变量间关系的统计方法。回归分析按照变量的数量分为一元回归和多元回归。两个变量使用一元回归,两个以上变量使用多元回归。
多元线性回归模型(multiple linear model)

特点:基于基因表达、蛋白质、代谢物等之间的直接和间接相互作用联系。
分析结果:关联网络图

图例:肠道菌群16S+血液代谢组+肝脏转录组,通过多元线性模型关联分析,筛选出若干优秀模型,组建低剂量抗生素饲喂促进仔猪快速生长的多组学调控网络。
关联理论基础:肠道菌群可通过产生代谢物进入血液,运输至肝脏影响肝脏细胞的基因表达。
(3)网络关联
细胞内所有大分子相互作用的集合,称为相互作用组(Interactome),是大多数基因型与表型关系的基础,可以用来指导解释组学技术检测到的变化如何干扰整个机体。
机体的分子响应和变化具有功能富集性、通路富集性。因此不同组学检测数据也具有相似的功能富集性和变化规律。
网络关联算法正是基于这些生物学理论基础。
- 基于WGCNA的共变关联网络分析(WGCNA module correlation)
- 基于表观模块的差异网络分析(EMDN algorithm)
- 相似性网络融合分析(SNF algorithm)
分析结果:关联网络图
- ①基于WGCNA的共变关联网络分析
- 利用组间差异基因鉴定共甲基化和共表达模块。
- 模块-模块相关性、模块表型相关性可以有效识别具有功能富集性的多组学变化模块。
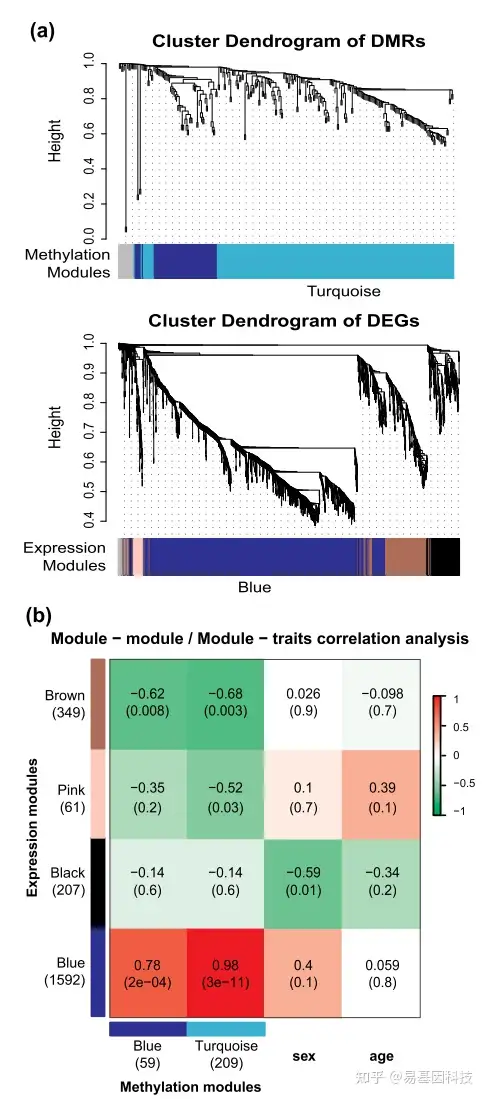
图例:血液组织RRBS + RNA-seq,基因的差异甲基化模式与基因表达模式的共变关联网络分析。
- 前期直接关联得到的基因很少;
- 改变策略,采用基于WGCNA的共变关联网络分析,得到的共甲基化和共表达基因均富集于自噬相关通路。
关联理论基础:基因组DNA的甲基化与基因表达变化具有功能富集性。


图例:肠道宏基因组+代谢组,不同管理状态下川金丝猴粪便代谢物与肠道菌群基于WGCNA的共变关联网络分析。
- 鉴定了2对强正相关的物种和代谢物的共变化模块。
- 圈养条件的代表性模块中发现了潜在致病菌和相关代谢物。
关联理论基础:肠道菌群可响应环境变化改变肠道微环境中相关的代谢产物的浓度。
- 基于表观模块的差异网络分析(EMDN algorithm)
- 利用组间差异基因鉴定共甲基化(共表达)模块。
- 差异共甲基化(差异共表达)网络筛选。
- 从多个差异共变网络中筛选共同网络。


图例:基于表观模块的差异网络分析(EMDN algorithm)
- 相似性网络融合分析 (SNF algorithm)

图例:
- SNF算法(图1d)使用了一种基于信息传递理论的非线性算法,该方法迭代更新每个网络,使其与其他网络更加相似。经过几次迭代之后,SNF收敛到单个网络中。
- 算法的优点是,弱相似性(低权重的边)消失,有助于降低噪声,而在一个或多个网络中存在的强相似性(高权重的边)被添加到其他网络中。

图例:融合网络三个cluster内部的连接性、紧密性和cluster之间相对较少的边界,说明该算法可以更清晰地显示多形性成胶质细胞瘤(GBM)患者的分型情况。
- 其他网络关联分析方法

从关联走向因果:组学分子实验验证
基因表达相关的组学:
- 基因敲除/抑制
- 基因过表达
甲基化组学:
- 甲基化酶基因的敲除与过表达
宏基因组(肠道菌群):
- 无菌动物模型
- 粪菌移植
以上是关于多组学分析方法及组学分子实验验证的解析,易基因提供表观组、转录组、微生物组等多组学科研技术服务。

参考文献:
Yan H, Bombarely A, Xu B, et al.Autopolyploidization in switchgrass alters phenotype and flowering time viaepigenetic and tranion regulation[J]. Journal of experimental botany,2019
Zhang, D., Hu, Q., … Gao, F. (2019). Epigenetic and transcriptional signatures of ex situ conserved golden snub-nosed monkeys (Rhinopithecus roxellana). Biological Conservation, 237, 175–184.
Zuo, T., Lu, X. J., Zhang, Y. (2019). Gut mucosal virome alterations in ulcerative colitis. Gut, 68(7), 1169–1179.
Gao, Y., Liu, X.. (2017). Protein Expression Landscape of Mouse Embryos during Pre-implantation Development. Cell Reports, 21(13), 3957–3969.
Evaluating the influence of conservation activities on the gut microecosystem of Rhinopithecus roxellana based on establishment of a gut microbiome gene catalog. Unpublished.
Inter-correlated gut microbiota and SCFAs changes upon antibiotics exposure links with rapid body-mass gain in weaned piglet model. The Journal of nutritional biochemistry,2019, 74: 108246.
Multiple network algorithm for epigenetic modules via the integration of genome-wide DNA methylation and gene expression data. BMC Bioinformatics , 2017,18(1), 1–13.
Similarity network fusion for aggregating data types on a genomic scale. Nature Methods , 2014,11(3), 333–337.
Di Nanni, N., Bersanelli, M.(2020). Network Diffusion Promotes the Integrative Analysis of Multiple Omics. Frontiers in Genetics,11(February), 1–12.
相关阅读:
多组学关联研究怎么做?DNA甲基化组+转录组+宏基因组+16S研究思路
干货系列:高通量测序后的下游实验验证方法——ChIP-seq篇
标签:图例,甲基化,组学,基因,关联,多组,干货 From: https://www.cnblogs.com/E-GENE/p/17405728.html