本文以 SQL 查询为基础,在关系模型的执行方案下讨论了分布式/并行 OLAP 任务执行的基本模型和经典方案,并且涵盖了一些最新研究(如动态调整技术)的介绍。主要策略:Data Locality、Working Stealing、Delay Stealing、慢任务异地重试等。
万变不离其宗,这些策略与分布式系统中的任务并行策略本质上很像,例如通过数据分区来支持分布式、任务调度中利用的数据局部性、任务窃取、延迟窃取等。可通过了解这些策略在心中有个认知,知道在做系统时要考虑的问题和可能的解决措施。
需要注意的是,这些策略并不是奇思妙想,而是把很多容易想到的符合直觉的方案提出成理论,并在系统实践中通过实验结果严重策略是否好用。本质上就是一个“实验工程”——提出一种看上去还可以的方案,再通过实验尝试验证方案的可行性。
另外,从本文中也可以看出“吹牛”的重要性,能将很多大家能想到甚至是工业界很多系统中用到的方案“包装”成一种策略提出来、并进行偏理论层面的表述。这样不仅让系统的设计方案变得更有“唬人”,更重要的是看上去更简洁了。
典型的例子是这里的EXCHANGE算子的提出:EXCHANGE 算子是在 Volcano 模型下实现数据交换(Shuffle)的重要解决方案,它使得其他算子完全可以以单线程模式运行,并将数据交换变为一个透明的操作,EXCHANGE 算子的引入使得传统关系模型的执行方案可以被优雅地转换为并行执行方案。可看出,EXCHANGE实际上就是不同算子间的数据交换操作的封装,对外表现为一个算子被其他算子使用。本质上并没有什么新奇的地方。
再例就是数据不均衡的处理,容易想到的就是把任务多的核拿些任务给少的核去执行,“拿”的方式可以是主动去拉取、也可以是有个全局调度者去重分配。这里却表述为"working-Stealing/Relocation"策略,“逼格”立马不同了。
转自 https://io-meter.com/2020/01/04/olap-distributed
以下为正文
OLAP 是大数据分析应用非常重要的组成部分。这篇文章是介绍 OLAP 任务在并发/分布式环境下执行和调度的算法和模型的。我们将从最简单的 Volcano 模型开始讲起,逐步引出分布式环境下执行 OLAP 查询操作的一些挑战和经典的解决方案。
这些算法和模型将主要在 SQL 和关系模型的语境之内讨论, Spark 和 Flink 这类基于 DAG 的处理系统内也有很多相似的概念,在本文中将不会赘述。
基础模型
Volcano 模型
在《SQL 查询优化原理与 Volcano Optimizer 介绍》中,我们已经对以关系代数为基础的 SQL 查询优化算法进行了介绍,本文的很多内容也将建立在前文内容的基础之上。首先我们来介绍在单线程执行环境下广为人知的经典模型——Volcano 模型。(值得注意的是,这里的 Volcano 模型指的是查询的执行模型,和前文的优化器模型并非同一事物。)
Volcano 模型又叫迭代器模型,其基本思路十分简单:将关系代数当中的每一个算子抽象成一个迭代器。每个迭代器都带有一个 next 方法。每次调用这个方法将会返回这个算子的产生的一行数据(或者说一个 Tuple)。程序通过在 SQL 的计算树的根节点不断地调用 next方法来获得整个查询的全部结果。比如 SELECT col1 FROM table1 WHERE col2 > 0;这条 SQL 就可以被翻译成由三个算子组成的计算树。如下图所示,我们也可以使用伪代码将这三个算子的执行逻辑表示出来。

可以看到,Volcano 模型是十分简单的,而且他对每个算子的接口都进行了一致性的封装。也就是说,从父节点来看,子节点具体是什么类型的算子并不重要,只需要能源源不断地从子节点的算子中 Fetch 到数据行就可以。这样的特性也给优化器从外部调整执行树而不改变计算结果创造了方便。为了方便分析上述计算方案的调用顺序和时间花费,我们将一个 next 函数的调用分为三部分:调用部分(Call)、执行部分(Execution)和返回部分(Return)。下图描绘了之前的计算树的执行过程:
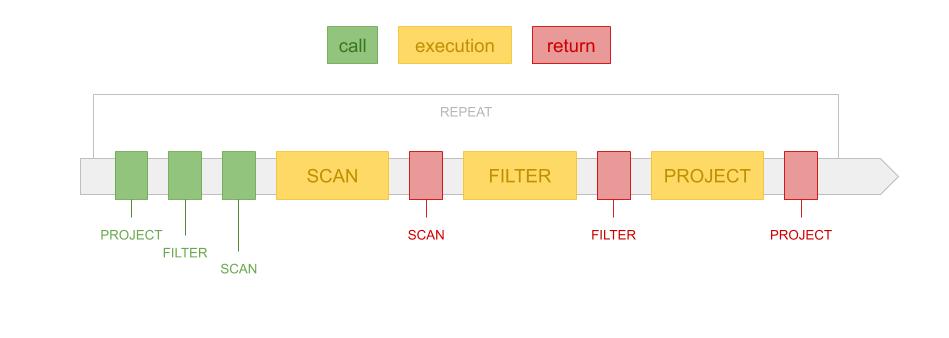
如上图所示,绿色方块代表对 next 方法的调用,黄色方块代表对应算子的执行内容,红色方块代表算子的数据返回。可以看到,上述计算树的执行,是通过不断地重复对 \ PROJECT 算子的调用开始的。当 PROJECT 算子被调用后,他紧接着要先调用 \ FILTER 算子的 next 方法,而 FILTER 算子又会进一步调用 SCAN 算子。因此,最先执行计算任务的是 SCAN 算子,在 SCAN 算子返回一行结果之后,FILTER 算子开始进行处理,直到 PROJECT 算子完成他的任务。
以上只是 Volcano 模型完成一行操作所进行的任务,一次查询需要不断地进行上述操作以处理表中的每一行。《MonetDB/X100: Hyper-Pipelining Query Execution》当中的分析表明,这些对 next 方法的调用(绿色部分)本身就占用了大量的执行时间,因此一个很容易想到的优化方案就是在调用 next 方法的时候一次处理一批数据。这种优化方案被称为向量化(Vectorization)这种向量化的执行方案不但使得函数调用的成本得以被均摊,也对 CPU 的 Cache 更为友好。向量化还为进一步的优化(如 SIMD 指令执行)提供了有利条件。
上述 SQL 和执行方案只是最简单的一个案例,接下来让我们讨论一个稍微复杂一点的例子:
1 |
SELECT t1.col1, t1.col2, t2.col2 |
在这个例子中,有一个 JOIN 算子,因此在生成的执行方案树当中会有一个分叉。我们假定 t2 表的行数远小于 t1 表,这样一个合理的执行方案可能是先将 t2 表的所有数据读出来构造一个 Hash 表,再将 t1 表当中的每一行读出并通过 Hash 表查询获得结果。此时的 Volcano 模型的执行要更复杂些。JOIN 算子为了向上封装这些细节,需要在内部不断调用 t2 表的 next 方法直到将其内容全部读取出来。因此,对于这样一条 SQL,他的执行树需要表示成下图的样子。
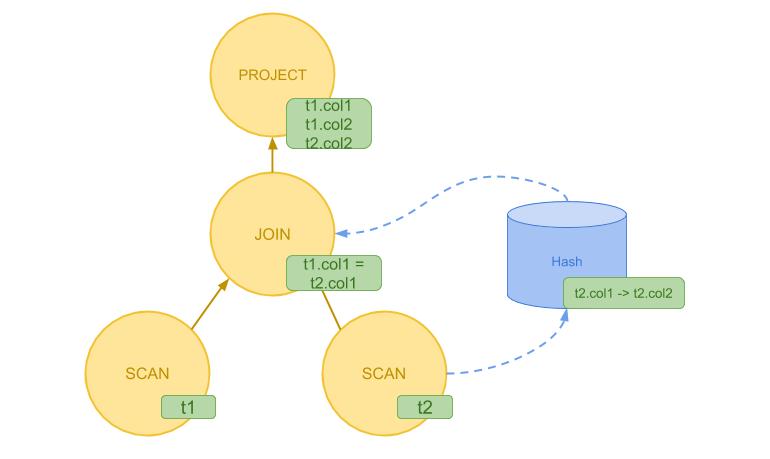
如上图所示,我们现将 t2 的内容读入 Hash 表,构建 t2.col1 -> t2.col2 的映射。之后再逐一读入 t1 表的内容,对于 t1 表的每一行,我们使用它的 col1 列在 Hash 表中进行查询,从而得到 JOIN 之后的结果。
对于这样的几个执行方案,他的执行顺序图可以表示成如下情况。可以看到,对 t2 表的扫描完全包含在 JOIN 算子的执行过程当中。
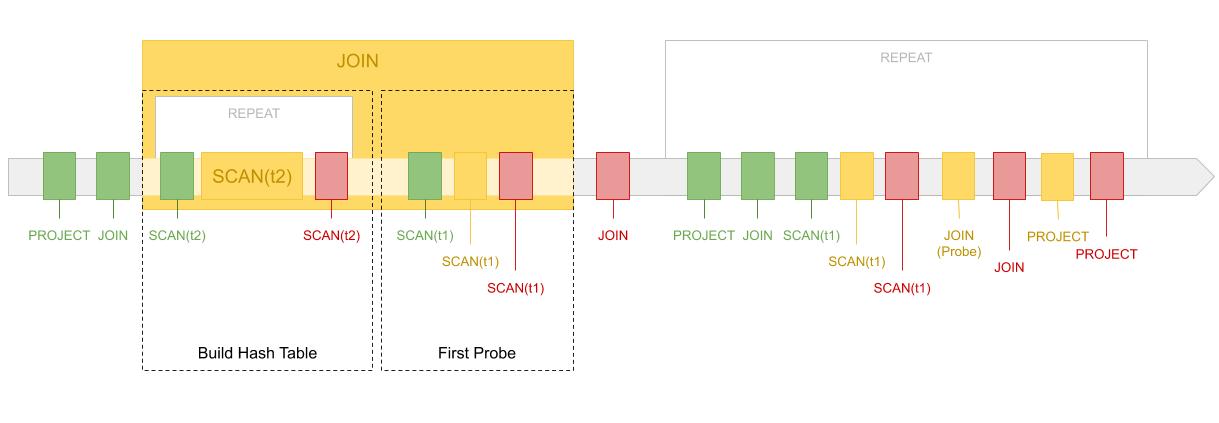
可以看到,JOIN 算子的执行分为两个部分。第一个部分它会在内部不断调用 t2.next() 函数构建 Hash 表,之后调用 t1 的 SCAN 算子一次以便返回第一行结果。之后对 JOIN 的调用就只会读取 t1 的内容进行并在 Hash 表里探查(Probe)。这一方式实现的 Hash 表是一个带有内部状态的算子,与其他的算子大不相同。而它构建内部 Hash 表的过程可以被认为是一种物化(Materialization)。物化这一概念在之后讨论并发执行的时候也十分重要。
Push 模型(Bottom to Top 模型 )
除了上述 Volcano/迭代器模型,还有一种反向的调用模型也十分流行,那就是 Push 模型。Push 模型简单来说就是由调度器先分析执行树,然后从树的叶子节点开始执行,在执行之后,有子节点通知父节点执行操作。Push 模型的时间顺序图如下:
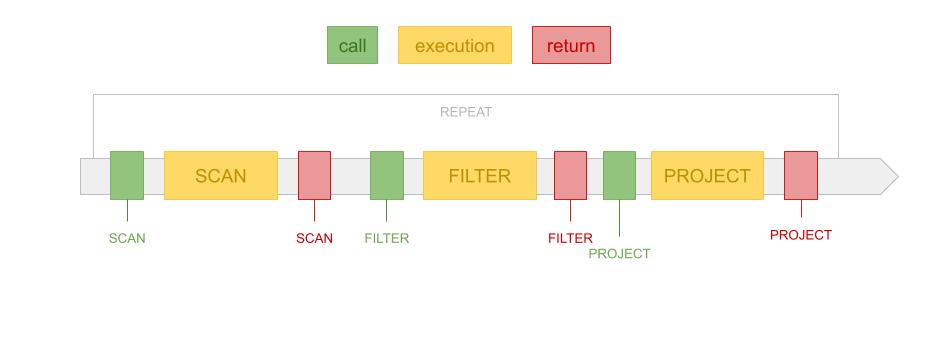
Push 模型的执行看起来更为直观,但是由于控制流是反转的,一般实现起来会比较繁琐。相比起来 Volcano 模型更易于操作,比如在终止查询的时候,Volcano 模型只要停止从根节点继续迭代即可。但是 Push 模型相对单纯的 Volcano 模型也有很多优点:由于子算子产生的结果会直接 Push 给父算子进行操作,Push 模型的 Context switch 相对较少,对 CPU Cache 的友好性也更强。
可以看到,无论是 Volcano 还是 Push 模型,执行查询的步骤都是调度问题。在下文,我们将会先以 Volcano 模型为例子,介绍其并发执行的解决方案。
并行模型
SQL 执行树的并发执行一般有两种类型:算子内部并行和算子间并行。这两种并发模型往往被组合使用。所谓算子内部并行,是指我们将数据进行分区,因此一个算子可以同时工作在不同的分区上,从而加快查询执行。算子间并行是指不同的算子(尤其是父子算子)同时在不同的 CPU 内核上运行,算子间通过通讯得以传递数据。算子间并行常见于流处理系统。
下图是上述简单 SQL 查询在算子内并行和算子间并行的示意图。
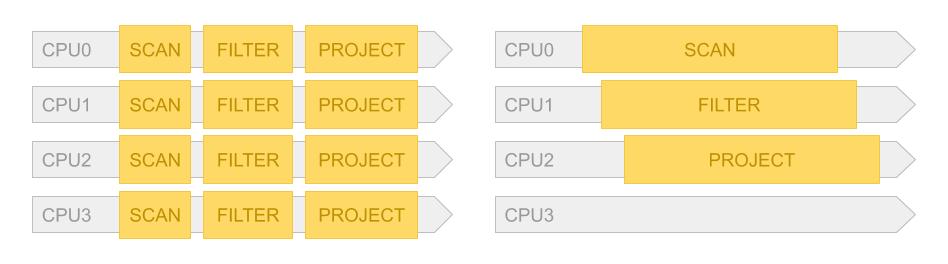
在示意图左边表示的是算子内部并行,这意味着每个算子处理的都是数据的不同分区(Partition),在右边表示的是算子间并行,这意味着每个算子都会处理所有的数据,只是下游的算子无需等待上游的算子结束任务——他可以持续地处理自己已经接收到的数据。
对于算子间并行来说,其执行树和在 Volcano 模型下的实现并没有特别大的区别,只是各个算子在调用 next 方法时可能会被阻塞。在 Push 模型下,它们也可以以类似 Actor Model 那样,为每个算子提供一个信箱或者 Buffer 以储存接收到的数据。
对于算子内部并行来说,如果只是向上述图示的简单查询,每个分片都可以被独立的处理而不同的 CPU 不需要任何数据交换。但是对于我们讨论的第二条带有 JOIN 语句的 SQL,一个算子内部并行的不同部分也需要进行数据交换。也就是说,有时我们可能需要进行 Shuffle 操作。
分布式/并行执行的 Shuffle 操作
在分布式/并行执行环境下需要执行 Shuffle 的原因有很多。其中一种情况是因为性能或者储存能力的原因,我们无法使用一个全局的 Hash 表,而必须使用分布式 Hash 表。分布式 Hash 表在每个 CPU 内核(或计算机节点)上只处理 Hash 表的某一分区。如果在 CPU 的另一个内核(或另一个计算机节点)上有这一个分区的数据,则必须将数据发送到这一分区进行处理,以保证数据的全局一致性。
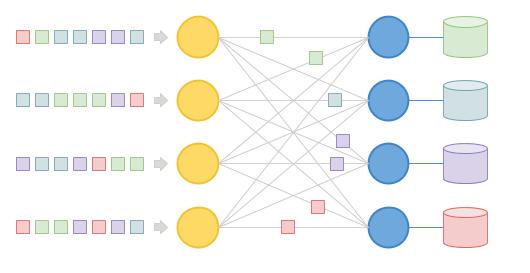
在上文所提到的带有 JOIN 的 SQL 查询中,JOIN 算子恰好需要构建一个 Hash 表。因此它也需要能够 Shuffle 数据。然而,这里就带来一个难点:我们并不想为并行执行的 JOIN 算子编写额外的代码,有没有办法让每个算子都以单线程模式执行,使得 Shuffle 操作对这些算子透明呢?
换句话说,我们仍然只需要以单线程模式实现每个算子(而不需要大幅修改它们),每个算子可以被自然地并发调度起来,不需要管理数据的 Shuffle 。这样执行器的实现就变的简单起来——我们可以基于单线程的算子来实现并行。
Volcano 模型已经提供了这一问题的解决方案:EXCHANGE 算子
EXCHANGE 算子
EXCHANGE 算子是用来为其他算子实现 Shuffle 功能的算子,它相当于将 Shuffle 的功能抽取出来作为一个独立的模块。在进行并行计算时,执行器会在执行方案树的合适位置插入 EXCHANGE 算子,然后将这一执行方案在数据的不同分区当中运行起来,每个分区的执行可以在一个不同的 CPU 内核(或计算节点)上。同一个 EXCHANGE 算子在不同内核(节点)上的实例会相互交换数据,保证上层算子可以透明地通过 next 调用得到正确的分区内的数据。
下图是上述复杂 SQL 在插入 EXCHANGE 算子并进行并行执行后的执行方案示意图。
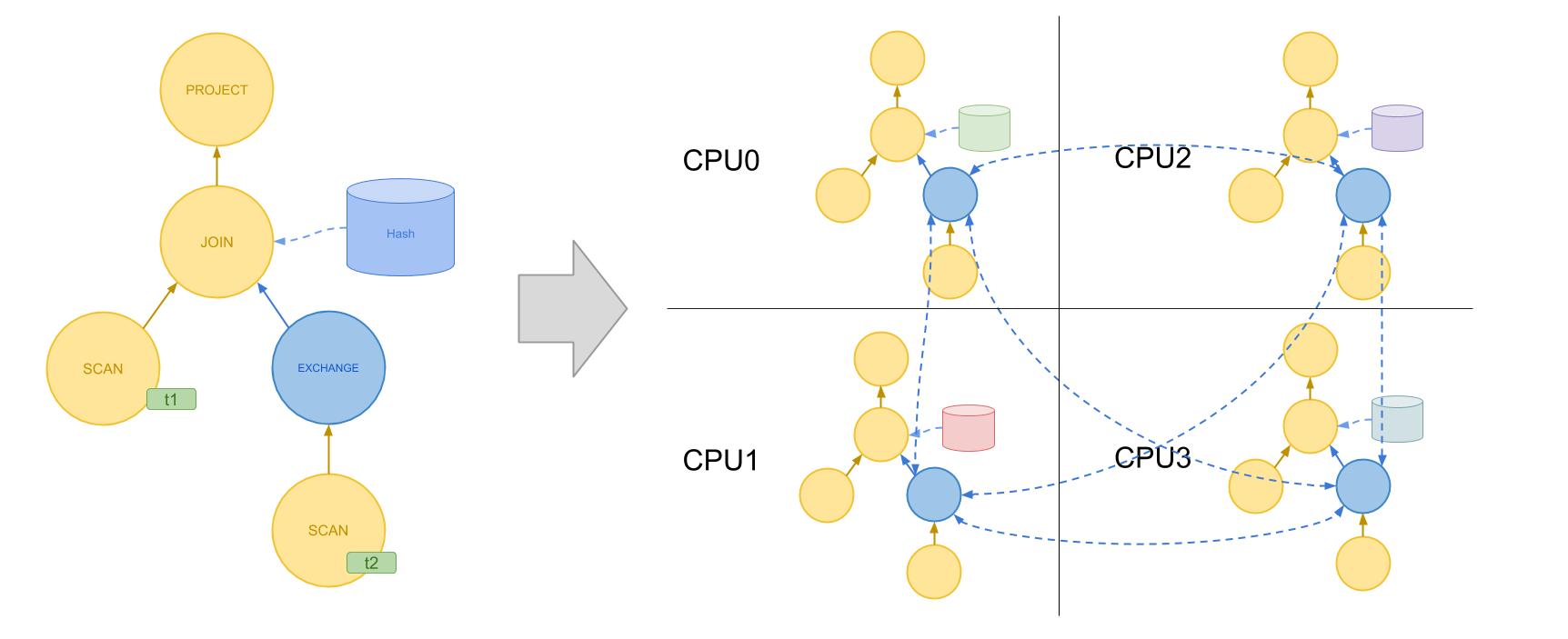
如图所示,我们在 t2 表的 SCAN 算子上方添加了一个 EXCHANGE 算子。这样,当每个 CPU 上运行的 JOIN 算子从这里执行 next 操作时,只会取到对应分区的数据行。如果 EXCHANGE 算子从下面的 SCAN 算子取到了其他分区的数据行,它会将其发送给对应 CPU 内核(或节点)上的 EXCHANGE 算子实例。因此,所有的其他算子都不需要对数据的分布和 Shuffle 操作有任何了解。
值得注意的是,我们在这里只为 t2 表添加了 EXCHANGE 算子而不是给所有算子都添加了 EXCHANGE,这是因为,我们可以使用 t1 表原本的分区来决定 JOIN 算子中构建的 Hash 表的分区,因此在对 t1 表进行 Probe 的时候,是不需要通过 EXCHANGE 算子来交换数据的。这一优化可以直接通过静态分析而实现。
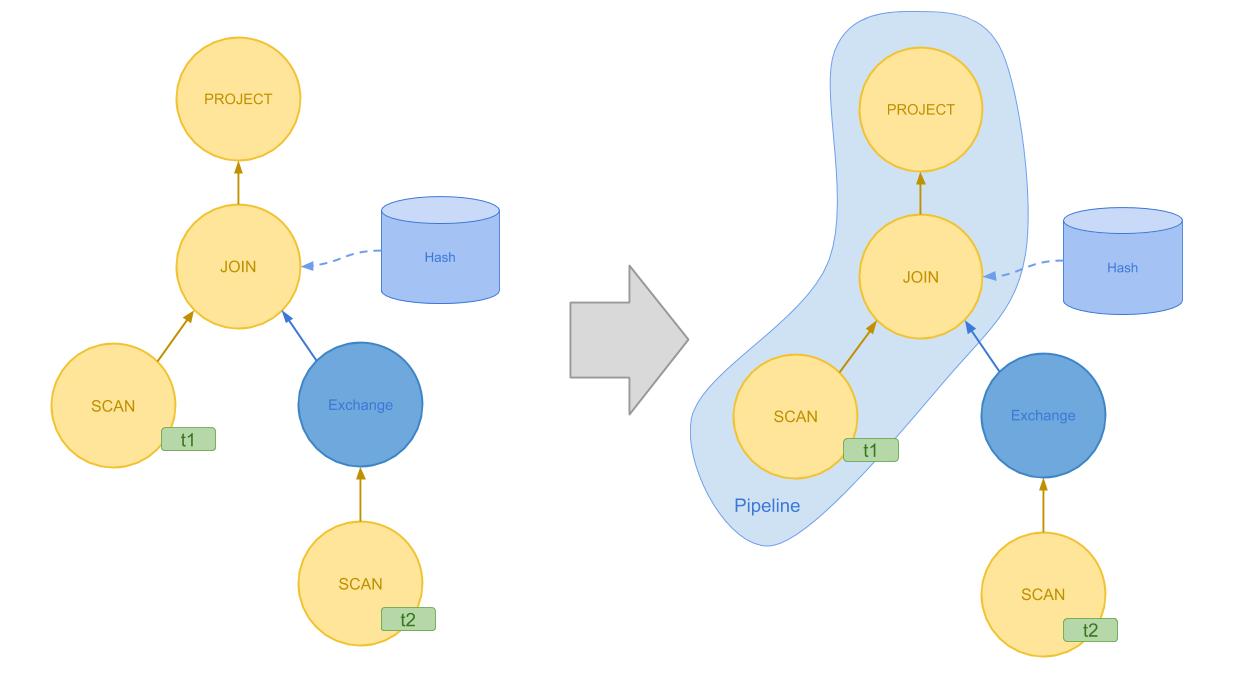
Pipeline(处理管线)
前文提到 Push 模型的 Context Switch 较少,在 Volcano 模型下,当一连串算子互相之间都不需要交换数据,我们可以使用数据管线技术来实现相似的目的。数据管线技术将一连串算子使用Operator Fusion 技术合并成一个算子那样进行调用,比如说,对于前文简单 SQL 的伪代码,使用处理管线合并之后的执行代码将会更加简洁。Pipeline 也常常配合代码编译技术使用,以极大地加速查询的执行。

值得注意的是,对于我们的第二个 SQL 查询,虽然有 EXCHANGE 算子在其中,导致右边的 t2 表的 SCAN 算子无法管线化,但是左边 t1 表、JOIN 和 PROJECT 三个算子是可以组成一个 Pipeline 的。
并行执行面临的挑战
前文提到了对 SQL 执行方案提到了对数据进行分割的两种方法:对 SCAN 输入的数据进行分区和在处理时对数据进行分段(向量化执行)。我们可以认为这两种分割方法前者是横向(Horizontal)切分,后者是纵向(Vertical)切分。如下图所示:
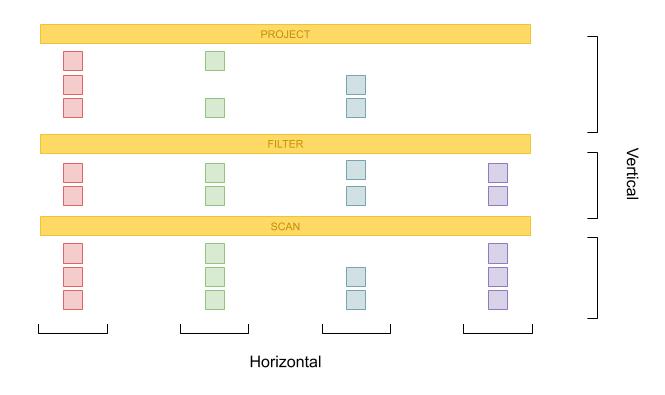
在启用数据分区来实现并行处理后,我们的分布式/并行任务执行就会面临如下的一些挑战:
- 数据倾斜:数据倾斜常见的情况有两种:1)对输入的数据进行分区时,不同分区数据量区别很大;2)经过一些计算(如 FILTER 操作)之后不同分区保留下来的数据量区别很大。由于并行处理任务结束的时间取决于最慢的任务,因此数据倾斜对执行性能的影响很大。一般来说,第一种数据倾斜的情况较为容易处理,我们可以通过再平衡和换用更好的分区方法来解决。第二种数据倾斜就比较难预测和处理了。
- 处理速度倾斜:除了数据倾斜之外,还有一种非常影响性能的倾斜是处理速度倾斜。这种倾斜是指不同的处理器内核(或节点)处理同样数据量所花费的时间不同。它常常出现在某些处理器内核(或节点)因环境干扰、任务调度、阻塞、错误和失败等原因减慢甚至中止响应的情况下。处理速度倾斜受环境因素影响大,很难发现和优化。
- Data Locality:当一个算子完成它所进行的计算并将结果传递给下一个算子时,我们往往希望下一个算子被调度在同一个 CPU 内核(或节点)上。这是因为内核间的内存交换或节点间的网络传输是一个非常耗时的操作。有时我们必须在 Data Locality 和数据/处理速度倾斜之间进行取舍,这对调度算法的设计带来了严峻的挑战。
为了解决上述三个难点并在调度算法设计时对其进行取舍,学术界和工业界做出了不懈的努力并产生了很多好的论文和实践。接下来我们将会看到一些经典的方案和最新的优化方向。
经典模型
NUMA 架构
在介绍解决 OLAP 并行执行的经典模型之前,我们先介绍对我们所面临问题的一个抽象建模 NUMA。NUMA 是 Non-Uniform Memory Access 的缩写。它指的是在较新生产的多核 CPU 中,不同 CPU 内核访问不同内存位置的速度不同的现象。
为什么会有这种现象呢?在过去,CPU 只有一个内存总线,所有的 CPU 内核访问内存时,都通过这个总线进行,因此每个 CPU 访问内存位置的速度都是相同的。这种访问模式被称为 UMA (Uniform Memory Access)。但是使用一个总线阻止了 CPU 对内存的并发访问,为了增加内存访问性能,新的 CPU 开始加入多个可以同时独立访问不同内存条的 Socket,并将相邻的 CPU 内核连接在这些 Socket 上。也就是说,一块 CPU 上的内核被组织成不同的分区,每个分区有一个 Socket 可以直接访问一块内存条,为了能在这些 CPU 分区之间共享内存,它们之间也建立了内存访问通路。下图左边部分表示了这种架构。
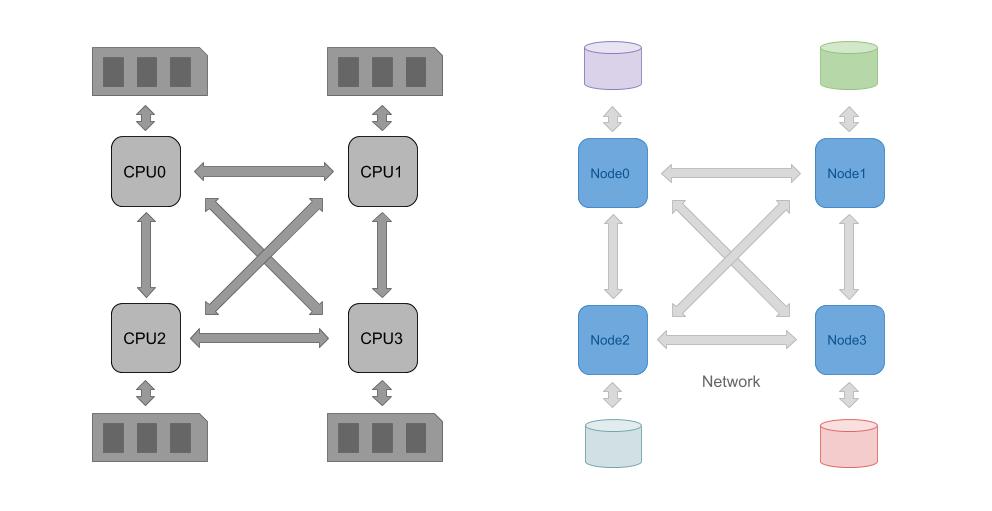
显然,一个 CPU 内核如果要访问另一个 CPU 管理的内存,就需要通过它们之间的联络通路进行一次跳跃,这种跳跃本身将会花费一定的时间。在现代操作系统(如 Linux 等)中,进行内存分配和进程调度时已经考虑了这种情况,因此会按照一定的算法对任务和数据进行分配。然而,由于操作系统无法具体确知进程的具体逻辑,这种算法对于数据库和 OLAP 应用往往并不理想。因此很多数据库自己实现了相关调度功能。
在上图的右侧是一个基于网络的处理集群的示意图,我们可以看到,通过网络执行任务的集群和带有 NUMA 属性的 CPU 有相似之处,如果在一个节点当中执行计算得到的计算结果需要被其他节点访问,也需要在节点之间进行一次传输操作。而每个节点自身也拥有一个类似内存的储存空间(硬盘)。这两种架构虽然有不同的规模,其结构却是雷同的。因此很多时候我们也可以把应用于 NUMA CPU 的并行调度算法应用于分布式系统当中。
Morsel-Driven Parallelism
接下来我们来介绍在 NUMA-aware 查询执行方面非常经典的论文《Morsel-Driven Parallelism: A NUMA-Aware Query Evaluation Framework for the Many-Core Age》提出的模型。这一篇论文以 HyPer 系统为基础,主要有以下几个特点:
- 使用 Pipeline 技术组合算子
- 使用自底向上的 Push 模型调度任务。当一个任务执行结束时,它会通知调度器将后序任务假如到任务队列中
- 既使用水平数据分区,也使用垂直数据分区,每个数据块的单位被称为 Morsel。一个Morsel 大约包含10000行数据。查询任务的执行单位是处理一个 Morsel
- NUMA-aware,为了实现 Data Locality,一个内核上执行的任务,由于其产出结果都储存在当前内核的 Cache 或 Memory 里,因此会优先将这个任务产生的后序任务调度在同一个内核上。这样就避免了在内核间进行数据通信的开销。
- 使用 Work-stealing 实现弹性伸缩和任务负载均衡,以缓解数据倾斜和处理速度倾斜带来的性能瓶颈。也就是说,当一个内核空闲时,它有能力从其他内核“偷取”一个任务来执行,这虽然有时会增加一个数据传输的开销,但是却缓解了忙碌内核上任务的堆积,总体来说将会加快任务的执行。
- 使用 Delay Scheduling 防止过于频繁的 Work stealing。在内核空闲并可以偷取任务时,调度器并非立即满足空闲内核的要求,而是让它稍稍等待一段时间。在这段时间里,也许忙碌内核就可以完成自己的任务,而跨内核调度任务就可以被避免。令人惊讶的是,这种简单的处理方式在实际应用中效果非常好。
在这一模型中,Pipeline 执行、以 Morsel 为单位进行数据切分和放置以及 Push 模型的任务调度前文都有涉及,也不难理解。在此特别介绍一下这一模型使用的 NUMA-aware、Work-stealing 和 Delay Scheduling 算法。
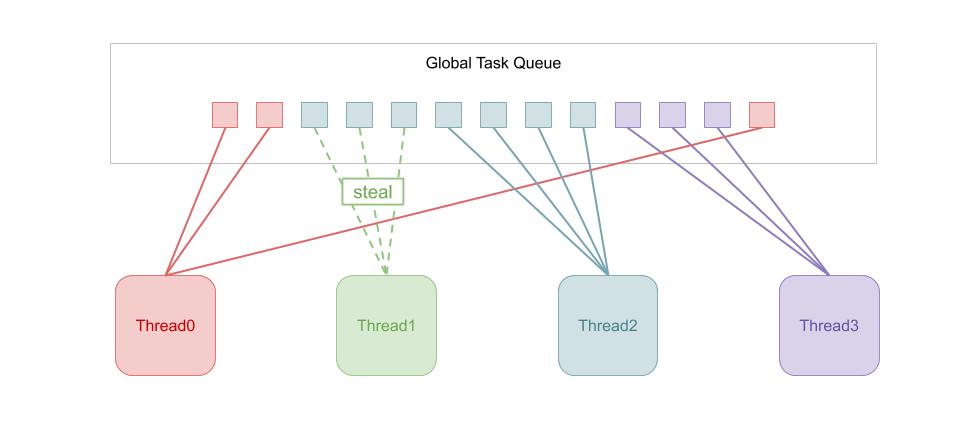
在上述论文中,NUMA-aware/Data Locality 的实现是基于一个全局的任务队列。这一任务队列使用无锁数据结构实现,因此可以被各个内核上的不同线程高效地访问和修改。每个被添加的到队列中的任务与各个内核之间有不同的亲近(Affinity)值。一个任务如果在某一个内核上执行,那么他产生的后序任务和这个内核就都具有较高的亲近值,因此当此内核空闲时,新的任务就非常可能会被调度到它上。这样就实现了对 Data Locality 的满足。
进一步,由于可能出现数据倾斜和处理速度倾斜,严格静态的满足 Data Locality 的要求可能不是最佳的解决方案。因此论文提出了使用 Work-stealing 技术进行负载均衡的方法。
熟悉 Java 并发编程的朋友可能对 WorkStealingPool 很熟悉,在这种 Executor 当中,空闲的 Thread 可以从其他 Thread “偷窃”一个任务来执行,这样各个线程的负载就会越来越均衡。在 HyPer 中,这是通过空闲内核上的线程从全局队列当中偷取与其他内核亲近值较高的任务来实现的。
为了防止偷取过于频繁得发生,HyPer 还引入了 Delay Schedule 的概念,也就是稍稍等待任务原本应该执行的内核一小会,期待原内核上的任务在这段时间内就可以完成,从而避免偷窃任务带来的数据传输开销。这一方法并非由 HyPer 首创,实际上,早在 2010 年由 Spark 主要作者 Matei 发表的《Delay Scheduling: A Simple Technique for Achieving Locality and Fairness in Cluster Scheduling》就介绍了这种方法。它不光应用于 NUMA-aware 的数据库系统中,还广泛应用于各种大数据处理系统和任务调度系统(如 Hadoop、YARN 等)。HyPer 的任务调度策略可以由下图表示。
除了上述特性以外,HyPer 还会在每个内核调度两个线程,以便最好地利用每个内核的 CPU 时间,填充其中一个线程出现 IO 产生的空隙。
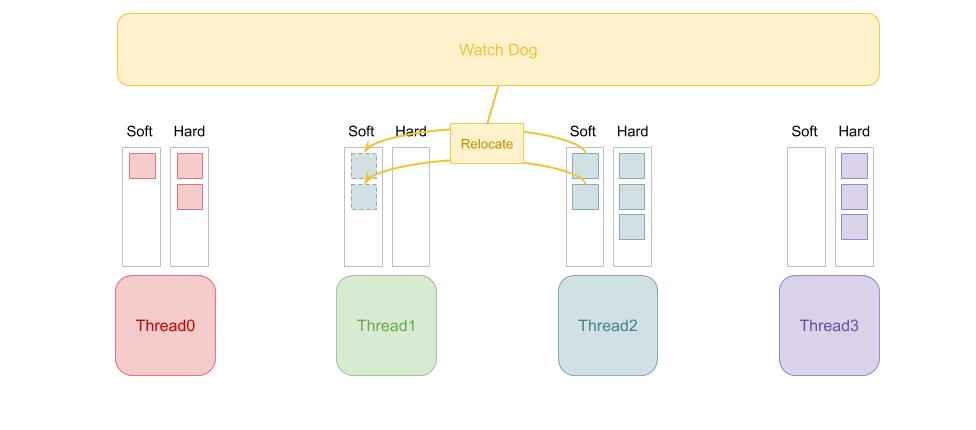
除了 HyPer 所实现的 NUMA-aware 模型,SAP HANA 系统也实现了类似的 Morsel-Driven 系统。不同的是,HANA 不是使用所有线程共享的全局队列,而是为每个线程配置本地的任务队列。而任务的再平衡也是通过一个独立运行的 Watch Dog 线程完成的。在这一模型中,Watch Dog 线程可以实现非常丰富的功能,灵活地监控和调配资源。但是任务再平衡的逻辑就比较复杂,没有 Work-stealing 这么简单直观了。
为了防止某些不适合被放到其他内核的任务被调度走 ,HANA 会为每个线程配置 Hard Queue 和 Soft Queue 两个队列。其中,Soft Queue 里的任务可以被 Watch Dog 线程重新配置到其他内核。
分布式和本地并行混合方案
在 2015 年的 VLDB 论文《High-Speed Query Processing over High-Speed Networks》里介绍了 HyPer 系统在高速网络尤其是 RDMA 系统上实现的进一步优化。在本文中,我们略去其中有关高速网络应用的部分,仅关注其中有关分布式和本地并行混合模型的优化方案。
所谓分布式与本地并行的混合方案,指的是在分布式系统中,每个节点又都是具备多核计算能力的服务器。因此,从微观来说,每个节点本身是一个 NUMA 系统,从宏观来说,这些节点组成的集群也是一个 NUMA 系统。
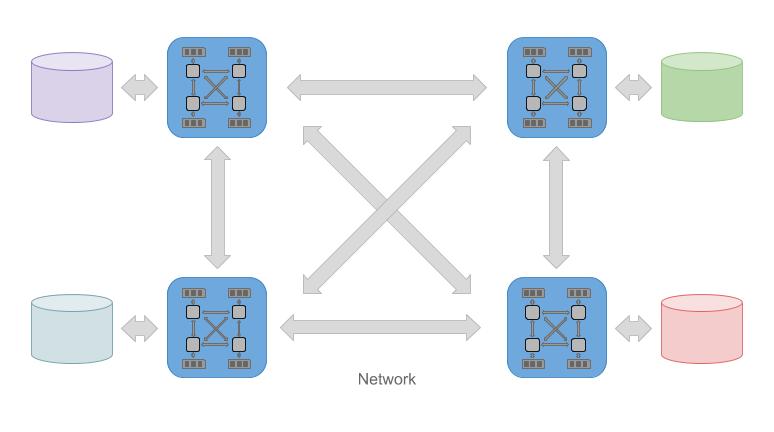
这篇文章提出的第一个优化是,对于某些 EXCHANGE 算子,如果我们知道它下面的输出结果集比较小,我们可以不通过 Shuffle 的方式而是通过 Broadcast 的方式来将其传递到各个节点。这也是执行 OLAP 计算的一种常见优化。比方说,在上述 t1 JOIN t2 的 SQL 查询中,如果 t2 的数据量很小,那么将其全部物化并直接构建出一个 Hash 表,并传播给各个节点是一个不错的选择,这是因为大部分聚合操作在本地就完成了,避免了多次数据的交换。
这篇论文提出的另一个相关的技术也很简单。在传统的模型下,假如我们有 <span id="MathJax-Span-2" class="mrow"><span id="MathJax-Span-3" class="mi">M� 台机器,每台机器运行 <span id="MathJax-Span-5" class="mrow"><span id="MathJax-Span-6" class="mi">N� 个查询进程,每个进程里有一个 EXCHANGE 算子。那么这些 EXCHANGE 算子之间就有 <span id="MathJax-Span-8" class="mrow"><span id="MathJax-Span-9" class="mo">(<span id="MathJax-Span-10" class="mi">M<span id="MathJax-Span-11" class="mo">×<span id="MathJax-Span-12" class="mi">N<span id="MathJax-Span-13" class="mo">)<span id="MathJax-Span-14" class="mo">⋅<span id="MathJax-Span-15" class="mo">(<span id="MathJax-Span-16" class="mi">M<span id="MathJax-Span-17" class="mo">×<span id="MathJax-Span-18" class="mi">N<span id="MathJax-Span-19" class="mo">−<span id="MathJax-Span-20" class="mn">1<span id="MathJax-Span-21" class="mo">)(�×�)⋅(�×�−1) 条相互交流的链路。也就是说所有这些 EXCHANGE 算子都可能会相互交换信息,这将产生巨大的连接数。如果这些链路同时发送数据包,很有可能产生数据涌塞。因此,此论文提议在每台机器上启动一个 Multiplexer 专门用来管理数据请求。也就是说,同一个节点上的 EXCHANGE 实例会先将数据发送到 Multiplexer,而本机内的数据 EXCHANGE 直接通过 Multiplexer 处理而无需使用网络栈。对于外部的数据请求,Multiplexer 将会进行缓冲 和批量传送。因此链路数减少到 <span id="MathJax-Span-23" class="mrow"><span id="MathJax-Span-24" class="mi">M<span id="MathJax-Span-25" class="mo">×<span id="MathJax-Span-26" class="mo">(<span id="MathJax-Span-27" class="mi">M<span id="MathJax-Span-28" class="mo">−<span id="MathJax-Span-29" class="mn">1<span id="MathJax-Span-30" class="mo">)�×(�−1) ,获得了一个量级上的减少。
动态调整数据放置和执行计划
前面提到,SAP HANA 的 NUMA-aware 模型使用了 Watch Dog 线程。这一实现增加了调度的灵活性,Watch Dog 线程也可以掌握到很多系统的信息并根据这些信息动态调整数据放置和资源调度。2019 VLDB 的论文《Adaptive NUMA-aware data placement and task scheduling for analytical workloads in main-memory column-stores》就是基于这一优势所做出的改进。论文中提出了算法以很低的资源消耗获得较为准确的内存和 CPU 使用估量,并根据这个估量和对查询当中数据放置(数据分区)的了解来实现较为复杂和精准的调度。
这篇论文的一个很重要的贡献就是发现 Memory 密集的操作(如 SCAN 操作)不适合被 Steal 到其他内核运行。论文中提出的算法可以智能地发现这些 Memory 密集的操作,从而逐步将其锁定 在最合适的内核上,以便进一步压榨 NUMA 系统中的计算资源。
动态调整数据放置和执行计划可以说是数据库系统调度的最前沿研究和发展了。其难度和复杂度都相当高。在本文中只能对其小部分思想进行简介,有兴趣的朋友可以阅读原论文以获得更准确的信息。
总结
本文以 SQL 查询为基础,在关系模型的执行方案下讨论了分布式/并行 OLAP 任务执行的基本模型和经典方案,并且涵盖了一些最新研究(如动态调整技术)的介绍。我们可以看到,对于并行 执行来说,数据的横向和纵向分割都是必不可少的。对数据进行横向分区使得我们可以在不同的分区上并行执行任务,将数据在纵向上切分,可以减少方法调用次数、减少 Context Switch 以及为弹性扩展和解决数据倾斜问题提供可能。
EXCHANGE 算子是在 Volcano 模型下实现数据交换(Shuffle)的重要解决方案,它使得其他算子完全可以以单线程模式运行,并将数据交换变为一个透明的操作。EXCHANGE 算子的引入使得传统关系模型的执行方案可以被优雅地转换为并行执行方案。
NUMA 模型是分布式/并行执行 OLAP 查询的一个基础抽象,它既可以应用于单机多核环境,也可以应用于多机集群环境。我们介绍了两种 NUMA-aware 的经典模型,它们一般使用 Work-stealing/relocation 方法来处理数据失衡和处理速度失衡,同时使用 Delay Scheduling 来防止过于频繁的任务偷窃或交换。
最后我们提到了一些比较新和复杂的实现,如动态调整数据放置和执行计划等。这些崭新的研究可以进一步压榨计算资源,获得更高的执行性能。
在本文中,没有详细介绍一种很简单的优化方式,那就是慢任务异地重试机制。有时因为节点失败或者网络阻塞等原因,一个查询的分布式任务中会有一小部分执行非常慢,而整体的查询速度则受限于这些查询。这类任务被称为尾部(Tail)任务。分布式系统业界的知名大佬 Jeff Dean 在其《The tail at scale》一文中详细介绍了这种情况和解决方案。
从上述 Work-stealing、Delay Scheduling 和慢任务异地重试可以看出,很多分布式系统当中的棘手问题都可以使用十分简单的解决办法获得不错的效果。让人不禁感慨系统设计有时真是大道至简。
标签:模型,调度,并发,OLAP,内核,算子,执行,数据,CPU From: https://www.cnblogs.com/z-sm/p/17387521.html