前言 书接上回,在上一篇文章中,我们介绍了BEVFormer这一先进的BEV算法。在本篇文章中,我们将深入探讨BEVFormer的实现细节,旨在帮助读者更深入地理解BEVFormer的工作原理和性能表现。
本教程禁止转载。同时,本教程来自知识星球【CV技术指南】更多技术教程,可加入星球学习。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【CV技术指南】CV全栈指导班、基础入门班、论文指导班 全面上线!!
算法细节
BEVFormer的输入
BEVFormer的输入是多视角摄像机和历史BEV特征。具体而言,BEVFormer使用多个摄像机捕获3D场景,并将这些摄像机视图转换为Bird's-Eye-View(BEV)图像。
此外,BEVFormer还使用历史BEV特征来捕获3D场景中物体之间的关系。
BEVFormer的编码器
BEVFormer使用一种基于Transformer和时间结构的编码器来聚合来自多视角摄像机和历史BEV特征的时空信息。
该编码器由两个部分组成:一个是用于处理多视角摄像机输入的“Multi-View Encoder”,另一个是用于处理历史BEV特征输入的“Temporal Encoder”。
Multi-View Encoder:Multi-View Encoder使用Transformer和空间注意力机制来聚合来自多视角摄像机的时空信息。
Multi-View Encoder首先将每个摄像机视图转换为Bird's-Eye-View(BEV)图像,并将这些图像作为输入。
然后,Multi-View Encoder使用Transformer和空间注意力机制来融合这些图像,并生成一个包含所有摄像机视图信息的表示。
Temporal Encoder:Temporal Encoder使用Transformer和时间注意力机制来聚合历史BEV特征。
Temporal Encoder首先将历史BEV特征作为输入,并使用Transformer和时间注意力机制来结合这些信息,并生成一个包含所有历史信息的表示。
BEVFormer的查询
从编码器中生成表示后,BEVFormer使用查询来查找空间/时间空间并相应地融合时空信息。
这种方法使用预定义的网格状BEV查询与空间/时间的特征信息来进行交互,以查找并融合时空信息,也可以帮助BEVFormer有效地捕获3D场景中物体之间的关系,来达到更优秀的表达。
BEVFormer的注意力机制
除了使用Transformer和时间结构来聚合时空信息外,BEVFormer还使用注意力机制来进一步提高系统整体的性能。
这两种注意力机制,一种是用于跨摄像机视图之间的注意力机制,叫做Spatial Cross-Attention,另一种是用于历史BEV特征之间的注意力机制,叫做Temporal Self-Attention。
Spatial Cross-Attention用于跨摄像机视图之间的注意力机制。使用这种方法来查询,并相应地聚合时空信息。然后,该方法使用空间交叉注意力机制来计算每个摄像机视图与其他摄像机视图之间的关系,并生成一个包含所有摄像机视图信息的表示。
Temporal Self-Attention用于历史BEV特征之间的注意力机制,同样是结合对应的时空信息。然后,这个方法使用时间自我注意力机制来计算历史BEV特征之间的关系,并生成一个包含所有历史信息的表示。
BEVFormer的输出
从编码器和查询中生成表示后,BEVFormer将这些表示输入到输出层中进行处理。具体而言,输出层可以根据不同任务进行定制化设计。
例如,在3D物体检测任务中,输出层可以将表示转换为3D边界框和类别概率分布;在地图分割任务中,输出层可以将表示转换为地图分割结果。
可以看出,BEVFormer是一种基于Transformer和时间结构的Bird's-Eye-View(BEV)编码器,可以有效地聚合来自多视角摄像机和历史BEV特征的时空特征,并生成更强大的表示。
从 BEVFormer 生成的 BEV 特征可以同时用于多个 3D 感知任务,比如 3D 物体检测和地图分割。
在上篇的实验结果表明,在KITTI数据集上进行评估时,与其他现有方法相比,BEVFormer在3D物体检测和地图分割方面具有更好的性能。
实验效果
BEVFormer模型在nuScenes数据集上的实验结果表明其有效性。当其他条件相同的情况下,使用时序特征的BEVFormer比不使用时序特征的BEVFormer-S在NDS指标上提高了7个以上的点数。
特别是当引入时序信息后,基于纯视觉的模型能够真正地预测物体的移动速度,这对于自动驾驶任务具有重大意义。
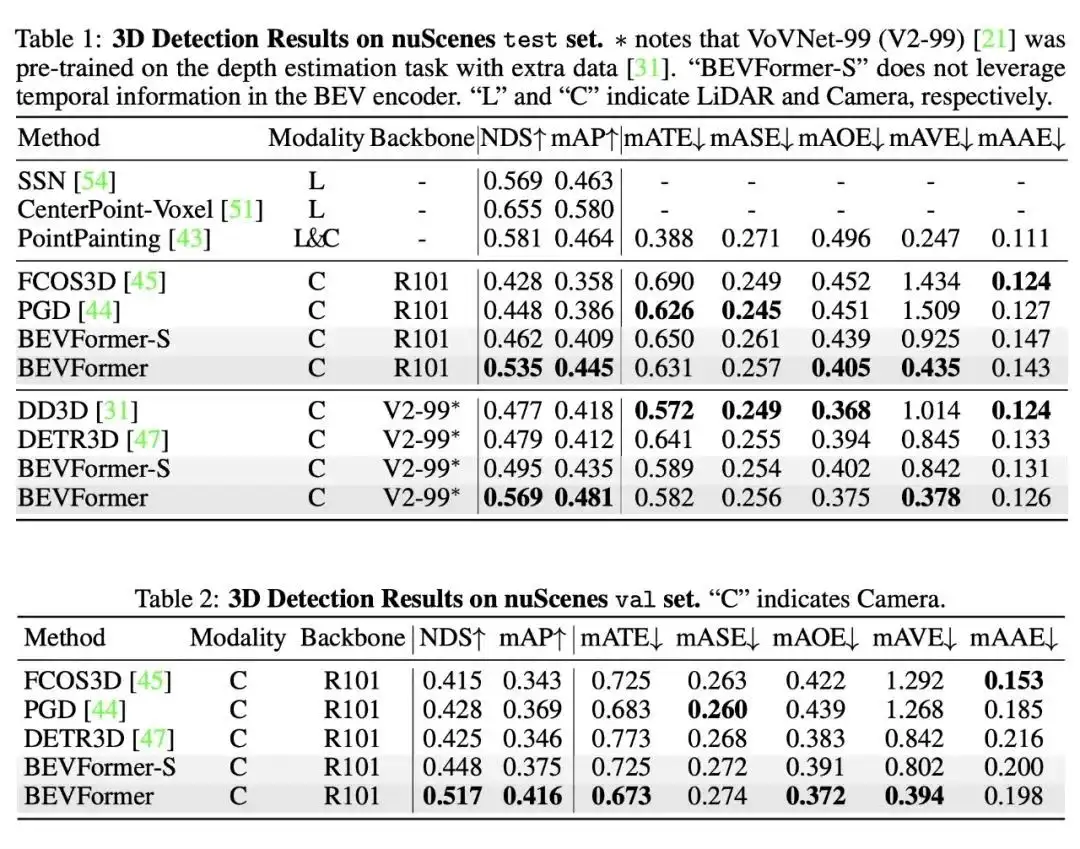
我们还证明了模型同时做检测和分割任务能够提升在 3D 检测任务上的性能,基于同一个 BEV 特征进行多任务学习,意义不仅仅在于提升训练和推理是的效率,更在于基于同一个 BEV 特征,多种任务的感知结果一致性更强,不易出现分歧。
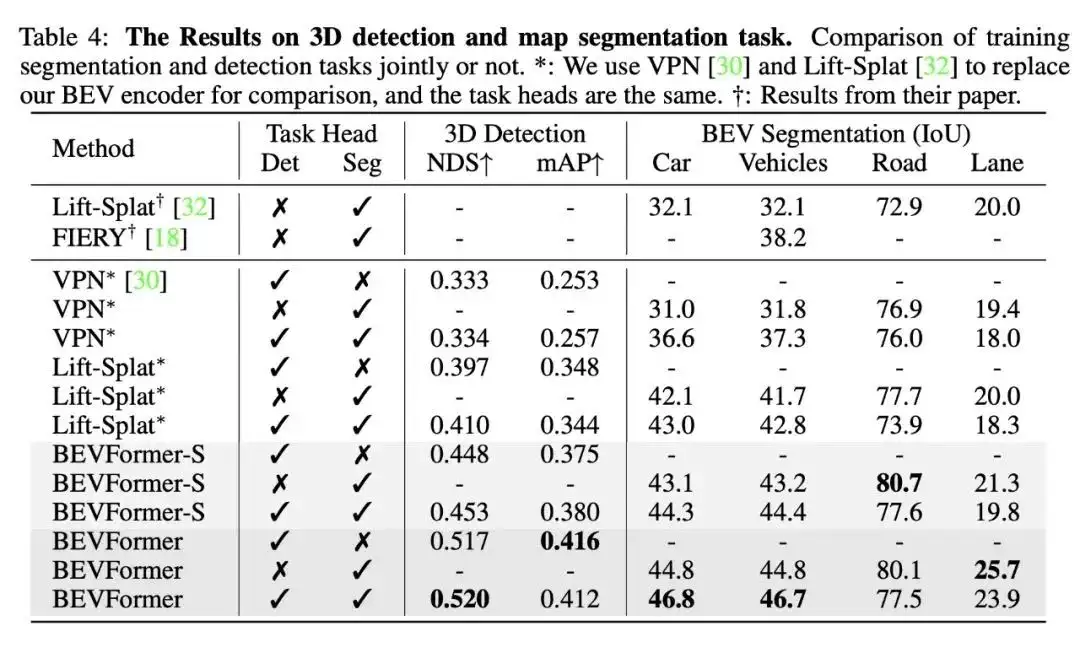
下面再来回顾一下BEVFormer的效果:

文末
总而言之,该篇论文提出了一个采用纯视觉做感知任务的算法模型 BEVFormer。BEVFormer 通过提取环视相机采集到的图像特征,并将提取的环视特征通过模型学习的方式转换到 BEV 空间,模型去学习如何将特征从 图像坐标系转换到 BEV 坐标系,从而实现 3D 目标检测和地图分割任务,并取得了 SOTA 的效果。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:470899183。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
一次性分割一切,比SAM更强,华人团队的通用分割模型SEEM来了
CVPR'23|向CLIP学习预训练跨模态!简单高效的零样本参考图像分割方法
CVPR23 Highlight|拥有top-down attention能力的vision transformer
【CV技术指南】咱们自己的CV全栈指导班、基础入门班、论文指导班 全面上线!!
CVPR 2023|21 篇数据集工作汇总(附打包下载链接)
CVPR 2023|两行代码高效缓解视觉Transformer过拟合,美图&国科大联合提出正则化方法DropKey
ViT-Adapter:用于密集预测任务的视觉 Transformer Adapter
CodeGeeX 130亿参数大模型的调优笔记:比FasterTransformer更快的解决方案
CVPR 2023 深挖无标签数据价值!SOLIDER:用于以人为中心的视觉
上线一天,4k star | Facebook:Segment Anything
AI最全资料汇总 | 基础入门、技术前沿、工业应用、部署框架、实战教程学习
标签:下篇,特征,摄像机,BEVFormer,BEV,CV,3D From: https://www.cnblogs.com/wxkang/p/17384637.html